기계학습 - Deep learning - LSTM, GRU
Deep learning - Recurrent Neural Network
기본적인 형태의 RNN은 바닐라 RNN이라고 부른다. 바닐라 RNN의 경우 시퀀스가 길어질수록 성능이 떨어지는 문제를 보였다. 이 문제를 장기 의존성 문제(The problem of Long-Term Dependencies) 라고 하는데 장기 의존성 문제를 해결하기 위한 여러 모델이 나왔다. 이번 포스팅에서는 장기 의존성 문제 해결을 위한 파생형 중 LSTM과 GRU에 대해 알아보겠다.
LSTM과 GRU에 대해 알아보기에 앞서, 바닐라 RNN의 구조를 뜯어보고 가겠다.
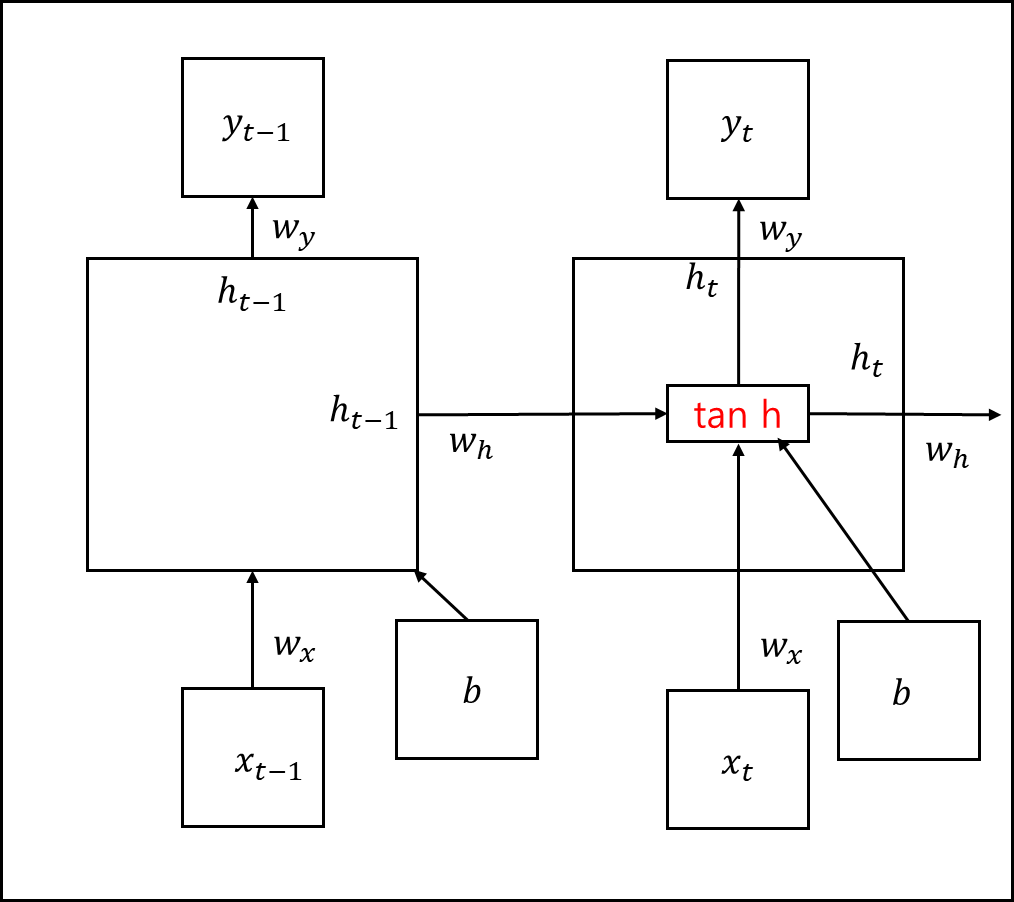
위 은닉 상태의 식을 표현하자면 아래와 같다.
\[h_{t}=tanh(W_{x}x_{t}+W_{h}h_{t-1}+b)\]요컨대 각 뉴런에 대한 입력은 가중치와 곱해지고, 편향은 별도로 더해져
모두 하이퍼볼릭탄젠트 함수를 적용하여 출력된다. 출력된 값은 은닉층의 출력인 은닉상태가 되는 것이다.
위 그림을 보고 아래의 파생형을 보면 이해가 조금 더 잘 될 것이다.
1. 장단기 메모리(Long Short-Term Memory, LSTM)
바닐라 RNN의 경우에는 단순히 하이퍼볼릭 탄젠트 함수만 적용했다면, 장단기 메모리의 경우 각 모듈별로 나뉘어 각 모듈이 수행하는 역할이 생긴 형태이다.
은닉층에 입력게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 정보를 지우고 기억해야할 것을 정해서 남기는 것이다.
계산 자체는 바닐라 RNN보다 복잡해졌지만 긴 시퀀스의 입력을 처리하는데 탁월한 성능을 보인다.
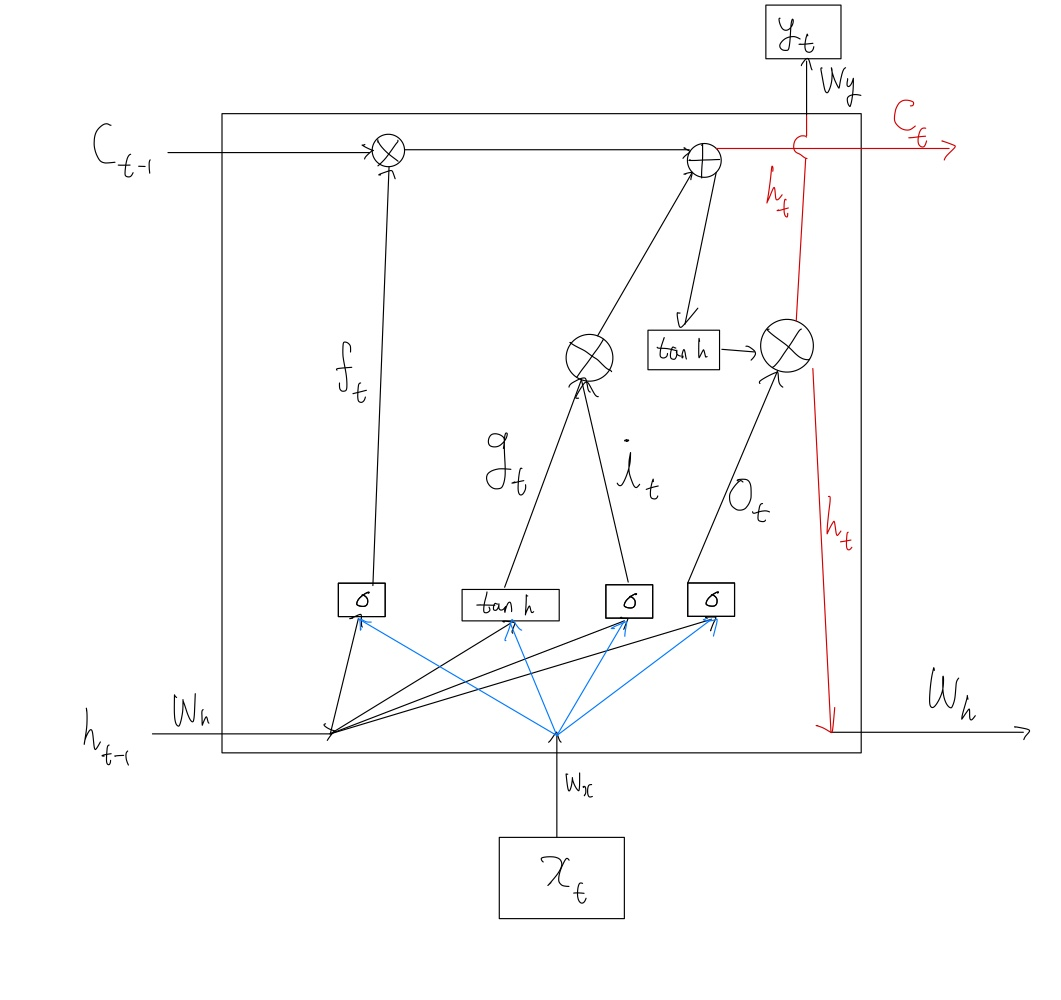
그림에서는 표시할게 너무 많아서 편향에 대한 것은 수식에만 넣어두었다. 수식을 정리하기에 앞서 미리 알아야할 것들을 정의해두겠다.
- $\sigma$ 는 시그모이드 함수이다.
- $tanh$ 는 하이퍼볼릭탄젠트 함수이다.
- $W_{xi},W_{xg},W_{xf},W_{xo}$는 $x_{t}$와 함께 각 게이트에서 사용되는 4개의 가중치이다.
- $W_{hi},W_{hg},W_{hf},W_{ho}$는 $h_{t-1}$ 와 함께 각 게이트에서 사용되는 4개의 가중치이다.
- $b_{i},b_{g},b_{f},b_{o}$ 는 각 게이트에서 사용되는 4개의 편향이다.
1) 입력 게이트
현재 정보를 기억하기 위한 게이트이다.
\(i_{t} = \sigma(W_{xi}x_{t}\)
\(g_{t}=tanh(W_{xg}x_{t}+W_{hg}h_{t-1}+b_{g})\)
2) 삭제 게이트
기억을 삭제하기 위한 게이트이다.
\[f_{t} = \sigma(W_{xf}x_{t}+W_{hf}h_{t-1}+b_{f})\]3) 셀 상태
여기서 원 안에 x 모양의 그림과 원 안에 + 모양의 그림이 있는데 각각 원소별 곱과 원소별 합을 말한다. 두 행렬이 있을 때 같은 위치의 성분끼리 곱하거나 더하는 것을 뜻한다.
\[C_{t}=f_{t} \bigotimes_{}^{} C_{t-1} + i_{t} \bigotimes_{}^{} g_{t}\]4) 출력 게이트와 은닉 상태
현재 시점 t의 은닉 상태를 결정하는 일에 쓰이게 된다.
\(o_{t} = \sigma(W_{xo}x_{t}+W_{ho}h_{t-1}+b_{o}\)
\(h_{t}=o_{t} \bigotimes_{}^{} tanh(c_{t})\)
2. 게이트 순환 유닛(Gated Recurrent Unit, GRU)
GRU에는 업데이트 게이트와 리셋 게이트 두 가지만 존재한다. 때문에 계산 자체는 LSTM에 비해서 빠르지만 성능은 비슷하다고 알려져있다.
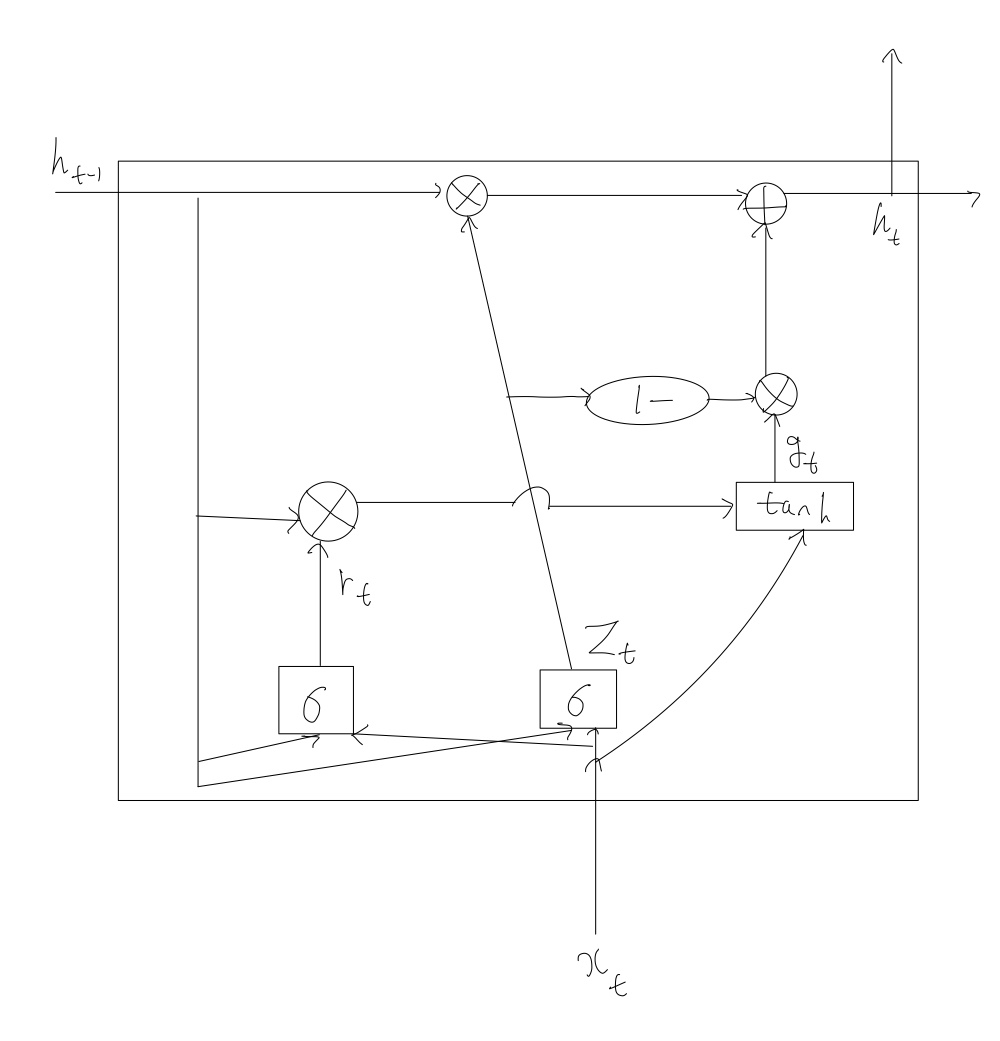
\(r_{t}=σ(W_{xr}x_{t}+W_{hr}h_{t-1}+b_{r})\) \(z_{t}=σ(W_{xz}x_{t}+W_{hz}h_{t-1}+b_{z})\) \(g_{t}=tanh(W_{hg}(r_{t} \bigotimes_{}^{} h_{t-1})+W_{xg}x_{t}+b_{g})\) \(h_{t}=(1-z_{t}) \bigotimes_{}^{} g_{t}+z_{t}∘h_{t-1}\)
※ 본 포스팅은 추가적으로 업데이트 될 예정이다. 내가 제대로 정리한게 맞는지 검증이 필요하다.
참고 자료
- 위키독스 - 딥 러닝을 이용한 자연어 처리 입문
- Sepp Hochreiter, Jurgen Schmidhuber, “LONG SHORT-TERM MEMORY”, Neural Computation 9(8):1735-1780, 1997
- Kyunghyun Cho et al, “Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation”