컴파일러 - 어휘 분석
어휘 분석(lexical analysis)
1. 개요
어휘 분석(lexical analysis)은 컴파일러의 첫 번째 단계로, 원시 소스 코드(문자열)의 연속을 의미 있는 단위인 토큰(token) 으로 분리하고 각 토큰의 종류를 식별하는 과정이다. 이 단계에서는 공백, 주석 등을 제거하여 후속 단계인 구문 분석(parser)이 다루기 쉬운 형태로 변환한다. 주된 목표는 소스 코드의 문자 시퀀스에서 예약어, 식별자, 연산자, 구분자, 리터럴 등을 추출하여 토큰 스트림(token stream)을 생성하는 것이다.
아래는 어휘 분석기와 파서와의 상호작용을 그림으로 나타낸 것이다.
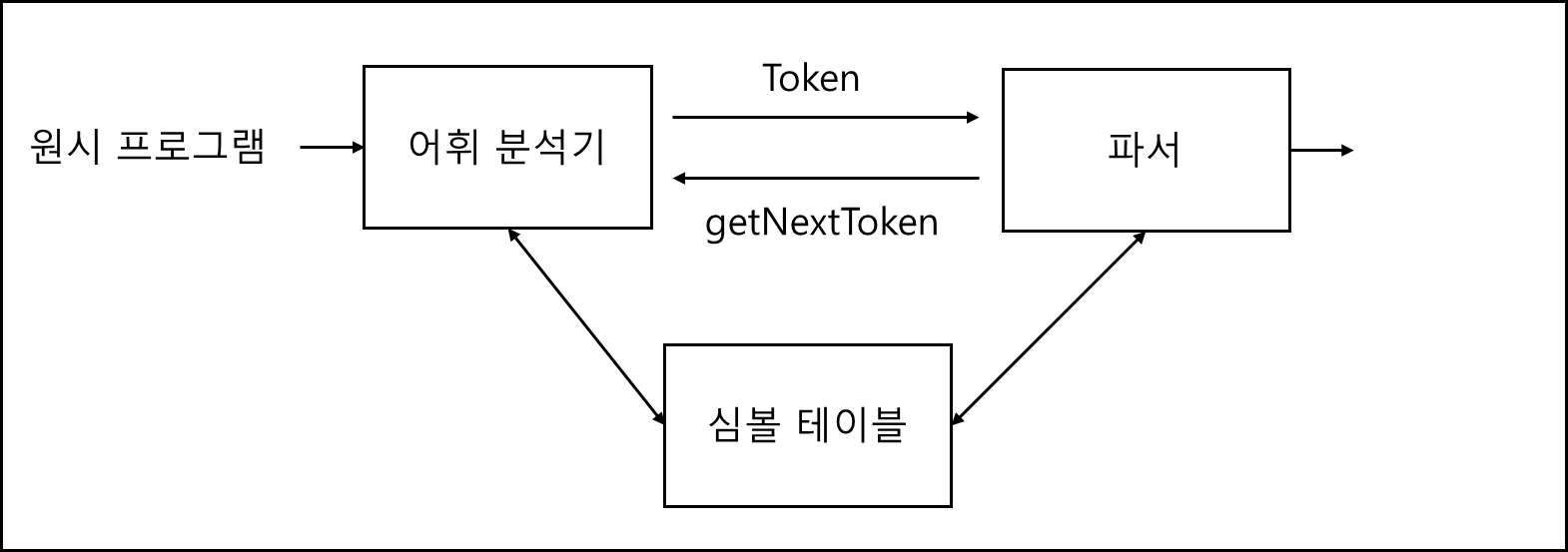
일반적으로 파서가 토큰을 요구하고 어휘분석기가 토큰을 생성해서 보내준다. 그 과정에서 해당 토큰이 어떤 심볼인지 기재되어있는 심볼 테이블을 어휘 분석기가 참고하게 되는데, 읽어들인 토큰이 특정 식별자인지 참고하여 이에 걸맞는 형태의 토큰으로 생성해서 보내주기도하고 어휘 분석기가 해당 식별자에 대한 정보를 심볼 테이블에 추가하기도 한다.
2. 입력 버퍼(Input buffer)
어휘 분석기는 입력 버퍼를 통해 소스 코드를 효율적으로 읽는다. 일반적으로 이중 버퍼(Double-buffering) 구조를 많이 사용하며, 아래와 같은 특징이 있다. 이 구조를 통해 문자 단위의 I/O 비용을 최소화하고, 효율적인 패턴 매칭이 가능하다.
a. 버퍼 크기
보통 4KB~8KB 정도의 고정 크기(일반적으로 디스크 블록의 크기) 버퍼를 두 개 사용하여, 하나가 비워질 때 다른 하나를 채워 I/O 오버헤드를 줄인다.
b. 포인터
- lexeme_begin: 현재 추출하려는 토큰의 시작 위치
- forward: 입력을 스캔하면서 현재 문자 위치
c. EOF 처리
버퍼의 끝에 특수한 EOF 마커(이를 책에서는 sentinel 문자라고 했다, 문자열 끝에 붙는 그거 맞다)를 삽입해 경계를 감지하고, 경계가 감지되었다면 버퍼를 다 읽었다는 말이므로 다른 버퍼에 자동으로 다음 부분을 로드한다.
3. 토큰
1) 명세
토큰은 다음과 같은 요소로 정의된다.
토큰 클래스(Token class / Token type): 식별자(identifier), 키워드(keyword), 연산자(operator), 구분자(delimiter), 리터럴(literal) 등
어휘 규칙(Lexical specification): 각 토큰 클래스에 속하는 문자열 패턴을 정규 표현식(regular expression)이나 유한 오토마타(finite automaton)로 정의
속성값(Attribute value): 토큰이 갖는 실제 값, 예를 들어 리터럴 토큰의 경우 숫자 값이나 문자열 값
2) 인식
어휘 분석기는 정의된 어휘 규칙에 따라 입력 버퍼를 스캔하면서 토큰을 인식한다.
a. 최장 매칭(Longest-match) 원칙: 가능한 한 길게 일치하는 패턴을 선택
b. 우선순위(Ordered choice): 두 패턴이 동일 길이로 매칭될 때는 명세된 순서에 따라 우선순위 충돌을 해결
c. 백트래킹 방지: 효율성을 위해 대부분의 어휘 분석기는 백트래킹을 피하는 DFA(Deterministic Finite Automaton)를 사용
d. 에러 처리: 토큰으로 인식할 수 없는 문자 시퀀스가 나올 경우, 에러 토큰을 생성하거나 에러 메시지를 출력
4. 유한 오토마타
어휘 분석기의 핵심 알고리즘은 유한 오토마타(Finite Automaton) 이며, 크게 다음 두 가지 형태가 있다.
1) NFA(Non-deterministic Finite Automaton)
정규 표현식에서 직접 변환 가능
ε-전이(빈 전이)를 포함
여러 상태를 동시에 고려해야 하며, 백트래킹이 필요할 수 있음
2) DFA(Deterministic Finite Automaton)
NFA를 subset construction 알고리즘으로 변환
각 입력 문자마다 다음 상태가 유일하게 결정
구현 및 실행 효율성이 높아 실제 어휘 분석기에 주로 사용
※ DFA의 동작 과정
초기 상태에서 시작
입력 문자를 읽어 현재 상태에서의 전이 테이블을 참조
전이 가능한 상태가 없으면 매칭 실패 → 에러 처리 또는 토큰 완성
매칭이 계속 가능하다면 forward 포인터를 전진
더 이상 전이가 불가능할 때, 마지막으로 받아들여진(accepting) 상태를 기준으로 토큰 결정
참고자료
- 순천향대학교 KOCW - 컴파일러
- Knowledge Repository - 프로그래밍 언어의 구문의 표현 - BNF, EBNF, 구분 도표 표현법
- 컴파일러 : 원리, 기법, 도구 제 2판. ALFRED V. AHO, MONICA S. LAM, RAVI SETHI, JEFFREY D. ULLMAN. 우원희, 신승철, 우균, 하상호 옮김