SQL - SELECT, GROUP BY, HAVING
사용법
개요
기본적인 SQL의 SELECT 문법은 아래와 같은 형태를 따른다.
1
2
3
4
5
6
7
-- ()은 앞에 온 값에 대한 설명
-- {}은 들어갈 내용
-- []은 값은 있거나 없거나
SELECT [DISTINCT] {* 혹은 특정 열 [특정 열에 대한 별칭]}
FROM {테이블 이름}
WHERE {조건}
ORDER BY [특정 열 {ASC(오름차순, 기본값, 생략가능) 혹은 DESC(내림차순)}]
각 항목 세부 설명
SELECT
해당 테이블에서 특정 열을 출력하고자 할때 특정 열을 지정해서 사용할 수 있다. 표를 기준으로 둘 때 열을 기준으로 잘라준다고 생각하면 편하다.
아래 테이블을 예시로 설명을 하겠다.
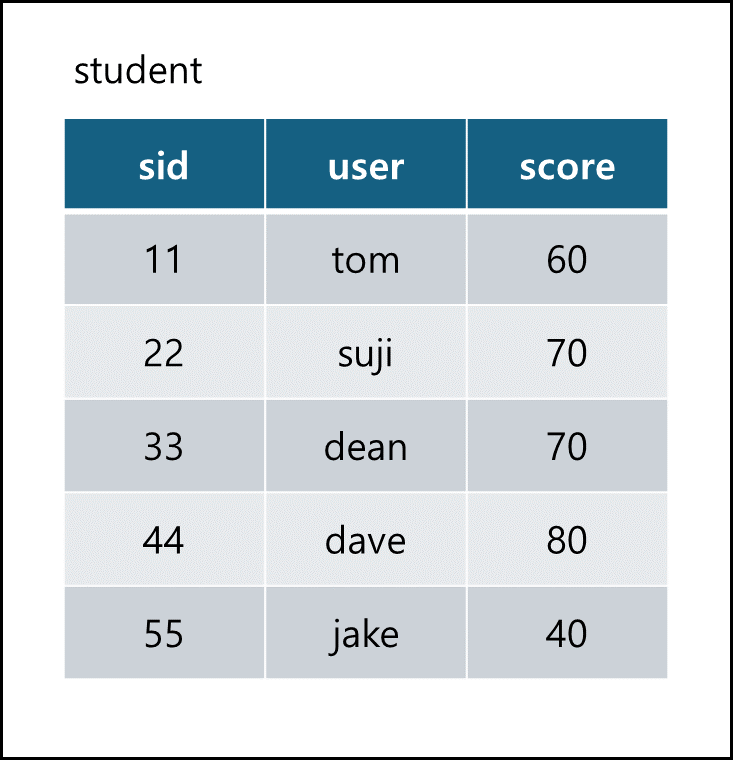
- *를 입력하면 테이블 전체 열을 출력한다.
1 2
SELECT * FROM student;
출력 :
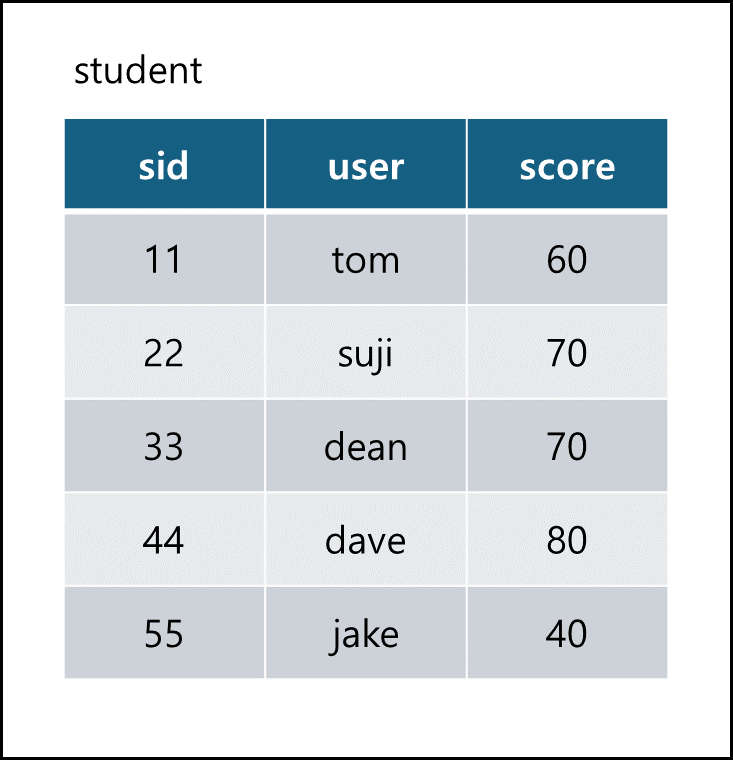
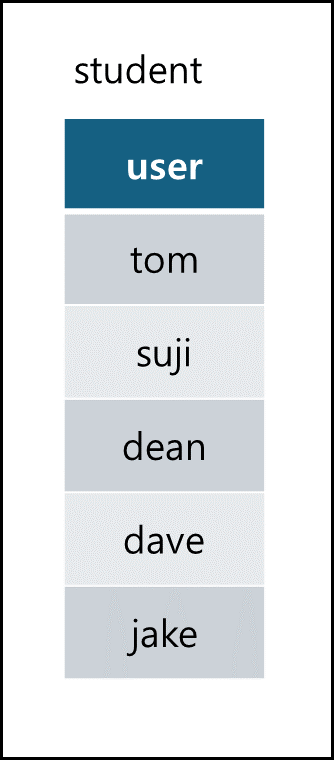
- 특정 열 이름을 입력하면 해당 열만 반환하게 할 수있다. 다음은 student 테이블에 user 열만 출력하는 sql이다.
1 2
SELECT user FROM student;
출력 :
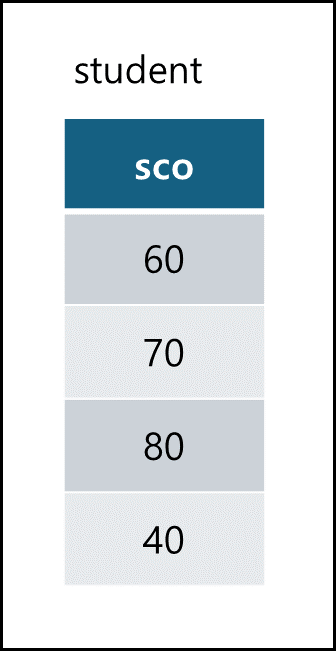
- 특정 열의 별칭을 지정하여 해당 이름을 반환할 수 있다. student table에 score를 sco로 변경하여 출력하는 sql이다. 여기에 distinct 까지 입력하면 중복 제거를 할 수있다.
1 2
SELECT distinct score sco FROM student;
출력 :
- 열을 결합하여 출력이 가능하다. || 연산자를 사용하면 되며 여기에 추가로 이름까지 지정 가능하다.
1 2
SELECT user||sid user_id FROM student;
출력 :
별도의 함수를 추가로 지정하여 해당 열의 값을 변경하여 출력 할 수 있다. 다음은 SELECT에 지정된 열을 대상으로 사용하는 예시 함수이다. 빠진것이 많으니 빠진 부분은 이곳을 참고하면 되겠다.
문자 함수
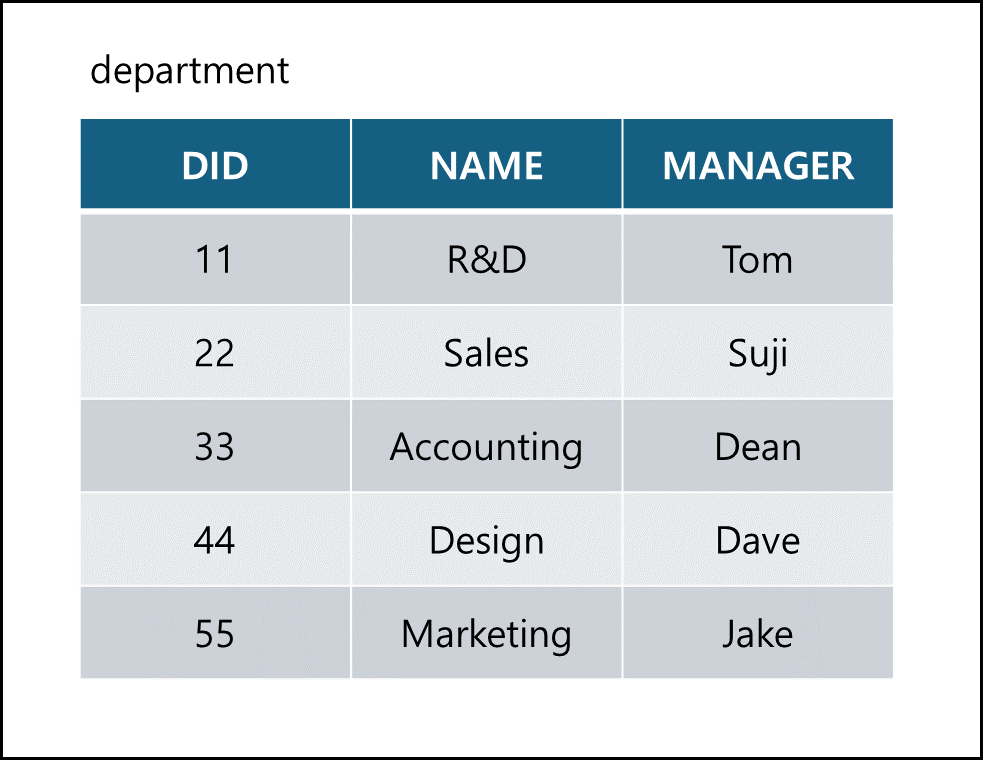
아래 테이블의 예시로 설명을 하겠다.
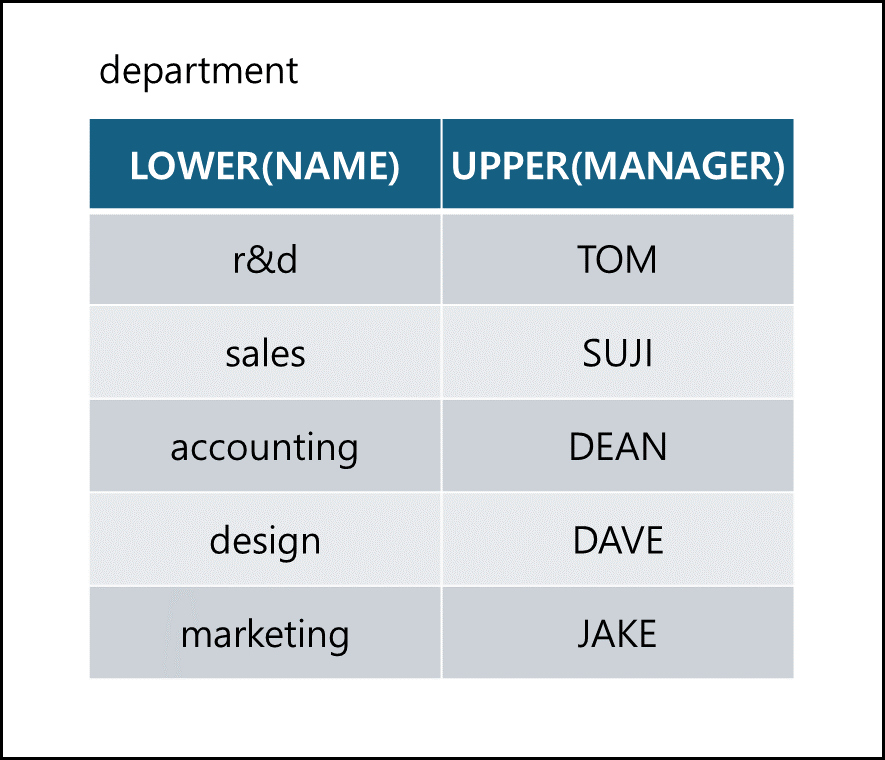
LOWER & UPPER
문자들을 소문자, 대문자로 변경하여 출력1 2
SELECT LOWER(NAME), UPPER(MANAGER) FROM DEPARTMENT;
LPAD
LPAD(필드, 문자 범위, ‘형식’)에 맞춰서 결과 출력1 2 3
SELECT LPAD(NAME,10,'*') FROM DEPARTMENT; -- 10칸을 확보하여 출력하되 왼쪽 빈칸은 *로 채운다.

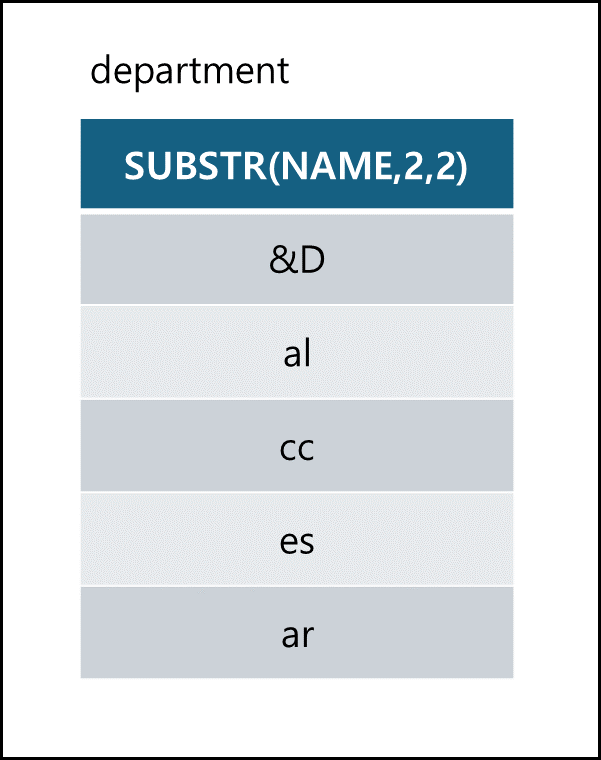
- SUBSTR
SUBSTR(‘문자열’혹은 필드,pos,n) pos의 위치부터 n개의 문자를 출력한다. n이 없으면 마지막까지 출력한다.1 2 3
SELECT SUBSTR(NAME,2,2) FROM DEPARTMENT; -- 2번째 문자열부터 2개 출력
INSTR
INSTR(필드,’문자’) : 필드에서 문자가 있는 위치를 출력
INSTR(필드,’문자’, 수1, 수2) : 수 1부터 문자가 있는 위치를 검색하되 수 2번째의 위치 출력
찾지 못하면 0을 반환1 2 3
SELECT INSTR(NAME,'c',2,2), INSTR(MANAGER,'o') FROM DEPARTMENT; -- NAME에 있는 'c'가 두번째 문자부터 검색했을때 2번째 등장하는 위치, MANAGER의 'o'가 등장하는 위치

- LENGTH
대상 필드나 입력한 문자열의 문자 개수를 출력1 2 3
SELECT LENGTH(NAME) FROM DEPARTMENT; -- NAME 필드의 길이 출력

- TRANSLATE
TRANSLATE(필드, ‘A’, ‘B’)함수는 필드에서 문자 A를 찾아 B로 변환하여 출력1 2 3
SELECT TRANSLATE(NAME,'e','d') FROM DEPARTMENT; -- NAME에서 'e'가 있다면 'd'으로 변경하여 출력

아래부터에서는 다음의 TABLE을 사용한다.
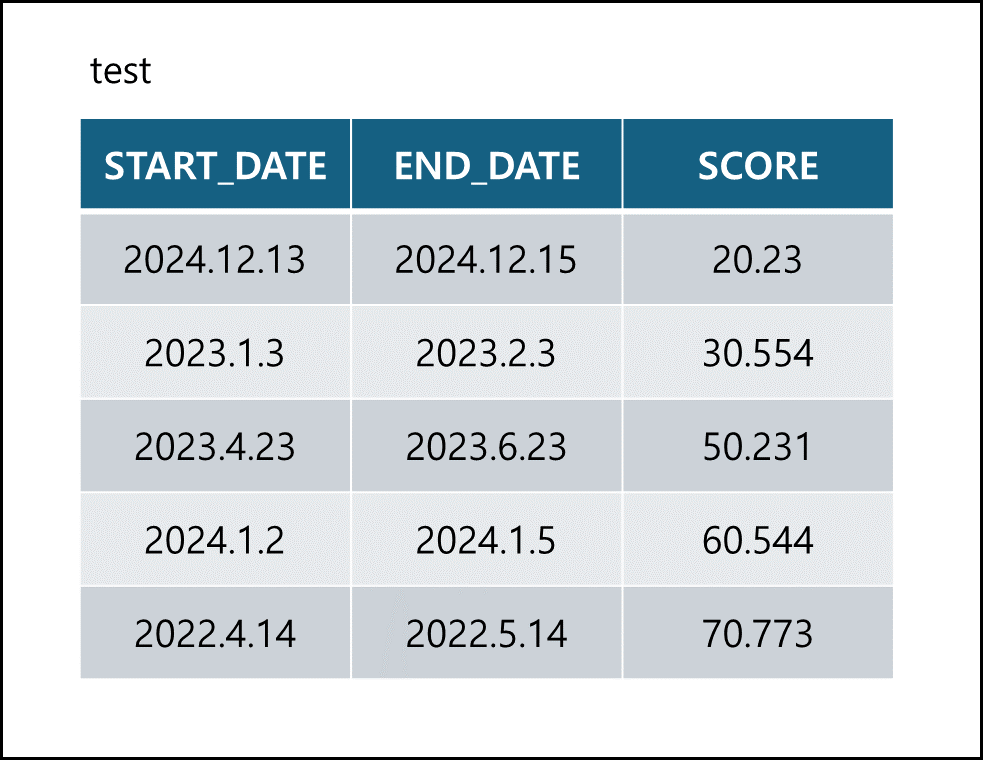
숫자 함수
- ROUND
ROUND(실수 필드값 혹은 실수 입력값, 정수) 함수는 입력값을 정수만큼 반올림한다.1 2
SELECT ROUND(SCORE,1) FROM TEST;
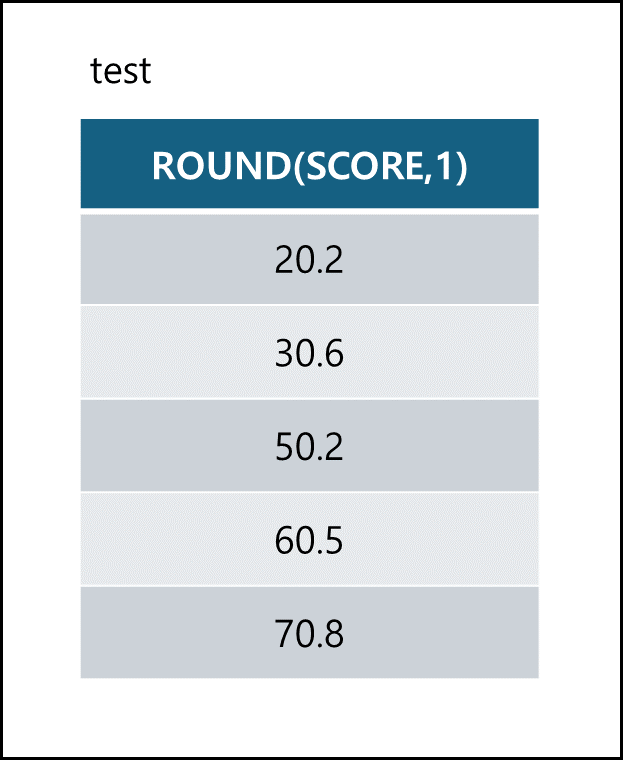
- POWER
POWER(실수 필드값 혹은 실수 입력값, 정수) 함수는 입력값을 정수만큼 제곱한 값을 출력1 2
SELECT POWER(SCORE,3) FROM TEST;
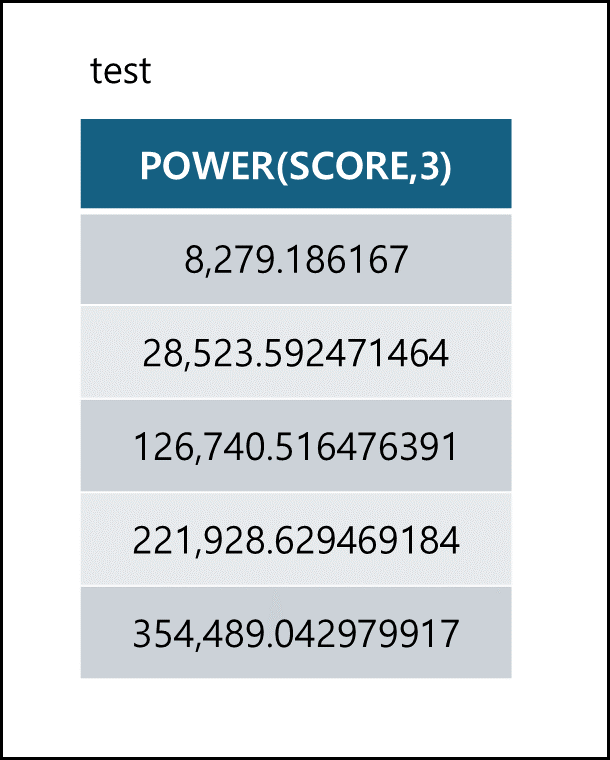
- SQRT
SQRT(필드값 혹은 실수) 함수는 입력값의 제곱근을 출력1 2
SELECT SQLT(SCORE) FROM TEST;
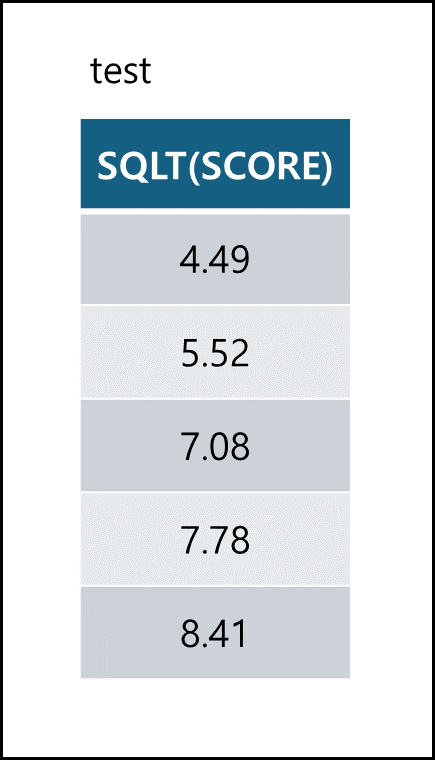
날짜 함수
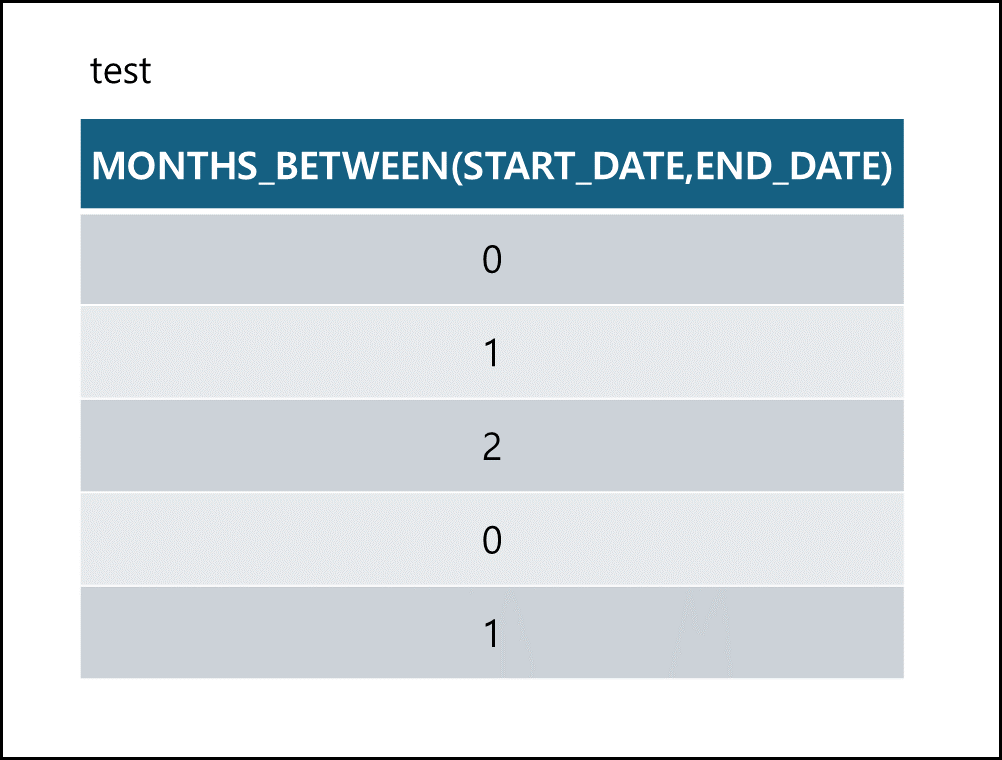
Months_Between(date1, date2) 함수는 date1과 date2 사이의 개월수를 출력한다.
- MONTHS_BETWEEN
1 2
SELECT MONTHS_BETWEEN(START_DATE,END_DATE) FROM TEST;
- ADD_MONTHS
ADD_MONTHS(날짜, 정수) 함수는 날짜의 달에 정수만큼 더한 값 출력1 2
SELECT ADD_MONTHS(START_DATE,3) FROM TEST;

집계 함수
이 함수들은 GROUP에 대해서 적용이 가능하기 때문에 Group 함수라고도 한다.
- COUNT
1 2 3 4
SELECT COUNT(*) FROM TEST WHERE SCORE=20.23; -- SCORE 값이 20.23인 것들의 개수

- SUM
SUM(필드 값) 함수는 필드의 총 합을 출력1 2 3
SELECT SUM(SCORE) FROM TEST -- SCORE 값을 다 더한 것

- AVG
AVG(필드 값) 함수는 필드의 총 평균을 출력1 2 3
SELECT AVG(SCORE) FROM TEST -- SCORE 값의 총 평균값

- MAX
MAX(필드 값) 함수는 필드값의 최대값을 출력1 2 3
SELECT MAX(SCORE) FROM TEST -- SCORE 값 중에 최대값을 출력

- MIN
MIN(필드 값) 함수는 필드값의 최소값을 출력1 2 3
SELECT MIN(SCORE) FROM TEST -- SCORE 값 중에 최소값을 출력

GROUP BY
동일한 필드 값을 갖는 레코드를 그룹으로 묶는 필드임.
이렇게 묶은 필드는 집계함수로 계산이 가능하다.
다음 쿼리는 아래의 표를 기준으로 설명하겠다.
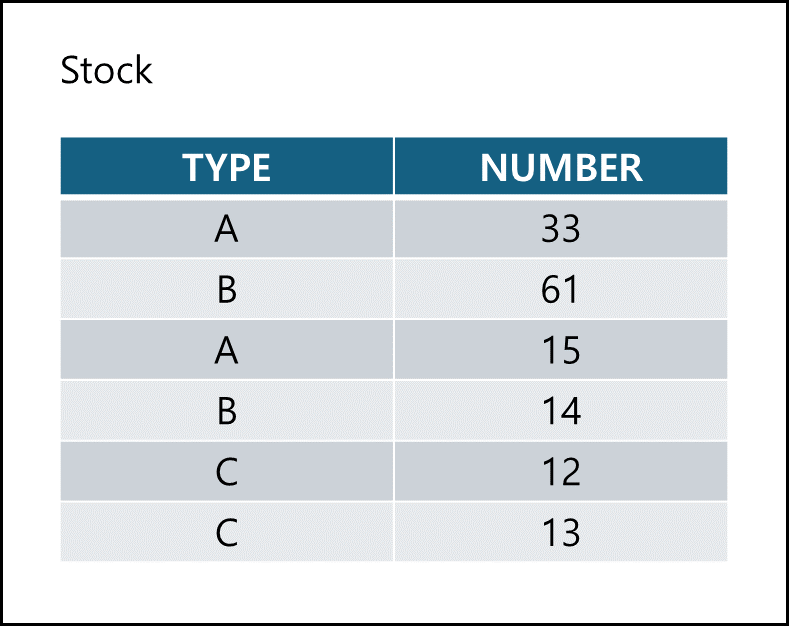
1
2
3
4
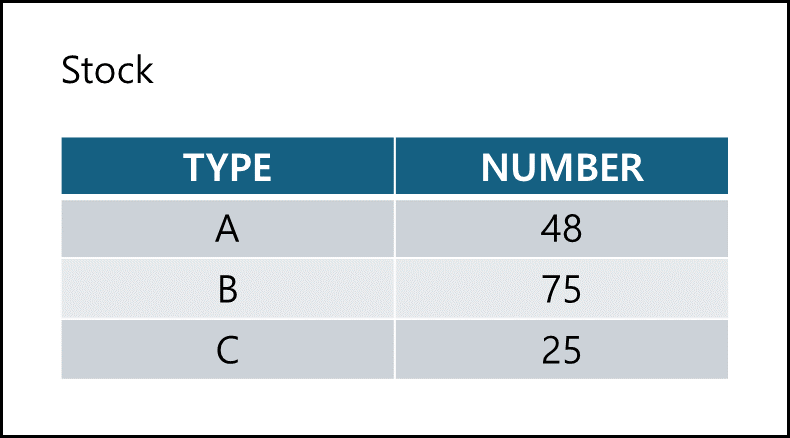
SELECT TYPE, SUM(NUMBER)
FROM STOCK
GROUP BY TYPE;
-- TYPE을 기준으로 NUMBER값을 합산하여 출력
HAVING
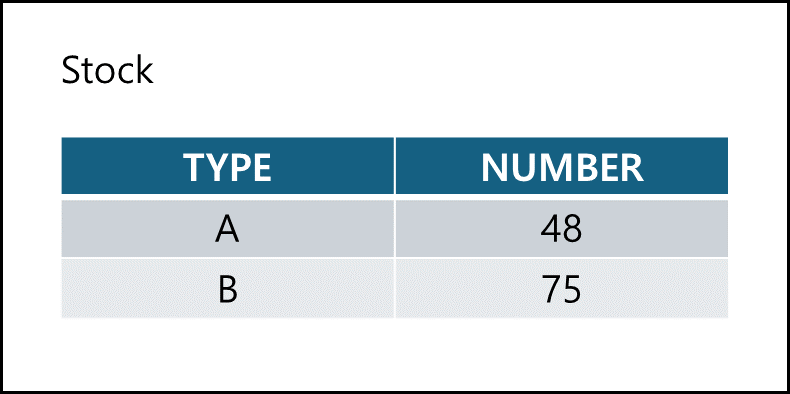
Group by에서 특정 조건을 만족하는 그룹만을 검색하고자 할 경우, Having을 사용한다.
여기서 WHERE은 필드에 대한 조건이고, HAVING은 그룹함수에 대한 조건이다.
SELECT TYPE, SUM(NUMBER)
FROM STOCK
GROUP BY TYPE
HAVING count(*) > 28;
참고자료
- 위키백과 - 데이터베이스
- 대학생 시절 강의 자료
- 데이터베이스, 이한출판사, 김경창 외 2명
- SQL Tutorial