컴퓨터 구조 - RAID
RAID
1. 개요
RAID는 한 마디로 다수의 SSD/HDD를 사용하기 위한 방법이다.
그냥 한 개의 스토리지 디바이스만 쓰면 되는거 아닌가 하는 의문이 들 수 있다. 2025년 1월 기준 현존하는 최대 용량이 HDD는 32TB[1] 인데 이거면 충분하지라고 생각할 수 있지만
매일 기가(GB) 단위는 우습게 넘기고 테라(TB) 혹은 페타(PB) 단위까지 저장해야하는 데이터 센터입장 에서는
다수의 스토리지를 “잘’ 사용하는 것은 매우 절실한 일이다.
그리고 정말 큰 데이터를 저장해야할때는 여기서 특별한 경우를 제외하고는 HDD를 많이 쓴다고 한다.
최근 나온 SSD는 122.88TB 용량[2]을 지원한다고 하는데 이걸 쓰면 되지 않냐고 생각할 수 있다.
문제는 SSD는 HDD에 비해 매우 비싸다. 그래서 대용량으로 쓰기엔 매우 부담되는 가격이다.
GB당 가격을 생각해보면 HDD가 압도적으로 싸다 따라서 HDD로 많이들 다수를 사서 쓴다.
꼭 큰 용량을 위해서만 다수의 하드디스크를 사용할까?
그건 아니다, 정확하게는 아래의 이유로 인해 많이들 다수의 하드디스크를 사용한다.
1) 용량(Capacity)
용량이 부족하기 때문에 다수의 하드디스크를 사용하는건 일견 당연해보인다.
단, 설정에 따라 하드디스크의 갯수에 따른 전체 용량이 완전 정 비례하진 않는다.
이는 아래에서 추가적으로 설명할 것이다.
2) 신뢰성(Reliability)
1개의 하드디스크만 있다고 해보자. 이 디스크에 뭔가 문제가 생겨서 데이터가 소실되었거나 변경되었을때 이 스토리지는 신뢰성이 있다고 할 수 있을까?
만약 2개 이상의 하드디스크에 서로 같은 내용이 기재되어있다면 1개 정도는 문제가 생겨도 데이터 보존에는 문제가 없게 된다. 물론 이것도 용량을 어느정도 희생해야하는 문제이다.
이 부분에 대한 설명도 아래에서 추가적으로 설명할 것이다.
3) 성능(Performance)
하드디스크 하나에서만 읽는 것보다 같은 내용이 담긴 하드 디스크에서 각기 다른 부분을 동시에 읽어들인다면 속도는 2배일 것이다. 물론 이것도 설정에 따라 다르고 하드디스크에서 읽어들이는 Bus나 Path에서 병목현상이 일어나지 않아야 가능한 일이긴하다. 이 역시 아래에서 추가적으로 설명할 것이다.
2. 종류 및 변천사
※ 선행적으로 알아야 할 것
종류 및 변천사에 서술하기에 앞서 선행적으로 알아야할 지표에 대해서 말하겠다.
이는 각 RAID에 대한 성능 분석을 위한 선행 지표라고 알면 되겠다.
- N : 디스크의 개수
- C : 1개 디스크의 용량
- S : 1개 디스크당 순차 처리량
- R : 1개 디스크당 임의 접근 처리량
- D : 작은 I/O에 대한 응답시간 (512Bytes)
1) JBOD (Just a Bunch Of Disks)
어플리케이션이 알아서 각기 다른 하드 디스크에 파일을 넣는 것이다.
그림으로 표현하면 아래와 같다.
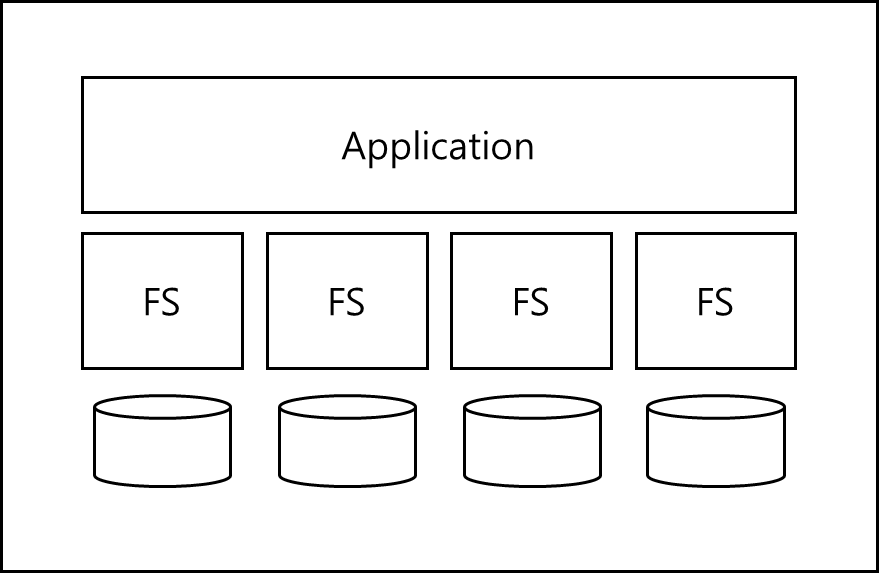
이 구조의 단점은 어플리케이션에서 해당 구현이 이루어져야한다는 점이다.
이 말인 즉슨 어플리케이션의 구현이 어려워진다는 것이고 이는 OS에서 제대로 된 추상화된 인터페이스를 제공하고 있다고 보기 어렵다.
위 문제를 해결하기 위해 나온게 아래와 같은 구조이다.
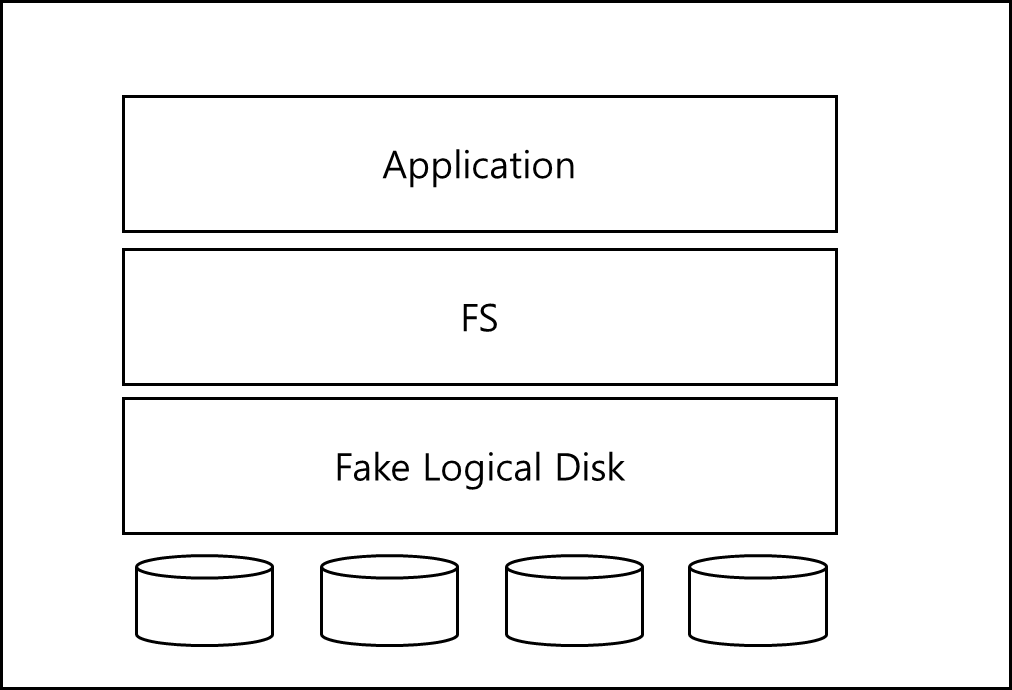
가상의 논리적 디스크 계층을 파일 시스템 아래에 넣어서 구동하는 것이다.
이런 가상의 논리적 디스크는 볼륨 매니저가 관리하는 것으로 위와 같은 구조를 RAID(Redundant Array of Inexpensive Disks) 구조라고 한다.
이렇게되면 어플리케이션에서는 단순히 한 개의 하드디스크에 파일을 넣는 것으로 구현하면 되니 좀 더 편하고 하드디스크의 증설과 관리가 편해진다.
2) RAID - 0
a. 구성
데이터를 논리적인 블럭으로 쪼개서 번갈아가면서 각각 디스크에 넣는 방식이다.
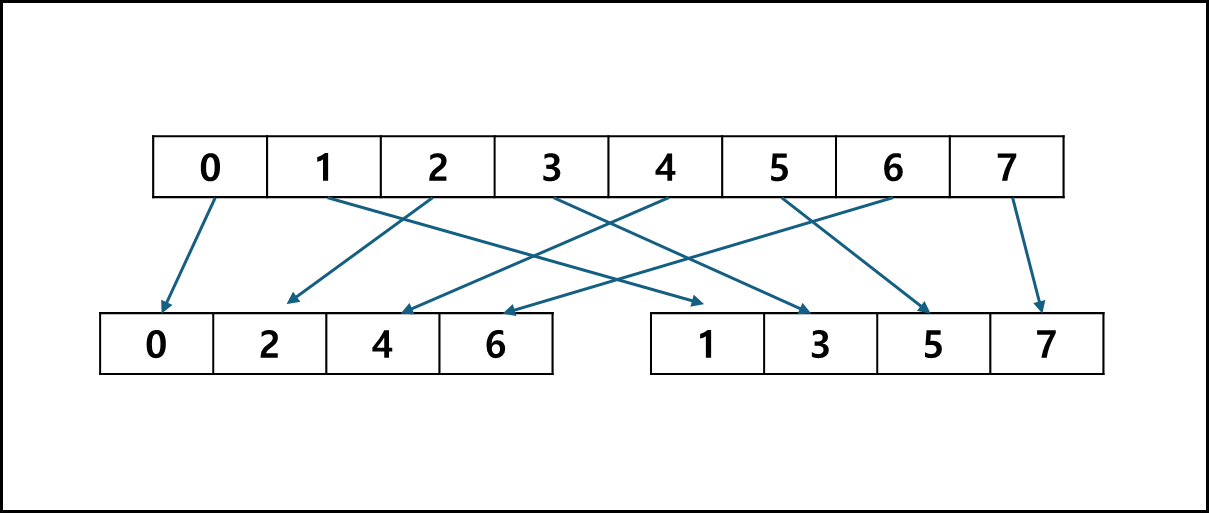
디스크가 4개이고 Chunk 크기가 1이라면 아래와 같이 배치 된다.
| DISK 0 | DISK 1 | DISK 2 | DISK 2 |
| 0 | 1 | 2 | 3 |
| 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 |
Chunk 크기가 2라면 아래와 같이 배치된다.
| DISK 0 | DISK 1 | DISK 2 | DISK 2 |
| 0 | 2 | 4 | 6 |
| 1 | 3 | 5 | 7 |
| 8 | 10 | 12 | 14 |
| 9 | 11 | 13 | 15 |
b. 성능 분석
- 용량 : N x C
- 신뢰성이 유지되는 최대 Disk fail(디스크의 물리적, 논리적 손상) 수 : 0
- 응답시간 : D
- 처리량 (순차, 임의) : N x S, N x R
3) RAID - 1
a. 구성
Mirroring 이라고도 말한다. 동일한 내용을 2의 디스크에 똑같이 기재하는걸 말한다.
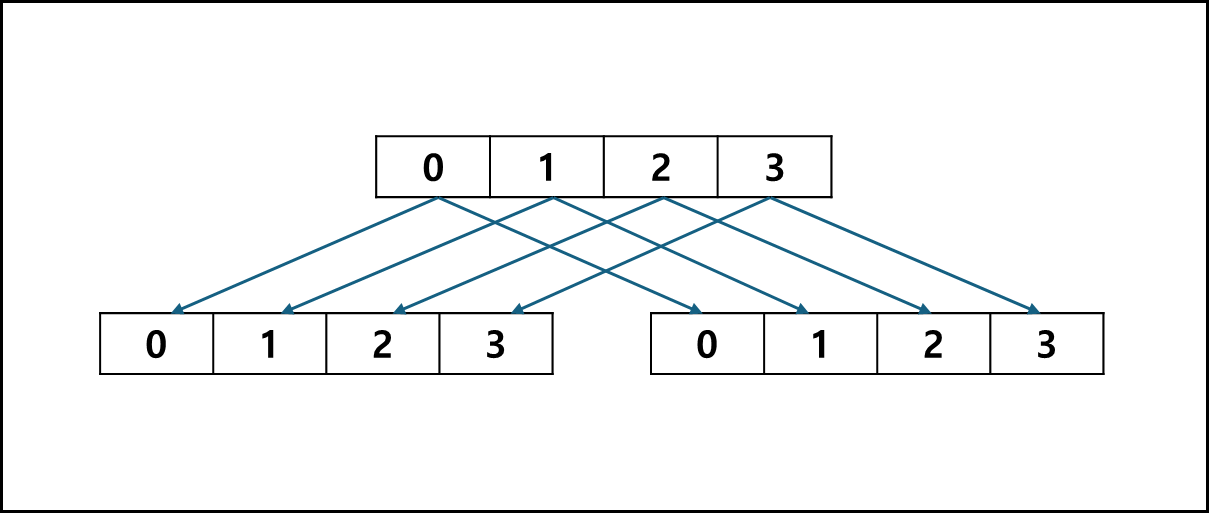
디스크가 4개인 경우 아래와 같이 구성된다.
| DISK 0 | DISK 1 | DISK 2 | DISK 2 |
| 0 | 0 | 1 | 1 |
| 2 | 2 | 3 | 3 |
| 4 | 4 | 5 | 5 |
| 6 | 6 | 7 | 7 |
b. 성능 분석
- 용량 : N/2 x C
- 신뢰성이 유지되는 최대 Disk fail(디스크의 물리적, 논리적 손상) 수 : 1 (설정에 따라 N/2)
- 응답시간 : D
- 처리량 (순차, 임의) : N/2 x S (구현에 따라 N x S)
4) RAID - 2
a. 구성
Hamming Code를 이용해서 Error Correction을 한다. 데이터 디스크로 m+1개를 쓰고 m개의 ECC(Error Correction Code) 디스크로 구성된다.

위와 같이 구성하면 추가적인 연산이 필요하므로 입출력 속도가 느리다고 한다.
또한 ECC 기록하는 디스크의 수명이 매우 떨어져 현재는 쓰이지 않는다.
5) RAID - 3
a. 구성
바이트 단위로 패리티를 구성하여 다른 한 개의 디스크를 패리티 블록으로 사용하는 것이다.
데이터 역시 바이트 단위로 균등하게 나누어 각 하드에 동등하게 입력하고 나머지 패리티 디스크에 각 바이트에 대한 패리티를 기재한다.

위와 같이 구성하면 한 개의 디스크가 고장나도 다른 디스크의 정보를 이용하여 복구가 가능하다.
데이터 디스크 중 하나가 고장나도 패리티를 통해 나머지 정보를 복구 할 수 있고 패리티 디스크가 고장난다면 다른 디스크를 통해 다시 패리티를 복구 할 수 있다.
b. 성능 분석
- 용량 : (N-1) x C
- 신뢰성이 유지되는 최대 Disk fail(디스크의 물리적, 논리적 손상) 수 : 1
- 응답시간(read, write) : D, 2 x D
- 순차 읽기 처리량 : (N-1) x S
- 순차 쓰기 처리량 : (N-1) x S
- 임의 읽기 처리량 : (N-1) x R
- 임의 쓰기 처리량 : R/2
6) RAID - 4
a. 구성
블록 단위로 패리티를 구성하여 다른 한 개의 디스크를 패리티 블록으로 사용하는 것이다.

위와 같이 구성하면 한 개의 디스크가 고장나도 다른 디스크의 정보를 이용하여 복구가 가능하다.
데이터 디스크 중 하나가 고장나도 패리티를 통해 나머지 정보를 복구 할 수 있고 패리티 디스크가 고장난다면 다른 디스크를 통해 다시 패리티를 복구 할 수 있다. RAID-3에 비해 불러오고 쓰는 단위가 커서 성능상 조금 더 이점이 있다고 한다.
b. 성능 분석
- 용량 : (N-1) x C
- 신뢰성이 유지되는 최대 Disk fail(디스크의 물리적, 논리적 손상) 수 : 1
- 응답시간(read, write) : D, 2 x D
- 순차 읽기 처리량 : (N-1) x S
- 순차 쓰기 처리량 : (N-1) x S
- 임의 읽기 처리량 : (N-1) x R
- 임의 쓰기 처리량 : R/2
쓰기 응답시간의 경우 패리티 디스크를 읽고 써야하므로 좀 더 소요된다. 임의 쓰기 처리량의 경우 패리티 디스크를 읽고 써야하기 때문에 시간당 처리량은 보통 디스크에 비해 절반이다.
7) RAID - 5
a. 구성
기본적으로 RAID-4와 같되, RAID 4의 경우 패리티 블록이 한 디스크에만 몰려있다면 패리티 처리에 대한 병목 현상이 발생한다. 때문에 각 패리티 블록은 각 디스크로 분산시킨게 RAID - 5이다.
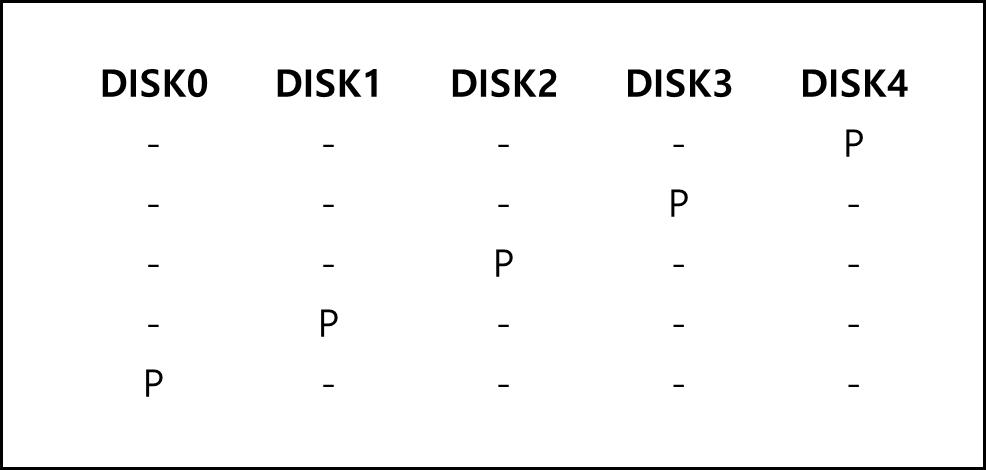
위와 같이 구성하면 각 패리티 블록이 분산되어있기 때문에 병목 현상이 발생하지 않는다.
b. 성능 분석
DISK가 5개 일 경우
- 용량 : (N-1) x C
- 신뢰성이 유지되는 최대 Disk fail(디스크의 물리적, 논리적 손상) 수 : 1
- 응답시간 : D, 2 x D
- 순차 읽기 처리량 : (N-1) x S
- 순차 쓰기 처리량 : (N-1) x S
- 임의 읽기 처리량 : N x R
- 임의 쓰기 처리량 : N x R/4
RAID-4와 기본적으로 같으나 임의 쓰기 처리량이 다른 것을 확인할 수 있는데 패리티 블록이 분산되어있기 때문이며 디스크가 A라면 R/A 형태가 되기 때문에 점점 더 많은 양을 처리할 수 있다.
6) RAID - 6
a. 구성
기본적으로 RAID-5와 같되, RAID-5의 경우 패리티 블록이 한 개씩 있었다면 RAID-6의 경우에는 패리티 블록이 두 개씩 있다.
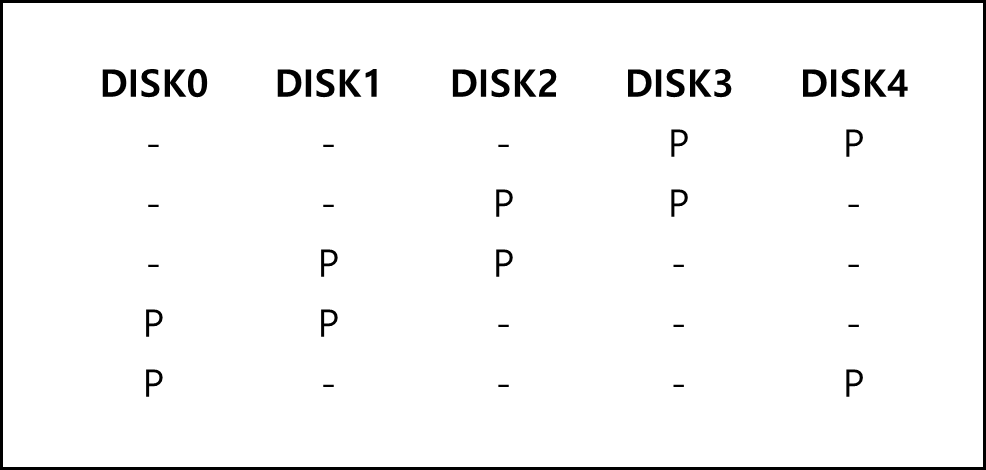
b. 성능 분석
DISK가 5개 일 경우
- 용량 : (N-2) x C
- 신뢰성이 유지되는 최대 Disk fail(디스크의 물리적, 논리적 손상) 수 : 2
- 응답시간 : D, 3 x D
- 순차 읽기 처리량 : (N-2) x S
- 순차 쓰기 처리량 : (N-2) x S
- 임의 읽기 처리량 : N x R
- 임의 쓰기 처리량 : N x R/2
※ 큰 데이터 센터에서는 동시에 2개의 Drive fail 나는 것을 방지하고자 RAID-6를 많이 사용한다고 한다.
3. 에러 처리
예를 들어보자 RAID-1에서 DISK를 2개로 구성하고 있는데 각각 DISK A와 DISK B라고 하겠다. 동일한 데이터를 각각 A와 B에 적고 있었는데, A를 적고 있던 도중 정전이나 DRIVE FAIL로 인해서 어떤게 원래 데이터 였는지 알수가 없게 되었다. 말한 경우와 같이 Crash가 났을 때 어떻게 처리할까?
만약에 별도의 하드웨어 RAID 컨트롤러가 있다면 내부에 비휘발성 RAM이 있어서 어디까지 작업이 되어있는지 기재되어 있어서 그걸 기준으로 원래 데이터를 복구 할 수 있다.
하지만 Software RAID를 하고 있었다면 (가령, 리눅스라던지) 그러면 사실상 에러를 체크할 방법이 없다.
참고자료
- [1] The largest SSD and hard drives of 2025
- [2] SC24: Phison, 세계 최대 Gen5 SSD 용량, 기록적인 강도 등 선보여
- 서강대학교 김영재 교수님 고급데이터 베이스 강의 자료
- 위키백과 - RAID