문자열 검색 알고리즘
문자열 검색 알고리즘
말 그대로 주어진 텍스트에서 특정 문자열을 찾는 알고리즘에 대한 간단한 포스팅을 할까한다.
찾아보니까 문자열 탐색 알고리즘은 좀 많고, 컴파일러에서 쓰이는 오토마톤 기반 매칭도 있지만 그런것들은 제외하고 단순구현, KMP, Boyer-Moore 방식만 포스팅해보도록 하겠다.
1. 단순 구현
사실 어떤 문제가 주어지면 가장 먼저 해볼 것은 가장 무식하게 처리하는 방식이다.
단순 구현도 사실상 Brute Force로 검색하는 것이다.
예를 들어 ABCD 라는 텍스트에서 DC라는 문자열을 단순 구현으로 검색하려고한다면 아래와 같은 과정을 거쳐야한다.
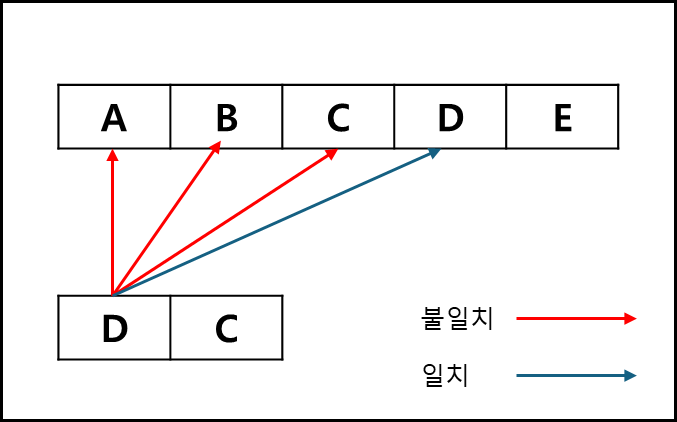
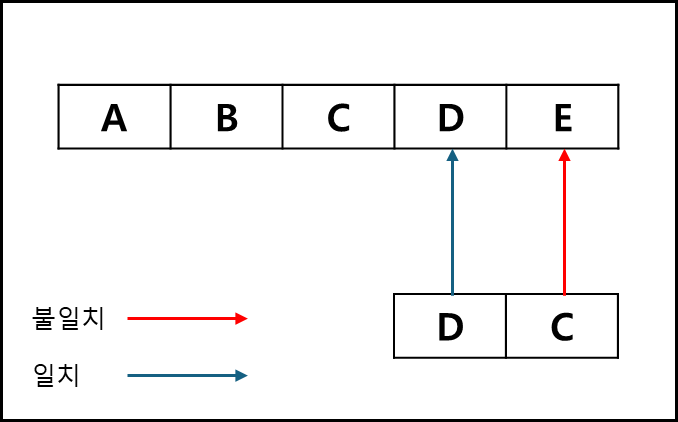
어떤 텍스트 A의 길이가 M이고, 찾으려는 문자열 B의 길이가 N이라면 최악의 경우 O(MN)만큼 시간이 걸릴 수 있다. 각각의 텍스트 문자에 대해서 찾으려는 문자열의 처음부터 끝까지 탐색해야하기 때문이다.
2. KMP 알고리즘
Donald Knuth, James Morris, Vaughan Pratt가 1977년에 개발한 알고리즘이다. 불일치가 발생했을 때 패턴 자신에 포함된 정보를 이용하여 최적의 이동 거리를 계산한다. 불일치 지점의 문자 이전까지 이미 매칭된 부분 문자열의 구조를 분석하여, 건너뛸 수 있는 위치를 결정한다.
이 알고리즘의 핵심은 Failure Function (LPS Array)이다. “Longest Prefix Suffix” 배열을 구하는 것으로 이 배열의 각 위치 i는 패턴의 처음 i개 문자의 prefix가 동시에 suffix인 가장 긴 길이를 저장한다.
여기서 말하는 prefix는 접두사, suffix는 접미사로 패턴 “ABCDE”가 있다면 접두사와 접미사는 아래와 같다.
- 접두사
1 2 3 4 5
A AB ABC ABCD ABCDE
- 접미사
1 2 3 4 5
E DE CDE BCDE ABCDE
패턴 “ABABDABA”이 있을때 LPS 값은 아래와 같다.
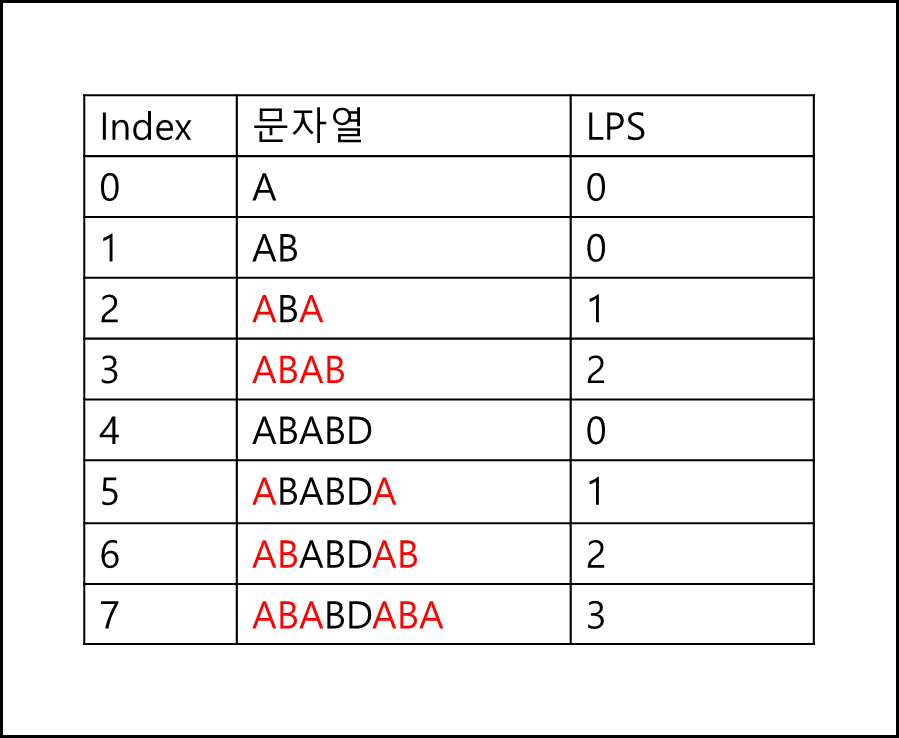
각 길이별 prefix와 suffix의 일치길이를 표로 만들어서 LPS로 표현해놓은 표이다. 만약 텍스트 “ABABDDABABDABA” 에서 패턴 “ABABDABA”를 찾는다고 할 때 아래와 같다.
먼저 문자열 INDEX와 LSP POINTER를 동시에 1씩 증가시켜가며 Pattern과 Text가 같은지 확인한다.
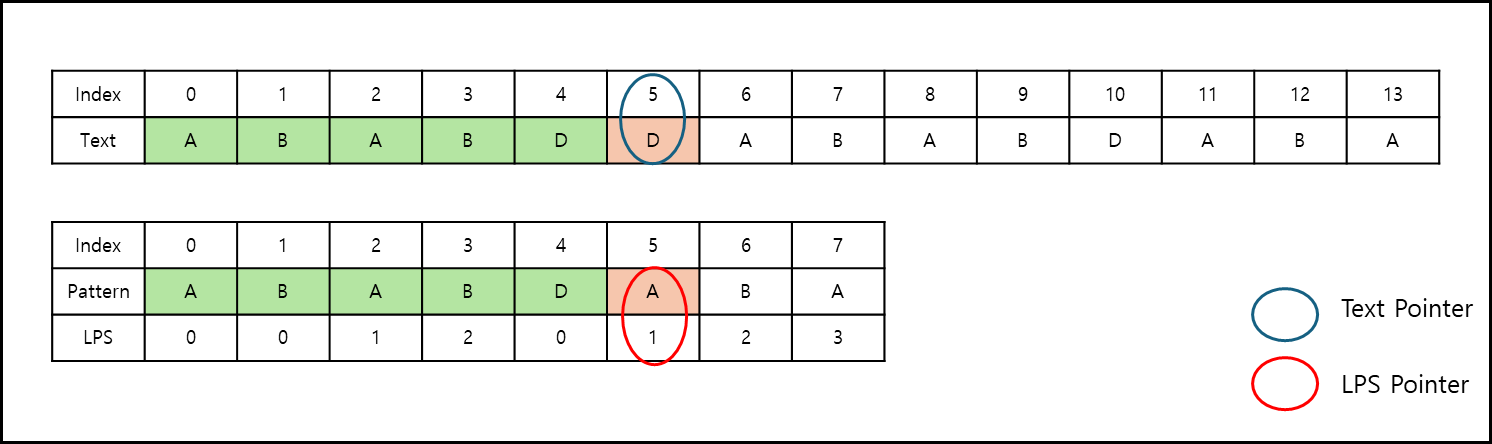
INDEX 5부터 매치가 안되었다. 이때 LSP Pointer는 현재 위치 -1 Index의 값을 가져와서 LSP Pointer를 옮기고 해당 위치의 Pattern 부터 검색하기 시작한다.
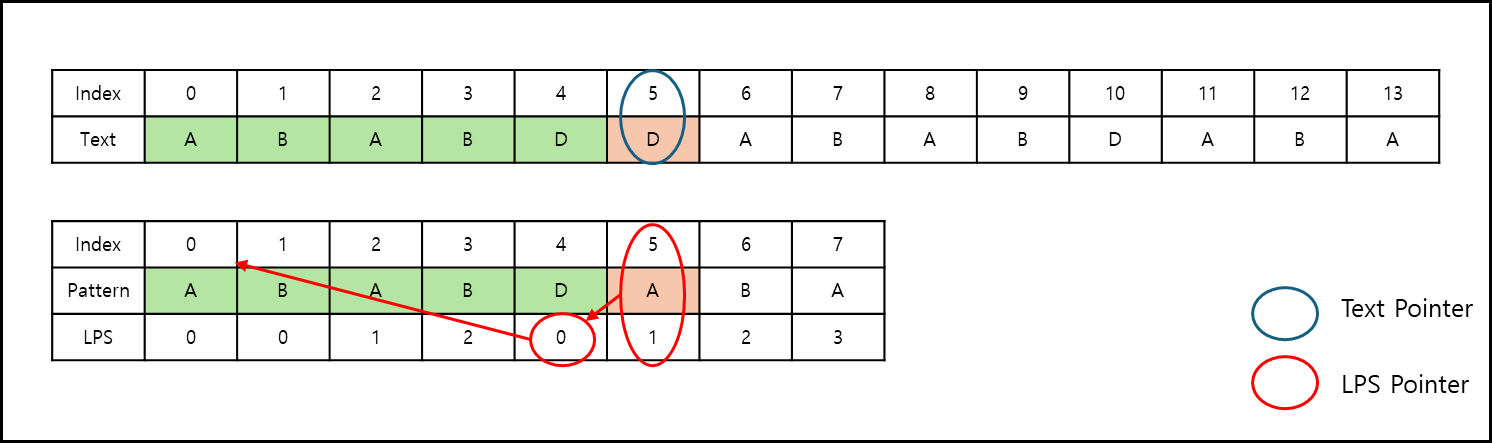
LPS Pointer는 A를 가리키나 현재 텍스트값은 D이다. 맞지 않는데, 이미 LSP Pointer의 Index가 0이므로 Text Pointer를 1 옮긴다.
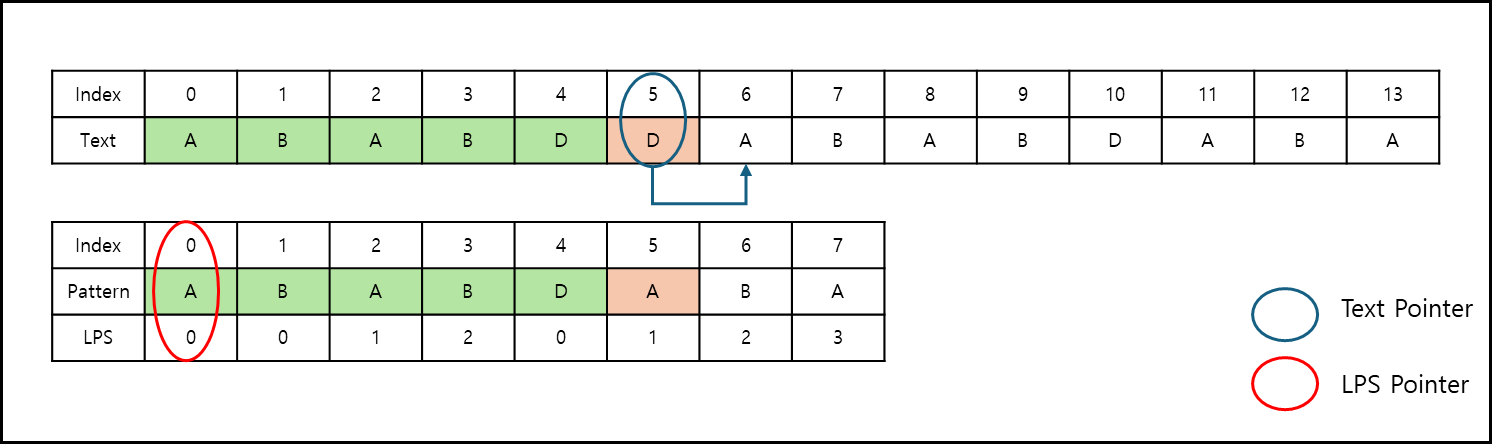
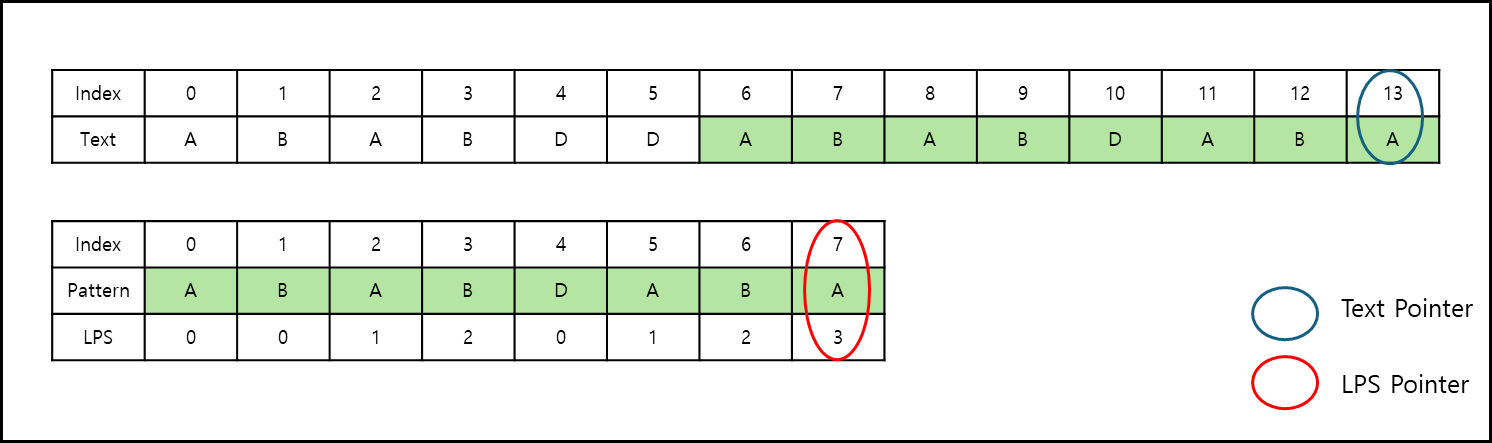
그 뒤부터는 모든 글자가 일치해서 패턴을 찾은 것을 알 수 있다.
3. Boyer-moore 알고리즘
Robert Boyer와 Strother Moore가 1977년에 개발했으며, 실무에서 가장 널리 사용되는 알고리즘이다. 일반적으로 KMP보다 빠른 성능을 보인다.
기본적으로 2가지 휴리스틱을 이용한다.
Bad Character Rule (나쁜 문자 규칙)
불일치가 발생했을 때, 텍스트에서 불일치한 문자가 패턴에 나타나는 가장 오른쪽 위치를 찾아 그곳까지 이동한다.
아래는 그 예시이다.
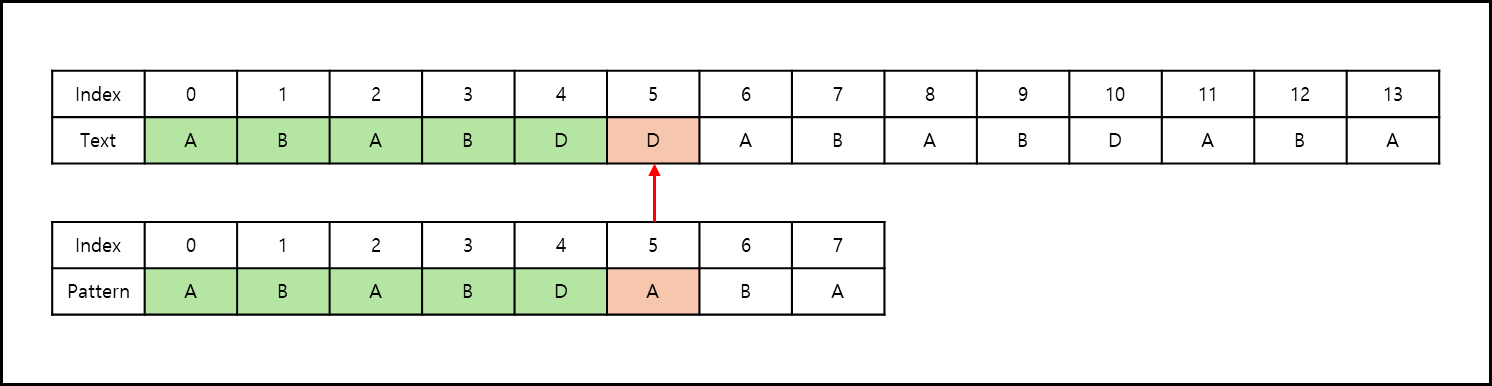
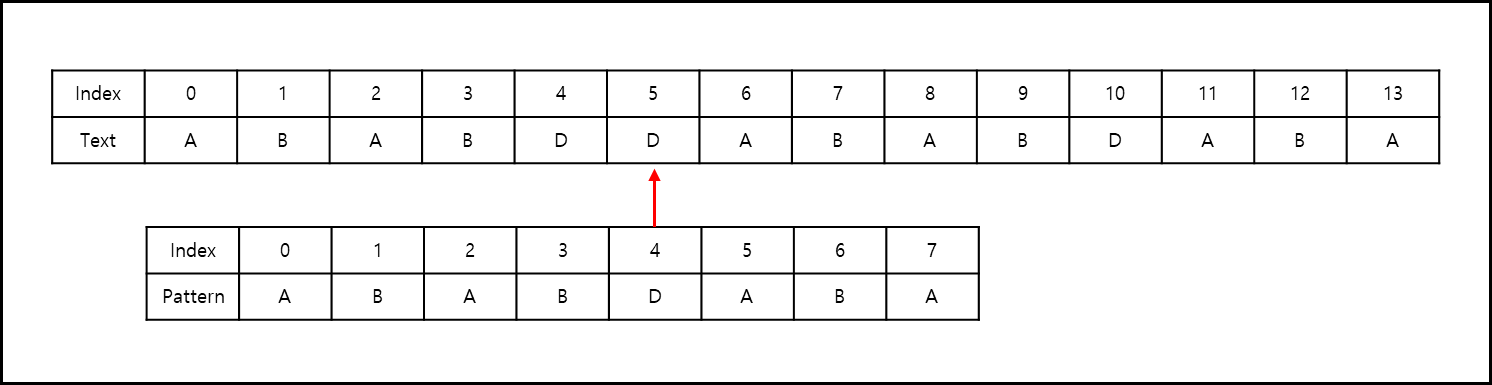
index 5에서 불일치가 일어났다. 불일치 값은 D이므로 패턴중에 가장 오른쪽에 있는 D값을 찾아서 아래의 그림과 같이 땡긴다.
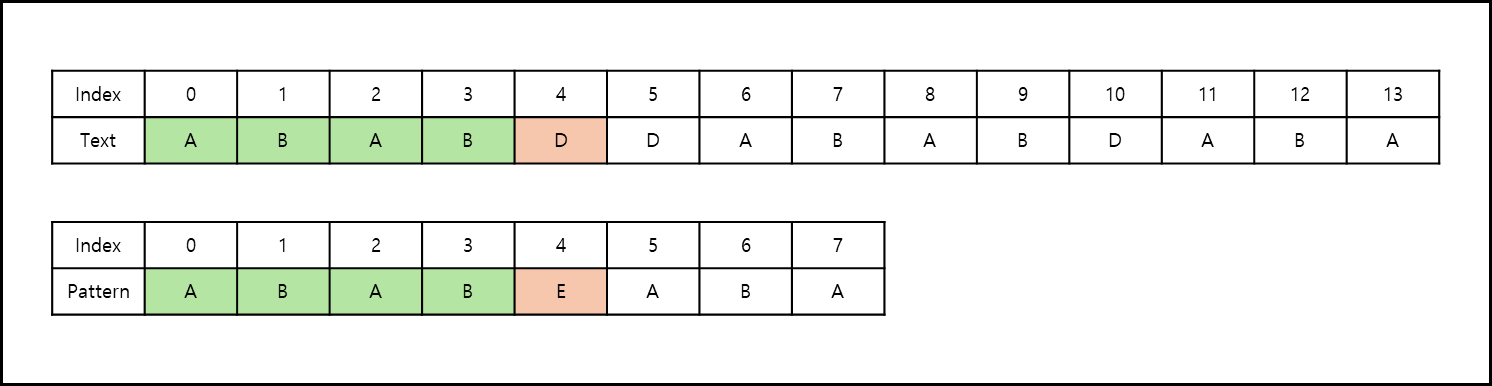
만약 아래와 같이 문자 탐색간 불일치가 일어났으나 불일치한 문자와 동일한 문자가 패턴 내에 없다면
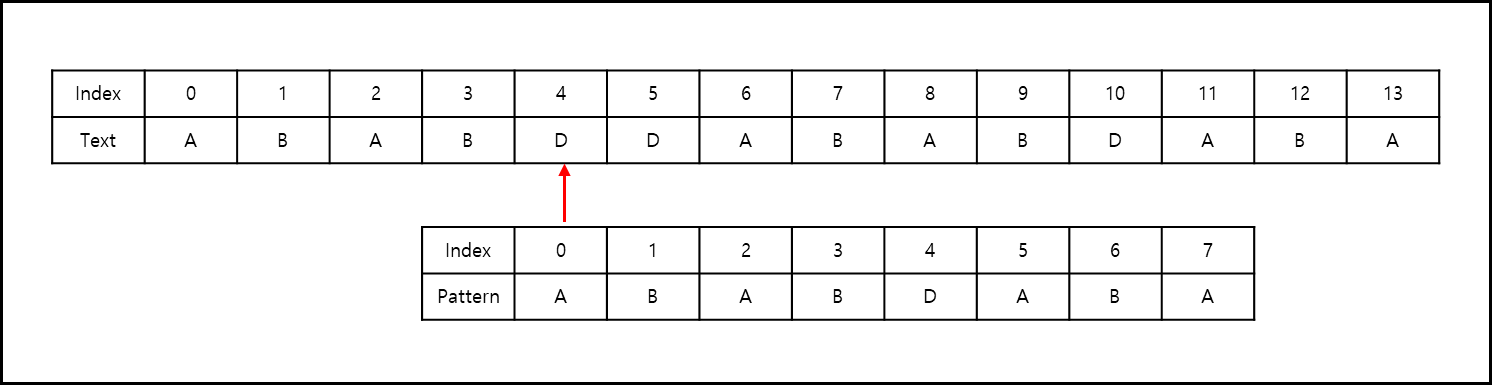
아예 불일치한 문자 뒤로 패턴 index를 넘긴다.
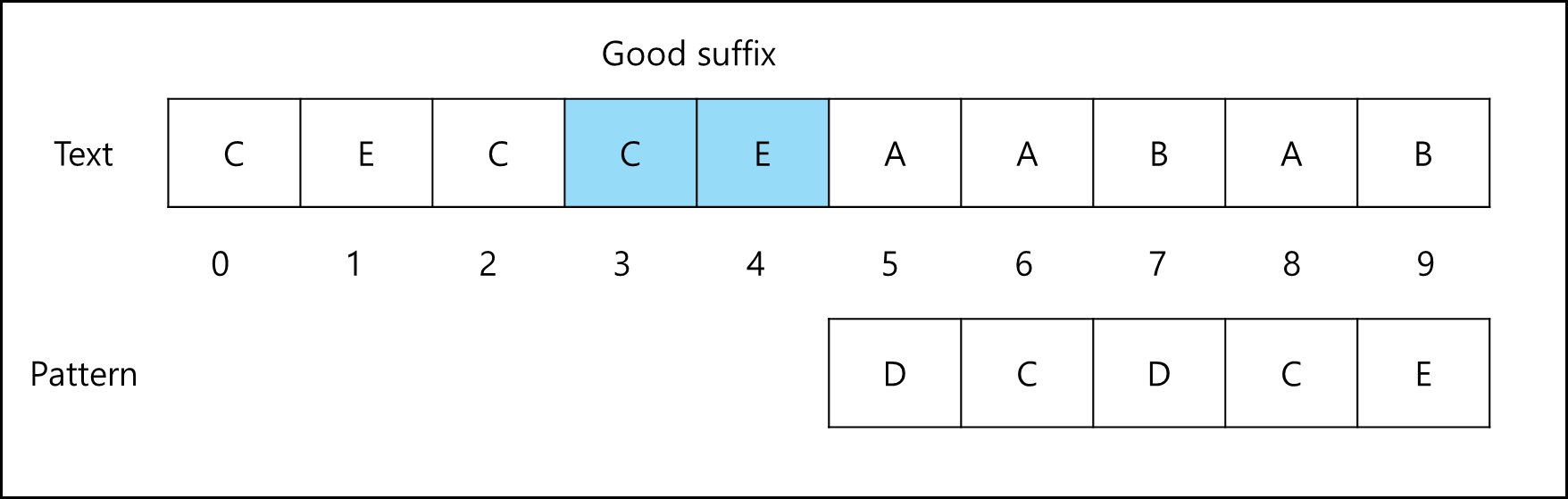
Good Suffix Rule (좋은 접미사 규칙)
좋은 접미사 규칙은 세 가지 경우로 나뉜다.
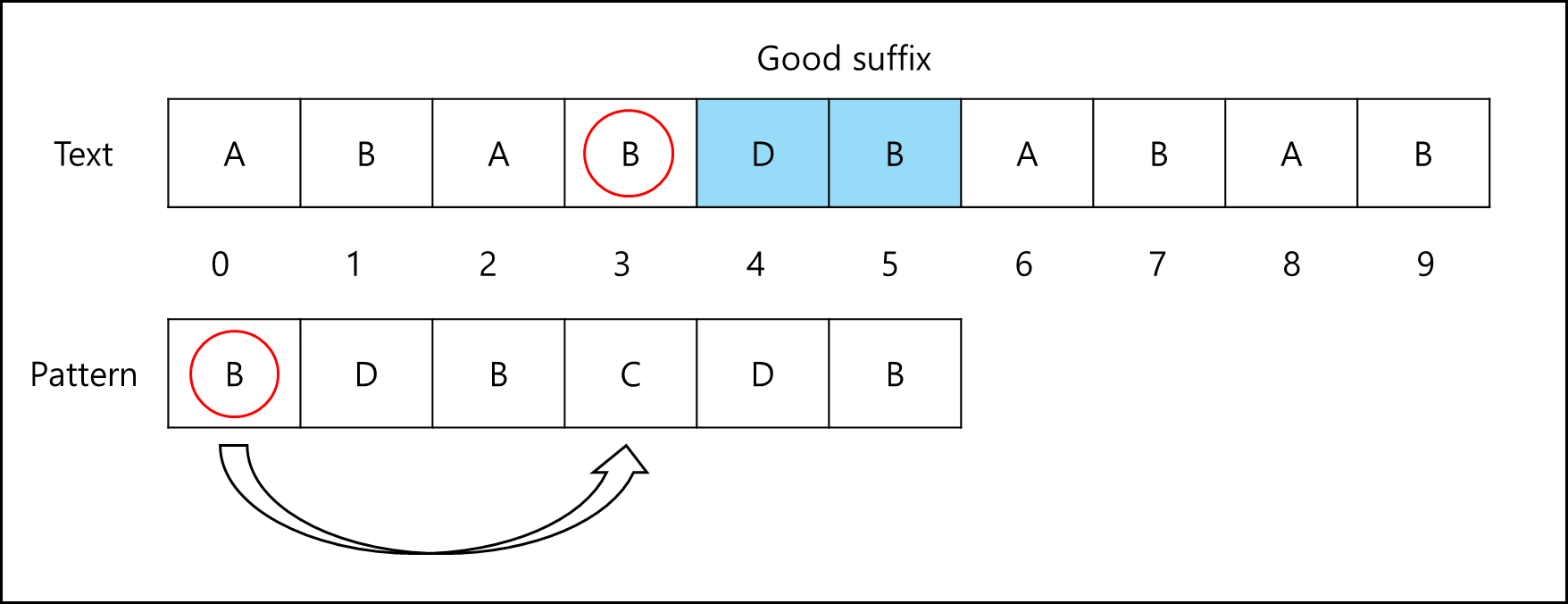
a. Case1. Good Suffix가 패턴의 다른 곳에도 있는 경우
다른 곳에 있는 일치하는 패턴 문자를 Good Suffix와 일치하도록 패턴을 이동시킨다.
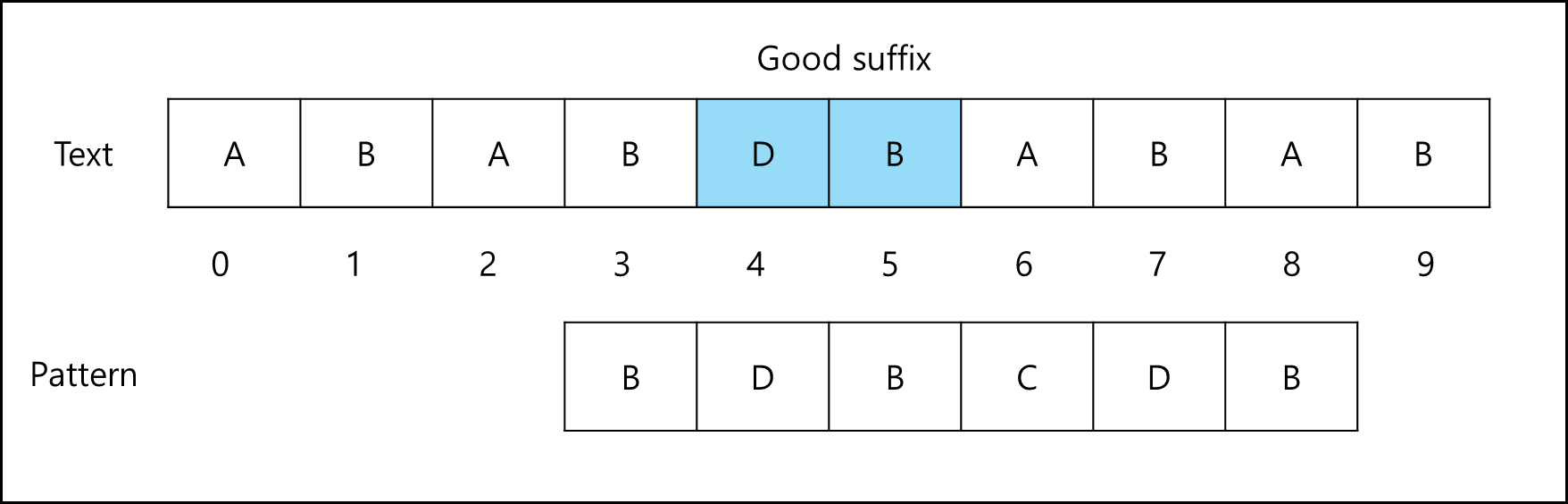
b. Case2. Good Suffix의 일부만 패턴의 시작 부분에 있는 경우
패턴의 접두사 부분을 Good Suffix 부분에 일치하도록 패턴을 이동시킨다.
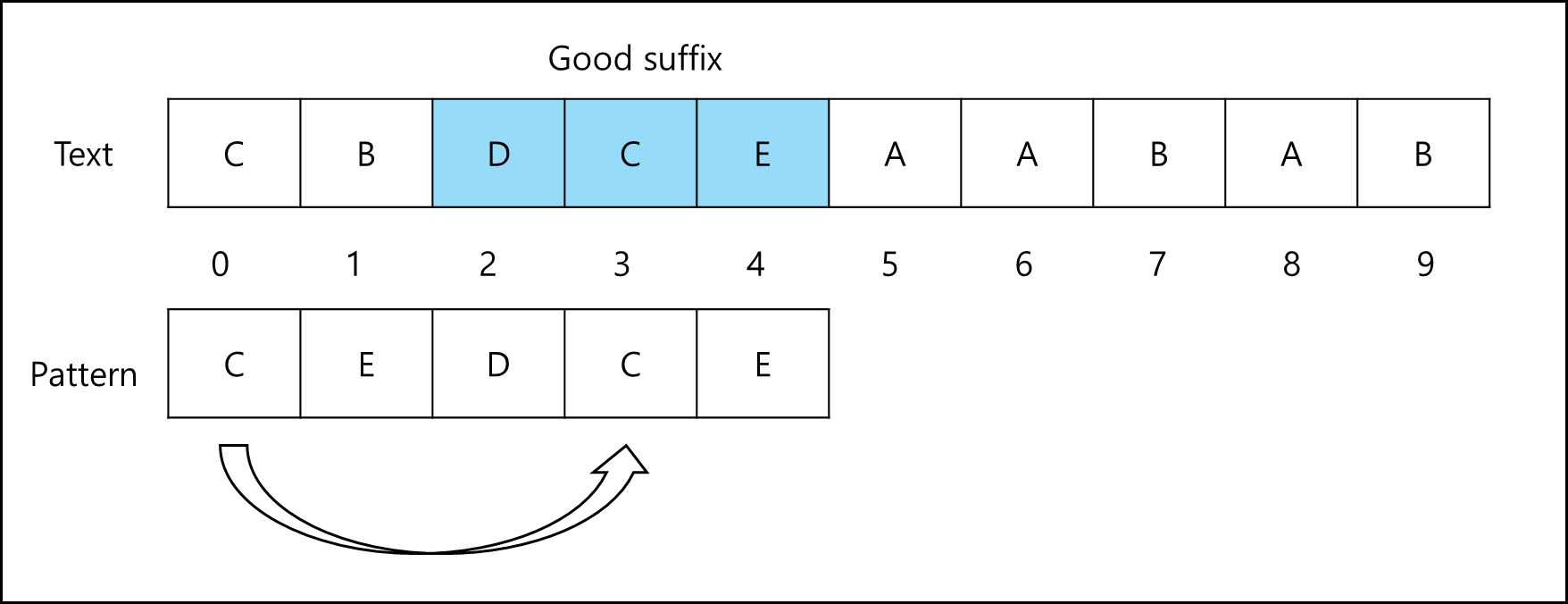
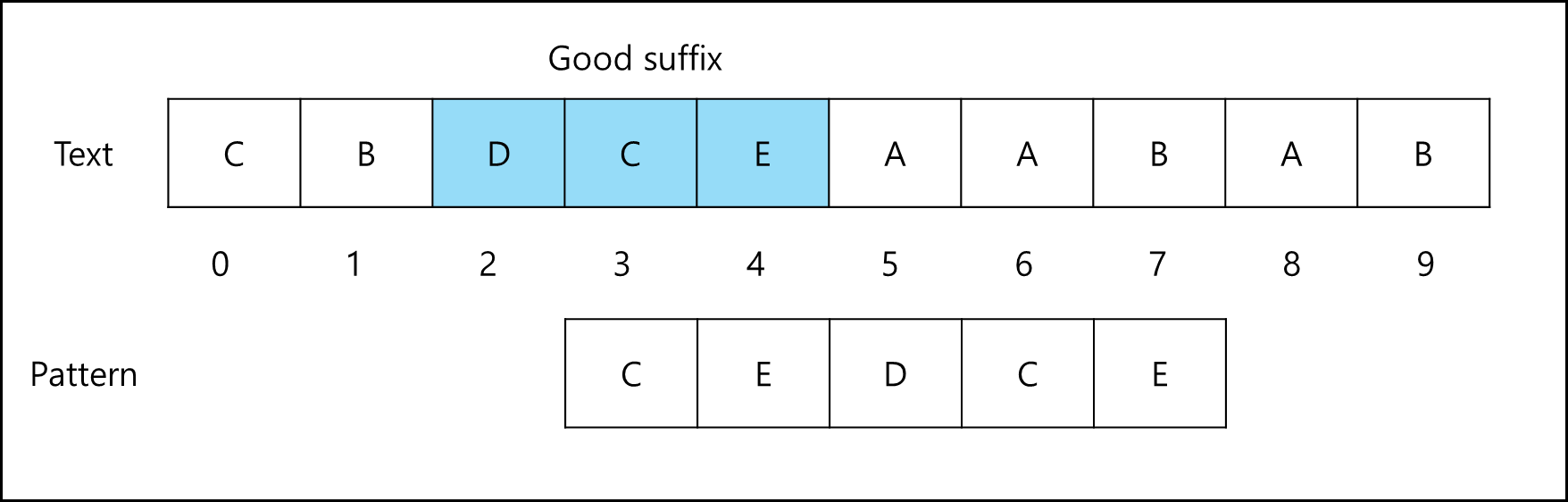
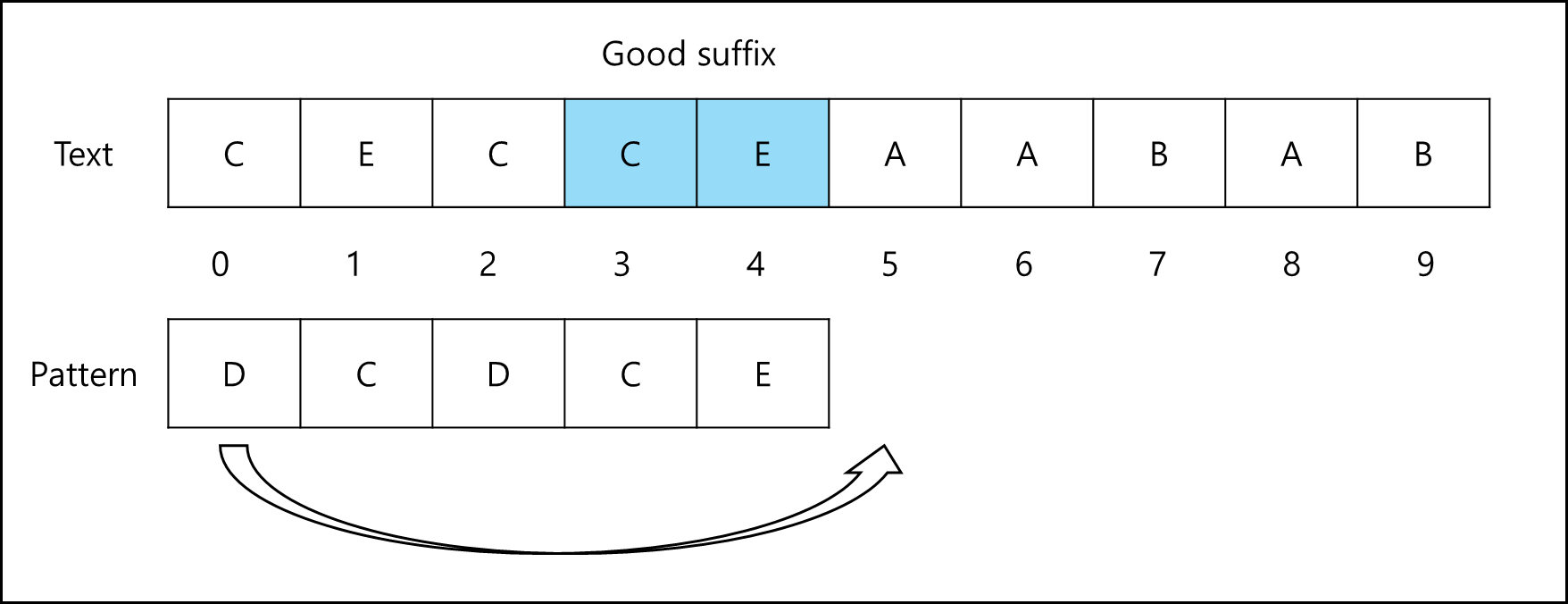
c. Case3. Good Suffix가 패턴의 다른 곳에 없는 경우
패턴을 Good Suffix 이후로 이동시킨다.
※ 추가 업데이트 및 검증 예정이다.