파일 시스템 - EXT
3. EXT
1) 개요
ext(extended file system, 확장 파일 시스템)는 리눅스용 파일 시스템 가운데 하나로 만든 이는 스테펜 트위디(Stephen Tweedie)이다. 1992년 4월에 처음 모습을 드러냈으며 오늘날 많은 리눅스 배포판에서 주 파일 시스템으로 쓰이고 있다.
a. ext2
Rémy Card가 ext(extended file system, 확장 파일 시스템)를 대체하기 위해 만들었으며 1993년 1월에 릴리즈했다. 아래의 OS에 대해 지원을 했다.
1
NetBSD, FreeBSD, the GNU HURD, Windows 95/98/NT, OS/2 and RISC OS.
유닉스의 파일 시스템과 많은 속성을 공유하고 있으며 블럭이나 아이노드, 디렉토리에 대한 컨셉이 그 예시이다. 이론상 최대 파일의 크기는 2TB, 최대 볼륨의 크기는 32TB이다.
b. ext3
ext3는 1999년 9월에 Stephen Tweedie가 작성하여 출시되었다. 이 ext3는 자료의 손실없이 ext2에서 바로 변경이 가능했는데 따라서 ext2와 ext3간의 파일 시스템은 상호 변환이 가능하다. ext2에서 ext3로 넘어오면서 달라진 부분이 무엇이냐고 한다면 역시 저널링 기능의 강화를 이야기할 수 있는데 이 저널링이라는 것은 저널링 파일 시스템의 준말로 파일 시스템에 번경사항을 반영하기 전에 저널 안에 생성되는 변경사항을 추적하는 파일 시스템이라고 말할 수 있다. 이 저널링에 대해서는 3단계 저널링을 지원한다.
Journal
두 파일 시스템의 메타 데이터와 파일 컨텐츠는 메인 파일 시스템에 전달되기전에 저널에 기록부터 한다. 문제가 생길시 저널 파일에서 빠르게 복구가 가능하나, 모든 파일 작업간에 저널에 한번 메인 파일 시스템에 한번씩 작업하기 때문에 성능이 느려질 수 있다.Ordered
메타 데이터만 저널에 기록된다. 파일 컨텐츠는 기록되지는 않지만 메타데이터가 저널에 기록되면 파일 컨텐츠는 디스크에 반드시 기록한다. 리눅스 배포판에서 기본값으로 설정되어있는데, 파일 쓰는 도중 꺼져버리면 저널은 새로운 파일을 가리키거나 추가된 데이터가 넘겨지지 않으며 삭제되어버린다. 요컨대 복구가 안될 수도 있고 데이터가 꼬여버릴 수도 있다.Writeback
메타 데이터만 저널에 기록되며 파일 내용은 기록되지 않는다. 리스크가 가장 큰 방법이며 충돌 바로전에 수정된 파일들은 손상 될 수 있다. 오래된 파일일 수록 저널이 복구된 뒤에 예상치 못한 결과가 나타날 수 있다. 성능적으로는 가장 빠르다.
ext3에서의 파일 최대 크기는 2TiB이며, 최대 볼륨 크기는 16Tib이다. 이는 블록 크기를 몇으로 두느냐에 따라 달라질 수 있다.
c. ext4
64bit 기억 공간 제한을 없애고 ext3의 성능을 향상시키고 하위 호환성이 있는 확장 버전으로써 만들어졌다. 하지만 아예 ext3에서 fork하여 ext4로 이름을 변경하였고 ext3를 유지보수하던 Theodore Ts’o는 ext4에 대한 계획을 발표하였다.
기본적으로 ext3의 fork 버전이었기에 ext3에서 ext4로 변경시키는 것이 가능하며 ext2는 ext3와 호환되기 때문에 ext2에서 ext4로도 변경이 가능하다.
지연된 할당 기능을 사용할 수 있는데, 데이터가 디스크에 쓰여지기전에 블록 할당을 지연시키고 실제 크기에 기반하여 블록할당을 결정한다. 이러면 블록할당에 대해 최적의 블록을 선출할 수 있게 되고 하나의 파일에 대한 블록이 여러곳으로 분산되는 현상을 막게되어 성능을 향상시킨다. (단편화 방지) 하지만 이 기능의 경우 디스크에 쓰기전에 지연이 발생하므로 커널 패닉이나 전원 차단시 데이터 손실이 날 수 있는데 2.6.30버전 이후에는 커널에서 이상을 알아차리고 이전으로 롤백이 가능하게 되었다.
이전에 ext3에서는 하위 디렉터리 수가 32,000개로 제한되어있다. 이 제한은 ext4에서 64,000개로 늘어났으며 dir_nlink 기능으로 더 큰 개수도 가능하다.
ext4에서 단일 파일의 최대 크기는 16TiB, 최대 볼륨 크기는 1EiB이다.
2) 세부 구조
ext4의 구조만 살펴보도록 하겠다. 기본적으로 ext4는 블록단위로 저장 공간을 할당한다. 블록은 1KiB에서 64Kib 사이의 섹터 그룹이며 섹터수는 2의 거듭제곱 수여야 한다. 이 블록의 크기가 페이지 크기보다는 작아야 마운팅 문제가 발생하지 않는다. 파일시스템은 일반적으로는 2^32개, 64bit 일 경우 2^64개 블록을 가질 수 있다. 이러한 블록은 블록 그룹이라는 그룹으로 묶여있다. 아래는 표준 블록 그룹의 레이아웃을 나타낸 그림이다.
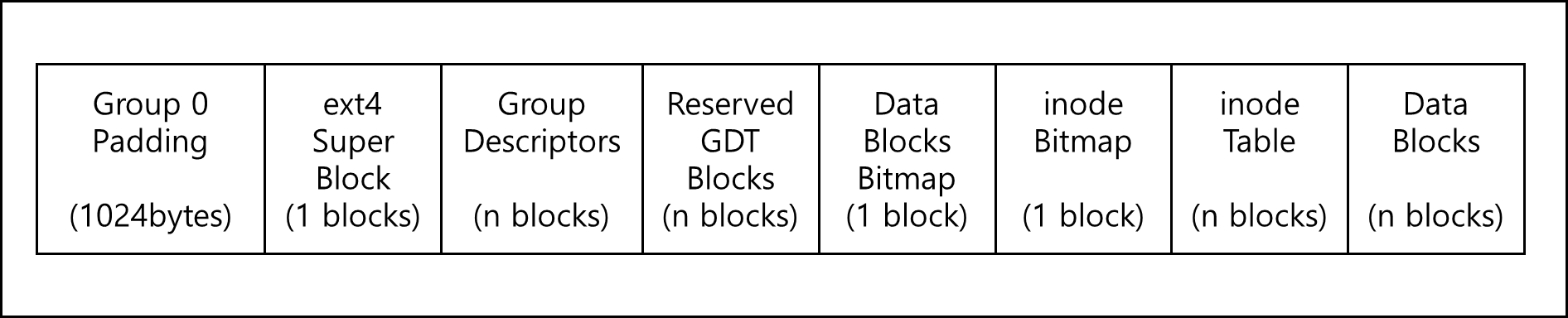
Group Padding 0는 말 그대로 비어있으며 1024바이트 만큼이다. 이 패딩에는 보통 x86부트 섹터나 이상한 것들을 설치 할 수 있다.
그 다음 수퍼블록은 그다음 블록인 블록 1에 들어가는데 이 슈퍼블록은 아래와 같은 정보들를 포함하고 있다.
- 전체 inode 개수
- 전체 블록의 개수
- 슈퍼유저에 의해 할당될 수 있는 블록의 개수
- 할당되지 않은 inode의 개수
- 할당되지 않은 블록의 개수
- 첫번째 데이터 블록
- 블록의 사이즈
- 그룹당 블록의 개수
이외에도 추가적인 정보를 담고 있다.
Block Group Descriptor와 Reserved GDT Blocks는 블록 그룹에 대한 정보이며 아래와 같은 정보를 담고 있다.
- 블록 비트맵 위치의 하위 32bit
- inode 비트맵 위치의 하위 32bit
- inode 테이블 위치의 하위 32bit
- 여유 블록 수의 하위 16bit
이외에도 추가적인 정보들이 있다.
Data block bitmap과 inode bitmap은 해당 데이터 블록과 inode 테이블의 항목이 사용중인지 표시하는 부분이다.
Inode Table은 파일정보를 저장하고, Data Block은 실제 데이터가 저장되는 곳이다.