공간 데이터 베이스 - Road network CNN
Road network CNN
1. 개요
이전에 포스팅했던 연속 최근접 이웃은 쿼리 선분(query segment)을 따라 이동하면서 각 구간별로 가장 가까운 데이터 포인트를 찾는 문제였다.
하지만 실제 우리가 사는 세상에서는 별도의 도로나 길이 존재하며 이 역시 Road network에 적용된 버전이 있다.
이번에 포스팅할 내용은 도로 네트워크 환경에서 효율적으로 연속 최근접 이웃 쿼리를 처리하는 알고리즘에 관한 내용이다.
2. UNICONS (UNIque CONtinuous Search algorithms) for NN queries
UNICONS는 NN 쿼리를 위한 알고리즘으로, Dijkstra 알고리즘에 사전 계산된 최근접 이웃 리스트를 통합한 방식이다. 세 개 이상의 엣지가 만나는 노드를 교차점(intersection point)이라 하며, 사전 계산된 NN 정보를 유지하는 교차점을 응축점(condensing point)이라고 한다.
1) 두 개의 기본 아이디어
a. 첫번째 아이디어
기본적으로 경로 P를 따라 연속 검색을 수행하려면 쿼리 경로에서 객체를 검색하고 각 노드에서 정적 쿼리를 실행하면 된다. 경로 P가 있다고 해보자. 이 P는 j개의 점 n으로 이루어져있다. 수식으로 나타내면 아래와 같다.
\[P = {n_{1}+n_{2}+...+n_{j}}\]P를 따라 이동중일때 각 $n_{1~j}$ 점에서 정적으로 RoadNetwork NN 쿼리를 실행하면 된다.
이를 수식으로 나타내면 아래와 같이 표현할 수 있다.
여기서 R은 Intersection point에서 실행한 NN 쿼리 결과이고 O는 쿼리 경로 P 위에 있는 Object의 NN 쿼리 결과이다.
b. 두번째 아이디어
이동하는 쿼리 포인트와 정적 객체 사이의 네트워크 거리 변화를 구간별 선형 방정식으로 표현할 수 있다는 것이다.
아래의 그림을 보자
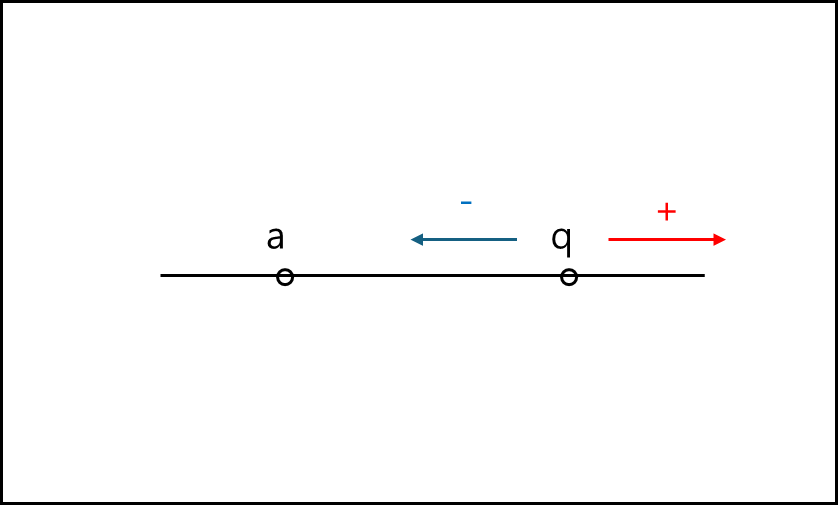
어떤 점 a와 q의 거리는 + 방향이나 - 방향으로 갈때 가까워지거나 멀어지는데 이를 선형 방정식으로 나타내면 아래와 같다.
\[d(q,a) = \left| q-a \right|\]위 식은 아래의 그래프로 나타낼 수 있다.
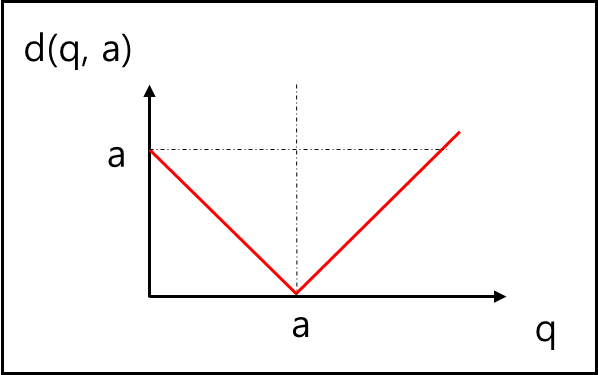
2) 알고리즘 절차
알고리즘은 분할 정복 방식을 기반으로 다음 세 단계로 진행된다
- 1단계: 교차점을 기준으로 쿼리 경로를 부분 경로(subpath)로 분할한다.
- 2단계: 각 부분 경로에 대해 유효 구간(valid interval)을 결정한다. 이는 다시 4개의 하위 단계로 구성된다:
- 2.1단계: 부분 경로상의 객체들을 검색
- 2.2단계: 부분 경로의 시작점과 끝점에서 NN 쿼리 실행
- 2.3단계: 커버 관계를 사용하여 중복 튜플 제거
- 2.4단계: 부분 경로를 유효 구간으로 분할
- 3단계: 인접한 부분 경로들의 유효 구간을 병합한다
3) 알고리즘 세부 설명
a. 위치에 따른 거리 수식
아래와 같은 그래프가 있다고 해보자.
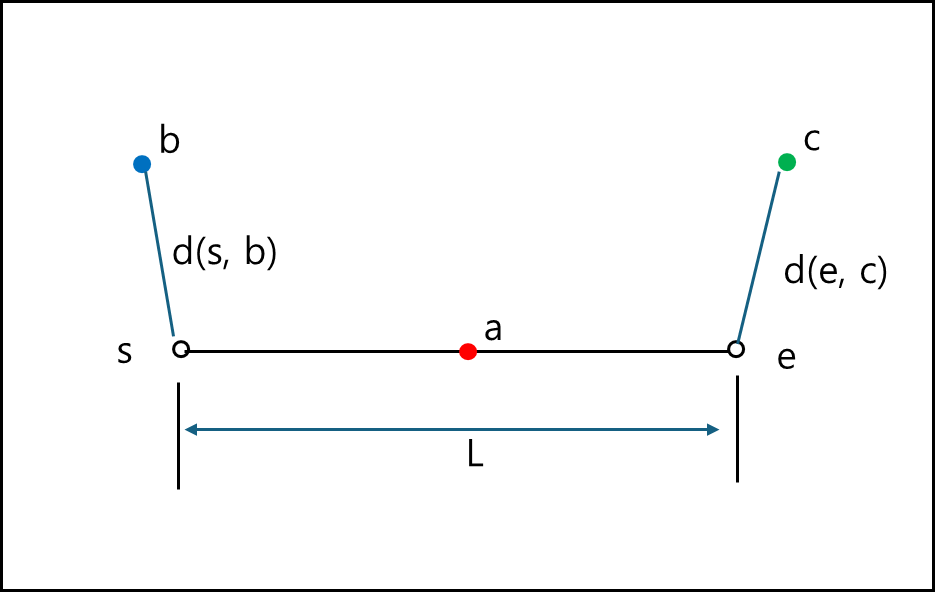
s에서 e를 잇는 선분이 쿼리 경로라고 할 때 쿼리 경로 위의 점 q가 s에서 e로 이동 할 때 각 점 a,b,c까지의 거리는 아래와 같이 나타낼 수 있다.
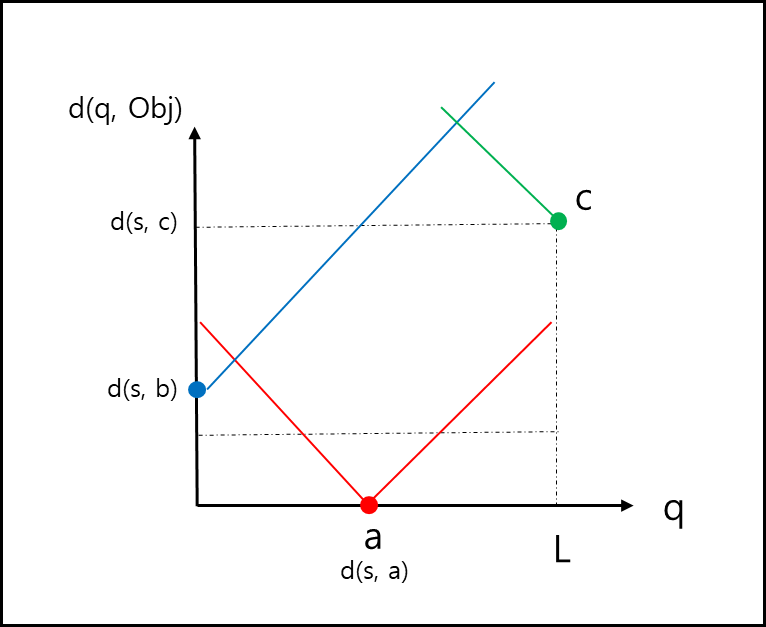
- a의 경우 쿼리 경로 내에 있으므로 q와 a가 동일해지면 거리가 0이 되지만 멀어지면서 거리가 멀어진다.
- b의 경우 s에서 최소이며, e로 이동할 수록 멀어진다.
- c의 경우 s에서 최대이며, e로 이동할 수록 가까워진다.
위 경우를 잘보면 어떤 점이 쿼리 경로 상에 있을 때 거리가 0까지 감소되었다가 증가하는 반면, 쿼리 외의 경로에 점이 있다면 고정 거리가 있음을 알 수 있다.
이를 식으로 나타내면 아래와 같다.
여기서 x는 경로 상의 시작 점의로 부터의 거리, y는 obj의 가장 가까운 점에서의 거리이다. 가령 s가 (0,0)이고 a가 (3,0) 일때 x는 3이고 y는 0이다.
b. 커버 관계
2.3.커버 관계를 사용하여 중복 튜플 제거 단계에서 사용하는 방법으로, 어떤 동일한 객체에 대해서 다수의 수식이 나올 수 있다.
이는 기준 되는 Query 점이 다르기 때문에 나타나는 문제이다.
점 s와 점 e를 잇는 쿼리라인 QL 위의 점 a이 아래와 같이 있다고 해보자.
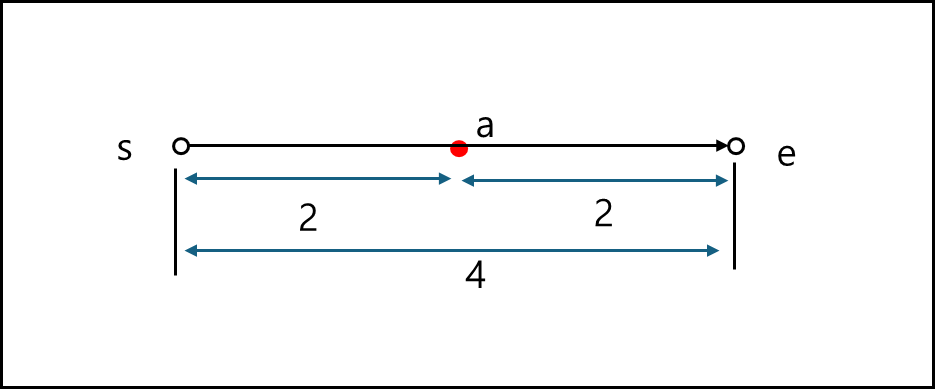
점 a는 각각 s와 e에 대해서 표현할 수 있는데, e는 일단 s에서 e까지 도달 한 뒤에 다시 a로 간다고 계산해야한다.
아니면 그냥 s에서 가는것과 다를바 없기 때문이다. 이를 2차원 좌표평면에 표현하면 아래와 같다.
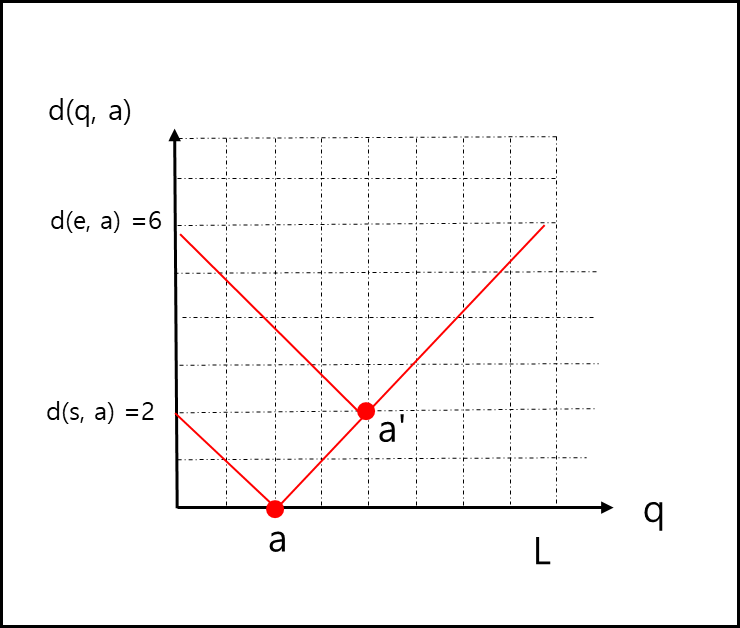
보는 바와 같이 s에서 출발한게 훨씬 거리가 짧다. 짧은 거리로 갈 수 있는 경우가 있을 때 상대적으로 긴 경로는 짧은 경로에 의해 커버된다. 이를 커버 관계라고 하면 그래프에서는 동일한 객체에 대해 거리가 짧은 쪽이 큰 쪽을 커버하게 된다.
4) 예시
예시를 들어서 설명하겠다. 아래와 같은 Roadnetwork가 있다.
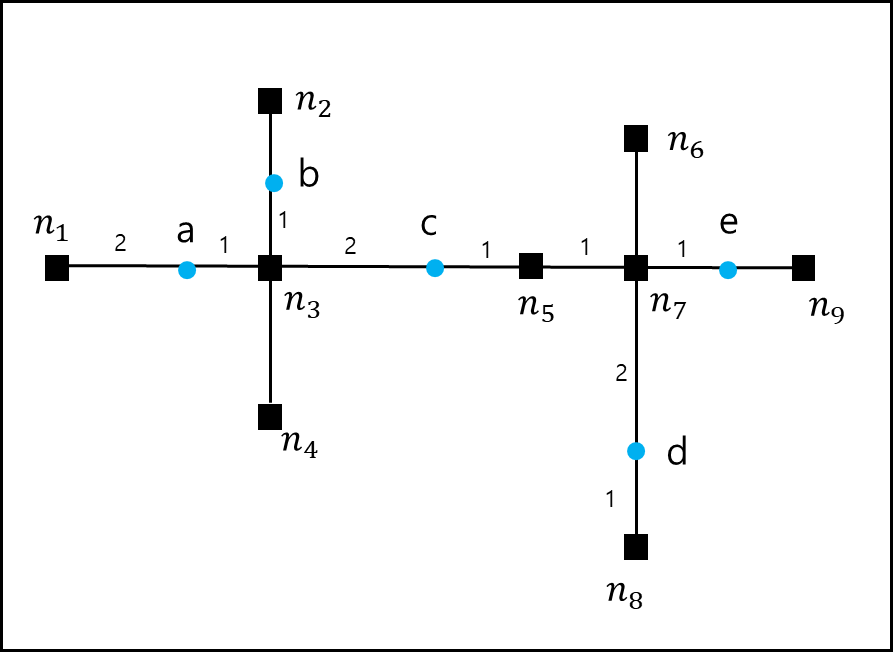
n3 -> n5 -> n7 -> n8까지 도달하는 선분이 쿼리 라인이라고 하고 이에 대해서 obj a~e까지 있다고 하자.
쿼리 라인에 대해 CNN을 구하기 위해서는 먼저 쿼리라인을 분할해야한다. 교차점을 기준으로 쿼리 경로를 부분 경로(subpath)로 분할한다.
이에 서브 경로 SP는 아래와 같이 두개로 분할 된다.
SP1 = {n3,n5,n7}
sp2 = {n7,n8}
서브 경로 SP1,2에 대해서 각각 시작점과 끝점에 대해 NN을 찾는다. 각 SP1의 시작점, 끝점을 $S_{SP1}$, $E_{SP1}$ 라고 할 때 각각의 SP에서 경로 방정식은 아래와 같다.
$S_{SP1}$
d(q,a) = |q|+1
d(q,b) = |q|+1$E_{SP1}$
d(q,c) = |q-4|+2
d(q,e) = |q-4|+1
여기서 최종 결과 집합 R은 아래의 식을 만족해야한다.
\[R_{path} = O_{path} \cup R_{n_{i}} \cup R_{n_{i+1}} \cdots \cup R_{n_{j}}\]경로 상의 Object의 NN로 구해야하므로 아래의 식이 추가된다.
- $O_{SP1}$
d(q,c) = |q-2|
위 값들을 모두 합집합하면 서브 경로 SP1에 대해서 아래와 같이 나타낼 수 있다.
- d(q,a) = |q|+1
- d(q,b) = |q|+1
- d(q,c) = |q-4|+2
- d(q,e) = |q-4|+1
- d(q,c) = |q-2|
여기서 동일 객체에 대한 값이 있는데 |q-2|가 |q-4|+2를 커버하므로 최종 집합은 아래와 같다.
- d(q,a) = |q|+1
- d(q,b) = |q|+1
- d(q,c) = |q-2|
- d(q,e) = |q-4|+1
각각의 수식을 그래프에 그려서 각각의 값이 가까운 범위를 구하면 아래와 같다.
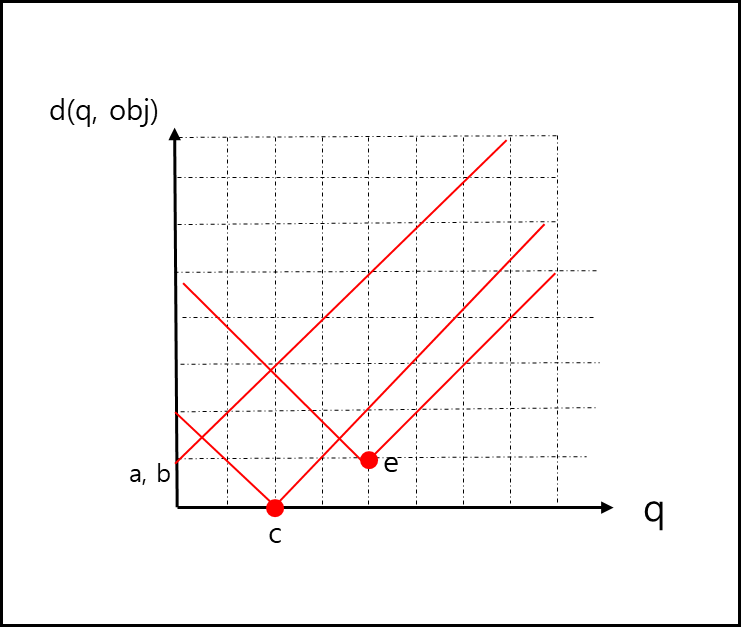
위 그래프를 보면 y 축 값이 가장 작은 그래프만 보면 각 범위와 그 범위에 따른 가장 가까운 점을 구할 수 있다.
범위 I에 대한 각각의 점들은 아래와 같다.
\(I_{1} = \left[ 0, \frac{1}{2} \right] , R_{I_{1}} = \{ a,b \}\)
\(I_{2} = \left[ \frac{1}{2},2 \right] , R_{I_{2}} = \{ c,a \}\)
\(I_{3} = \left[ 2, 4 \right] , R_{I_{3}} = \{ c,e\}\)
집합이기 때문에 순서는 신경쓰지 않는다.
위와 동일한 방법으로 SP2 = {n7,n8} 에 대해서 구하고 커버관계에 의한 중복 제거까지하면 아래의 집합이 나온다.
- d(q,e) = |q|+1
- d(q,d) = |q-2|
위 식에 대해서 그래프를 그리고 동일하게 가장 거리가 가까운 점을 구하면 아래와 같다.
\[I_{4} = \left[ 4, 7 \right] , R_{I_{4}} = \{ d,e\}\]참고자료
- Shashi Shekhar and Sanjay Chawla, Spatial Databases: A Tour, Prentice Hall, 2003
- P. RIigaux, M. Scholl, and A. Voisard, SPATIAL DATABASES With Application to GIS, Morgan Kaufmann Publishers, 2002