병렬분산컴퓨팅 - Parallel hardware
병렬 분산 컴퓨팅 - Parallel hardware
1. 개요
사실 대부분은 컴퓨터 구조 카테고리에 병렬 처리 및 병렬 처리 - Cache 일치 포스팅에 포함되어있다. 이번 포스팅에서는 해당 포스팅에서 포함되어있지 않은 내용을 커버해 볼 것이다.
2. UMA vs NUMA
1) UMA(Uniform Memory Access)
메모리에 접근하는 시간이 동일(Uniform)한 아키텍처이다.
그림으로 그려보면 아래와 같다.
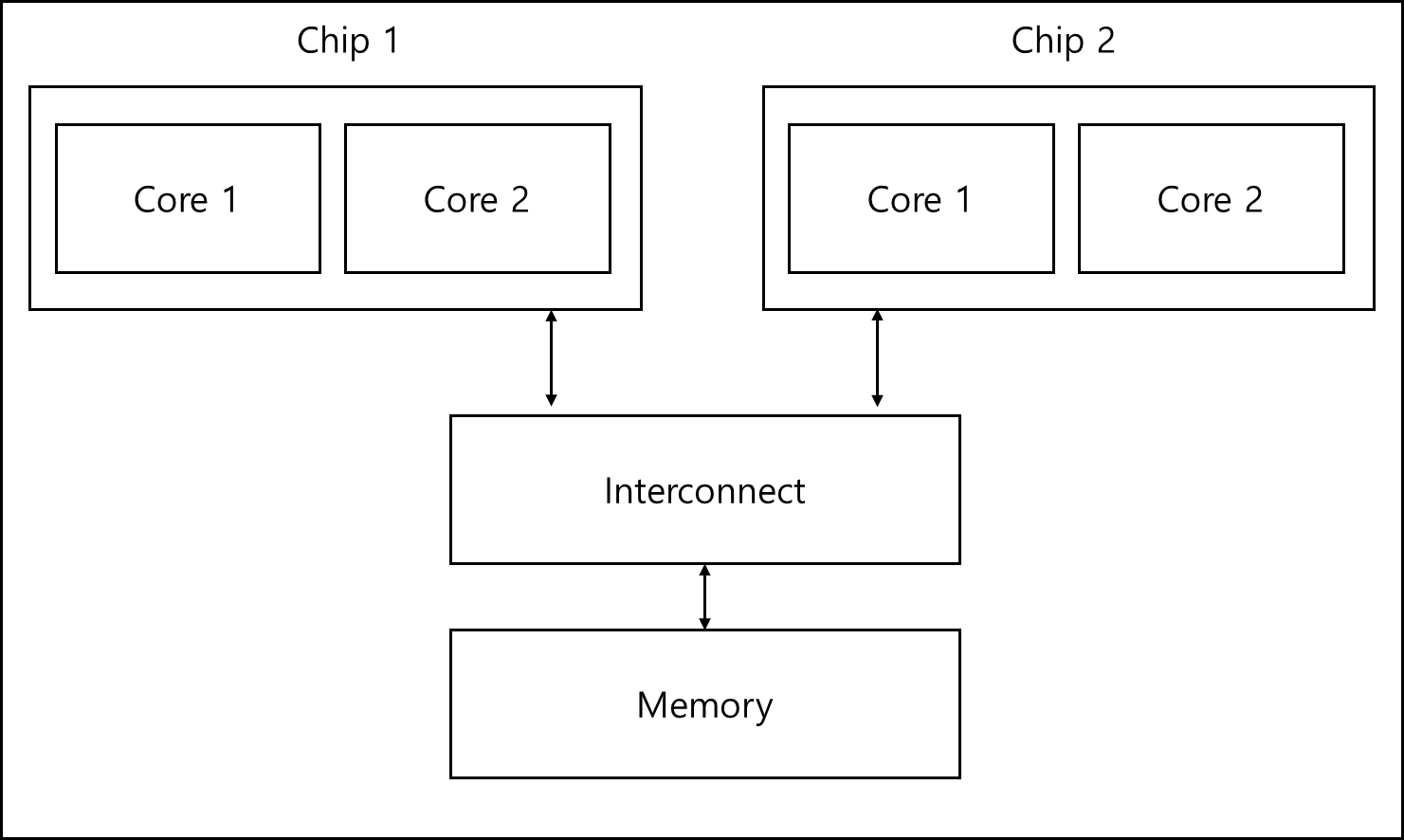
2) NUMA(Non-Uniform Memory Access)
메모리에 접근하는 시간이 동일하지 않은(Non-Uniform)한 아키텍처이다. 그림으로 그려보면 아래와 같다.
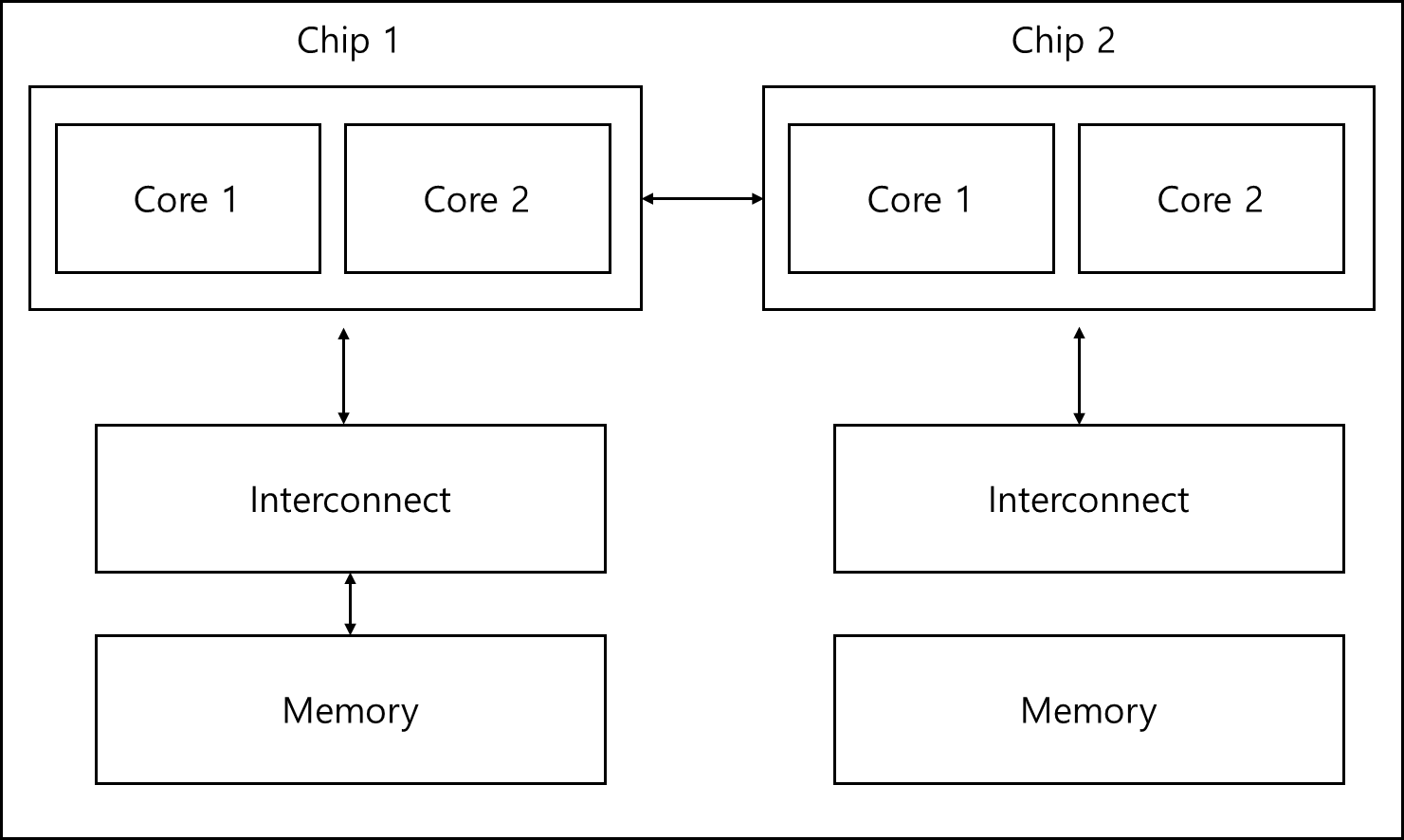
위 그림만 보면 둘다 memory까지 걸리는 시간이 같은 것 같은데? 할 수 있겠지만 오해하면 안된다. chip2 core가 chip1의 메모리에 접근하는 시간은 chip2 core가 chip2 memory에 걸리는 시간과 동일하지 않다.
3. Interconnection Networks
1) Shared Memory Interconnects
프로세서들끼리 Memory를 공유하는 형태의 Interconnects이다.
a. Bus Interconnect
버스에 연결된 장치의 수가 늘어날수록 버스 사용을 위한 경합(contention)이 심해지며, 이로 인해 전체적인 성능이 저하된다. 따라서 버스 인터커넥트는 확장성이 좋지 않다.
b. Switch Interconnect
스위치를 이용할 경우 다른 경로를 통해 통신할 경우 Bus와는 다르게 경합이 일어나지 않는다.
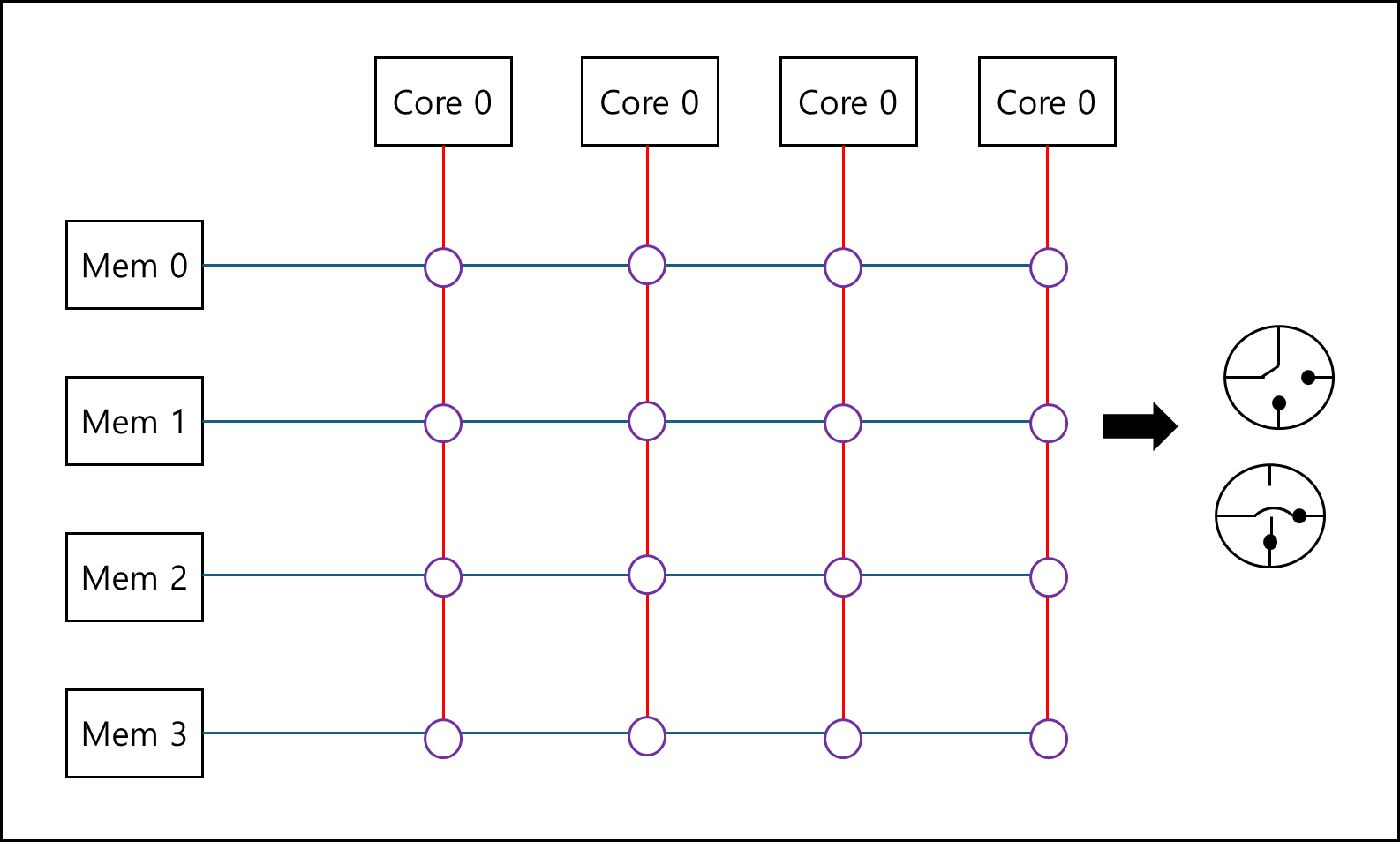
2) Distributed Memory Interconnects
이 방식도 Direct 방식과 Indirect 방식이 있다. 각각 Static 방식과 Dynamic 방식이라고도 한다.
※ Inter-connection의 성능을 측정하는 지표들
① Node degree
한 노드에 연결된 에지(링크)의 수를 의미하며, 즉 한 번의 홉(hop)으로 도달할 수 있는 인접 노드의 수를 나타낸다. 만약 각 노드마다 다르면, 가장 큰 값을 쓴다.
② Diameter
임의의 두 노드 사이의 가장 짧은 경로 중 가장 긴 경로를 의미한다 이는 한 프로세서에서 다른 프로세서로 메시지를 전송할 때 발생하는 최대 지연 시간을 측정하는 척도가 된다
③ Bisection width
네트워크를 동일한 크기의 두 영역으로 나누기 위해 절단해야 하는 가장 적은 링크의 수이다 이는 네트워크의 이등분을 가로지르는 최대 통신 대역폭을 나타내는 지표이다.
※ 데이터 전송 지표
① Latency
데이터 전송 시 소스(Source)가 전송을 시작한 시점부터 목적지(Destination)에서 첫 번째 바이트를 수신하기 시작할 때까지 걸리는 시간이다
② Bandwidth
링크가 데이터를 전송할 수 있는 속도로, 보통 초당 메가비트(Mb/s)나 메가바이트(MB/s) 단위로 표현된다. 목적지에서 첫 바이트를 받은 이후 데이터를 수신하는 속도를 의미하기도 한다
③ Bisection Bandwidth
네트워크를 두 개의 동일한 반으로 나누는 가장 작은 절단면을 가로지르는 대역폭으로, 전체적인 네트워크의 품질을 측정하는 척도이다.
수식으로 환산하면 한 개의 $Bandwidth \time Link$ 이다.
a. Direct
각 프로세서에 스위치가 달려서 다른 프로세서와 직접 연결되는 방식을 Direct(Static) 방식이라고 하며 아래와 같은 방식이 있다.
ⓐ Linear
말 그대로 노드들을 선형적으로 연결해둔 방식이다.
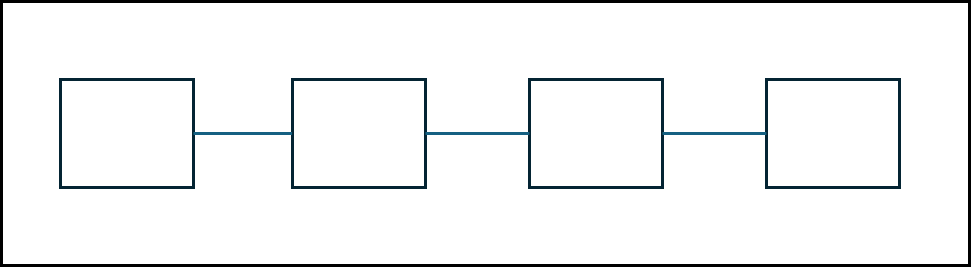
ⓑ Ring
노드들을 원형으로 연결해둔 방식이다.
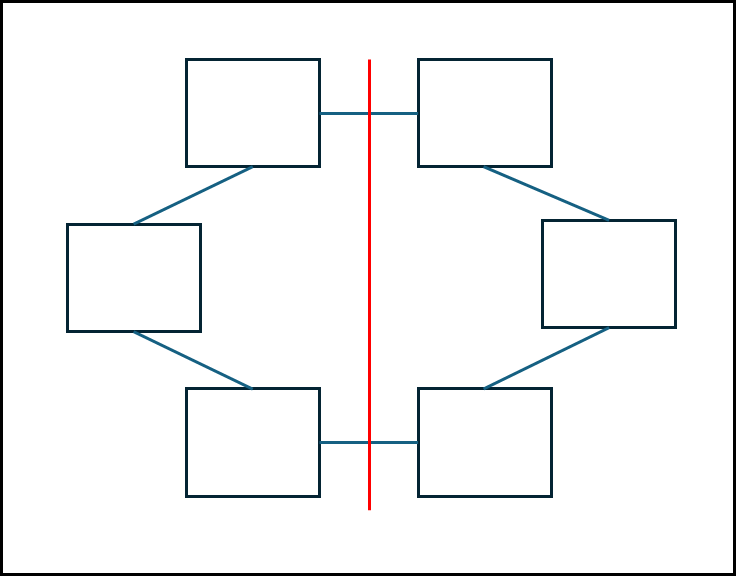
위 그림을 기준으로 Inter-connection의 성능을 측정하는 지표들을 구해보면 아래와 같다.
여기서 N은 Node의 개수이다.
- Node degree = 2 : 각 노드에 연결된 간선은 2개이다.
- Diameter = N/2 후 올림 : 간단히 말해서 가장 멀리 있는 노드로 갈때 필요한 edge의 개수이다.
- Link 개수 = N : Ring으로 만들면 노드 개수 만큼 edge가 필요하다.
- Bisection width = 2 : 붉은 선으로 해당 네트워크를 나누었을 때 붉은 선에 걸리는 edge 개수이다.
ⓒ 2D Mesh
2D 차원 그물 형태로 만들어둔 형태이다. 설명하기 편해서 2D로 둔 것이지, 3D나 4D로 확장이 가능하다.
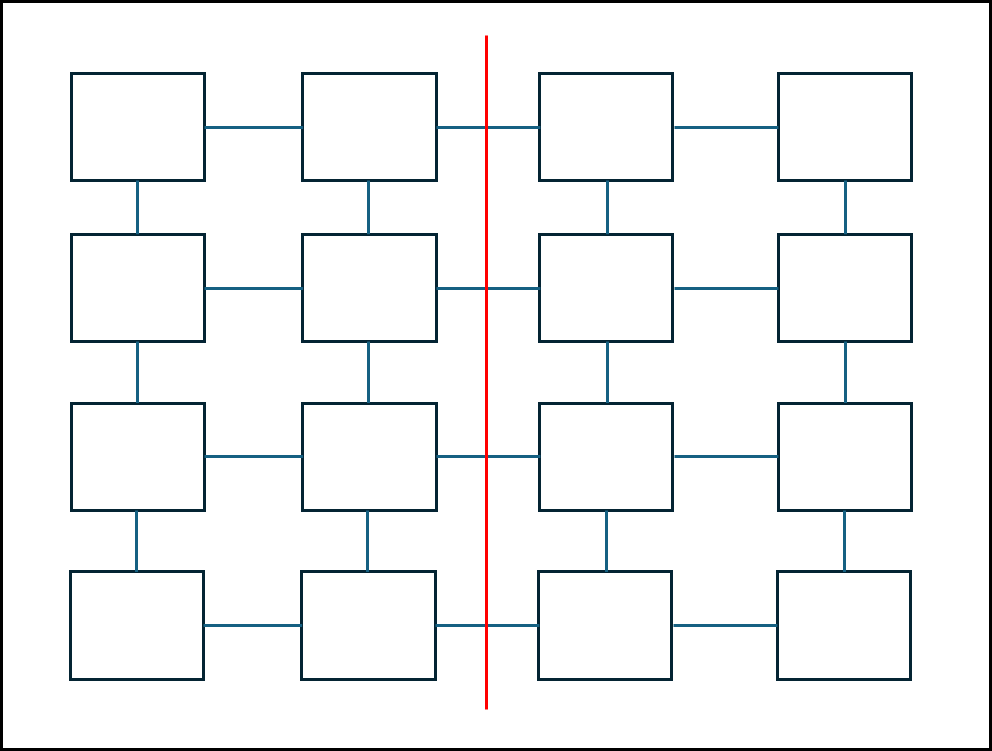
여기서 N은 Node의 개수이다. r는 Node의 제곱근이다.
- Node degree = 4 : 각 노드에 연결된 최대 간선은 4개이다.
- Diameter = 2 X (r-1) : 간단히 말해서 가장 멀리 있는 노드로 갈때 필요한 edge의 개수이다.
- Link 개수 = 2 X (N-r) :
- Bisection width = r : 붉은 선으로 해당 네트워크를 나누었을 때 붉은 선에 걸리는 edge 개수이다.
ⓓ 2D Torus
2D 차원 그물에서 가장 먼 거리까지 edge를 추가한 형태이다. Mesh 구조의 경우 끝과 끝이 연결되어있지않지만 Torus 구조는 끝과 끝이 연결되어있다. 2D Mesh와 마찬가지로 3D, 4D로도 확장이 가능하다.
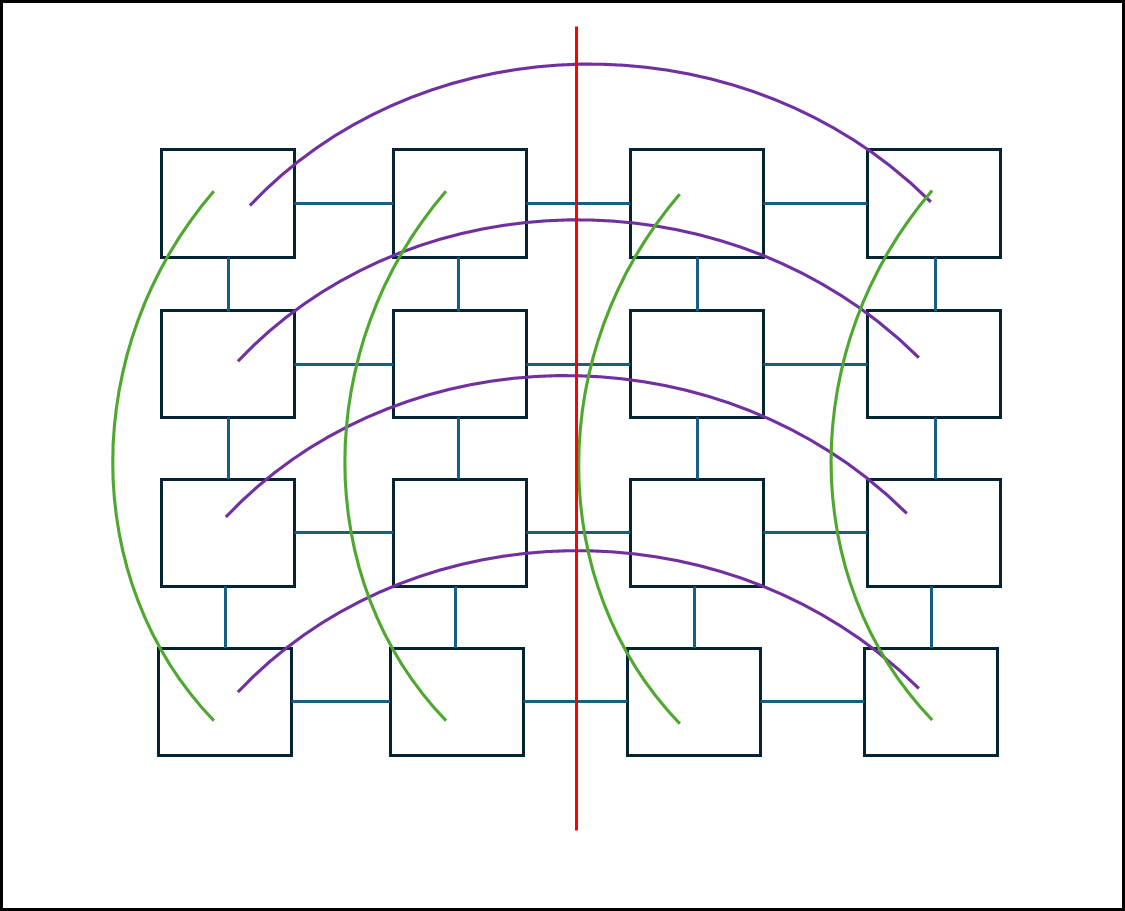
여기서 N은 Node의 개수이다.
- Node degree = 2 : 각 노드에 연결된 최대 간선은 4개이다.
- Diameter = 2 X (r/2)내림: 간단히 말해서 가장 멀리 있는 노드로 갈때 필요한 edge의 개수이다.
- Link 개수 = 2 X N : Ring으로 만들면 노드 개수 만큼 edge가 필요하다.
- Bisection width = 2 X r : 붉은 선으로 해당 네트워크를 나누었을 때 붉은 선에 걸리는 edge 개수이다.
ⓔ Fully connected
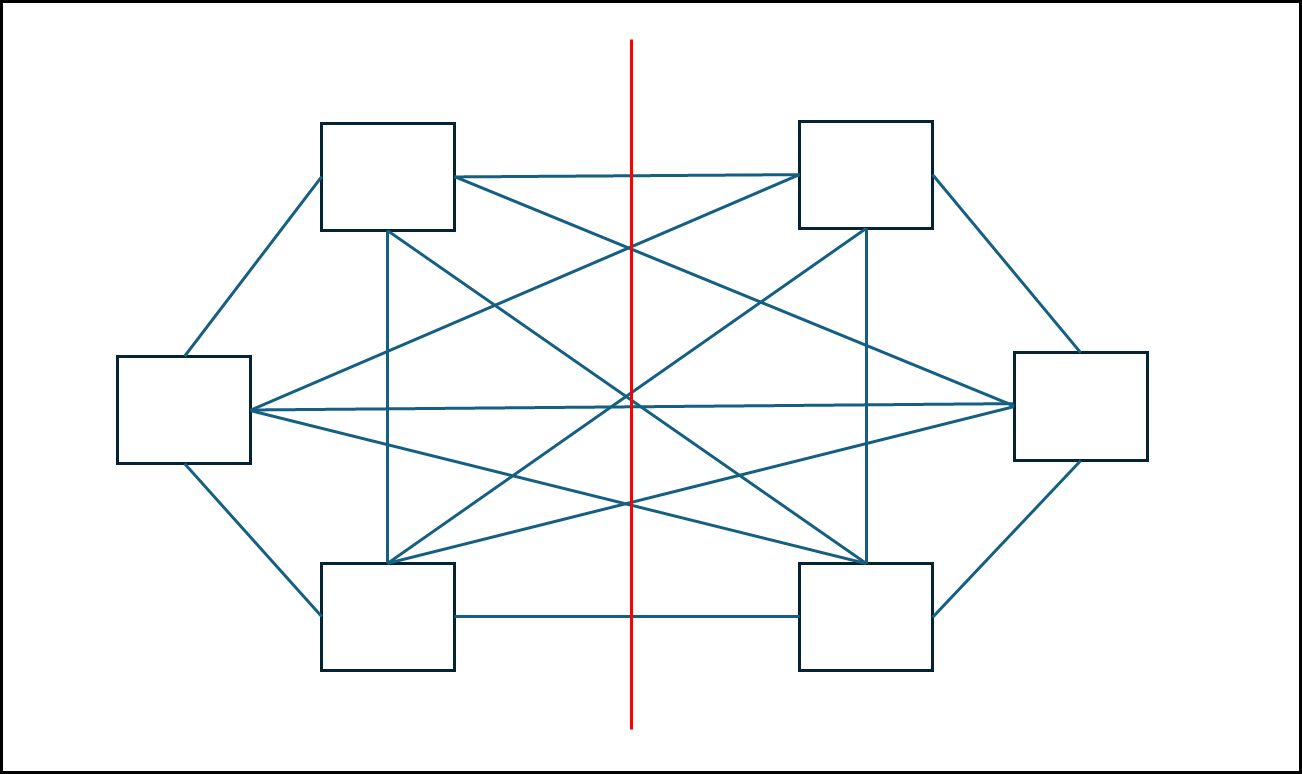
- Node degree = N - 1 : 각 노드에 연결된 최대 간선은 4개이다.
- Diameter = 1 : 간단히 말해서 가장 멀리 있는 노드로 갈때 필요한 edge의 개수이다.
- Link 개수 = N X (N-1)/2 : Ring으로 만들면 노드 개수 만큼 edge가 필요하다.
- Bisection width = $(N/2)^{2}$ : 붉은 선으로 해당 네트워크를 나누었을 때 붉은 선에 걸리는 edge 개수이다.
ⓕ Hypercube
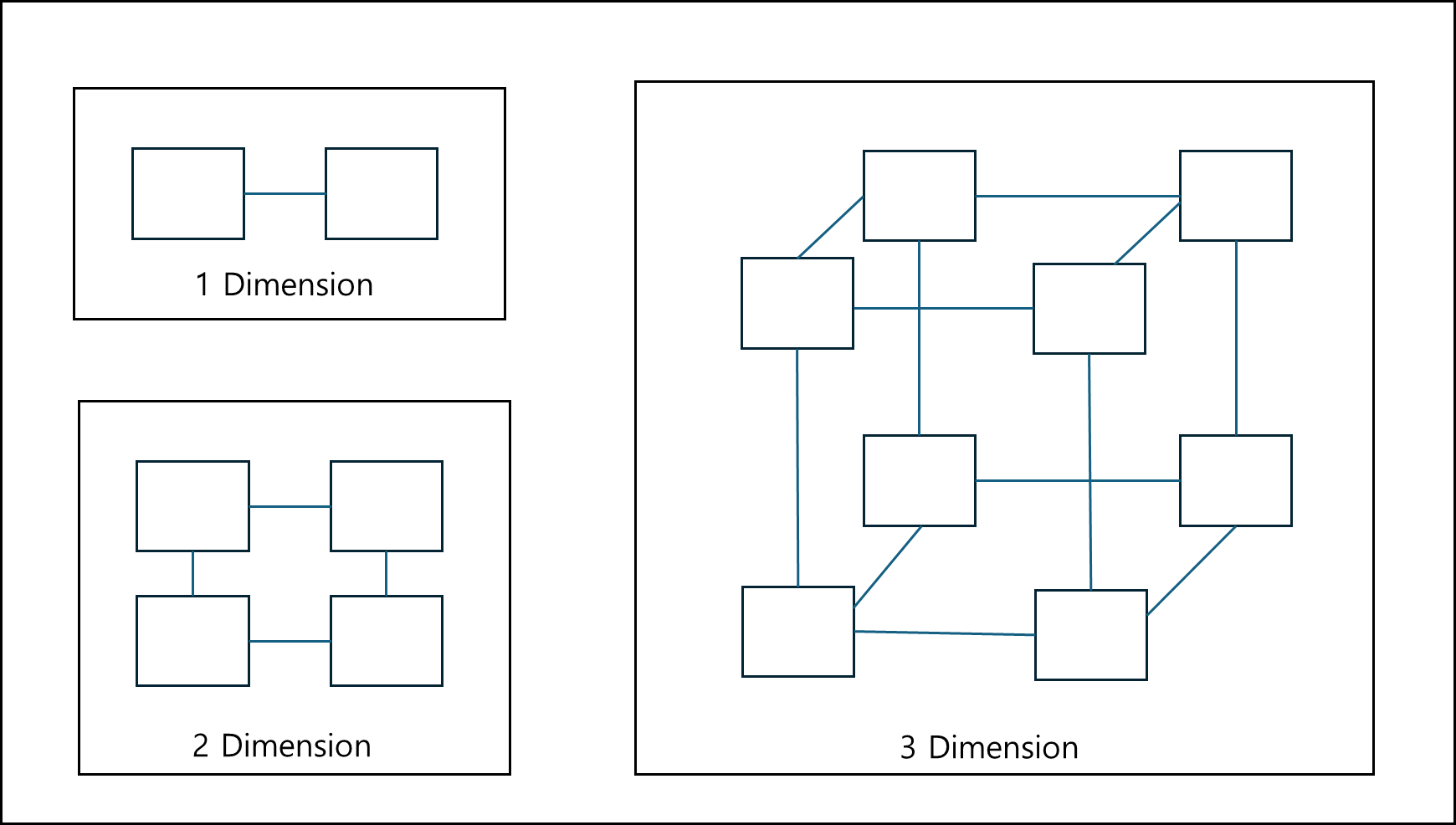
위의 그림은 1,2,3 차원에 대한 Hypercube를 나타낸 것이다.
여기서 차원은 n을 표현하며 N이 노드 개수일때 $n = log_{2}N$ 으로 나타낼 수 있다.
- Node degree = N - 1 : 각 노드의 차수는 차원과 동일하다.
- Diameter = n
- Link 개수 = n X N/2 : 각 노드마다 링크가 n개있고, 노드수가 N인데, 중복 제거를 위해 2를 나눈값이다.
- Bisection width = N/2 : 애당초 Hypercube 자체가 차원이 늘때마다 2배씩 Node가 늘고 2배씩 edge 개수가 늘어난다.
b. Indirect
각 프로세서에 스위치가 직접 달리지 않고 간접적으로 연결되어 다른 프로세서와 통신하는 방식을 Indirect(Dynamic) 방식이라고 하며 아래와 같은 방식이 있다
ⓐ Crossbar switch
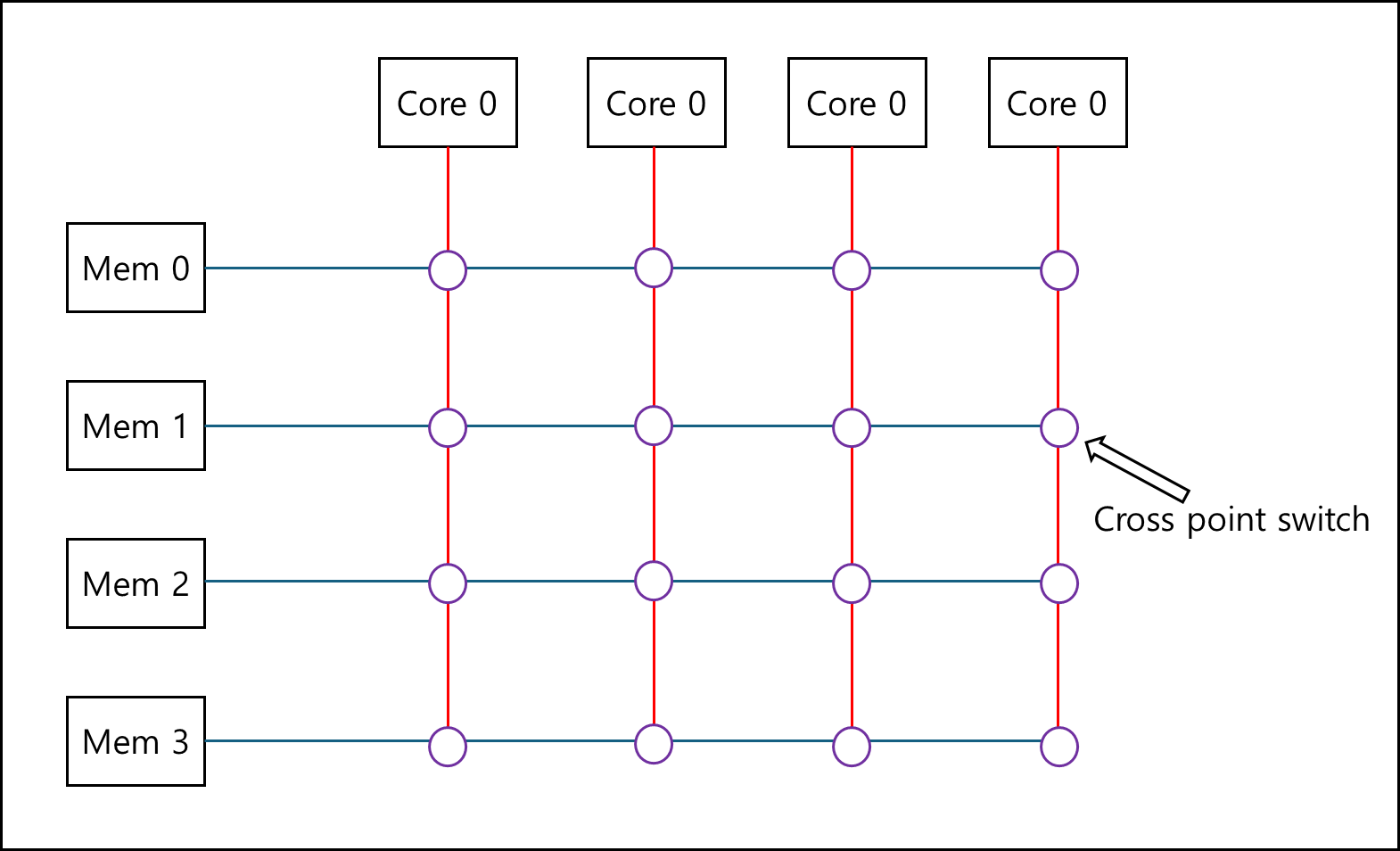
Shared Memory 방식과 크게 다르지 않다. 하지만 이 경우 스위치 개수가 너무 많이 필요하기 때문에 가격이 높다
ⓑ Omega switching system
스위치를 덜 쓰고, 좋은 성능을 위한 system이다. 아래의 그림을 보자.
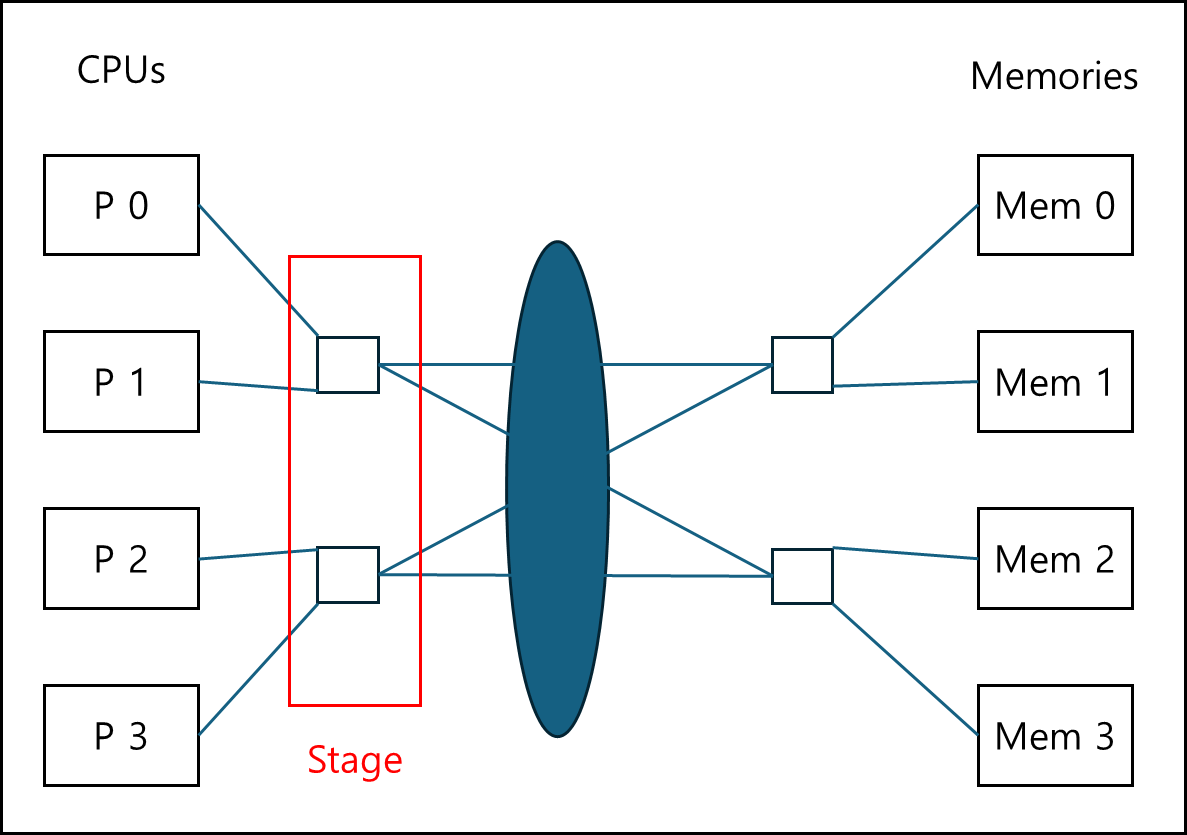
각 스위치 마다 2개씩 source, 즉 cpu(Node)가 붙고 각 스위치는 다른 스위치로 연결되어 있는 형태이다.
이를 세로로 살펴보면 스위치로만 이루어진 일종의 layer를 볼 수 있는데, 이를 stage라고 한다.
Node를 N개라고 할때 이 Stage에 포함된 switch 개수는 N/2개이다.
stage 층의 개수는 $log_{2}N$개이다. 즉, Node 개수가 N개일때 총 필요한 switch의 개수는 $Log_{2}N \times \frac{n}{2}$ 이다.
각 스위치는 아래와 같이 총 4개의 상태를 갖는다.
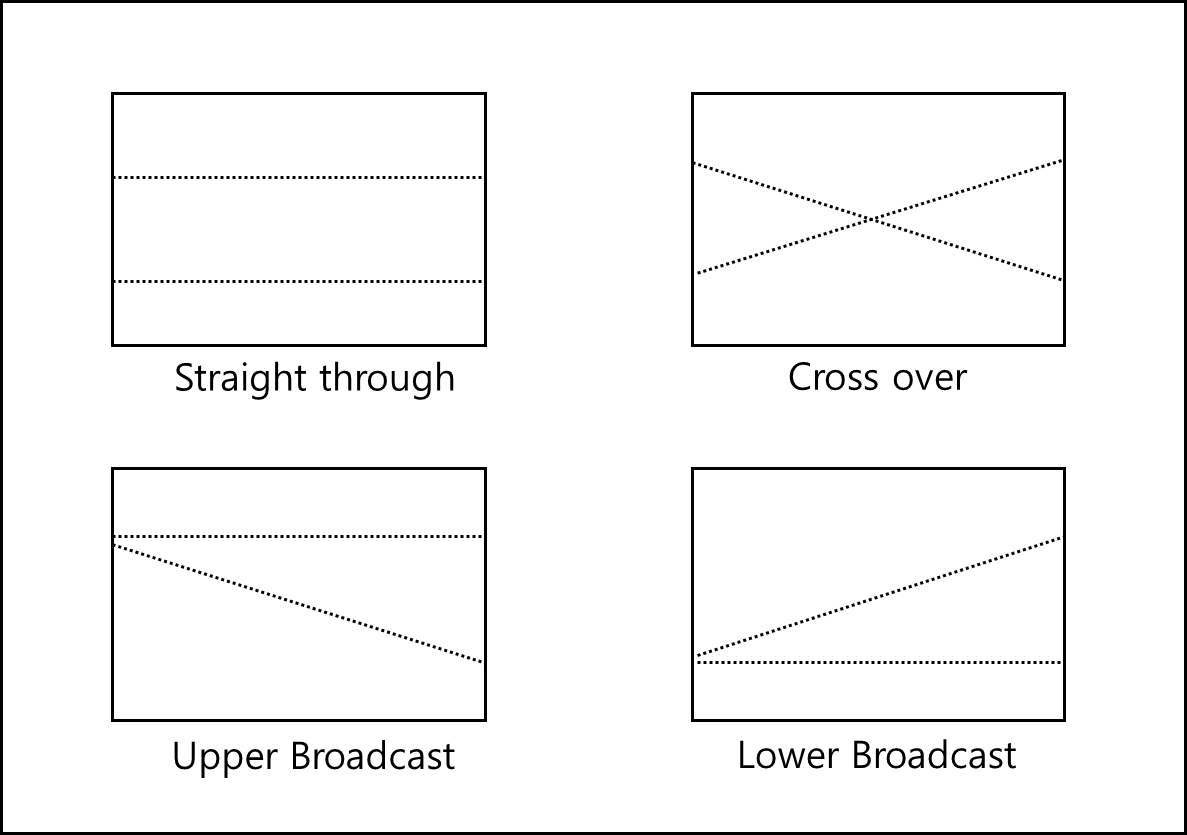
이 위의 상태 중에 broadcast는 쓰지 않고, cross 혹은 straight 만 사용한다.
Node to Switch나 Switch to Switch로 연결할때 Perfect shuffle 방식으로 연결한다.
가령, 0 ~ 15까지 있을 때 도착지는 bit shift left 1을 한 index와 연결한다.
아래의 그림을 보자.
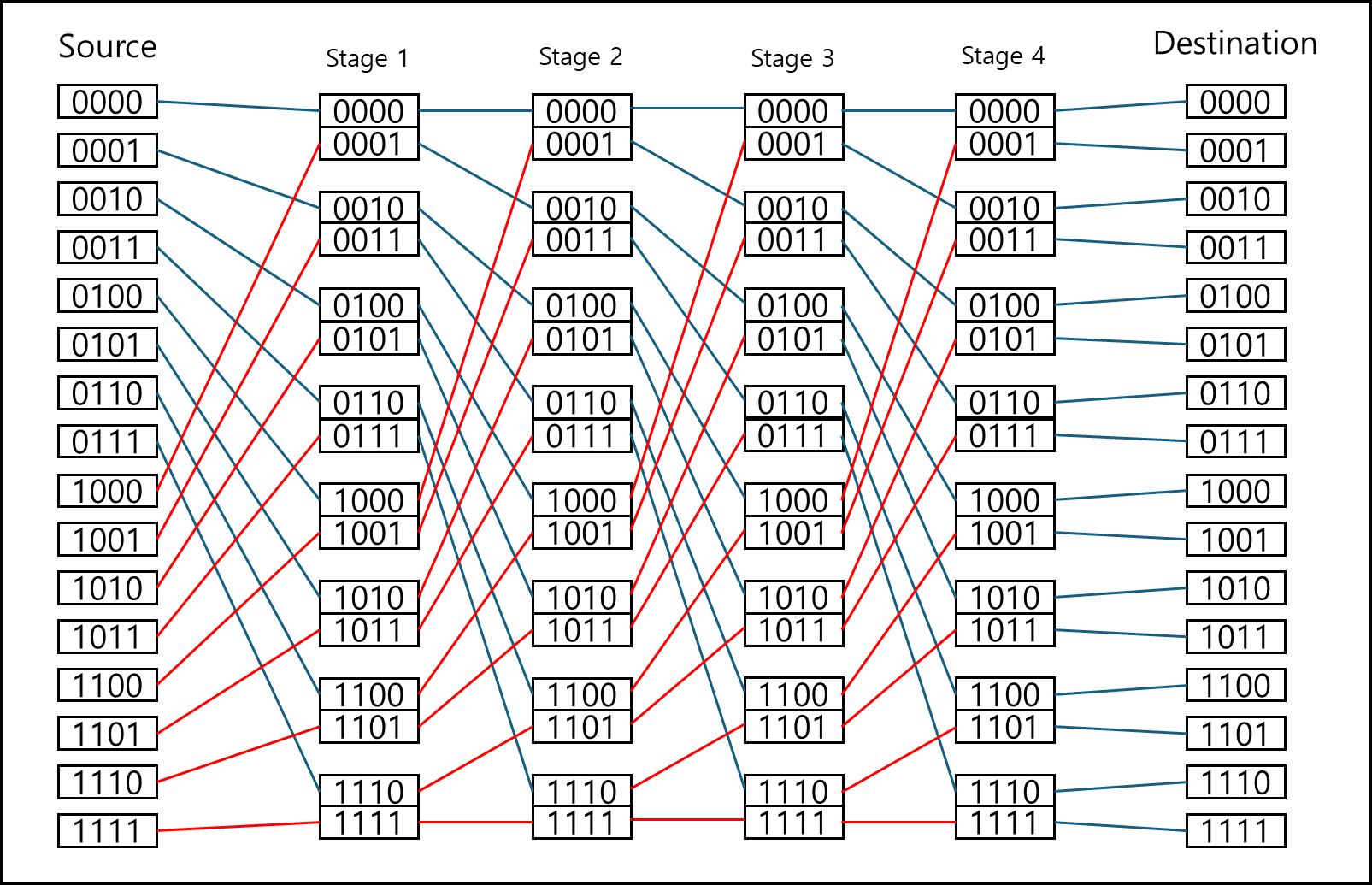
16 x 16의 경우 omega system을 그려본것이다. 0001의 경우 bit shift 1을 해서 0010으로 연결하는 식으로 다음 스테이지의 스위치에 연결을 하면 위와 같은 그림이 된다.
위와 같이 연결한건 좋은데 어떻게 routing 하느냐가 문제다. 만약 서로 다른 cpu가 어떤 메모리 혹은 cpu에 요청을 했을때 동일한 line을 타고
메세지가 가게되면 collision 이 일어나기 때문이다.
일단 omega system에서는 XOR-tag routing을 사용한다.
※ XOR-tag routing
방식은 간단하다 source와 destination의 bit index를 XOR하면 된다.
예를 들어 source가 0010이고, destination이 0011이라고 해보자.
1
2
3
4
0010
0011
----
0001
나온 결과를 왼쪽부터 확인했을 때 0은 straight, 1이면 cross로 경로를 타면 된다.
위 계산 결과를 그림으로 나타내면 아래와 같다.
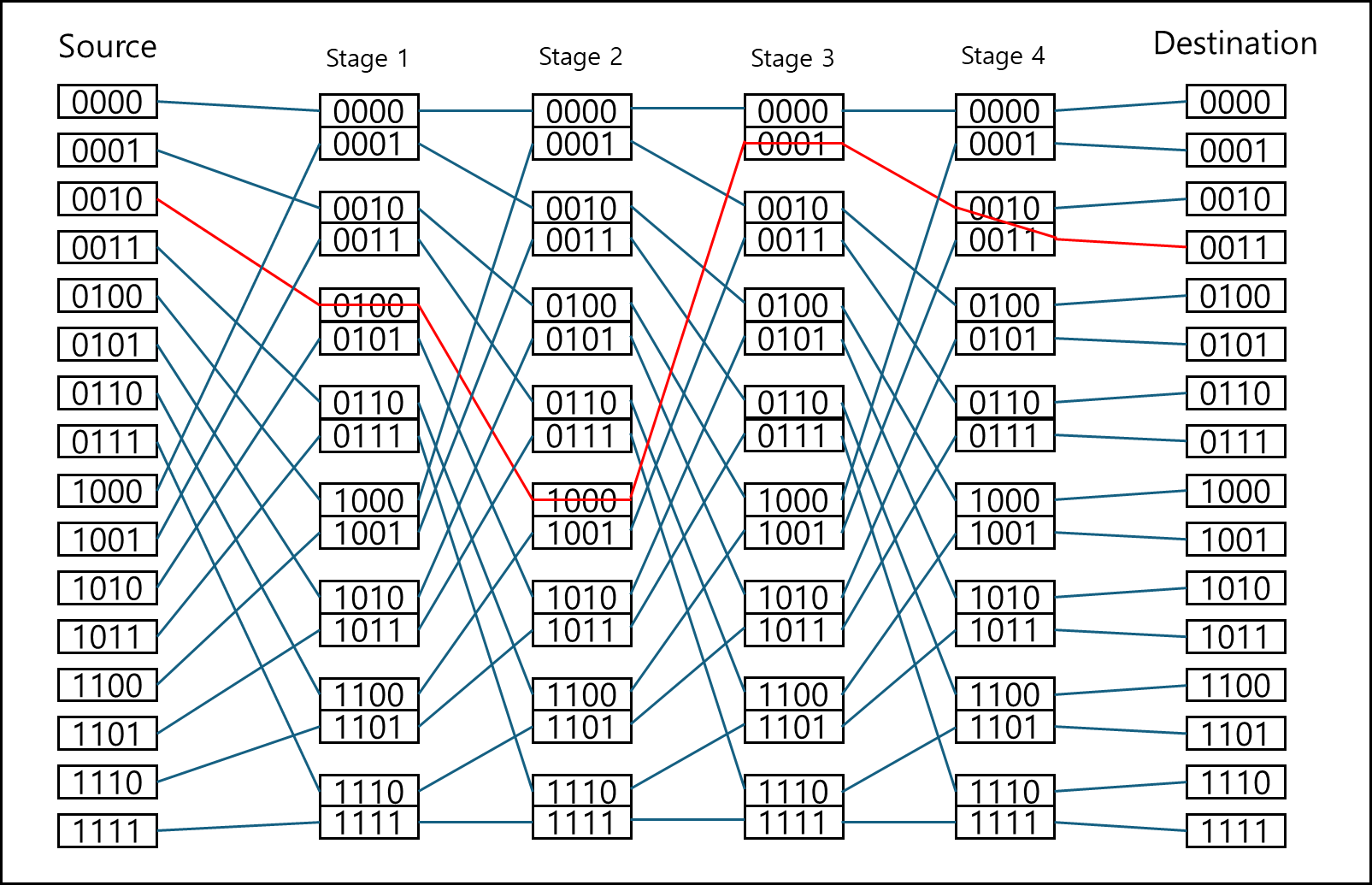
순서대로 표현하면 straight, straight, straight, cross이다.
※ Collision
방금 0010에서 0011로 가는 요청과 1010에서 0010으로 가는 요청이 동시에 발생한다면 어떻게 될까?
먼저 1010에서 0010을 XOR하면 아래와 같다.
1
2
3
4
1010
0010
----
1000
이를 0010에서 0011로 가는 요청과 1010에서 0010으로 가는 요청을 같이 그려보면 아래와 같다.
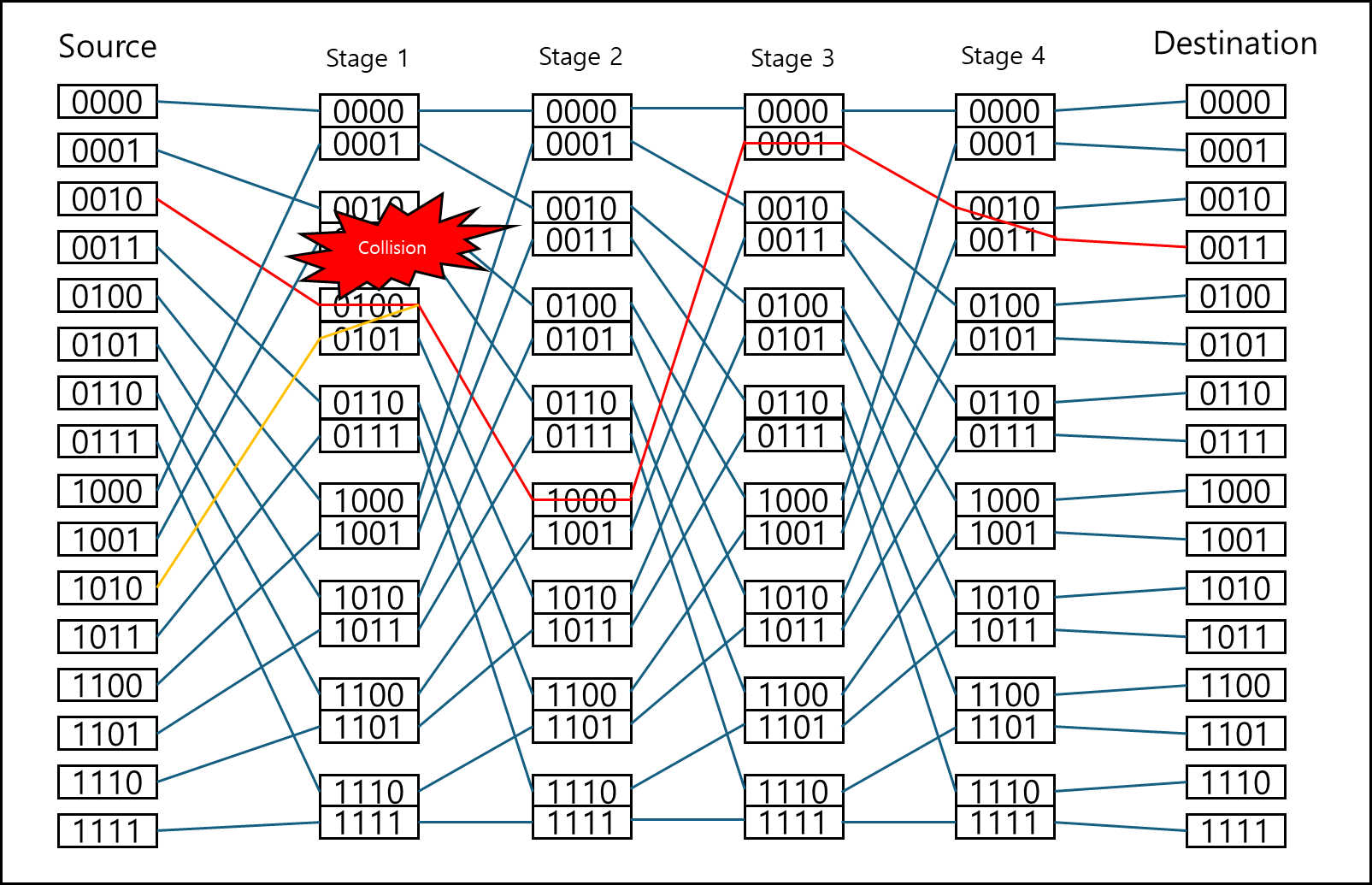
stage 1 시점에서 동일한 루트를 타고 전송됨을 확인할 수 있다. 이 경우 어느 한쪽은 기다려야한다.
위와 같은 경우를 collision이라고 한다.
※ 추가 업데이트 예정
참고자료
- 서강대학교 박성용 교수님 강의자료 - 병렬 분산 컴퓨팅
원문 참고자료들
- Peter S. Pacheco, An Introduction to Parallel Programming, Elsevier Inc. (Morgan Kaufmann), 2011, ISBN 978-0-12-374260-5
- Gerassimos Barlas, Multicore and GPU Programming – An Integrated Approach, Elsevier Inc. (Morgan Kaufmann), 2015, ISBN 978-0-12-417137-4.
- G. Coulouria, J. Dollimore, T. Kindberg, and G. Blair, Distributed Systems: Concepts and Design, 5 th Edition, Pearson, 2012, ISBN 978-0-273-76059-7
- M. van Steen and A. S. Tanenbaum, Distributed Systems, 3 rd Edition, 2017
- Martin Kleppmann, Designing Data-Intensive Applications, 1 st Edition, O’Reilly Media, 2017, ISBN 978-1491903070 (또는 2nd Edition in February 2026)