Database - Logging
Logging
1. 개요
DB에 어떤 값을 썼을 때 해당 값의 영속성이 보장되어야하는데 컴퓨터 시스템이라는게 여러가지 이유로 FAIL이 날 수 있다.
이 FAIL을 Crash라고 하고 Crash로 인해 일관성이 깨진 데이터를 복구 시키는걸 Recovery라고 한다. (사실 그냥 영어로 바꾼거긴하지만) 이 Recovery를 위한 알고리즘은 장애 발생시에도 데이터 베이스 일관성, 트랜잭션 원자성 및 내구성을 보장하는 기술이다.
이 알고리즘은 크게 두 part로 나누게 된다.
Crash가 터지기전 미리 작업을 해두는 것과, Crash 이후에 하는 처리가 바로 그것이다.
이번 포스팅은 Crash가 터지기전에 미리 작업을 해두는 방법인 Logging에 대해서 알아보겠다.
2. Failure 분류
1) Transaction Failures
a. 논리적 오류
- 무결성 제약 조건 위반 : Primary 키가 중복되어 삽입된 경우
- 비즈니스 로직 오류 : 금액이 0 이상이어야하는데 이하로 떨어진 경우
- 처리 되지 않은 예외 : 저장 프로시저 내부에서 예외가 발생했지만 제대로 처리되지 않은 경우
b. 내부 상태 오류
lock을 쓰는 DBMS의 경우 Deadlock이 발생하여 활성된 트랜잭션을 종료하는 경우
2) System Failure
a. 소프트웨어 문제
OS나 DBMS의 자체적인 문제이다(가령 0으로 나누기 예외 처리를 안했다던지)
b. 하드웨어 문제
컴퓨터가 DBMS를 호스팅하다가 Power가 나가거나 하드웨어적인 문제가 발생하는 경우이다.
시스템 충돌(예: 정전, 커널 패닉)이 발생하면 시스템은 즉시 깨끗하게 멈추고, 비휘발성 저장소(예: SSD, HDD, NVM)에 이미 기록된 데이터는 손상되지 않는다고 간주한다.
- 손상되지 않음은 사실 비휘발성 저장소를 만드는 부분에서 보증이 되어야한다. 따라서 우리는 일단 그렇게 간주하고 생각한다.
3) Storage Media Failures
a. 수리 불가능한 하드웨어 오류
헤드 충돌 또는 이와 비슷한 오류로 비휘발성 저장 장치 전체 혹은 일부가 손상
이 손상은 감지 가능한 것으로 간주되며 문제 발생시 별도의 보관된 버전에서 복원해야한다(RAID된 데이터라던지)
3. 데이터베이스의 기본 작동 구조
1) Buffer Pool
비휘발성 메모리(HDD나 SSD)는 휘발성 메모리(DRAM)에 기재하는 것보다 훨씬 느리다. 따라서 DBMS에 데이터를 쓸때 아래와 같은 절차를 거친다.
- 먼저 메모리에 데이터를 복사해오고
- 복사된 데이터에서 쓰기 작업을 한뒤
- 쓰기된 데이터를 비휘발성 메모리에 기재한다.
이 과정에서 임시로 쓰여지는 휘발성 메모리의 구역을 Buffer Pool이라고 한다.
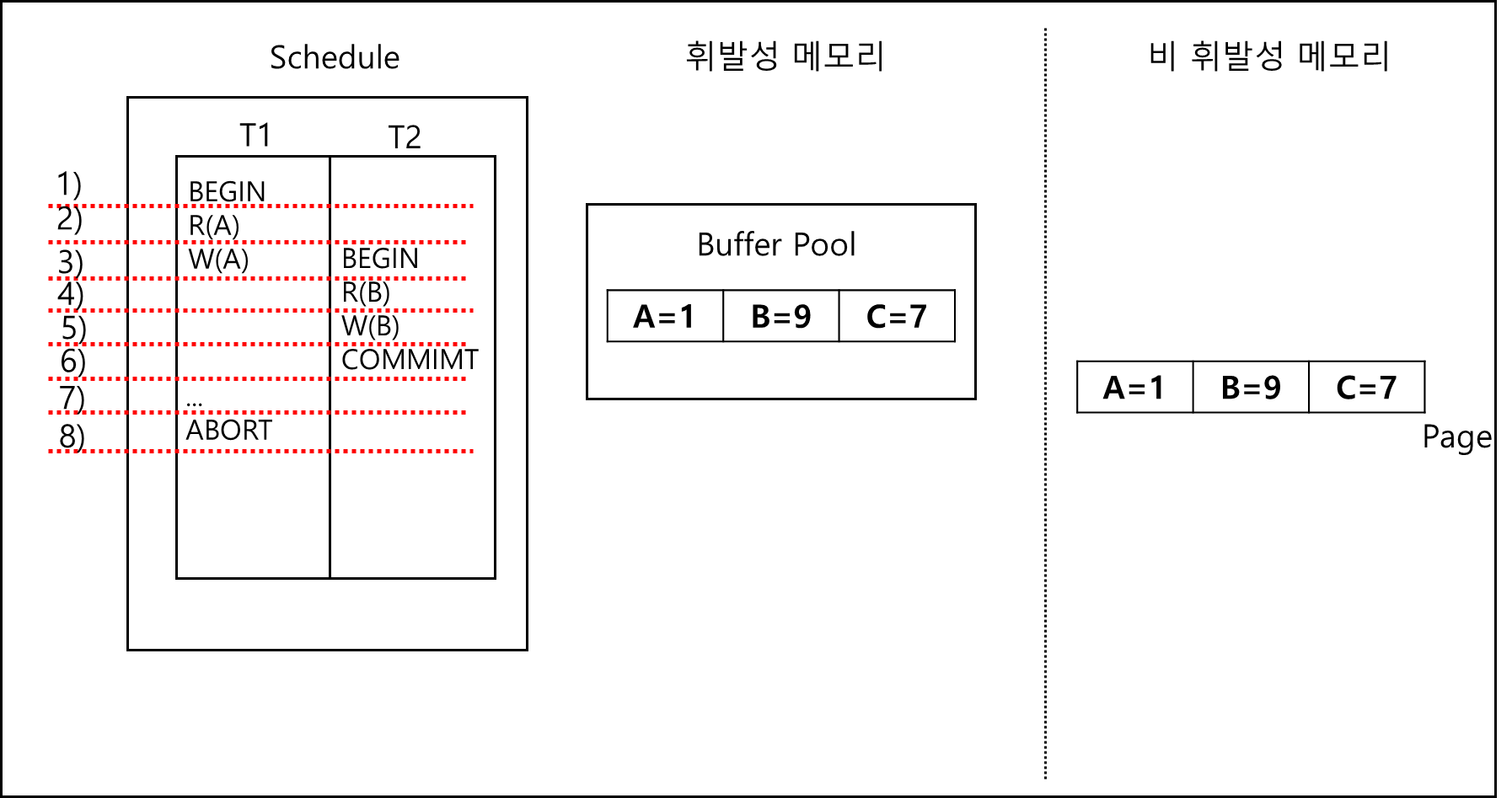
위 그림을 보자. 트랜잭션 1과 2가 있을때 임시 변경되는 것은 Buffer Pool에서 처리되고 commit 된 것들은 비 휘발성 메모리의 영역으로 넘어가서 해당 page에 기재된다.
3번 줄의 경우 A 값에 쓰기를 하여 변경하는데 이 경우 Buffer Pool에서 A값이 1이 아닌 다른 값이 될 수 있다. (같은 값으로 덮어쓰기 할 수도 있긴하다)
5번 줄의 경우 트랜잭션 2에서 B를 쓰게 되는데 Buffer Pool에서 B값이 9가 아닌 다른 값이 될 수 있다. 이후 트랜잭션 2에서 Commit을 하게 되고 데이터의 영속성을 위해서 비휘발서 메모리에 기재되어야 한다. 이때 트랜잭션 1에서 수정한 A값까지 같이 반영해야하는가가 문제다.
스케줄표를 보면 심지어 트랜잭션 1이 ABORT가 되기 때문에 작업한 A의 값도 돌려놔야한다. 이 경우 COMMIT의 대상이 아닌 데이터를 반영하게 되면 Steal Policy를 따른다고하고, 반영하지 않으면 Non-steal Policy를 따른다고 한다.
Non-steal Policy라면 작업 대상 페이지를 복사해서 Commit 대상의 데이터만 적용된 별도의 페이지로 만든 뒤 비휘발성 메모리에 반영시킨다.
굳이 Commit할때 따박 따박 모두 비휘발성 메모리에 써야할까? Commit마다 비 휘발성 메모리에 기재하면 Force Policy를 따른다고 하고, 항상 그때마다 기재하는건 아니라면 Non-Force Policy를 따른다고 한다.
2) Redo VS Undo
이 과정에서 DBMS는 다음 사항을 보장해야한다.
- 트랜잭션이 이미 커밋된 경우 데이터는 영속적이다.
- 트랜잭션이 중단된 경우 부분적인 변경사항은 영속적으로 처리되지 않는다.
이를 보장하기 위해 Redo와 Undo를 사용한다.
Redo
지속성을 위해 이미 완료된 거래의 효과를 다시 적용하는 과정Undo
불완전하거나 중단된 거래의 효과를 제거하는 과정
4. Shadow Paging
1) 개요
DBMS는 전체 데이터베이스를 복사하는 대신에 쓰기 작업시에 페이지를 복사하여 두 가지 버전을 생성한다.
- master : 커밋된 트랜잭션의 변경 사항만 포함한다.
- Shadow : 커밋되지 않은 트랜잭션의 변경 사항이 포함된 임시 데이터베이스이다.
트랜잭션이 커밋될 때 업데이트를 설치하려면 루트를 덮어써서 섀도우를 가리키도록 하여 마스터와 섀도우를 바꾸게 된다. 기본적으로 이 Shadow Paging은 Buffer Pool Policy가 No-Steal + Force 정책이다.
2) 작동 예시
실질적인 예시를 들어 설명해보겠다.
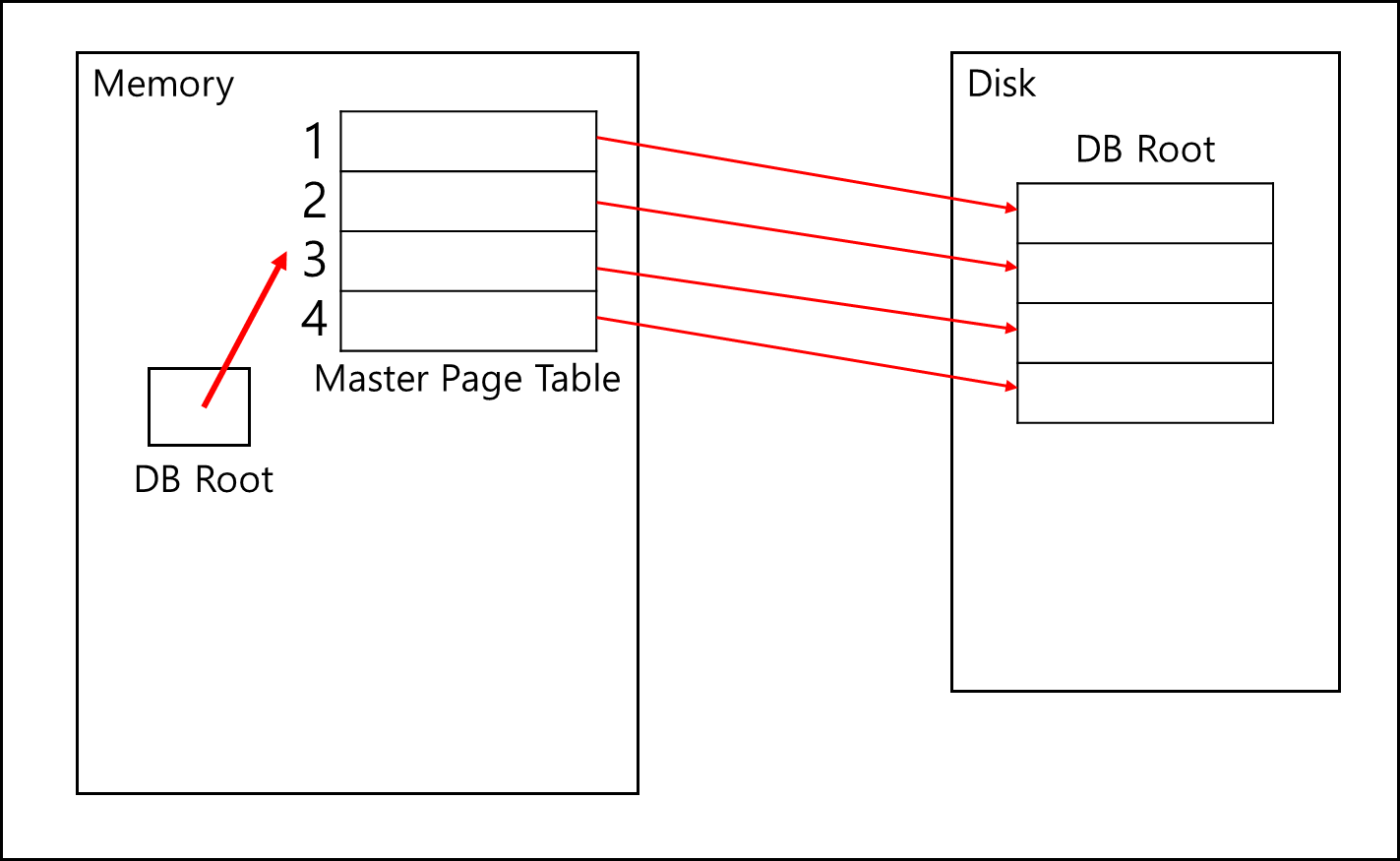
기본적으로 메모리에 Read-Only인 Master Page Table이 있다.
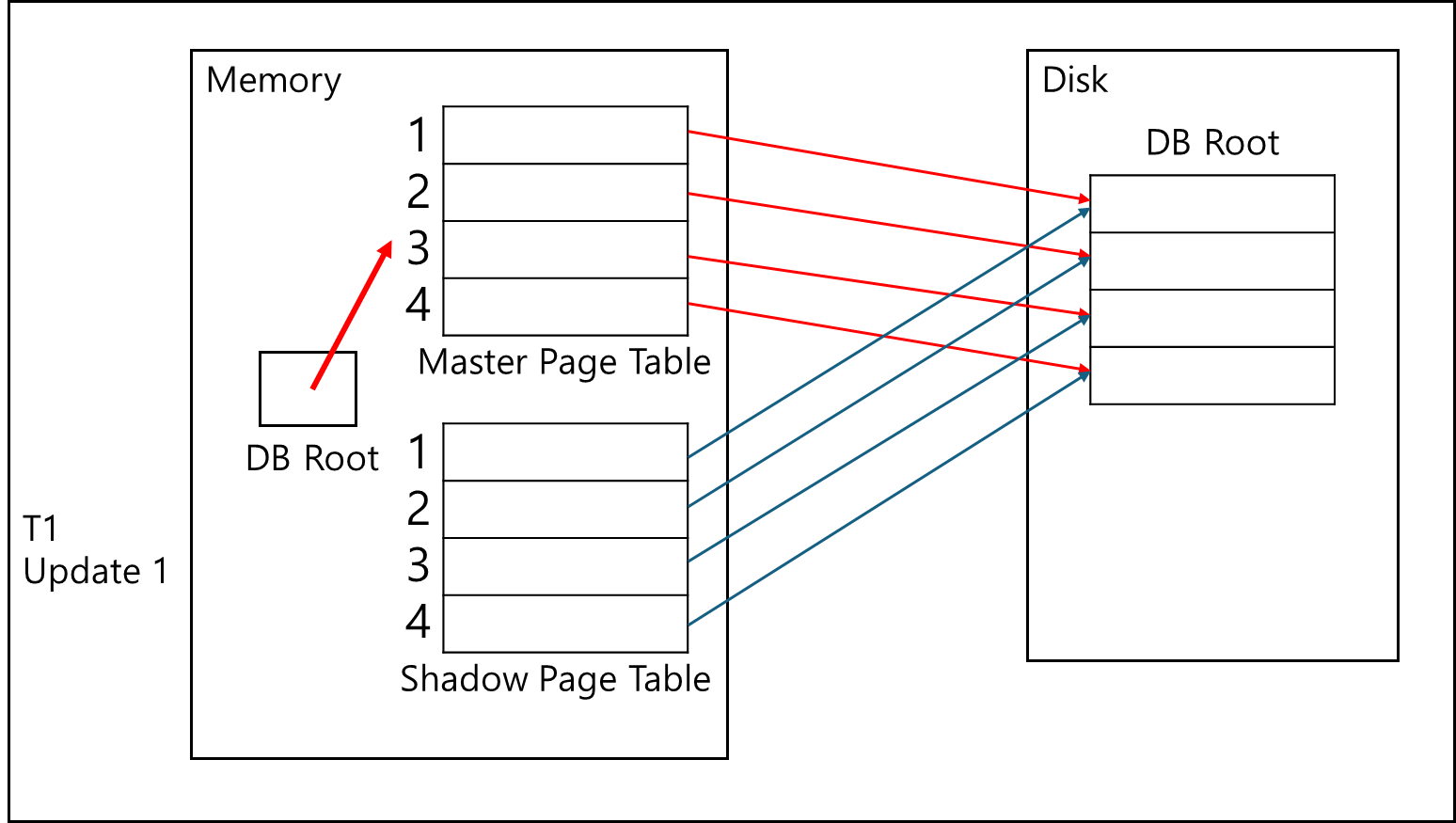
트랜잭션이 들어오게 되면 해당 페이지 테이블을 복사하여 메모리에서 운용하게된다.
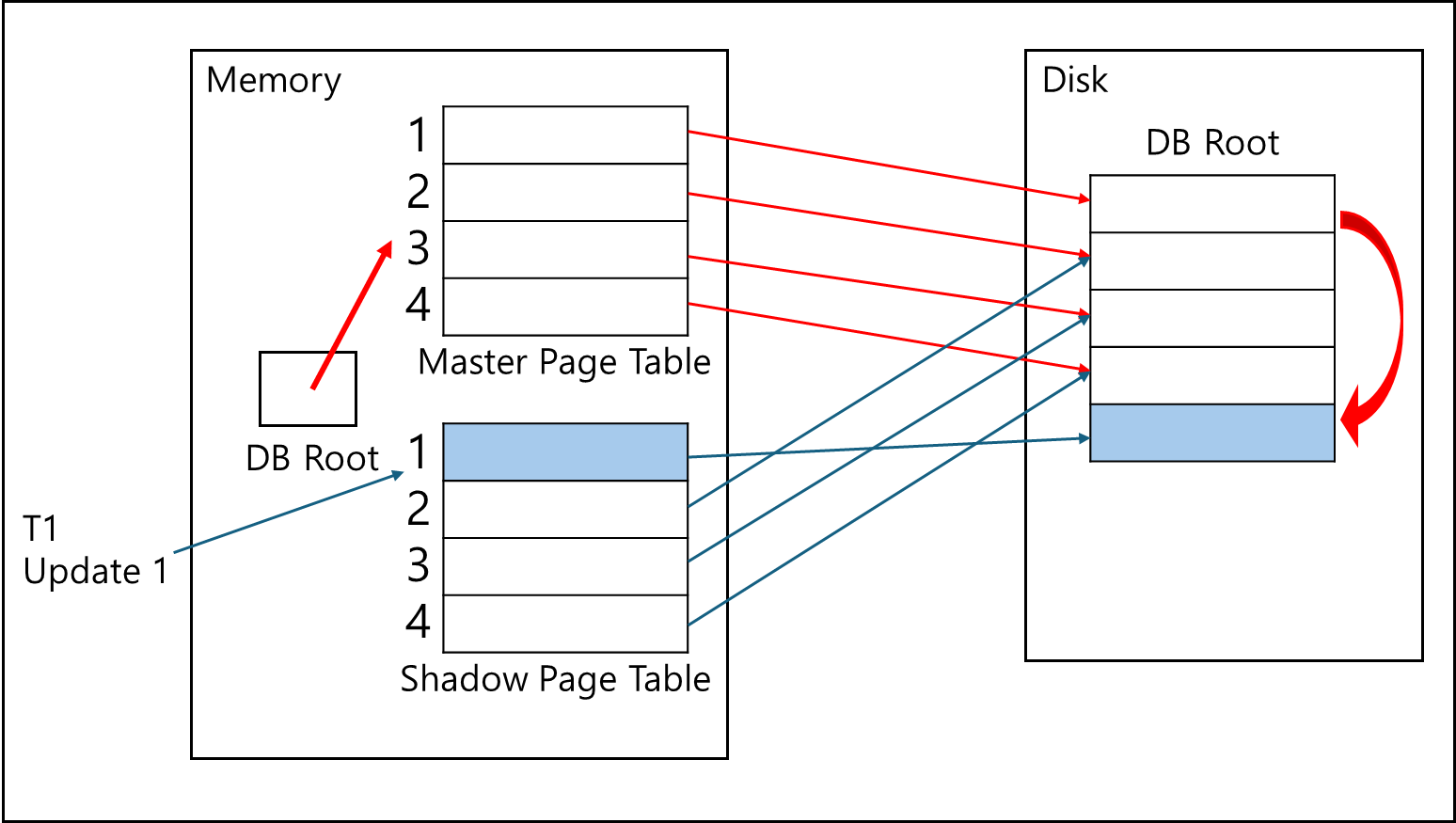
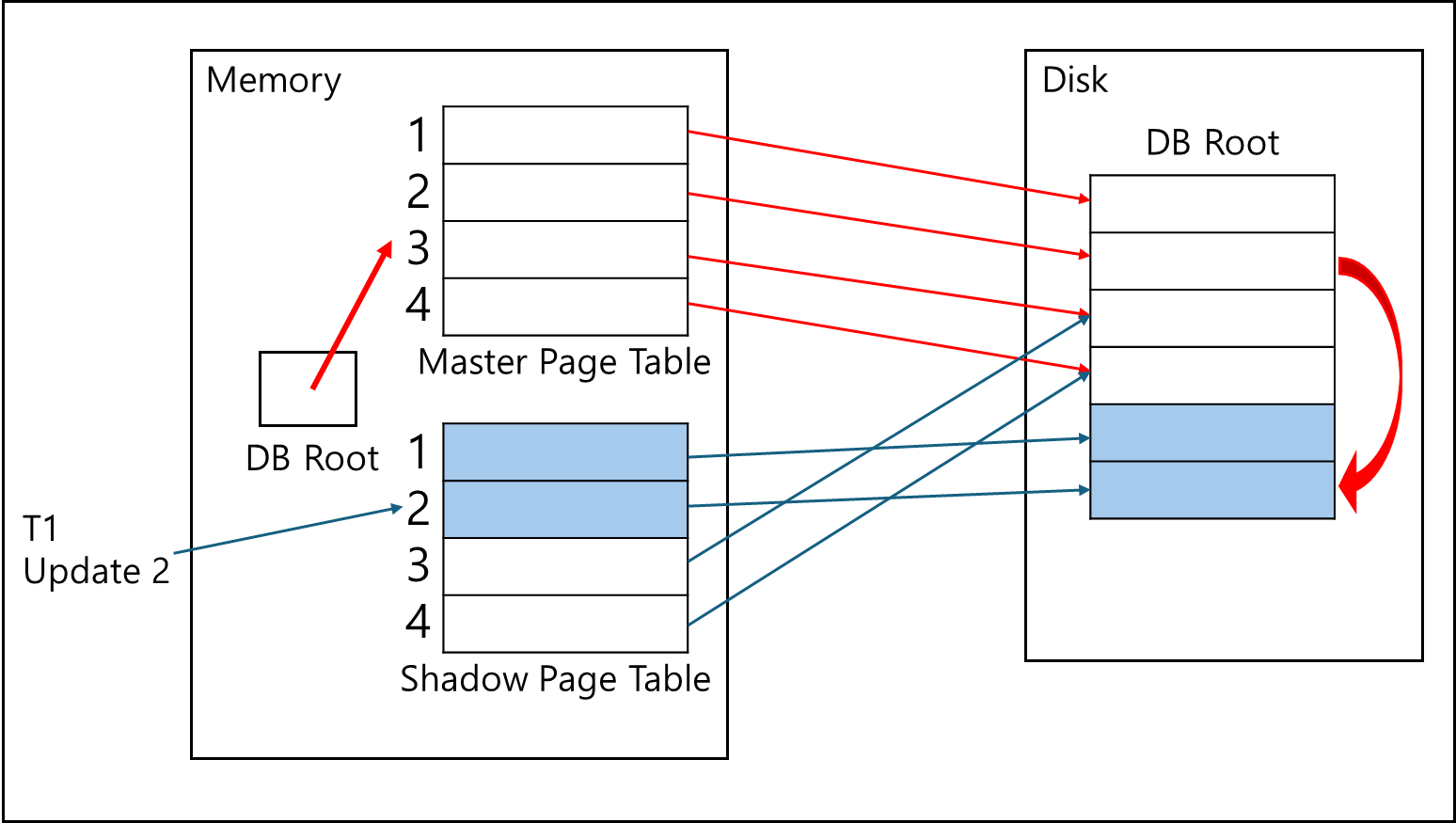
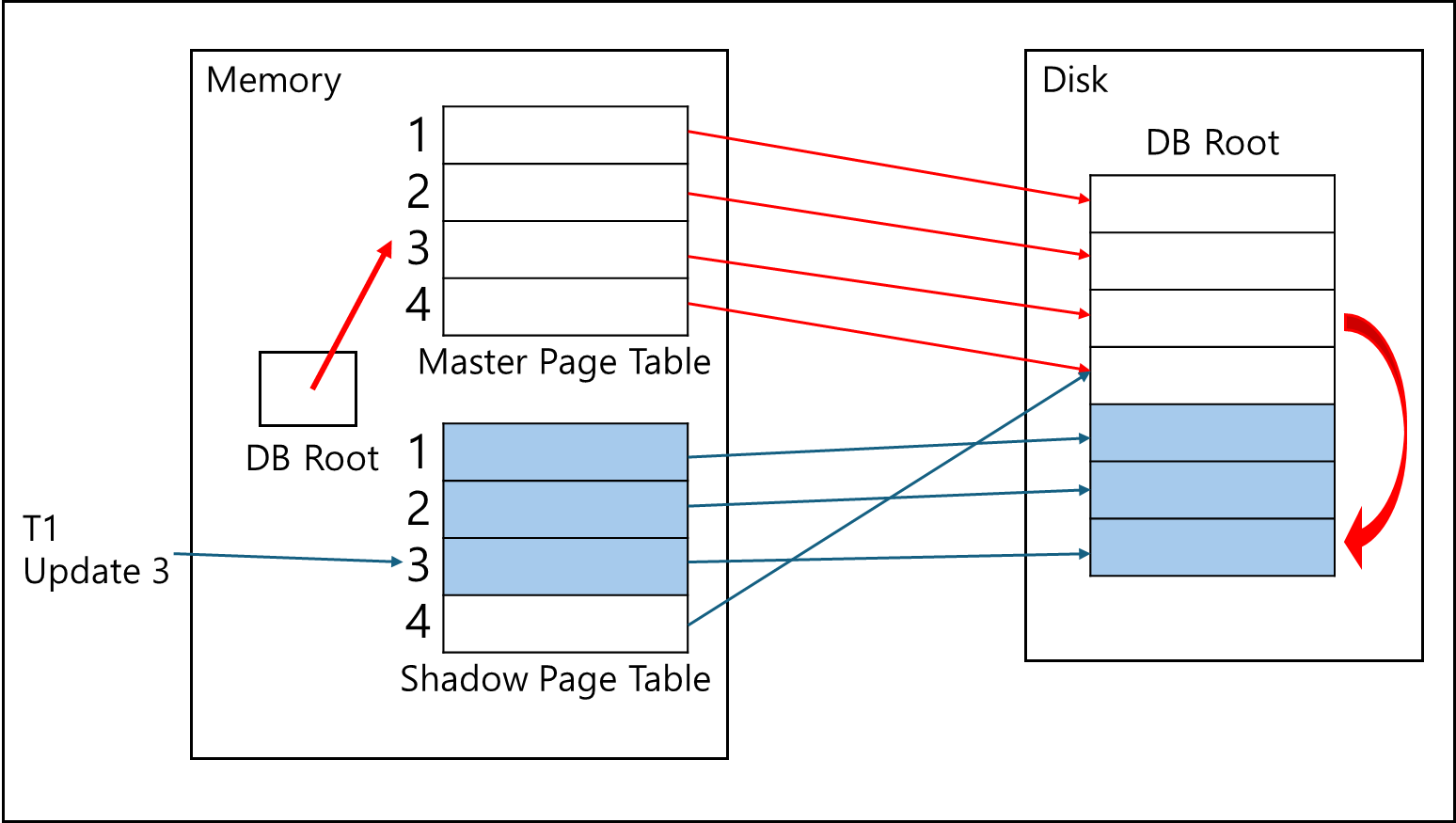
트랜잭션 1의 처리에 의해 1,2,3 페이지는 메모리에서 업데이트 되고, Disk에서는 해당 페이지가 추가되어 Shadow Page Table과 연결되어있다.
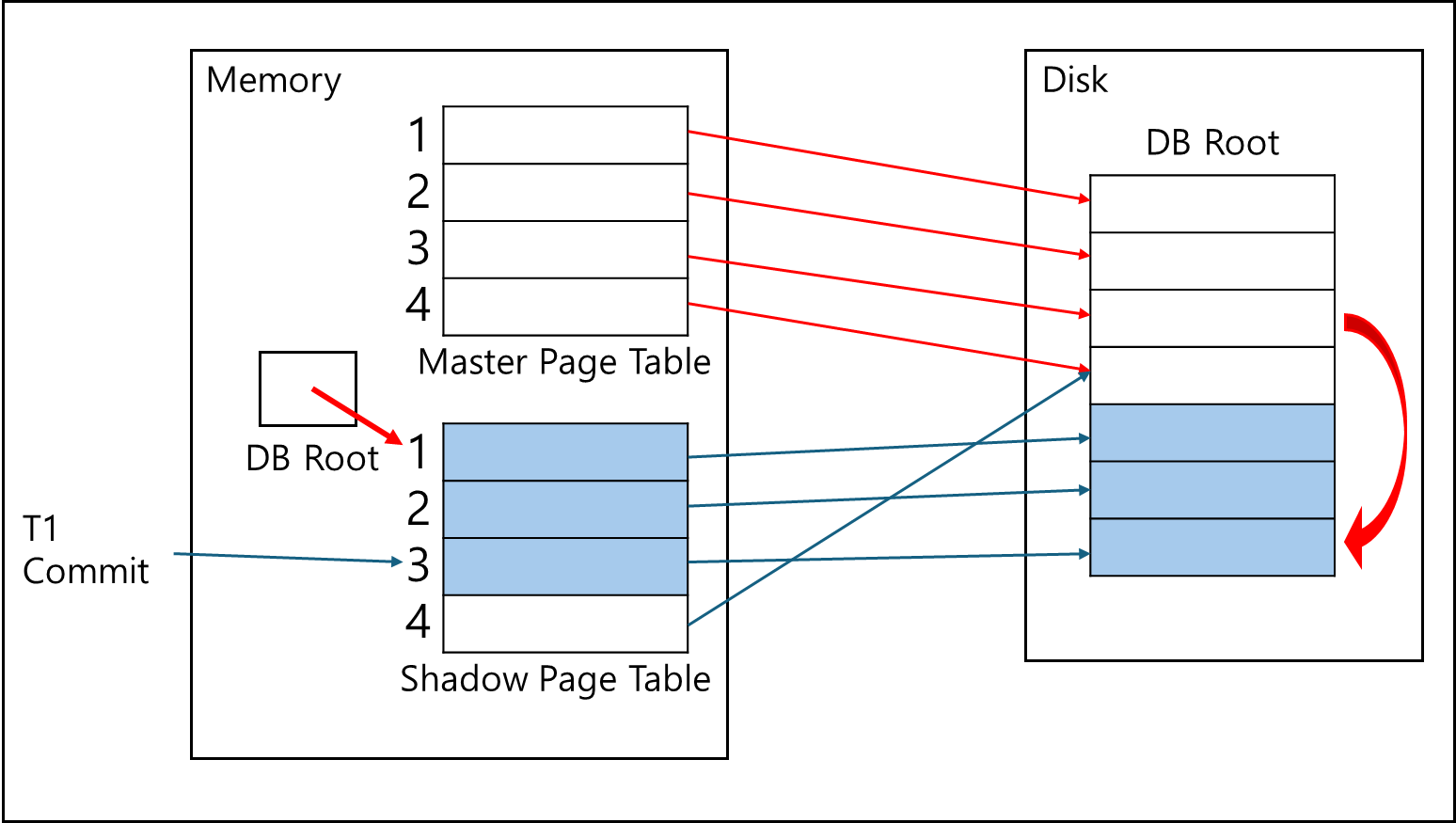
이후 트랜잭션 1이 commit을 하게되면 메모리에서 갖고 있던 DB Root의 포인터를 Shadow Page Table로 변경하여 Shadow Page Table을 Master Page Table로 변경한다.
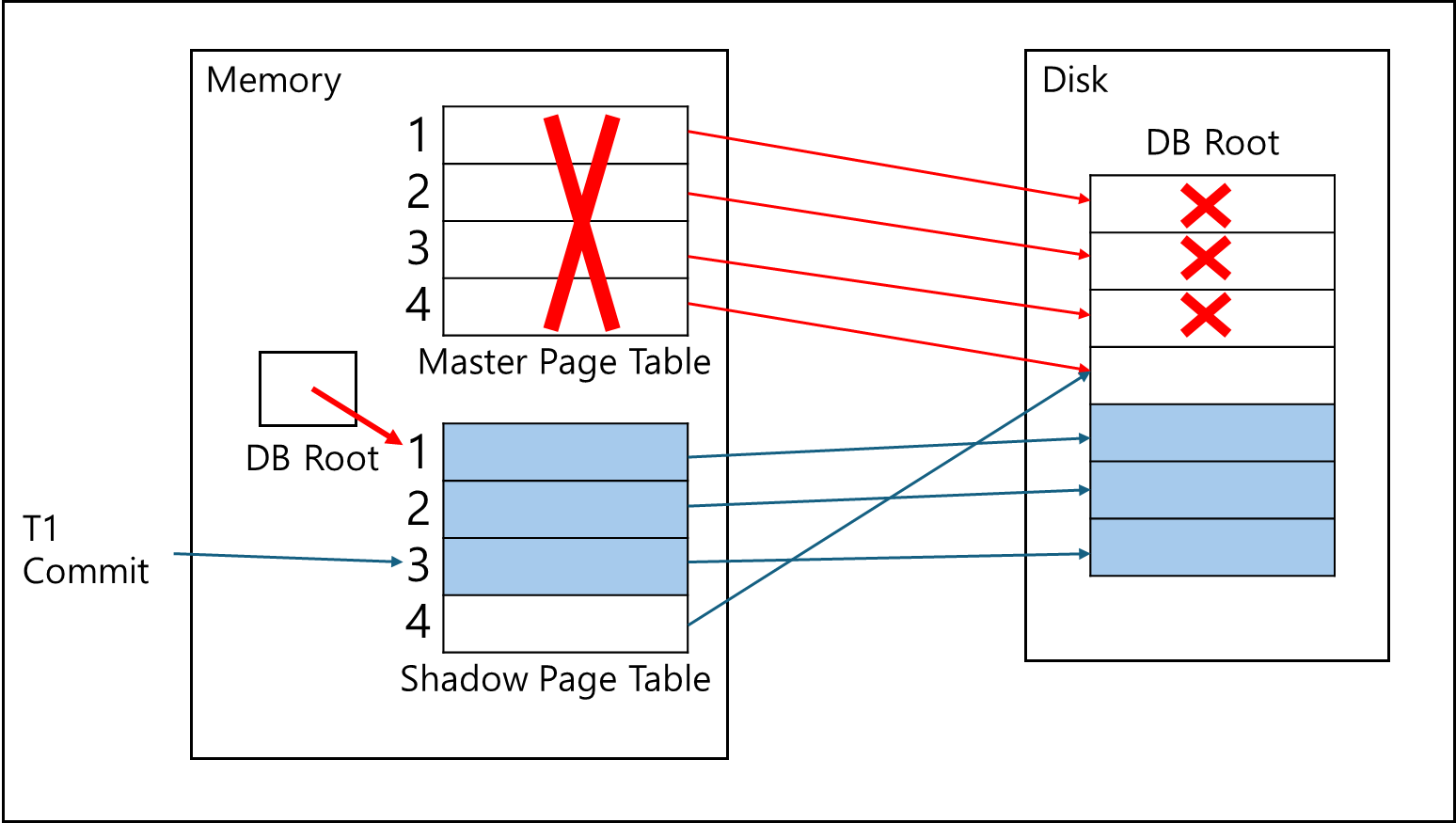
이후 Garbage Collection을 통해 메모리에 남아있던 구 Master Page Table과 Disk에 남아있던 과거 데이터를 삭제한다.
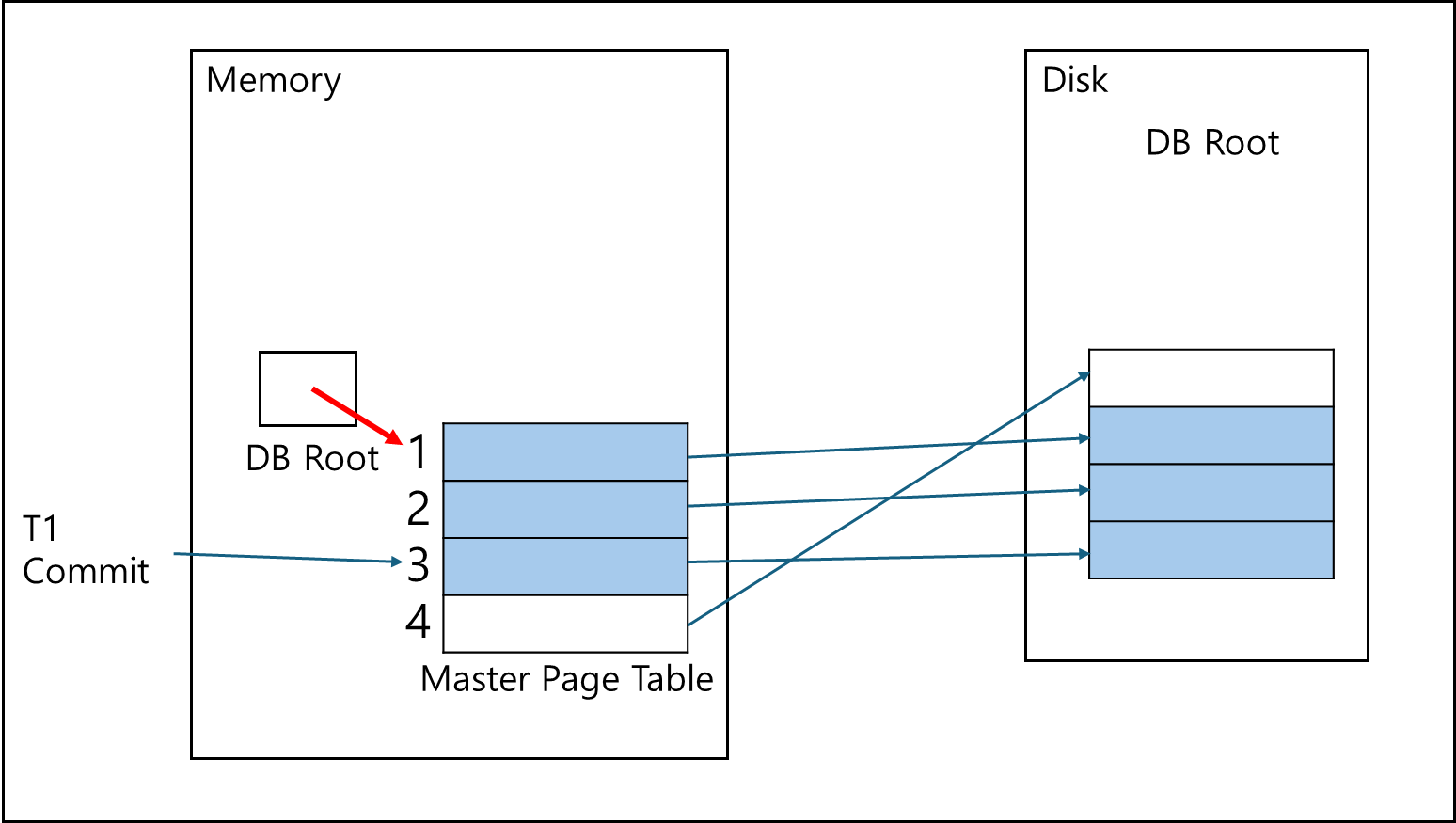
이후 남아있는 Shadow Page Table이 새로운 Master Page Table이 된다.
이렇게 구현해둘 경우 롤백과 Recovery는 아주 쉬워지는데 Undo의 경우 Shadow Page를 지워버리기만 하면 되며 Redo의 경우 별도로 필요가 없어진다.
3) 단점
* 전체 페이지 테이블을 복사하는 것은 비용이 많이 든다.
- B+트리(LMDB)처럼 구조화된 페이지 테이블을 사용한다.
- 전체 트리를 복사할 필요 없이, 업데이트된 리프 노드로 연결되는 트리의 경로만 복사하면 된다.
* 커밋 오버헤드가 높다.
- 업데이트된 모든 페이지, 페이지 테이블 및 루트를 flush한다.
- 데이터가 단편화된다(순차 스캔에 적합하지 않음).
- 가비지 컬렉션이 필요하다.
- 한 번에 하나의 작성자 트랜잭션만 지원하거나 일괄 처리 트랜잭션만 지원한다.
5. Rollback journal mode(SQLite)
트랜잭션이 페이지를 수정하면 DBMS는 마스터 버전을 덮어쓰기 전에 원본 페이지를 별도의 저널 파일에 복사한다. 이를 “롤백 모드”라고 하며 SQLite에서 사용하는 방식이다.
재시작 후 저널 파일이 존재하는 경우, DBMS는 커밋되지 않은 트랜잭션의 변경 사항을 취소하기 위해 해당 파일을 복원한다.
6. Write-Ahead Log
기본적으로 Shadow paging은 DBMS가 디스크에 랜덤 비연속적 쓰기를 한다.
이를 순차쓰기로 바꿀 수 없을까 하는 생각에서 나온게 이 Write-Ahead Log(이하 WAL) 방식이다.
WAL방식에서 DBMS는 모든 트랜잭션의 로그 레코드를 휘발성 저장소(일반적으로 버퍼 풀에 의해 백업됨)에 저장한다. 업데이트된 페이지와 관련된 모든 로그 레코드는 페이지 자체가 비휘발성 저장소에 덮어쓰기 전에 비휘발성 저장소에 기록되며 모든 로그 레코드가 안정 저장소에 기록될 때까지 트랜잭션은 커밋된 것으로 간주되지 않는다.
WAL에 기재할때 트랜잭션 시작점을 표기하기 위해
나머지는 아래의 예시를 통해 알아보겠다.

1,2까지 실행시킨 결과이다. WAL Pool에는 A의 이전값과 이후값, 그리고 트랜잭션 번호와 변경한 객체 ID가 포함되어있으며 Buffer Pool에도 내용이 적용되어있다.

B에 Write를 해서 값이 변경되었으며 WAL Pool에도 적용되어있다.

트랜잭션 2가 실행되었기 때문에 해당 내용이 WAL Pool에 반영되었으며 트랜잭션 2에서 B를 수정하는 작업이 WAL Pool과 Buffer Pool에 모두 반영되었다.

트랜잭션 2의 C객체에 대한 쓰기가 반영되었다.


Commit이 되었는데 왜 Disk에 반영이 안되었냐고 할 수 있지만 이후 설명할 체크포인트 생성시에나 페이지 교체 시점에 디스크에 따로 반영된다.

예시를 보면 알겠지만 일반적으로 이 Write-Ahead Log는 Buffer Pool Policy가 Steal + Non-Force 정책이며 Non-Force 정책답게 Commit 때마다 파일로 Write를 하는게 아닌 휘발성 메모리에 있는 Buffer가 꽉 차거나 혹은 작성 후 일정 시간이 지나면 (timeout) 파일로 Write하는 정책을 사용한다.
7. Checkpoint
위와 같이 작성한 WAL은 이론상 끝도 없이 커지게 된다. 문제는 DBMS가 Fail난 후 재시동하여 WAL FILE을 이용해서 작업 상황을 복구할때 생기는데, DBMS는 전체 로그를 재생해야 하므로 시간이 오래 걸리게된다.
이를 방지하기 위해서 주기적으로 체크포인트라는 것을 만드는데, 이는 Fail 이후 WAL을 실행해야하는 지점을 알려주는것이다. 아래의 예시를 보자.

위와 같은 WAL file이 있을때
여기서 T2 + T3는 마지막 체크포인트 이전에 커밋되지 않았는데, T2는 체크포인트 이후에 커밋되었으므로 다시 실행해야 하며 T3는 충돌 전에 커밋되지 않았으므로 실행 취소해야 한다.
체크 포인트만 제대로 찍어둔다면 작업 상태 복구에 꽤나 큰 이점이 있다. 하지만 이렇게 좋아보이는 체크포인트를 만들기 위해서 단순하게 생각해보면 꽤 많은 제약사항이 있다.
차단/일관성 체크포인트 프로토콜을 이용하면
- 모든 쿼리를 일시 중지한다.
- 메모리에 있는 모든 WAL 레코드를 디스크로 플러시한다.
- 버퍼 풀에 있는 모든 수정된 페이지를 디스크로 플러시한다.
- <CHECKPOINT> 항목을 WAL에 쓰고 디스크로 플러시한다.
- 쿼리를 재개한다.
모든 쿼리를 일시 중지하는 것만 해도 문제가 크다. 이는 사실상 서비스가 중단 된다는 말과 다를바 없기 때문이다. 하지만 이러한 체크포인트는 이점이 너무 많으므로 아예 사용자들이 잘 사용하지 않는 시간을 두고 이 시간동안 서비스를 중단해버리는 방식을 택하는데 은행이나 결제 서비스의 경우 12시쯤해서 결제가 5~15분정도 불가한 시간이 있는데, 이 시간 동안에 은행 DB에서 체크포인트 작업을 하는 것이다.
※ 15년도에는 체크포인트를 은행 점검시간에 찍는다고 배웠었는데, 현재까지 그렇게 운용하는지는 확실하지 않다.
이렇게 전체를 중지 시켜놓고 하는 체크포인트는 문제가 많기 때문에 다른 방법들이 많이 생겨났으며 이는 차후 추가적으로 언급하겠다.
참고자료
- 서강대학교 김영재 교수님 고급데이터 베이스 강의 자료
- Avi Silberschatz, Henry F. Korth, S. Sudarshan, Database System Concepts(McGraw-Hill, March 2019)