Database - Concurrency control - Timestamp ordering
Timestamp ordering
1. 개요
Lock 없이 Timestamp만을 가지고 직렬화를 판단하는 방식을 말한다.
여기서 Timestamp는 system clock이 될수도, 논리적카운터가 될수도 혹은 그 외의 방식으로 구현된 시간 순에 따라 생성되는 고유한 값이다
2. Basic Timestamp Ordering
각 트랜잭션의 Timestamp을 기준으로 Rollback 할지 아니면 Commit 할지 정하는 기본적인 방식으로 어떤 자원 X에 대한 READ 트랜잭션 $T_{i}$는 $Read-TS_{i}(X)$, 어떤 자원 X에 대한 Write 트랜잭션 $T_{i}$은 $Write-TS_{i}(X)$라고 할 때 Read write 둘다 마지막 연산을 기준으로 Timestamp를 찍는데, 마지막 연산을 각각 Read-TS(X), Write-TS(X)로 표현한다.
1) 장점
- 직렬화가 보장된다.
- lock이 없다 (따라서 dead lock을 방지할 수 있으며, lock overhead가 없다)
2) 단점
- 잦은 abort가 일어난다. (특히 오래된 트랜잭션에 대해 발생한다)
- 연쇄 abort가 가능하다. (잦아지면 트랜잭션들은 기아 현상을 겪을 수 있다
특히 긴 트랜잭션과 짧은 트랜잭션 다수가 있을 경우 연쇄 abort는 더 많을 수 있다)
3) 방식
말로 설명하면 힘드니 수도 코드를 기재하고 하나하나 설명하겠다.
a. Read
1
2
3
4
5
6
7
8
9
// 트랜잭션 i가 X에 대해서 읽기 동작시
if( TS(i) < Write-TS(x)) {
Abort Ti and Rollback/Restart;
}
else {
Read(x);
if(Read-TS(x) < TS(Ti))
Read-TS(x) = TS(Ti);
}
현재 실행중인 트랜잭션의 Timestamp가 Write-Timestamp 보다 이전이면 현재 트랜잭션을 Abort하고 Rollback 하고 재 시작해야한다. 예를 들어보자.
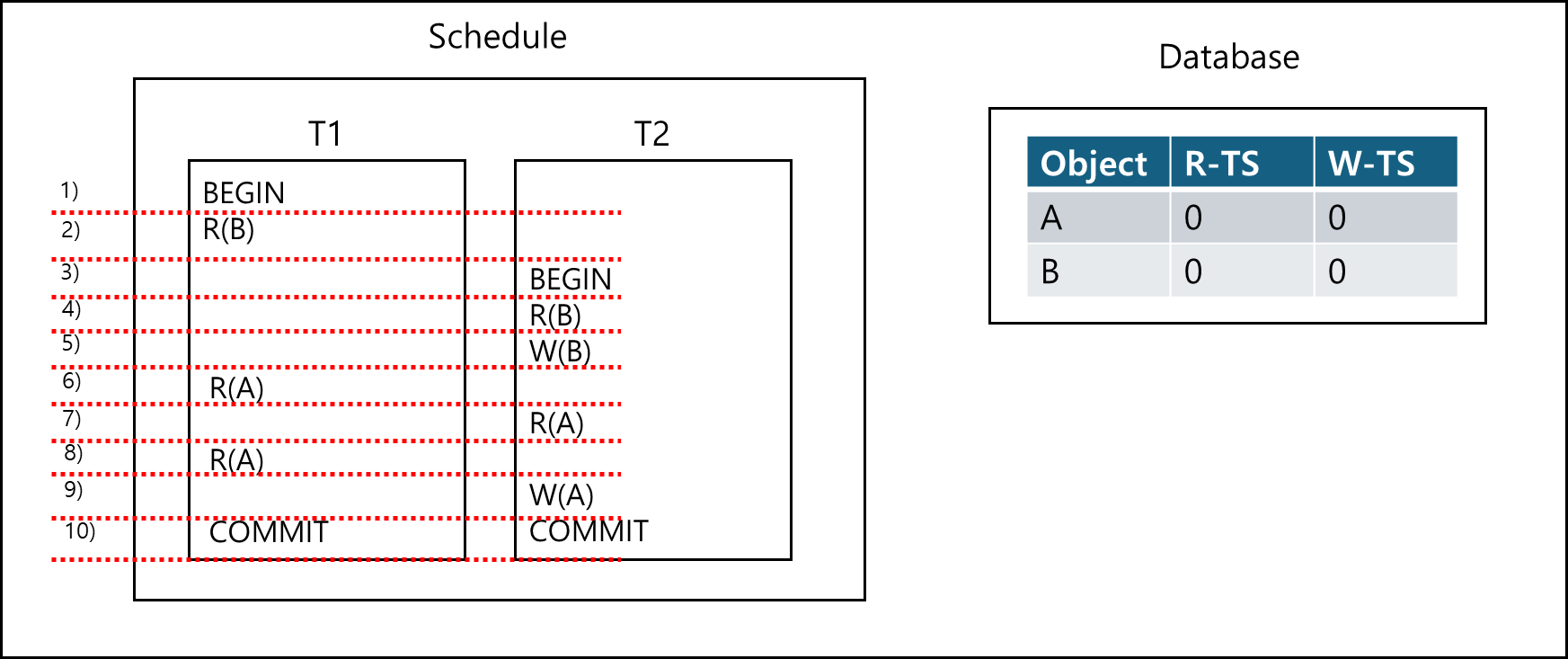
1) T1에 대해서 TIMESTAMP는 1이다. (TS(T1)= 1)
2) B에 대해서 READ가 일어났기 때문에 Write-TS(B) 값과 TS(T1) 값을 비교한다. TS(T1)(=1) > Wrtie-TS(B)(=0)이므로 abort하지 않고 Read-TS(B) = 1(작업한 트랜잭션의 Timestamp)로 세팅한다.
3) T2는 T1 다음으로 실행되므로 TIMESTAMP는 2이다. (TS(T2)= 2)
4) B에 대해서 READ가 일어났기 때문에 Write-TS(B) 값과 TS(T2) 값을 비교한다. TS(T2)(=2) > Wrtie-TS(B) (0)이므로 abort하지 않고 Read-TS(B) = 2(작업한 트랜잭션의 Timestamp)로 세팅한다.
5) B에 대해서 WRITE가 일어났기 때문에 Read-TS(B),Write-TS(B) 값과 TS(T2) 값을 비교한다. TS(T2)(=2) >= Write-TS(B)(=0), Read-TS(B)(=2)이므로 abort하지 않고 Write-TS(B) = 2(작업한 트랜잭션의 Timestamp)로 세팅한다.
6) A에 대해서 READ가 일어났기 때문에 Write-TS(A) 값과 TS(T1) 값을 비교한다. TS(T1)(=1) >= Write-TS(A)(=0)이므로 abort하지 않고 Read-TS(A) = 1(작업한 트랜잭션의 Timestamp)로 세팅한다.
7) A에 대해서 READ가 일어났기 때문에 Write-TS(A) 값과 TS(T2) 값을 비교한다. TS(T2)(=2) >= Write-TS(A)(=0)이므로 abort하지 않고 Read-TS(A) = 2(작업한 트랜잭션의 Timestamp)로 세팅한다.
8) A에 대해서 READ가 일어났기 때문에 Write-TS(A) 값과 TS(T1) 값을 비교한다. TS(T2)(=1) >= Write-TS(A)(=0)이므로 abort하지 않는데 Read-TS(A) > TS(T1)이므로 Read-TS(A)는 건드리지 않는다.
9) A에 대해서 WRITE가 일어났기 때문에 Read-TS(A),Write-TS(A) 값과 TS(T2) 값을 비교한다. TS(T2)(=2) >= Write-TS(A)(=0), Read-TS(A)(=2)이므로 abort하지 않고 Write-TS(A) = 2(작업한 트랜잭션의 Timestamp)로 세팅한다.
10) 트랜잭션 둘 모두 커밋한다.
b. Write
1
2
3
4
5
6
7
if( TS(i) < Read-TS(x) OR TS(Ti) < Write-TS(x)) {
Abort Ti and Rollback;
}
else {
Write(x);
Write-TS(x) = TS(Ti);
}
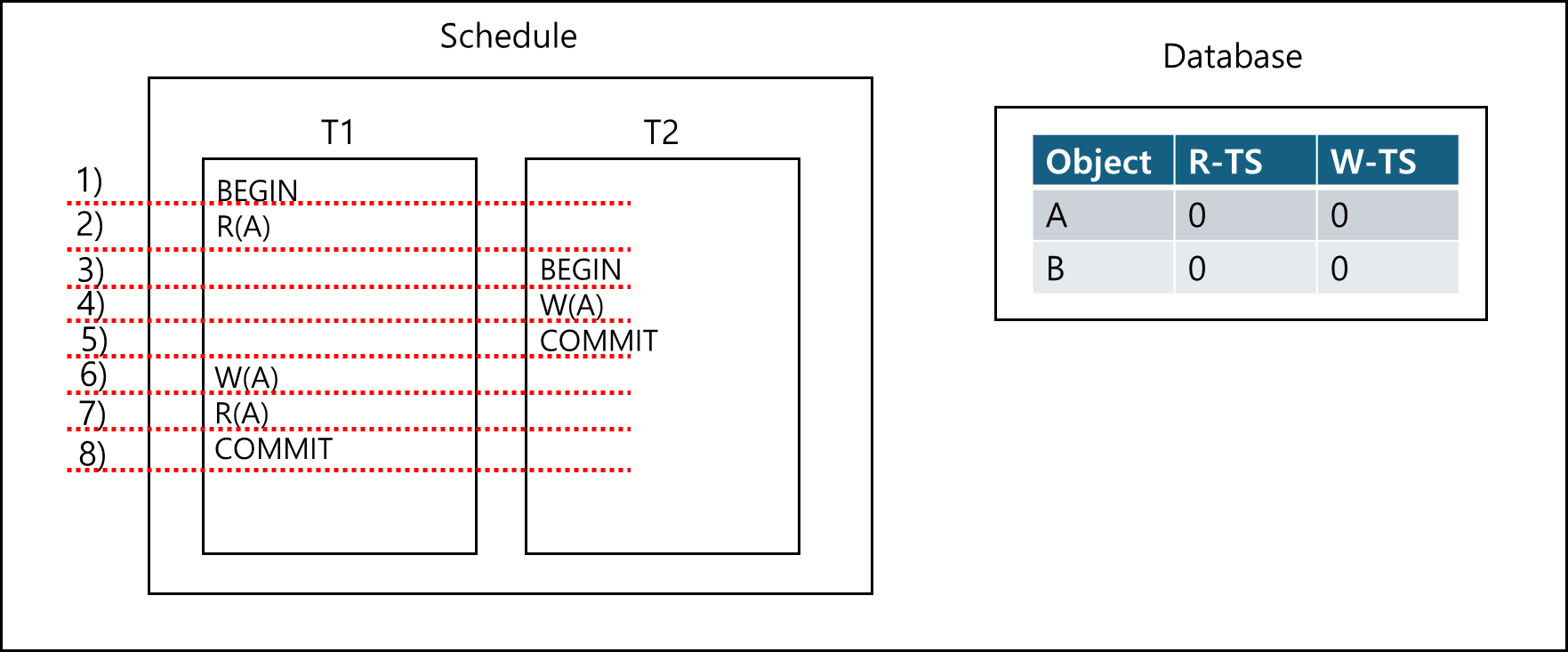
1) T1에 대해서 TIMESTAMP는 1이다.
2) A에 대해서 READ가 일어났기 때문에 Write-TS(A) 값과 TS(T1) 값을 비교한다. TS(T1)(=0) > Wrtie-TS(A)(=0)이므로 abort하지 않고 Read-TS(A) = 1(작업한 트랜잭션의 Timestamp)로 세팅한다.
3) T2에 대해서 TIMESTAMP는 T1 다음이므로 2이다.
4) A에 대해서 WRITE가 일어났기 때문에 Read-TS(A),Write-TS(A) 값과 TS(T2) 값을 비교한다. TS(T2)(=2) >= Write-TS(A)(=0), Read-TS(A)(=1)이므로 abort하지 않고 Write-TS(A) = 2(작업한 트랜잭션의 Timestamp)로 세팅한다.
5) T2를 COMMIT한다.
6) A에 대해서 Read가 일어났기 때문에 Write-TS(A) 값과 TS(T1) 값을 비교한다. 그런데 TS(T1)(=1) < Write-TS(A)(=2)이므로 abort하고 rollback 해야한다.
c. Thomas Write Rule
1
2
3
4
5
6
7
8
9
10
if( TS(i) < Read-TS(x)) {
Abort Ti and Rollback;
}
if(TS(Ti) < Write-TS(x)) {
// 그대로 진행하되 TS(Ti)에서 하는 Write 연산은 실행하지 않음
}
else {
Write(x);
Write-TS(x) = TS(Ti);
}
위에서 설명한 Write 연산에 대해서 좀 더 최적화된 버전이다.
어차피 덮어쓸 것이라면 Write 후 Write 시 abort를 해봐야 성능만 깎아먹으니 그냥 전 Write는 실행하지 않고 commit 해버리는 것이다.
만약 이후에 Read가 등장한다면 어차피 if( TS(i) < Read-TS(x)) 조건문에서 걸리니 상관없다는 것이다.
3. Optimistic Concurrency Control
1) 개요
1981년 카네기 멜론에서 만들어진 방식으로 Conflict가 실제로는 많지 않다는 점에서 착안한 방식이다.
2) Phase
Read Phase
read/write를 위해서 global 데이터에서 private workspace로 복사해온다.Validation Phase
트랜잭션을 commit할때 다른 트랜잭션과 conflict가 있는지 확인해본다. 만약에 문제가 없다면 타임스탬프를 그대로 반영한다.Write Phase
Validation이 성공하면 private workspace를 global data를 쓰기를 하고, 실패했다면 abort하고 다시 트랜잭션을 실행한다.
3) 예시
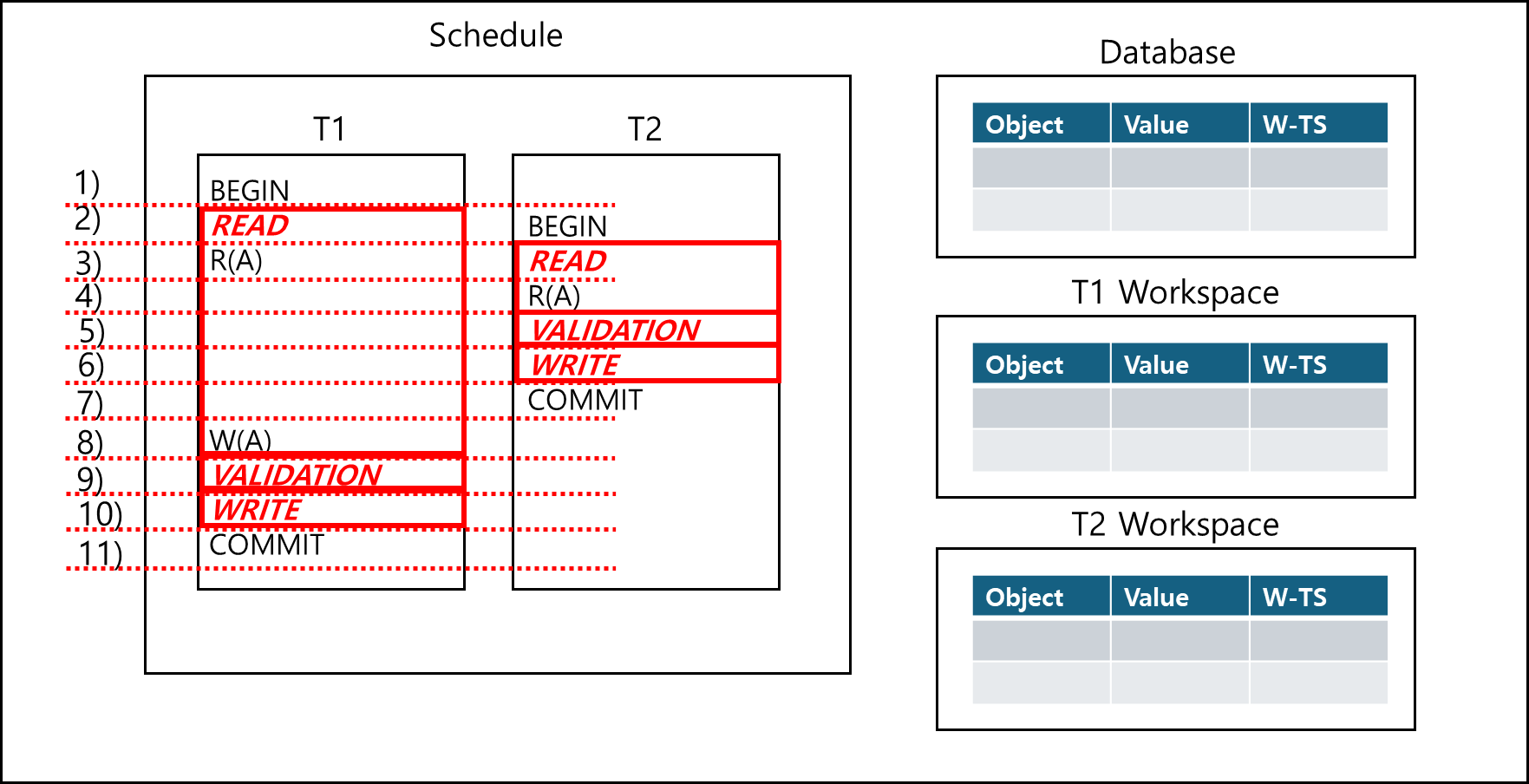
각 트랜잭션이 시작할때 Database에서 각각의 Private한 Workspace를 복사해온다.
위와 같은 트랜잭션일 때 구동방식은 아래와 같다.
1) 트랜잭션 1이 실행되며 T1 Workspace를 만든다.
2) 트랜잭션 2가 실행되고 T2 Workspace를 만든다. 트랜잭션 1의 READ PHASE가 실행되었다.
3) 트랜잭션 1에서 READ(A)가 일어나고, T1 Workspace는 아래와 같이 바뀐다.
| Object | Value | W-TS |
| A | 123 | 0 |
(Value 값은 임의로 넣었다.)
또한 트랜잭션 2에서 T1 Workspace를 만든다.
4) 트랜잭션 2에서 READ(A)가 일어나고, T2 Workspace는 아래와 같이 바뀐다.
| Object | Value | W-TS |
| A | 123 | 0 |
5) 트랜잭션 2의 Validation이 일어난다. T1보다 먼저했으므로 Timestamp는 1이다.
6) T2 Workspace를 없애면서 안의 값을 Database에 반영한다.
7) 트랜잭션 2가 종료되었다.
8) 트랜잭션 1에서 Write(A)가 일어나고, T1 Workspace는 아래와 같이 바뀐다.
| Object | Value | W-TS |
| A | 456 | ∞ |
(Value 값은 임의로 넣었으며, W-TS는 WRITE 전까지 무한(시스템상 최대 크기)로 잡아둔다)
9) 트랜잭션 1의 Validation이 일어난다. T2 다음으로 했으므로 Timestamp는 2이다.
10) 트랜잭션 1의 Private Workspace를 없애고, Database에 Workspace의 값을 반영하면서 W-TS 값을 트랜잭션 1의 Validation의 Timestamp를 지정한다.
11) 트랜잭션 1이 종료되었다.
4) Validation 방식
Validation을 하는 트랜잭션 기준으로 어느방향으로 보냐에 따라 방식이 두가지로 나뉜다.
- Backward Validation
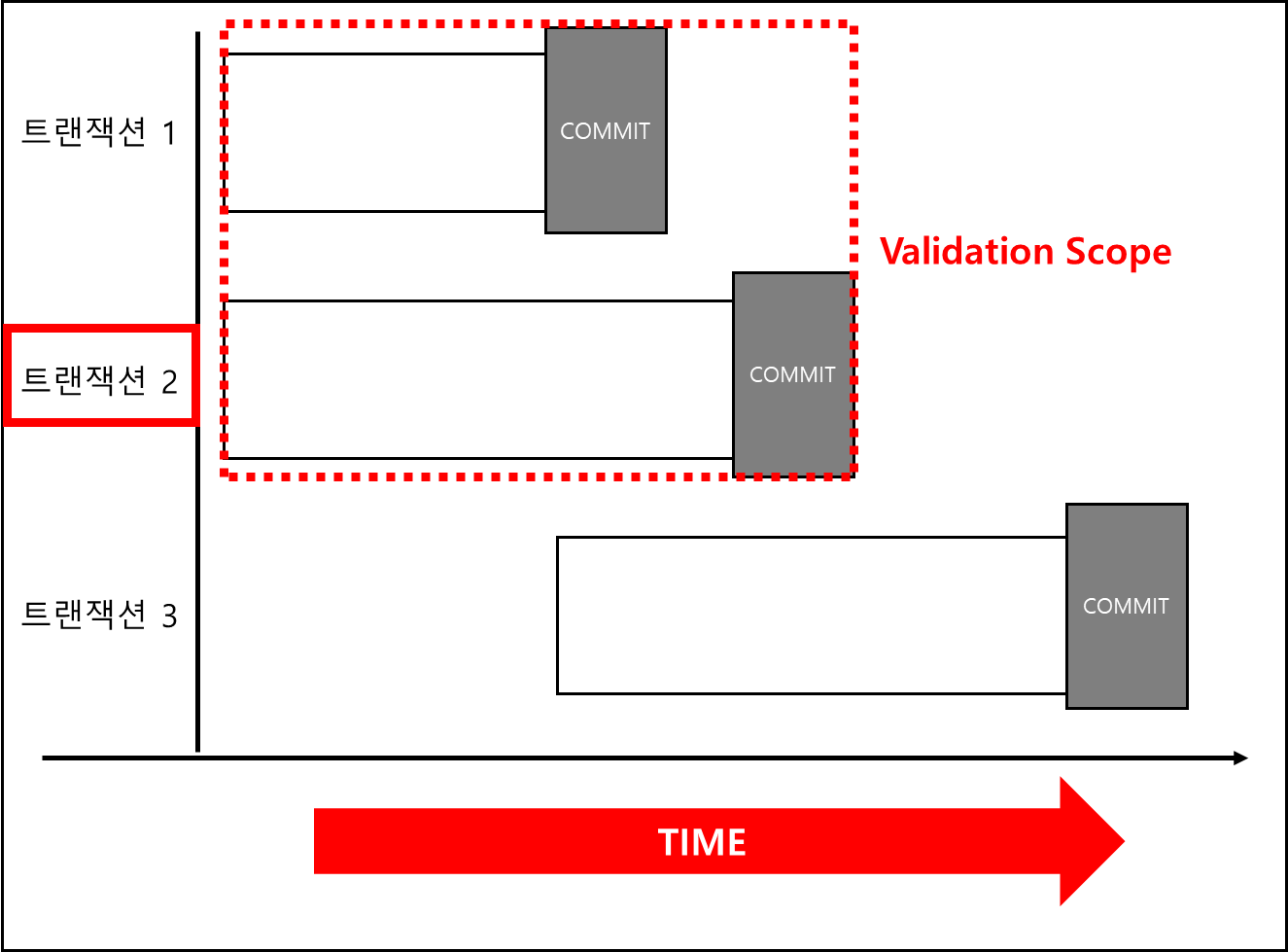
- Forward Validation
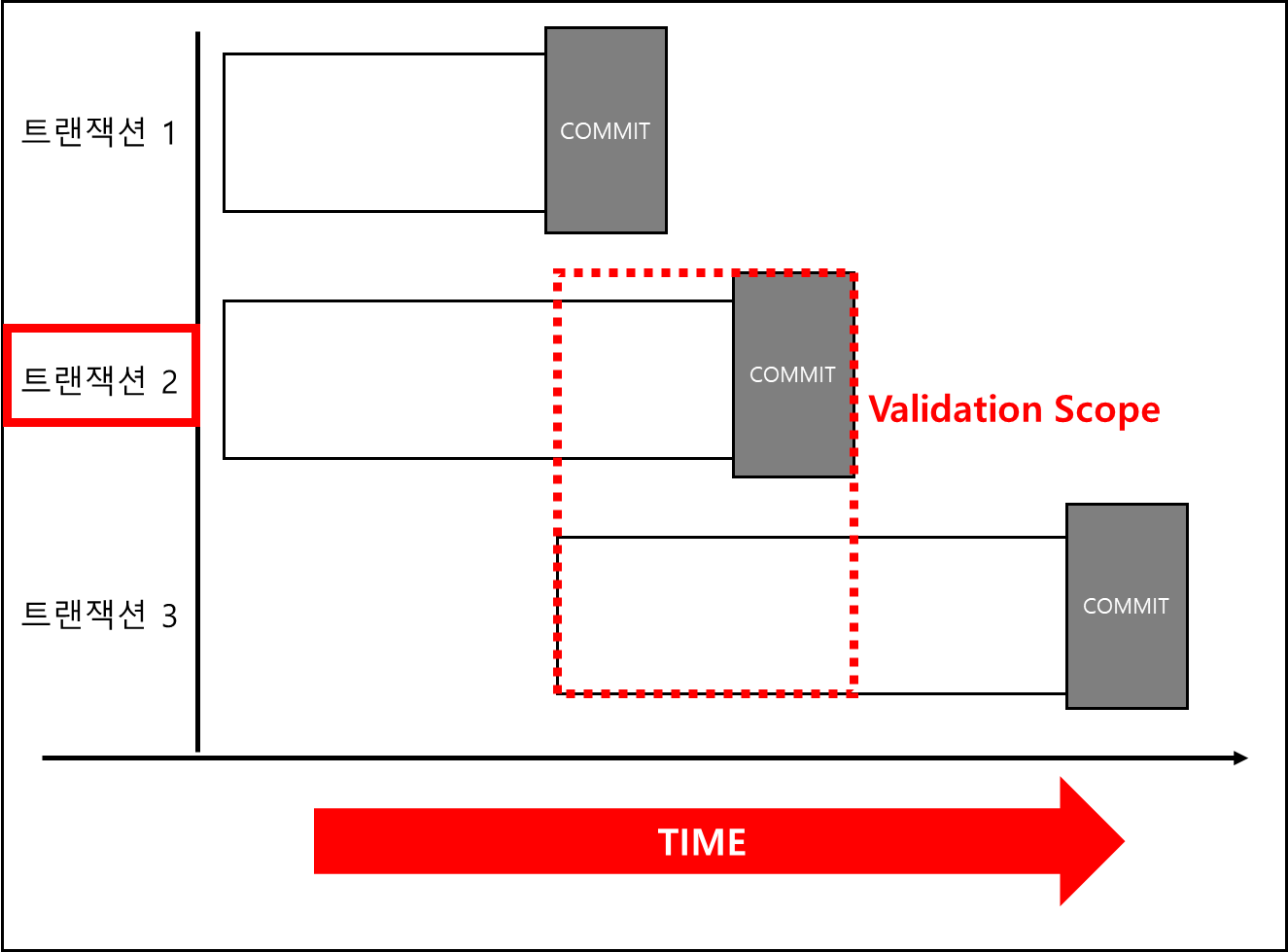
※ Front Validation
기본적으로 Validation Phase에 진입했을때 해당 트랜잭션에 대해서 TimeStamp가 찍힌다.
그리고 Validation Phase 진입시 각 방식에 맞는(Frontward or backward) 범위에서 실행된 트랜잭션에 대해서 체크를 하게된다.
만약 트랜잭션 i의 타임스탬프(TS(Ti))와 트랜잭션 j의 타임스탬프(TS(Tj))가 TS(Ti) < TS(Tj)라면 다음 세 가지 조건 중 하나가 충족되어야하며, 충족되지 않는다면 Abort를 한다.
1. 트랜잭션 i가 트랜잭션 j가 시작하기 전에 READ,VALIDATION,WRITE까지 모두 끝난 경우
순차적으로 실행되니 Abort할 이유가 없다.
2. 트랜잭션 i가 완료되기전에 트랜잭션 j가 Write Phase를 시작했는데 트랜잭션 i가 쓴 객체에 대해서 트랜잭션 j의 읽기 연산이 없을 경우
그냥 보면 뭔 소린가 싶다. 그림으로 살펴보자.
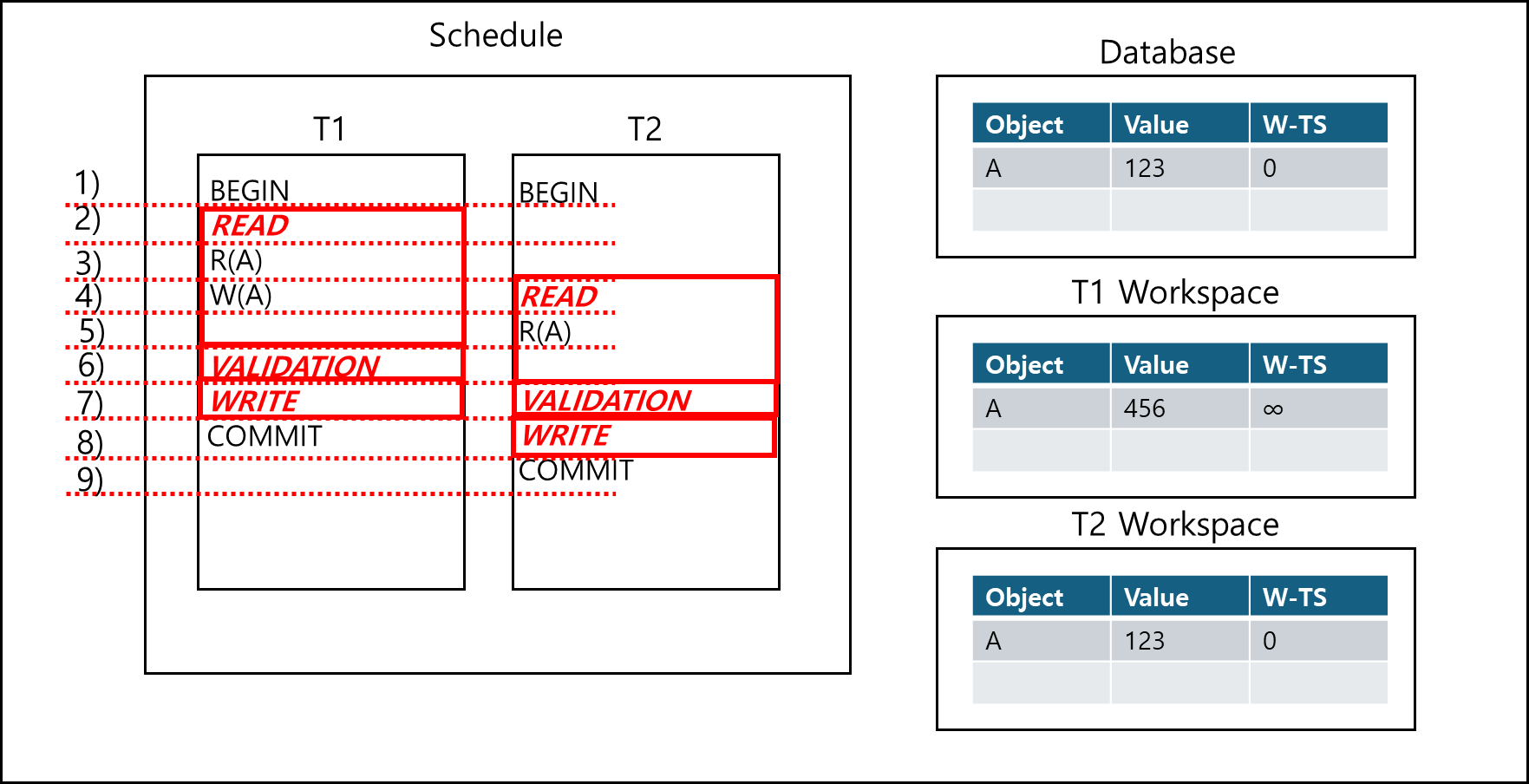
위와 같이 트랜잭션 1,2(이하 T1, T2)가 있다.
T1은 T2의 VALIDATION이 시작하기 전에 VALIDATION에 들어갔다.
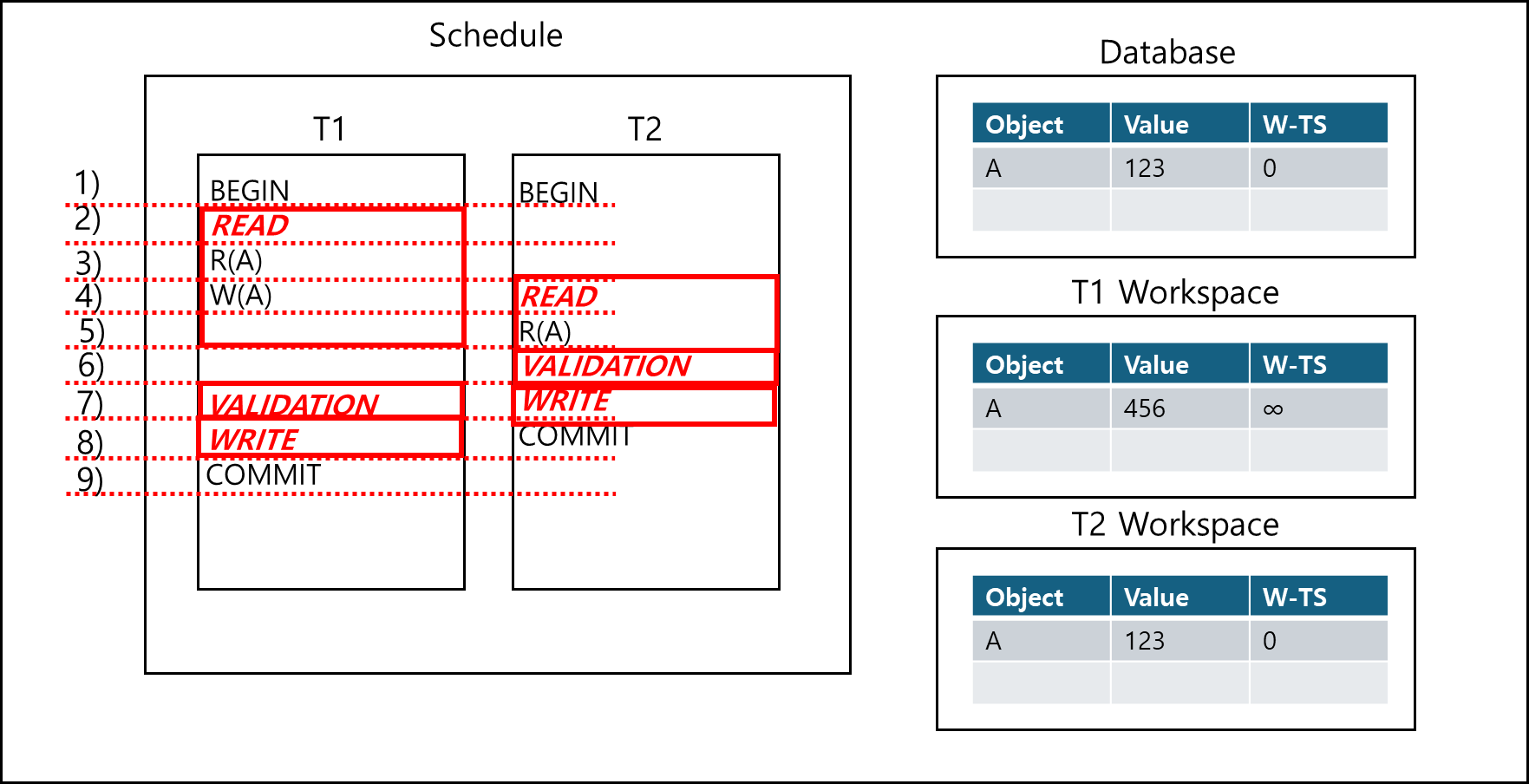
이 경우 T2는 T1의 VALIDATION 고려 대상에 들어가고, 트랜잭션 i가 Write한 대상은 트랜잭션 j가 읽고 있으므로 Abort 처리를해야한다. 다만 아래의 경우는 T2의 VALIDATION이 끝났기 때문에 T1의 VALIDATION 대상으로 취급하지 않기때문에 ABORT를 하지 않는다.
3. 트랜잭션 i가 트랜잭션 2가 완료되기전에 Read Phase를 끝냈을때 트랜잭션 i는 트랜잭션 j가 읽거나 쓴 객체에 쓰기를 하지 않았을 경우
이 역시 그림으로 살펴보겠다.
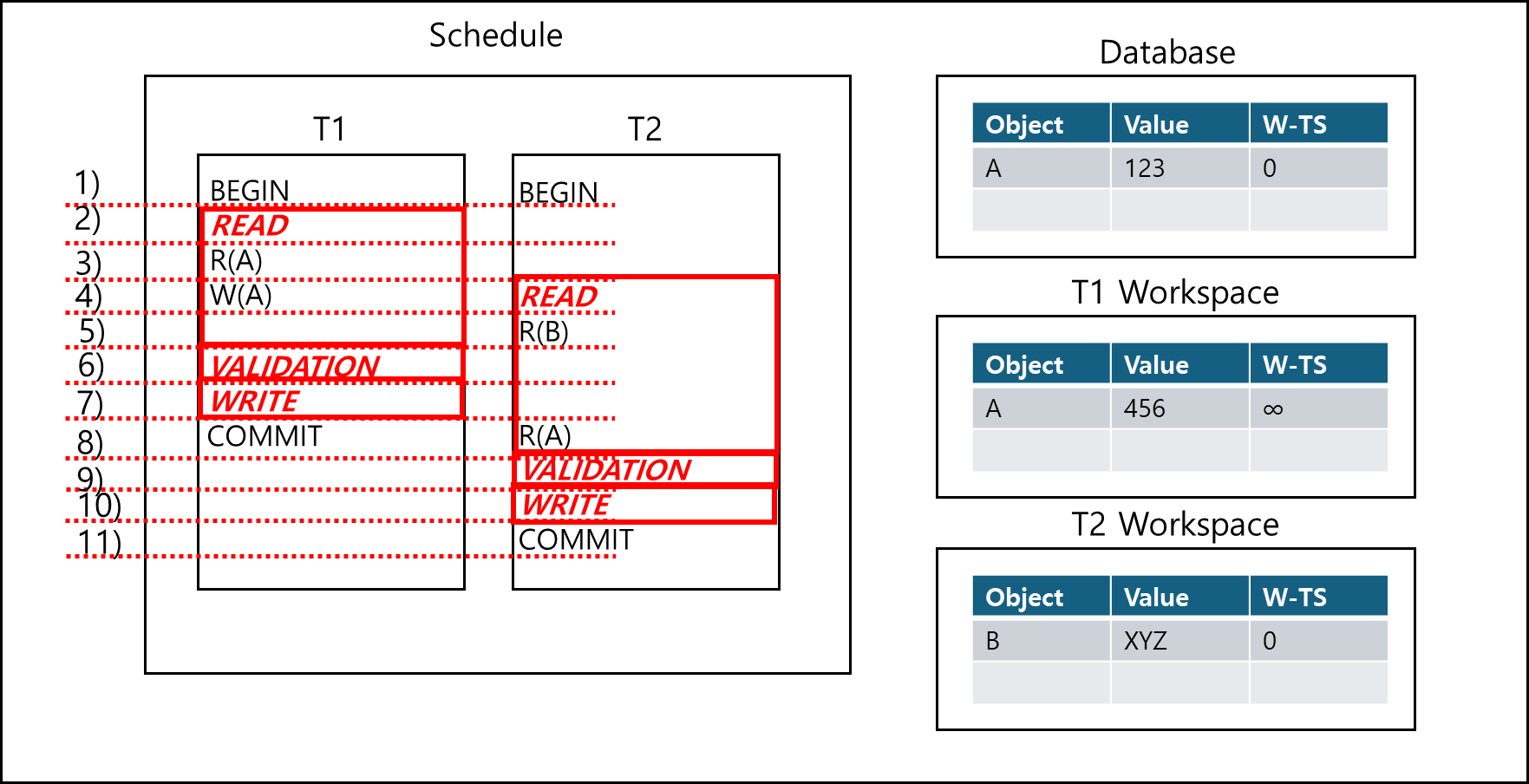
T1의 VALIDATION의 Timestamp는 1(먼저 validation했으므로)이고 이 시점에서 Validation 해봤을때 T2가 완료되기 전에 트랜잭션 2에 대해서 읽기나 쓰지를 하지 않았다. 이후 트랜잭션이 끝나고 나서 T1이 A에 대해서 DATABASE에 WRITE하게되면 T2는 DATABASE에서 변경된 A 값을 읽어올 수 있다.
5) 성능 이슈
OCC도 아래와 같은 이유로 성능 이슈가 있다.
- 데이터 복사하는데 드는 높은 오버헤드
- Validation/Write Phase에서 드는 병목 현상
※ 추가 업데이트 및 검증 예정이고, 아직 완벽하지 않으니 참고만 바란다.
참고자료
- 서강대학교 김영재 교수님 고급데이터 베이스 강의 자료