기계학습 - Deep learning - 손실함수와 옵티마이저
Deep learning
1. 손실 함수
기대값과 실제값의 차이를 수치화하는 함수이다.
함수의 값이 작아지게 만드는게 딥러닝의 목표이며 이 값은 가중치 w와 편향 b값을 조정함으로써 찾게된다.
손실함수의 종류는 매우 많지만 그 중에 3가지만 이야기해보겠다.
1) 평균 제곱 오차(Mean Squared Error)
이전에 통계학 관련 포스팅 할때 언급한 적이 있는 방법이다. 연속적인 값을 추정하는 회귀문제에서는 자주 쓰이는 방식이다.
다시 한번 간단히 설명하자면 아래와 같은 그래프가 있다고 가정해보자.

한 개의 점에 대한 오차는 실제값에서 예측값을 뺀 값이다.
각 점에 대한 오차는 양수 또는 음수로 나타나는대 부호 통일을 위해서 제곱 해준다.
이후 제곱한 오차 값을 모두 더한 뒤 전체 점 개수로 나눠주면 평균 제곱 오차를 구할 수 있다.
2) 이진 크로스 엔트로피(Binary Cross-Entropy)
분류 문제에서 손실 문제로 자주 쓰는 방식으로 이항 교차 엔트로피라고도 부른다. 대부분 어떤 분류에 속한다 혹은 속하지 않는다에 많이 쓰이는 손실함수이다. 때문에 0과 1사이의 값을 반환하는 시그모이드 함수를 사용한다. 이는 실제값이 0일때 y값이 1일 경우나 실제값이 1이거나 x값이 0일 경우 오차가 커짐을 의미하고 이를 수식으로 나타내면 아래와 같은 로그 함수로 표현 가능하다.
\(if \; y=1 \to cost(H(x),y) = -log(H(x))\) \(if \; y=0 \to cost(H(x),y) = -log(1-H(x))\)
위 수식을 그리면 아래와 같다.
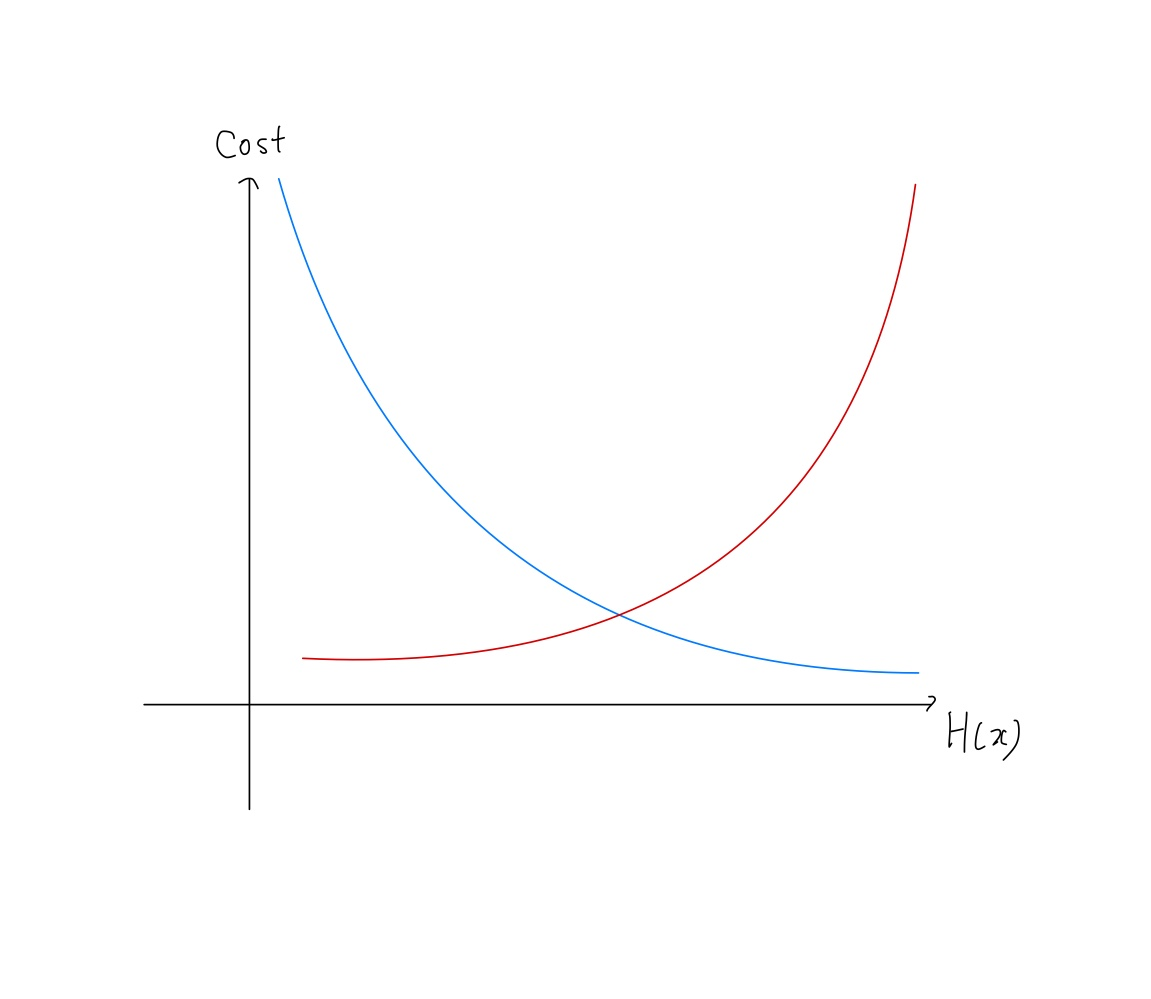
이를 한 점에 대한 오차를 하나의 수식으로 나타내면 아래와 같다.
\[cost(H(x),y) = - \left [ ylogH(x) + (1-y)log(1-H(x)) \right ]\]이를 전체 점에 대한 오차로 바꾸어 목적 함수로 바꾸면 아래와 같다.
\[-\frac{1}{n}\sum_{i=1}^{n}\left [ y_{i}logH(x_{i}) + (1-y_{i})log(1-H(x_{i})) \right ]\]3) 카테고리칼 크로스 엔트로피(Categorical Cross-Entropy)
범주형 교차 엔트로피라고도 부르는 손실 함수이며 다중 분류를 할때 사용하는 방식이다. 위의 이진 크로스 엔트로피와 크게 다르지 않다.
k개의 클래스가 있을 때 j는 실제 값의 항목 인덱스, $p_{j}$는 샘플 데이터가 j번째 클래스일 확률을 말할때 항목 한 개에 대한 오차는 아래와 같다.
\[cost = -\sum_{j=1}^{k}y_{j}log(p_{j})\]그렇다면 전체 항목에 대해 오차 평균을 낸다고 하면 아래와 같다.
\[cost = -\frac{1}{n}\sum_{i=1}^{n}\sum_{j=1}^{k}y^{i}_{j}log(p^{i}_{j})\]2. 옵티마이저
위에서 언급한 손실 함수의 값을 줄여주는 최적화를 해주는 방식이다.
※ 배치(Batch) 손실 함수의 값이 줄여나가는 것이 학습의 요지이다. 이때 이용되는 개념이 배치(Batch)이다.
가중치 등 매개 변수의 값을 조정하기 위해 사용하는 데이터의 양을 뜻하는 것으로 경사하강법 1회에 사용되는 데이터의 묶음 양이다.
1) 배치 경사 하강법(Batch Gradient Descent)
전체 데이터를 1 batch로 두고 한번의 학습을 하는 것을 말한다.
전체를 가지고 학습을 하기에 시간이 오래 걸리며, 메모리도 크게 요한다.
2) 배치 크기가 1인 확률적 경사 하강법(Stochastic Gradient Descent, SGD)
배치 크기가 1인 확률적 경사 하강법은 랜덤으로 선택한 하나의 데이터에 대해서만 계산하는 방법이다.
전체를 배치로 두고 학습하는 것보다는 당연히 월등히 적게 걸리게지만 변경 폭이 너무 크고, 정확도가 낮다.
하지만 시간이 월등히 덜 걸리고, 메모리를 적게 요한다는 장점이 있다.
3) 미니 배치 경사 하강법(Mini-Batch Gradient Descent)
위의 두 가지의 장점을 취합해서 만든 방법이다.
배치 크기를 적절하게 정하여 경사 하강법을 시행한다. 이것도 느려서 아래와 같은 방법들이 나왔다.
※ 그외
모멘텀(Momentum)
SGD에 관성의 개념을 적용한 것으로 이전 이동거리와 관성 계수 m에 따라 파라미터가 변경된다. 일반적으로 m은 0.9를 사용한다.- 아다그라드(Adaptive Gradient, Adagrad)
- 알엔에스프롭(RMSprop)
- 아담(Adam)
※ 본 포스팅은 추가적으로 업데이트 될 예정이다. 내가 제대로 정리한게 맞는지 검증이 필요하다.
참고 자료
- 인공지능 개념 및 응용 3판 Artificial Intelligence Concepts and Applications (2013년) - 도용태, 김일곤, 김종완, 박창현, 강병호 저, 사이텍미디어
- 위키독스 - 딥 러닝을 이용한 자연어 처리 입문
- Machine Learning, Tom Mitchell, McGraw Hill, 1997.
- geeksforgeeks - Type of machine learning
- [312 개인 메모장:티스토리] - Optimizer 의 종류와 특성 (Momentum, RMSProp, Adam)