GPU 프로그래밍 - CUDA Stream 간 동기화
CUDA Stream 간 동기화
이전에 cuda 문법에 대해서 포스팅한 적이 있다.
이번에는 Stream 동기화에 대해서 좀 더 알아보도록 하겠다.
1. 개요
GPU를 잘 사용한다는 것은 GPU를 100% 활용한다는 것이다.
일반적으로 Branch가 적고 Memory coalescing을 지키며 Warp Occupancy가 높고, Shared Memory를 적극적으로 활용하면 일반적으로는 GPU를 잘 쓴다고 할 수 있다. (물론 더 잘하는 사람들은 Texture Memory까지 사용하여 가속화하기도한다)
있는 메모리를 잘 쓰는 것도 매우 중요하지만, 여기에 더불어 중요한게 있으니 Synchronization을 이용한 Computation - Communication Overlap이다.
기본적으로 GPU는 아래의 순서대로 작업한다.
- HOST에서 GPU의 VRAM으로 데이터를 복사해온다.
- VRAM에서 해당 데이터를 주어진 커널에 따라 연산한다.
- 연산한 결과를 VRAM에서 HOST RAM으로 복사한다.
이 과정이 순차적으로 1이 끝나고 2가 시작되고, 2가 끝나고 3이 시작되는 식으로 처리된다면 일반적인 프로그램 실행 순서겠지만, 사실 1,3은 생각보다 꽤 긴 시간이 필요하다.
일반적인 Memory에 접근하는 것으로 생각할 수 있지만, PCI-express를 타고 데이터가 왔닥 갔다 하기 때문이다.
때문에 CUDA에서 제공하는 Stream 기능을 이용하여 데이터 전송 부분을 비동기적으로 운용하는 것이다.
2. Stream Synchronization
STREAM을 한 개만 사용하여 VECTOR 두 개를 더하는 연산을 3번 한다고 해보자. 각각 다른 값을 가졌지만 동일한 크기 N을 가진 VECTOR 1~6을 1-2, 3-4, 5-6 끼리 더하는 연산이다. VECTOR 1~6은 Pinned Memory에 저장되어있으며 코드로 나타내면 아래와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// .... 전략 ......
cudaMalloc(&GPU_vector1,sizeof(float)*N);
cudaMalloc(&GPU_vector2,sizeof(float)*N);
cudaMalloc(&GPU_vector1_2,sizeof(float)*N);
cudaMalloc(&GPU_vector3,sizeof(float)*N);
cudaMalloc(&GPU_vector4,sizeof(float)*N);
cudaMalloc(&GPU_vector3_4,sizeof(float)*N);
cudaMalloc(&GPU_vector5,sizeof(float)*N);
cudaMalloc(&GPU_vector6,sizeof(float)*N);
cudaMalloc(&GPU_vector5_6,sizeof(float)*N);
cudaMemcpy(GPU_vector1,vector1,sizeof(float)*N,cudaMemcpyHostToDevice);
cudaMemcpy(GPU_vector2,vector2,sizeof(float)*N,cudaMemcpyHostToDevice);
cudaMemcpy(GPU_vector3,vector3,sizeof(float)*N,cudaMemcpyHostToDevice);
cudaMemcpy(GPU_vector4,vector4,sizeof(float)*N,cudaMemcpyHostToDevice);
cudaMemcpy(GPU_vector5,vector5,sizeof(float)*N,cudaMemcpyHostToDevice);
cudaMemcpy(GPU_vector6,vector6,sizeof(float)*N,cudaMemcpyHostToDevice);
dim3 threads = {512,1,1};
dim3 blocks = {(N+threads.x-1)/threads.x,1,1};
vectorAdd <<< blocks, threads >>> (GPU_vector1,GPU_vector2,GPU_vector1_2,N);
vectorAdd <<< blocks, threads >>> (GPU_vector3,GPU_vector4,GPU_vector3_4,N);
vectorAdd <<< blocks, threads >>> (GPU_vector5,GPU_vector6,GPU_vector5_6,N);
cudaMemcpy(vector1_2,GPU_vector1_2,sizeof(float)*N,cudaMemcpyDeviceToHost);
cudaMemcpy(vector3_4,GPU_vector3_4,sizeof(float)*N,cudaMemcpyDeviceToHost);
cudaMemcpy(vector5_6,GPU_vector5_6,sizeof(float)*N,cudaMemcpyDeviceToHost);
// ... 후략 ....
별도의 스트림을 지정하지 않았지만 별도의 스트림을 지정하지 않았다면 default stream에서 모두 실행된다.
이를 그림으로 표현하면 아래와 같다.
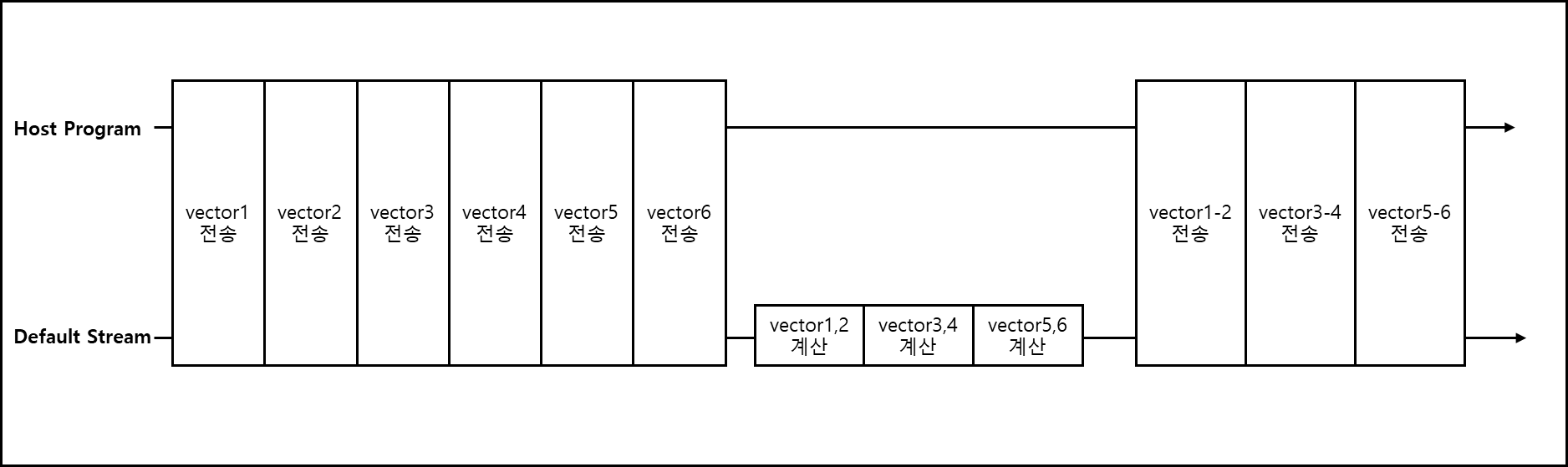
기본적으로 cudaMalloc은 host와 묵시적으로 동기화된다. 기본 stream만 사용하면 위와 같은 그림으로 실행된다.
※ 내용 업데이트 및 추가적인 검증 예정
1) Double buffering
하나의 stream을 하나 더 추가하여 구동하면 아래와 같은 코드가 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
// ... 전략 ....
// 비동기 전송을 위해 호스트 메모리를 pinned으로 등록(또는 cudaMallocHost로 미리 할당)
CHECK(cudaHostRegister(vector1, bytes, cudaHostRegisterDefault));
CHECK(cudaHostRegister(vector2, bytes, cudaHostRegisterDefault));
CHECK(cudaHostRegister(vector3, bytes, cudaHostRegisterDefault));
CHECK(cudaHostRegister(vector4, bytes, cudaHostRegisterDefault));
CHECK(cudaHostRegister(vector5, bytes, cudaHostRegisterDefault));
CHECK(cudaHostRegister(vector6, bytes, cudaHostRegisterDefault));
CHECK(cudaHostRegister(vector1_2, bytes, cudaHostRegisterDefault));
CHECK(cudaHostRegister(vector3_4, bytes, cudaHostRegisterDefault));
CHECK(cudaHostRegister(vector5_6, bytes, cudaHostRegisterDefault));
// 2개의 stream
const int STREAMS = 2;
cudaStream_t streams[STREAMS];
for (int s=0;s<STREAMS;s++) CHECK(cudaStreamCreate(&streams[s]));
// device ping-pong buffers: 각 stream마다 하나씩
float *d_a[STREAMS], *d_b[STREAMS], *d_out[STREAMS];
for (int s=0;s<STREAMS;s++) {
CHECK(cudaMalloc(&d_a[s], bytes));
CHECK(cudaMalloc(&d_b[s], bytes));
CHECK(cudaMalloc(&d_out[s], bytes));
}
// 호스트 벡터들을 pair 배열로 정리 (처리 순서)
float* hostA[3] = { vector1, vector3, vector5 };
float* hostB[3] = { vector2, vector4, vector6 };
float* hostOut[3] = { vector1_2, vector3_4, vector5_6 };
// launch parameters
dim3 threads(512);
dim3 blocks( (N + threads.x - 1) / threads.x );
// 각각의 pair를 순서대로 제출 (stream은 i % 2로 토글)
for (int i=0;i<3;i++) {
int s = i % STREAMS; // 사용할 stream & ping-pong 버퍼 인덱스
// H2D (async)
CHECK(cudaMemcpyAsync(d_a[s], hostA[i], bytes, cudaMemcpyHostToDevice, streams[s]));
CHECK(cudaMemcpyAsync(d_b[s], hostB[i], bytes, cudaMemcpyHostToDevice, streams[s]));
// kernel in the same stream
vectorAdd<<<blocks, threads, 0, streams[s]>>>(d_a[s], d_b[s], d_out[s], N);
// check kernel launch error (deferred until stream sync, but we can check last error)
CHECK(cudaGetLastError());
// D2H (async)
CHECK(cudaMemcpyAsync(hostOut[i], d_out[s], bytes, cudaMemcpyDeviceToHost, streams[s]));
// (선택) 필요하면 이벤트로 완료 시점을 기록하거나 host에서 사용하기 전에 stream 동기화를 한다.
// 여기서는 마지막에 모든 stream을 sync 함.
}
// 모든 stream 완료 대기
for (int s=0;s<STREAMS;s++) CHECK(cudaStreamSynchronize(streams[s]));
// (검증 예시)
printf("sample outputs: %f, %f, %f\n", vector1_2[0], vector3_4[0], vector5_6[0]);
// 정리
for (int s=0;s<STREAMS;s++) {
CHECK(cudaFree(d_a[s]));
CHECK(cudaFree(d_b[s]));
CHECK(cudaFree(d_out[s]));
CHECK(cudaStreamDestroy(streams[s]));
}
CHECK(cudaHostUnregister(vector1));
CHECK(cudaHostUnregister(vector2));
CHECK(cudaHostUnregister(vector3));
CHECK(cudaHostUnregister(vector4));
CHECK(cudaHostUnregister(vector5));
CHECK(cudaHostUnregister(vector6));
CHECK(cudaHostUnregister(vector1_2));
CHECK(cudaHostUnregister(vector3_4));
CHECK(cudaHostUnregister(vector5_6));
// ... 후략 ....
이를 그림으로 표현하면 아래와 같다.
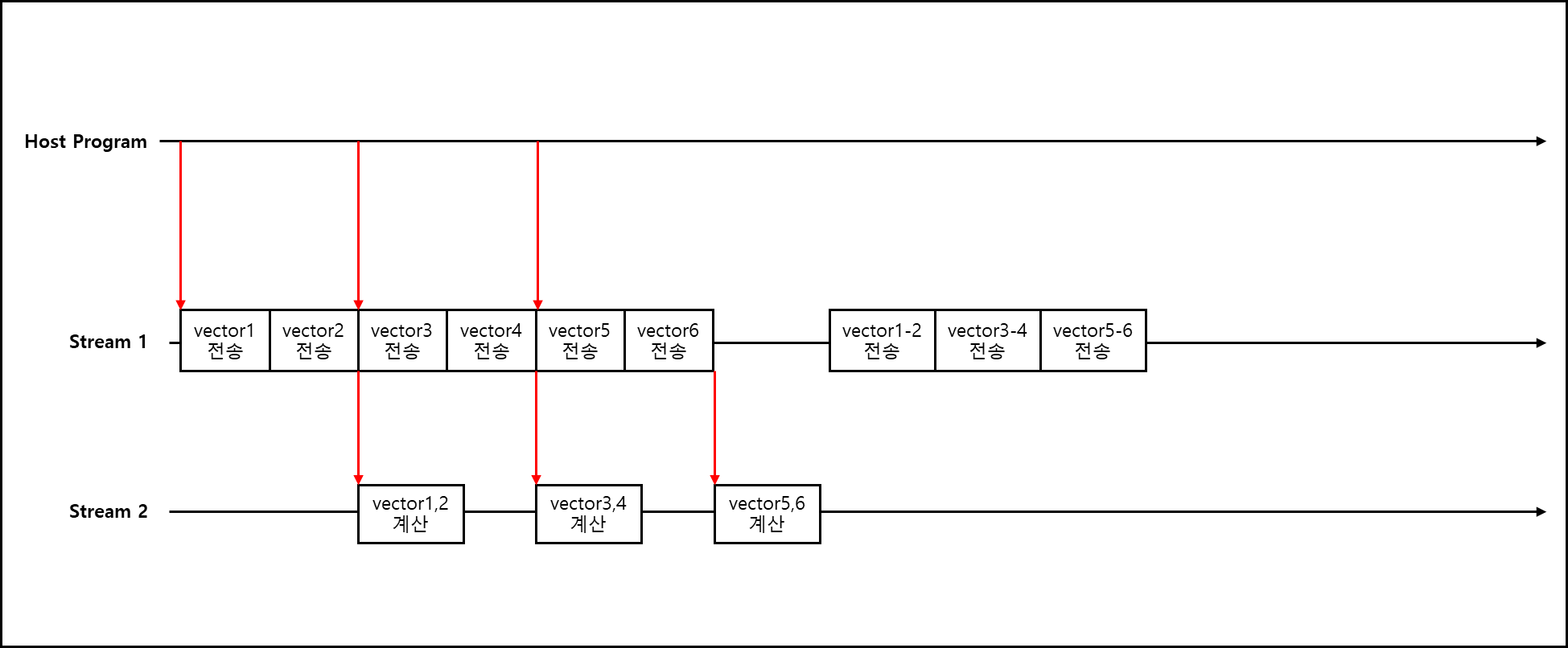
Steam 하나는 데이터 전송용으로 다른 하나는 계산용으로 사용하는 것이다. Stream이 따로 작동하여 overlap되면 overlap 된 시간만큼 전체 시간 소요가 줄어든다.
※ 내용 업데이트 및 추가적인 검증 예정
2) Triple Buffering
stream을 하나 더 추가하여 하나는 출력 stream으로 사용할 경우의 코드이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
// ... 전략 ...
// 1) pinned host memory 필요 (async memcpy)
CUDA_CHECK(cudaHostRegister((void*)h_A1, sizeof(float)*N, 0));
CUDA_CHECK(cudaHostRegister((void*)h_B1, sizeof(float)*N, 0));
CUDA_CHECK(cudaHostRegister((void*)h_C1, sizeof(float)*N, 0));
CUDA_CHECK(cudaHostRegister((void*)h_A2, sizeof(float)*N, 0));
CUDA_CHECK(cudaHostRegister((void*)h_B2, sizeof(float)*N, 0));
CUDA_CHECK(cudaHostRegister((void*)h_C2, sizeof(float)*N, 0));
CUDA_CHECK(cudaHostRegister((void*)h_A3, sizeof(float)*N, 0));
CUDA_CHECK(cudaHostRegister((void*)h_B3, sizeof(float)*N, 0));
CUDA_CHECK(cudaHostRegister((void*)h_C3, sizeof(float)*N, 0));
// 2) streams & events
cudaStream_t s_h2d, s_kernel, s_d2h;
CUDA_CHECK(cudaStreamCreate(&s_h2d));
CUDA_CHECK(cudaStreamCreate(&s_kernel));
CUDA_CHECK(cudaStreamCreate(&s_d2h));
// events to chain streams
cudaEvent_t ev_h2d_pair[3], ev_kernel_pair[3];
for (int i = 0; i < 3; ++i) {
CUDA_CHECK(cudaEventCreateWithFlags(&ev_h2d_pair[i], cudaEventDisableTiming));
CUDA_CHECK(cudaEventCreateWithFlags(&ev_kernel_pair[i], cudaEventDisableTiming));
}
// 3) per-pair device buffers (each pair has its own d_A,d_B,d_C)
float *dA[3], *dB[3], *dC[3];
size_t bytes = sizeof(float) * N;
for (int i = 0; i < 3; ++i) {
CUDA_CHECK(cudaMalloc(&dA[i], bytes));
CUDA_CHECK(cudaMalloc(&dB[i], bytes));
CUDA_CHECK(cudaMalloc(&dC[i], bytes));
}
const int threads = 512;
const int blocks = (N + threads - 1) / threads;
// --- Pair 0: vector1 & vector2 ---
CUDA_CHECK(cudaMemcpyAsync(dA[0], h_A1, bytes, cudaMemcpyHostToDevice, s_h2d));
CUDA_CHECK(cudaMemcpyAsync(dB[0], h_B1, bytes, cudaMemcpyHostToDevice, s_h2d));
CUDA_CHECK(cudaEventRecord(ev_h2d_pair[0], s_h2d)); // H2D 완료 표시
CUDA_CHECK(cudaStreamWaitEvent(s_kernel, ev_h2d_pair[0], 0)); // kernel 스트림은 H2D 대기
vectorAdd<<<blocks, threads, 0, s_kernel>>>(dA[0], dB[0], dC[0], N);
CUDA_CHECK(cudaGetLastError());
CUDA_CHECK(cudaEventRecord(ev_kernel_pair[0], s_kernel)); // kernel 완료 표시
CUDA_CHECK(cudaStreamWaitEvent(s_d2h, ev_kernel_pair[0], 0));// D2H 스트림은 kernel 대기
CUDA_CHECK(cudaMemcpyAsync(h_C1, dC[0], bytes, cudaMemcpyDeviceToHost, s_d2h));
// --- Pair 1: vector3 & vector4 ---
CUDA_CHECK(cudaMemcpyAsync(dA[1], h_A2, bytes, cudaMemcpyHostToDevice, s_h2d));
CUDA_CHECK(cudaMemcpyAsync(dB[1], h_B2, bytes, cudaMemcpyHostToDevice, s_h2d));
CUDA_CHECK(cudaEventRecord(ev_h2d_pair[1], s_h2d));
CUDA_CHECK(cudaStreamWaitEvent(s_kernel, ev_h2d_pair[1], 0));
vectorAdd<<<blocks, threads, 0, s_kernel>>>(dA[1], dB[1], dC[1], N);
CUDA_CHECK(cudaGetLastError());
CUDA_CHECK(cudaEventRecord(ev_kernel_pair[1], s_kernel));
CUDA_CHECK(cudaStreamWaitEvent(s_d2h, ev_kernel_pair[1], 0));
CUDA_CHECK(cudaMemcpyAsync(h_C2, dC[1], bytes, cudaMemcpyDeviceToHost, s_d2h));
// --- Pair 2: vector5 & vector6 ---
CUDA_CHECK(cudaMemcpyAsync(dA[2], h_A3, bytes, cudaMemcpyHostToDevice, s_h2d));
CUDA_CHECK(cudaMemcpyAsync(dB[2], h_B3, bytes, cudaMemcpyHostToDevice, s_h2d));
CUDA_CHECK(cudaEventRecord(ev_h2d_pair[2], s_h2d));
CUDA_CHECK(cudaStreamWaitEvent(s_kernel, ev_h2d_pair[2], 0));
vectorAdd<<<blocks, threads, 0, s_kernel>>>(dA[2], dB[2], dC[2], N);
CUDA_CHECK(cudaGetLastError());
CUDA_CHECK(cudaEventRecord(ev_kernel_pair[2], s_kernel));
CUDA_CHECK(cudaStreamWaitEvent(s_d2h, ev_kernel_pair[2], 0));
CUDA_CHECK(cudaMemcpyAsync(h_C3, dC[2], bytes, cudaMemcpyDeviceToHost, s_d2h));
// 동기화: 각 스트림 끝까지 대기
CUDA_CHECK(cudaStreamSynchronize(s_h2d));
CUDA_CHECK(cudaStreamSynchronize(s_kernel));
CUDA_CHECK(cudaStreamSynchronize(s_d2h));
// 정리
for (int i = 0; i < 3; ++i) {
CUDA_CHECK(cudaEventDestroy(ev_h2d_pair[i]));
CUDA_CHECK(cudaEventDestroy(ev_kernel_pair[i]));
CUDA_CHECK(cudaFree(dA[i]));
CUDA_CHECK(cudaFree(dB[i]));
CUDA_CHECK(cudaFree(dC[i]));
}
CUDA_CHECK(cudaStreamDestroy(s_h2d));
CUDA_CHECK(cudaStreamDestroy(s_kernel));
CUDA_CHECK(cudaStreamDestroy(s_d2h));
CUDA_CHECK(cudaHostUnregister((void*)h_A1));
CUDA_CHECK(cudaHostUnregister((void*)h_B1));
CUDA_CHECK(cudaHostUnregister((void*)h_C1));
CUDA_CHECK(cudaHostUnregister((void*)h_A2));
CUDA_CHECK(cudaHostUnregister((void*)h_B2));
CUDA_CHECK(cudaHostUnregister((void*)h_C2));
CUDA_CHECK(cudaHostUnregister((void*)h_A3));
CUDA_CHECK(cudaHostUnregister((void*)h_B3));
CUDA_CHECK(cudaHostUnregister((void*)h_C3));
// ....후략....
이를 그림으로 표현하면 아래와 같다.
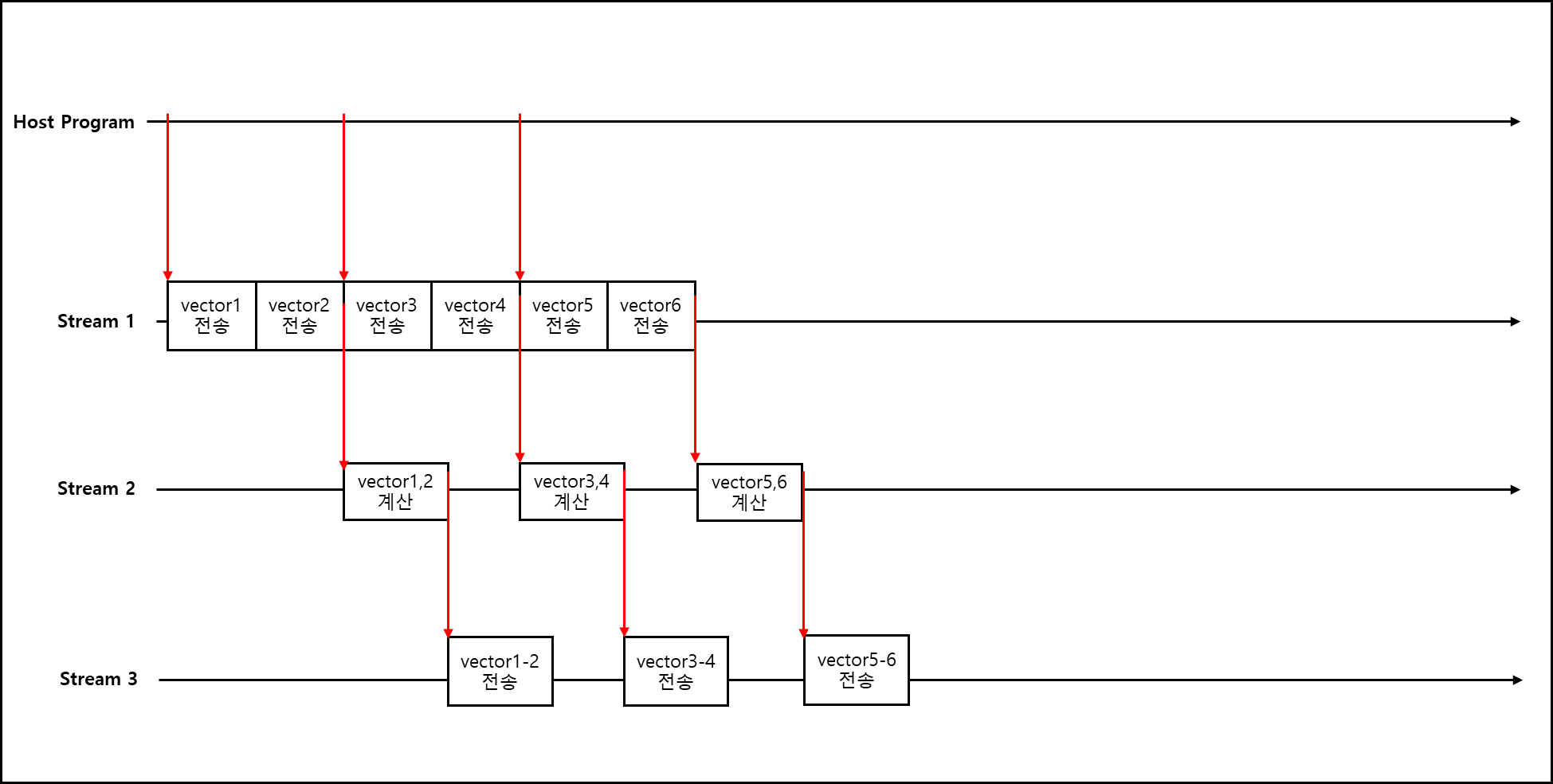
overlap이 추가적으로 일어나서 좀 더 실행 시간이 감소한 것을 볼 수 있다.
※ 주의사항
위 다중 버퍼링을 쓰기 위해서는 Hardware에서 지원해야한다.
논리적으로는 많은 수의 Stream을 사용할 수 있지만 Hardware에서 해당 Stream을 동시에 처리하는 것을 지원하지 않는다면 단순히 순차적으로 실행될 뿐이다.
이를 위해서는 cuda에서 nvcc로 아래의 코드를 포함해서 빌드한 뒤에 결과를 확인해야한다.
1
2
3
cudaDeviceProp test;
cudaGetDeviceProperties(&test,0);
printf("engine count : %d",test.asyncEngineCount);
engine count 값에 대한 설명은 아래와 같다.
0 : 비동기 복사/중첩 미지원 1 : 호스트↔디바이스 복사와 커널 실행을 동시에 지원(단방향) 2 : H2D와 D2H를 동시에 (양방향) 진행하면서 커널도 실행 가능.
※ 내용 업데이트 및 추가적인 검증 예정