병렬분산컴퓨팅 - Parallel software & Performance
병렬 분산 컴퓨팅 - Parallel software & Performance
1. Parrallel software
1) Programming model
병렬 프로그래밍의 경우 실제로 구동되는 환경과 모델 사이의 추상화 부분에서 좀 상이할 수 있다.
이게 무슨 말이냐면 프로그래밍적으로는 분산 메모리를 가장하고 만들어질 수 있지만, 실제 구동되는 환경은 공유 메모리 환경일 수 있으며 반대로 공유 메모리를 가장하고 만들어진 프로그램이지만 실제 구동되는 환경을 분산 메모리일 수 있다는 점이다.
a. Shared memory model
변수를 공유(shared)하거나 전용(private)으로 설정할 수 있다. 스레드 간의 통신은 공유 변수를 통해 암시적(implicit)으로 이루어진다. 대표적인 예로 OpenMP, Pthreads, Cilk 등이 있다.
b. Distributed memory model
메시지 패싱(Message-Passing) 모델이라고도 한다. 각 프로세스는 자신의 전용 메모리에만 직접 접근할 수 있으며, 통신은 MPI(Message Passing Interface)나 소켓과 같은 API를 명시적으로 호출하여 데이터를 주고받는 방식으로 이루어진다.
c. Hybrid model
두 가지 이상의 모델을 결합한 방식이다. (예: MPI + OpenMP, MPI + CUDA)
2. 병렬성의 유형(Types of Parallelism)
1) 데이터 병렬성(Data parallelism)
여러 프로세서가 서로 다른 데이터에 대해 동일한 작업을 수행하는 방식이다.
2) 태스크 병렬성(Task parallelism)
여러 프로세서가 동일한 데이터에 대해 서로 다른 작업을 수행하는 방식이다.
3. 병렬 소프트웨어 개발시 고려사항
1) 비결정성(Non-determinism)
동일한 입력에 대해서도 실행할 때마다 결과가 달라질 수 있는 특성이다. 이는 여러 스레드가 독립적으로 실행되면서 문장을 완료하는 상대적인 속도가 매번 다르기 때문에 발생하며, 경쟁 상태(race condition)의 원인이 된다.
2) 스레드 안정성(Thread Safety)
여러 스레드가 동시에 실행하더라도 문제가 발생하지 않는 코드 블록을 의미한다. 예를 들어, 정적 변수를 사용하는 함수는 여러 스레드가 동시에 호출할 경우 안전하지 않을 수 있으며, rand()나 asctime() 같은 일부 표준 C 라이브러리 함수는 스레드에 안전하지 않아 재진입 가능한(reentrant) 버전(rand_r 등)을 사용해야 한다.
3. Performance
1) 주요 성능 지표 (Speedup 및 Efficiency)
a. 지표 정의 전 사전 정의
코어 개수를 $p$ 라고 하고, 어떤 작업을 1개의 코어에 맡겨서 순차 처리한 시간을 Serial run-time이라고하는데 이를 $T_{serial}$ 이라고한다. 어떤 작업을 병렬로 처리하여 완료한 시간을 Parallel run-time이라고 하며, 이를 $T_{Parallel}$ 이라고 한다.
일반적으로 바라는 건 $T_{Parallel} = $T_{serial} / P$지만 사실 동기화 오버헤드나 통신 오버헤드등으로 실제로는 아래의 식과 같다.
\[T_{Parallel} = $T_{serial} / P + T_{overhead}\]b. 스피드업 (S)
스피드업은 해당 프로그램을 병렬화했을 때 속도가 얼마나 빨라졌냐를 측정하는 지표이다.
수식은 아래와 같다.
여기서 $T_{serial}$은 전체 프로그램을 Single node로 구동했을 때의 소요 시간이다.
스피드업 종류를 그래프로 그려보면 아래와 같다.
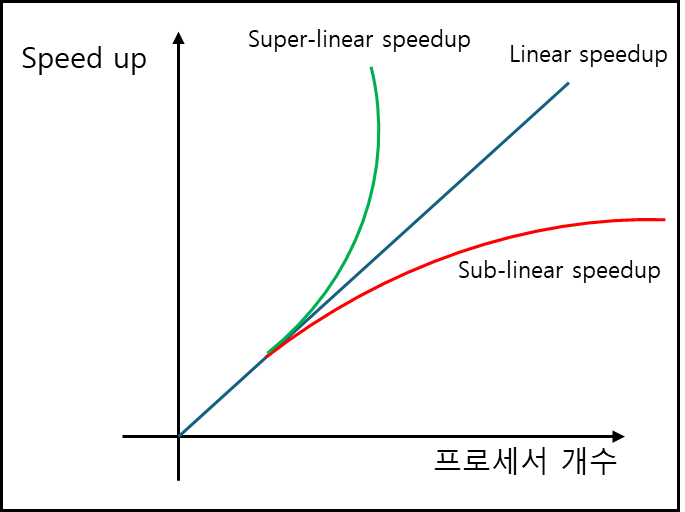
Linear Speedup
S = p인 경우이고, 드물게 가능함Super-linear speedup
S > p인 경우인데, 이론적으로는 가능하지 않으나 캐시 히트나 하드웨어적인 지원으로 인해 매우 드물게 발생가능하다.Sub-linear speedup
일반적인 형태이다.
c. 효율성 (E)
효율성은 위에서 구한 스피드업 $S$ 를 코어 수인 $p$로 나눈 값이다.
즉, 한 개의 코어가 얼마나 일을 많이 했느냐를 보는 지표라고 할 수 있다.
만약 E가 1이면 프로그램은 100%의 효율로 구동되는 것이다. 효율성 그래프를 그려보면 아래와 같다.
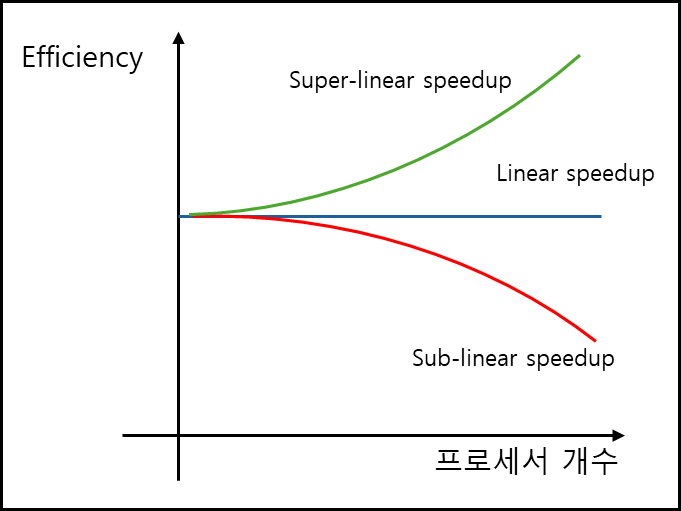
2) 법칙
Amdahl’s law
기본적으로 Problem이 고정된 상태에서 Serial 프로그램을 병렬화 했을 때 기대 가능한 최대의 스피드업을 구하는 공식이다. 아래의 그림을 보자.
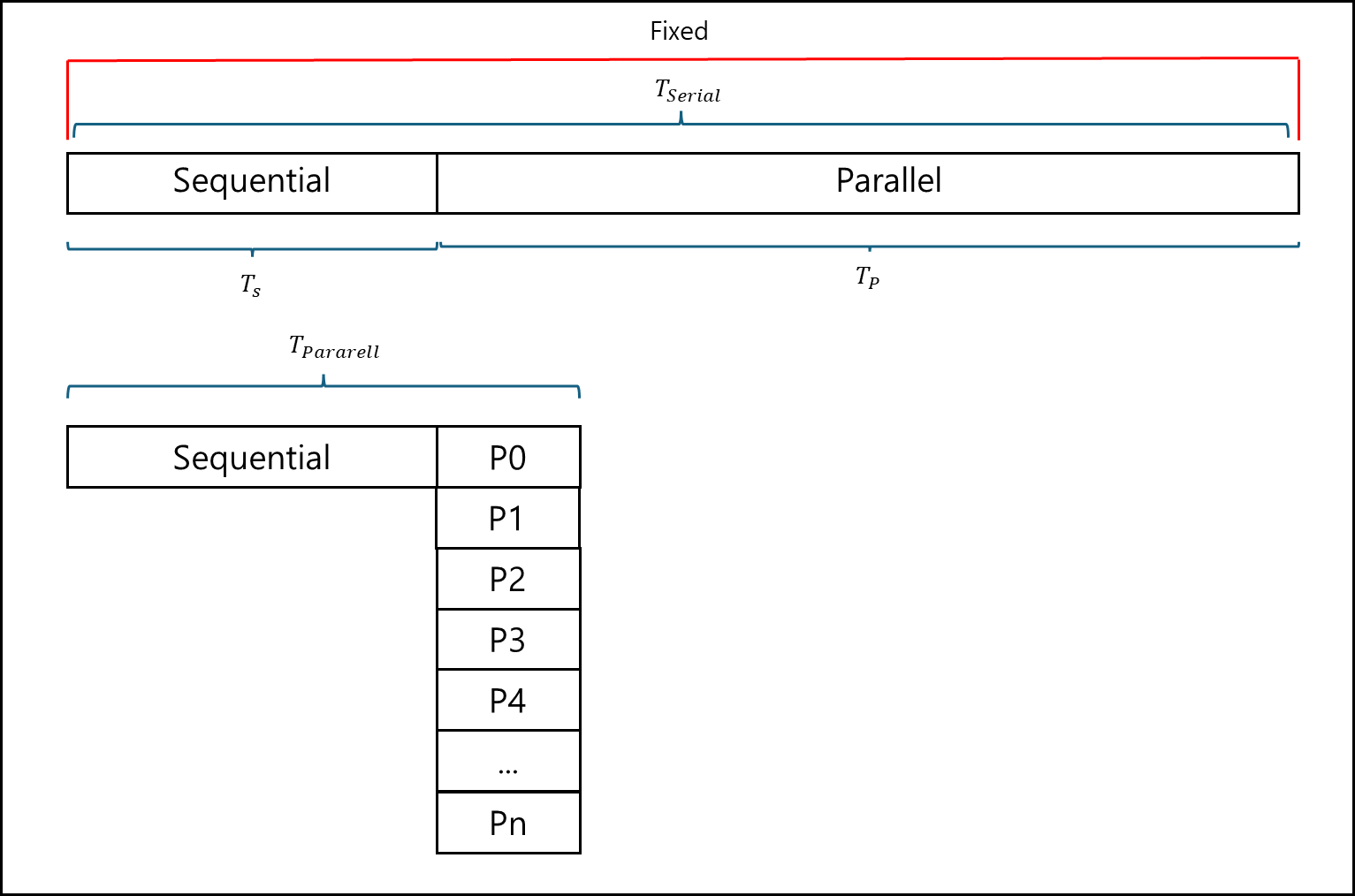
어떤 프로그램이 있고, 이 프로그램의 일의 양의 크기가 고정되어있다고 하자.
어떤 정해진 일이 있고, 전체를 단일 Node(Processor)로 구동했을때 걸리는 시간을 $T_{Serial}$ 이라고 하자. 그리고 이 프로그램에서 병렬화 불가능한 부분을 단일 Node로 구동하는데 걸리는 시간을 $T_{s}$, 병렬화 가능한 부분을 단일 Node로 구동하는데 걸리는 시간을 $T_{p}$ 라고 하고 Node p에 의해서 병렬화되어 전체 구동된 시간을 $T_{Pararell}$ 이라고 해보자.
이 경우 각 $T_{Serial}$ 과 $T_{Pararell}$ 그리고 스피드업에 대해서는 아래와 같다.
\(T_{Serial} = T_{s}+T_{p}\) \(T_{Pararell} = T_{s}+(T_{p}/p)\) \(S(p) = \frac{T_{Serial}}{T_{Pararell}} = \frac{T_{s}+T_{p}}{T_{s}+T_{p}/p}\)
위의 T 값들은 모두 시간에 대한 값이었다. 여기서 프로그램에서 병렬화 불가능한 부분을 f로 잡고 나머지 병렬화 가능한 부분을 1-f로 정의할 경우 $T_{s}$ 와 $T_{p}$ 에 대해서는 아래와 같다.
\(T_{s} = f \times T_{Serial}\) \(T_{p} = (1-f) \times T_{Serial}\)
위 식으로 전체 프로그램에서 병렬화 불가능한 부분이 f만큼일때 이론상 가능한 최대의 스피드업은 아래와 같다.
\[S(p) = \frac{T_{s}+T_{p}}{T_{s}+T_{p}/p} = \frac{f \times T_{Serial} + (1-f) \times T_{Serial}}{f \times T_{Serial}+(1-f)\times T_{Serial}/p} = \frac{1}{f+(1-f)/p}\]※ 예시
어떤 프로그램을 단일 노드로 구동했을 때 20초가 걸리는데, 90%가 병렬화가 가능하고, 병렬화에 대한 오버헤드가 전혀 없다고 가정한 상태에서 최대 가능한 스피드 업 크기는?
\(T_{Serial} = 20 sec\) \(T_{p} = 18/p sec\) \(T_{s} = 2 sec\)
\[Speed up = \frac{0.1 \times T_{Serial} + 0.9 \times T_{Serial}}{0.1 \times T_{Serial} + 0.9 \times T_{Serial}/p} = \frac{20}{2+18/p} <= 10\]Gustafson’s law
구스타프슨의 법칙은 기존 암달의 법칙에서 문제가 고정되어있지 않고 증가한다는 가정에서의 Speed up을 구하는 것이다.
아래의 그림을 보자.
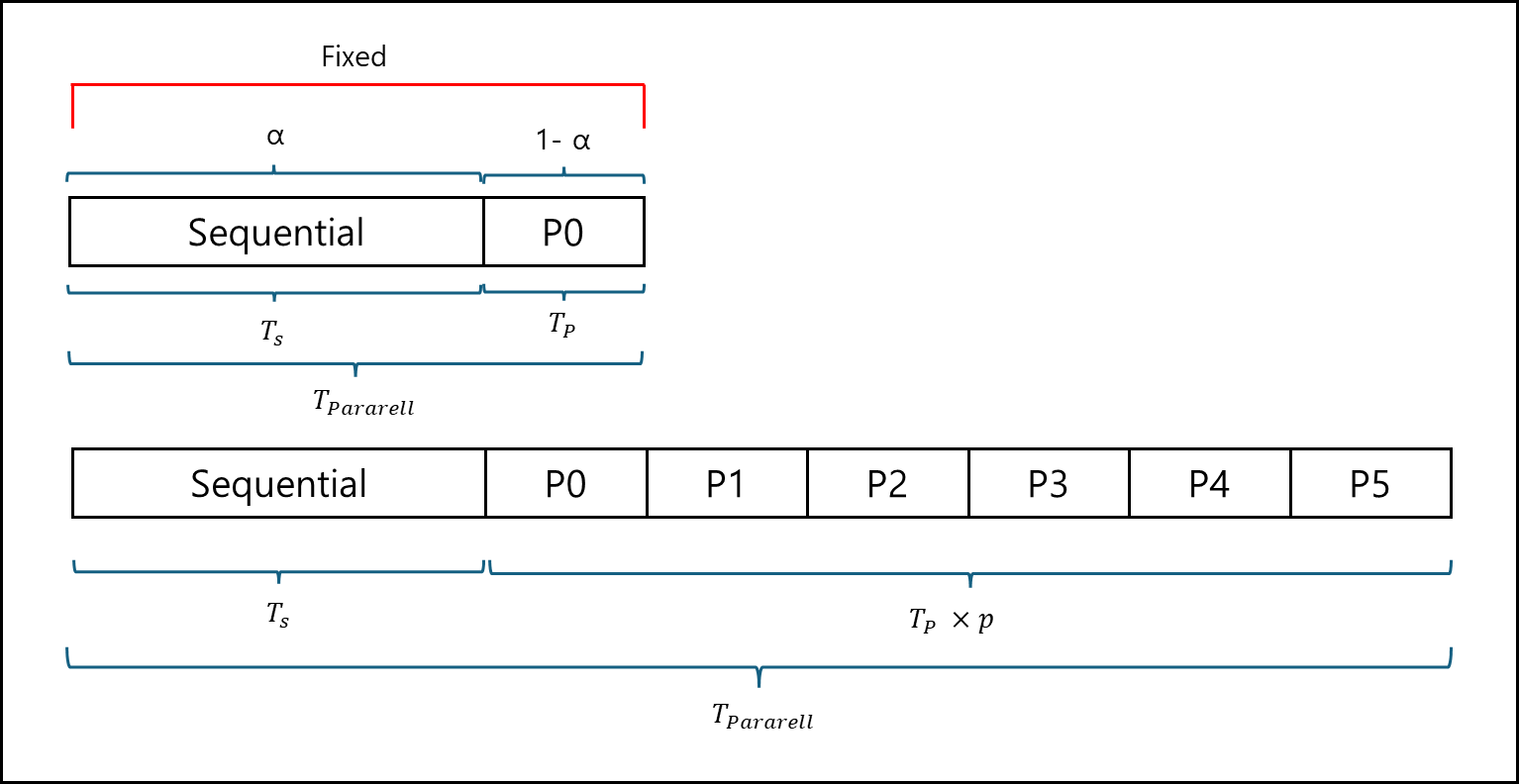
여기서 $T_{Parallel}$ 과 $T_{Serial}$ 은 아래와 같다.
\(T_{Parallel} = T_{s} + \times T_{p}\) \(T_{Serial} = T_{x} + p \times T_{p}\)
여기서 프로세서와 함께 각 프로세서가 맡는 일 역시 비례해서 늘어난다면 이에 대한 스피드업(Scaled speed up)은 아래와 같다.
\[Ss(p) = \frac{T_{Serial}}{Parallel} = \frac{T_{x}+p\times T_{p}}{T_{s}+T_{p}} = \alpha + p \times (1-\alpha)\]만약 알파값이 작아지면 전체 스피드업은 p(노드 개수)에 가까워진다.
※ 예시
만약 병렬 프로그램이 총 5개의 머신에서 구동하고 있고 10%의 병렬불가능한 파트를 갖고 있다면, 한 개의 머신에서 구동될때보다 몇배 정도 빠른가?
\[\alpha = 0.1, Ss(5) = 0.1 + 5 \times 0.9 = 4.6\]만약 두 배의 스피드업을 하고 싶다면 몇 개의 머신을 써야하는가?
\[9.2 = 0.1 + p \times 0.9 ~= 10.1\]따라서 총 11개의 머신을 써야한다.
※ 추가 업데이트 예정
참고자료
- 서강대학교 박성용 교수님 강의자료 - 병렬 분산 컴퓨팅
원문 참고자료들
- Peter S. Pacheco, An Introduction to Parallel Programming, Elsevier Inc. (Morgan Kaufmann), 2011, ISBN 978-0-12-374260-5
- Gerassimos Barlas, Multicore and GPU Programming – An Integrated Approach, Elsevier Inc. (Morgan Kaufmann), 2015, ISBN 978-0-12-417137-4.
- G. Coulouria, J. Dollimore, T. Kindberg, and G. Blair, Distributed Systems: Concepts and Design, 5 th Edition, Pearson, 2012, ISBN 978-0-273-76059-7
- M. van Steen and A. S. Tanenbaum, Distributed Systems, 3 rd Edition, 2017
- Martin Kleppmann, Designing Data-Intensive Applications, 1 st Edition, O’Reilly Media, 2017, ISBN 978-1491903070 (또는 2nd Edition in February 2026)