프로세스와 스레드
프로세스
실행 중인 프로그램이라고 할 수 있다.
다음과 같은 C언어 프로그램이 있다고 가정해보자
1
2
3
4
5
6
7
8
9
10
11
12
# include <stdio.h>
int glob=3; //global or static variable
void Function_A (void)
{
int loc, *dynamic;
dynamic = malloc(1383);
printf(“….
...
return 0;
}
유닉스에서 프로그램이 구동되면 같은 소스라고 하더라도 다른 메모리 영역에 배치되게 된다. 여기서 glob 전역 변수는 정적 데이터와 함께 data 영역에 배치되고 loc와 같은 변수는 Stack 영역에, dynamic과 같은 동적 할당된 영역은 heap 영역에 그리고 prinf와 같은 코드는 Text 영역에 배치된다. (리눅스와 윈도우도 비슷하다. 하지만 맥의 경우 조금 다르다.)
그림으로 나타내면 다음과 같다.
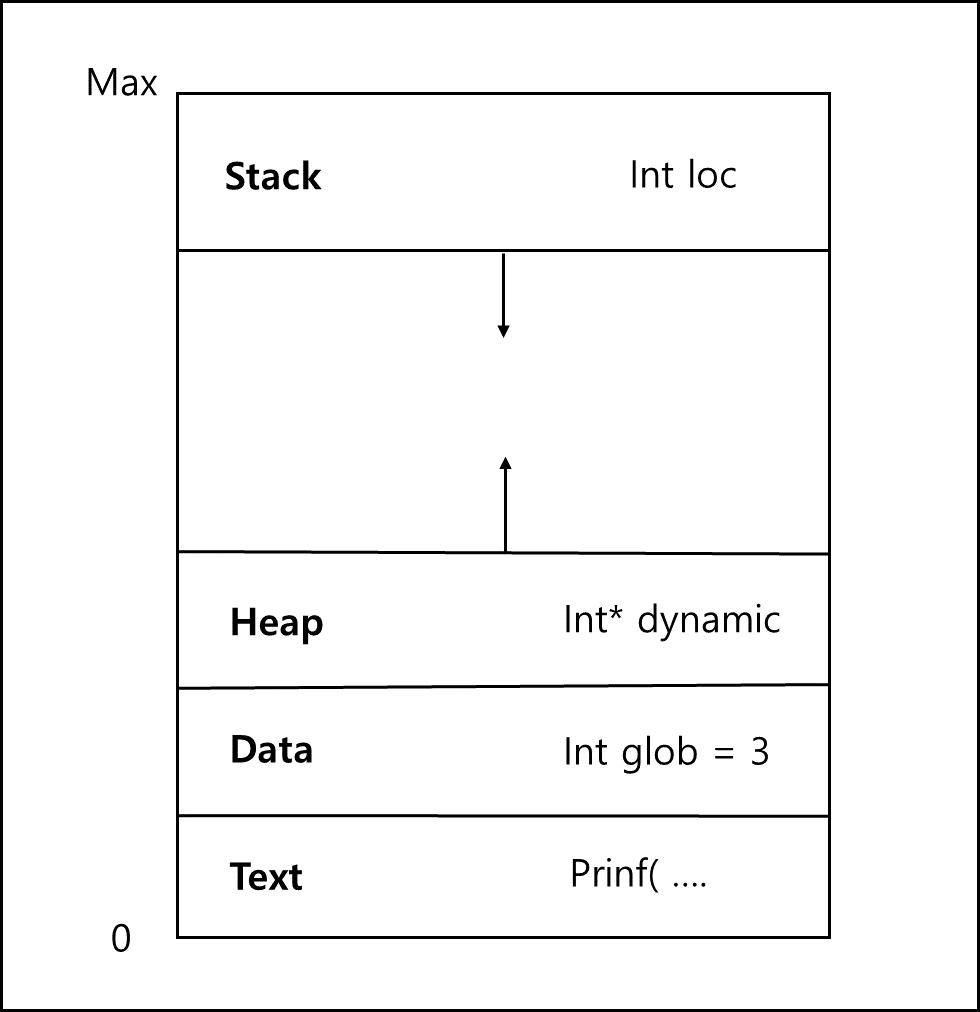
이러한 하나의 구조 전체를 프로세스라고 한다. 이러한 프로세스는 페이징을 통해 전체가 메모리에 쪼개져서 올라가게된다. (페이징은 OS 카테고리의 페이징과 세그멘테이션 부분을 참고하기 바란다)
이런 프로세스를 관리하기 위해서는 프로세스에 대한 정보가 필요하며 이러한 정보는 PCB라는 구조체에 담겨서 관리되게 된다.
PCB에는 다음과 같은 정보가 담기게 된다.
- PID (Process Identifier)
- Priority
- Waiting Event
- State
- Location of image in disk
- Location of image in memory
- open files
- directory
- state vector save area
- tty
- parent, child process
- execution time
하지만 이러한 PCB는 너무 용량이 많기 때문에 메모리에 통째로 올려둘 경우 메모리 용량을 너무 많이 차지 않다. 그래서 프로세스 영역과 유저 영역으로 나누어 프로세스 영역은 메모리에 상주 시키고 유저 영역은 DISK에 넣어두어 필요할때 불러쓴다.
위의 PCB를 보면 알겠지만 프로세스 단위로 리소스를 할당하게 된다. 그렇기 때문에 프로세스는 리소스의 할당 단위이다. 또한 서로 다른 프로세스가 서로의 영역을 침범하지 못하게 메모리 보호가 걸려있다. 이 역시 프로세스 단위로 보호가 걸려있기 때문에 보호의 단위이기도 하다.
스레드
스레드는 사실상 프로세스의 하위 개념이다. 프로세스가 별도의 스레드를 만들지 않았다면 프로세스가 한 개의 스레드로 돌아가는 것이다. 그렇기 때문에 스레드는 작업의 단위이며 작업의 단위이기 때문에 곧 스케줄링의 대상이 된다.
다수의 스레드가 한 개의 프로세스에서 돌아간다고 가정하면 스레드 간에 코드와 데이터, heap은 공유되나 스레드의 스택이나 레지스터의 상태는 공유되지 않는다. 그렇기 때문에 어떤 데이터를 공유하며 다른 작업을 요할 경우 멀티 스레드로 구동하는게 현명한 방법이다.
참고 자료
- Operating System Concept (written by Silberschatz, Galvin and Gagne)