C++ - 자료형, 변수와 상수
C++ 자료형과 변수
1. 자료형
1) 기본 자료형(Primitive data types)
a. bool(boolean)
1byte의 크기를 갖는 자료형으로 true, false 만 넣을 수 있다.
비교 연산자 (<,>)에서의 반환값은 모두 bool이며 기본적인 내용은 C와 동일하다.
1
bool flag = true;
b. int(integer)
32bit든 64bit 시스템이든 4Bytes이며, 일반적으로 정수를 담는데 사용한다. 앞에 한 비트는 sign bit로 0이면 +, 1이면 -인데, unsigned를 붙이게 되면 sign 비트마저 값을 나타내는데 쓰기 때문에 음의 표현은 못하는 대신 양의 표현범위가 2배로 늘어난다.
1
int num = 123;
c. char(character)
1byte 크기의 자료형으로 한 개의 ascii 코드를 넣을 수 있다.
옛날에야 영어로 모든걸 표현하는게 당연했으니 1byte로 문자 한개를 넣을 수 있게 만든 것이다.
해당 자료형으로 배열을 만들 경우 문자열을 넣을 수 있으며 이는 이후에 추가적으로 포스팅할 것이다.
1
char character = 'a';
d. wchar_t(wide character)
4bytes 크기의 자료형으로 char와 같이 문자를 다루기 위한 자료형이다. 다만 4bytes인 이유는 UTF-8을 지원하기 위함이다.
1
wchar_t w_character = "김";
e. float(floating point number), double(double precision floating point number)
부동소수점을 표현하는 방식으로 float은 4bytes, double은 8bytes의 크기를 가진다.
1
2
float f1 = 1.2;
double d1 = 1.2;
f. void
void 타입은 사실 자료형이긴한데 크기를 가지지 않는다.
해당 자료형으로 변수를 선언할 수 없기 때문이다. 따라서 함수의 반환형이 없을때나 사용한다.
단, pointer를 담는 변수는 고정된 크기를 가지기 때문에 void 타입의 포인터 변수를 선언할 수 있으며 다른 타입의 포인터라도 void로 형 변환해서 넣으면 수용 가능하다.
1
2
3
void testFunction () {}
void *void_pointer;
2) 사용자 정의 자료형(User defined types)
a. struct
C에서는 구조체라고 이야기했던 struct이다. 구조체안에는 여러 기본 자료형 및 사용자 정의 자료형 모두가 포함 될 수 있으며 해당 구조체의 크기는 내부의 모든 원소의 자료형 크기를 모두 더한 값이나, 메모리에 배정시에 속도 효율을 위해 특정 값의 배수로 alignment되어 배정될 수 있다.
1
2
3
struct MyStructure {
int ID;
};
b. enum
열거형이라고 많이들 알고 있다. 정수로 형변환할 경우 처음부터 0,1,2로 찍히지만 해당 플래그들을 사용자가 사용하기 쉽게끔 정의하여 사용할 수 잇다.
1
2
3
4
5
6
7
8
9
10
11
12
#include <iostream>
using namespace std;
int main() {
enum {test,test2};
cout << test << endl;
cout << test2 << endl;
return 0;
}
//결과는 아래와 같이 나옴
//0
//1
c. class
클래스는 사실 다른 언어에서 객체지향 개념을 접했다면 당연히 알 것이다. 이 부분은 추가 포스팅으로 다루겠다.
1
2
3
4
5
6
class MyClass {
public:
MyClass() = default;
~MyClass() = default;
int nID_;
};
d. 공용체
다른 자료형의 값을 상황에 따라 하나만 선택적으로 사용하기 위한 자료구조이다. C에서부터 이어져온 불필요한 공간을 줄이기 위한 눈물 겨운 노력이라고 할 수 있다.
아래와 같이 사용한다.
1
2
3
4
5
6
#include<iostream>
union MyType{
int intNum;
double doubleNum;
}
뭔가 구조체랑 생김새가 비슷하네 할 수 있지만, intNum에 값을 저장하면 doubleNum 값을 못쓰고 반대의 경우도 마찬가지이다. 따라서 해당 union 값에 어떤 것을 쓰는지 알 수 있는 비트를 별도로 갖고 있기 위해 이 union은 구조에체 포함되어 사용되기도한다. union이라는 이름에 맞게 int형과 double으로 위와 같이 정의되면 가장 용량을 크게 요하는 자료형을 따라 해당 MyType의 크기는 8bytes로 잡힌다.
e. 비트 필드
구조체를 이용하여 정의하는 방식으로 해당 데이터의 담을 수있는 bit 수를 지정해서 변수를 선언하는 방식이다.
아래 예시를 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include <iostream>
struct MyType
{
// 4bit 사용하여 변수 선언, 0 ~ 15까지 표현가능
unsigned int b : 4;
};
int main()
{
MyType s = {14};
++s.b; // 15가 됨.
std::cout << s.b << '\n';
++s.b; // 범위 초과. 0으로 됨
std::cout << s.b << '\n';
}
위와 같이 bit 수를 지정하여 변수를 선언할 수 있다.
이런 기능이 왜 필요햐냐고 물을 수 있는데, 가령 network packet을 처리해야한다고 가정해보자.
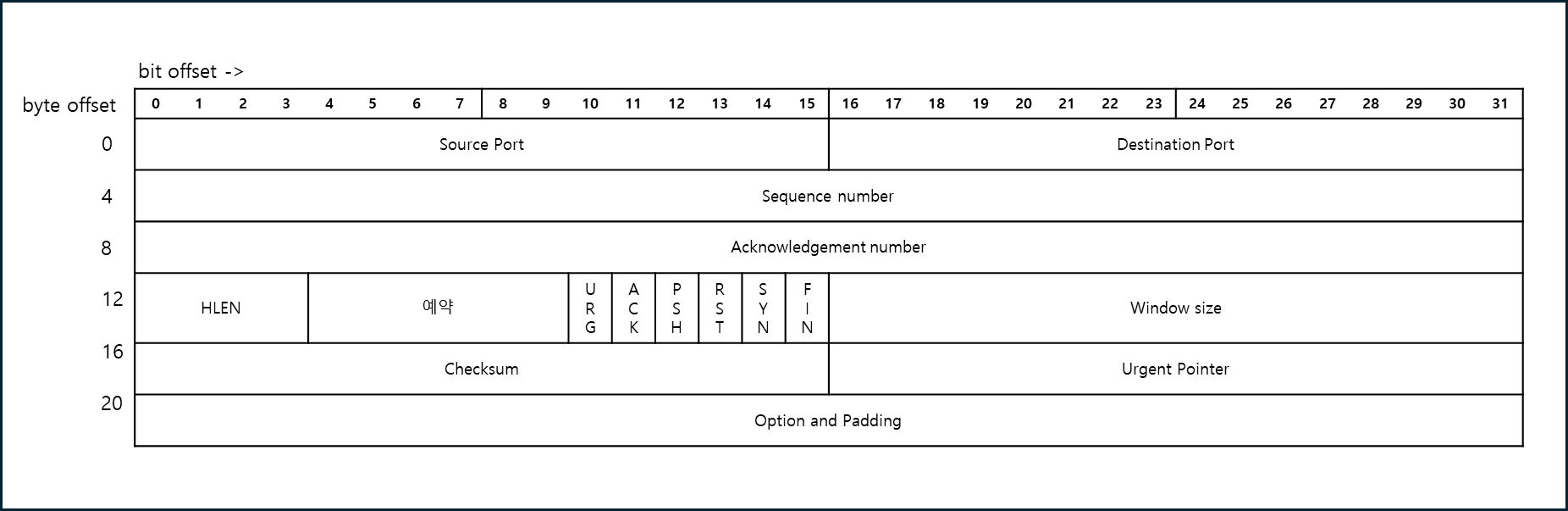
위 그림은 TCP 헤더이다. 이 헤더를 살펴보면 1bit씩 처리해야하는 flag도 가지고 있다. 따로 bit mask를 통해서 bit 연산을 해도 좋겠지만 그렇게 되면 직관적이지 않다. 아예 아래와 같이 struct를 정의해서 사용하면 편하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#include <iostream>
using namespace std;
struct TCP_HEADER {
unsigned int sourePort : 16;
unsigned int destPort : 16;
unsigned int squenceNumber : 32;
unsigned int acknowledgementNumber : 32;
unsigned int hLen : 4;
unsigned int : 6; // 예약 부분은 사용하지 않기 때문에 아예 이름을 비워둠
unsigned int URG : 1;
unsigned int ACK : 1;
unsigned int PSH : 1;
unsigned int RST : 1;
unsigned int SYN : 1;
unsigned int FIN : 1;
unsigned int windowSize : 16;
unsigned int checksum : 16;
unsigned int urgentPointer : 16;
unsigned int : 32;
};
int main()
{
TCP_HEADER header;
header.sourePort = 27017;
header.destPort = 24681;
// ...
cout << sizeof(TCP_HEADER) << endl; // 크기는 24
}
※ 그외 자료형들
코딩테스트할때 자주 쓰이는 std::array, std:::string, std::vector 나 std::map 과 같은 자료구조도 사용자 정의 자료형이다. 이건 좀 중요하기 때문에 별도로 포스팅하겠다.
※ typedef, using
모든 자료형은 별칭을 달 수 있다. typedef는 struct를 쓸때 자주 쓰기도 한다. 아래의 코드를 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <iostream>
using namespace std;
typedef struct MyStructType {
int nNumber;
} myStruct;
int main() {
myStruct test = {1};
myStruct test2 = {42};
cout << test.nNumber << endl;
cout << test2.nNumber << endl;
return 0;
}
C++11부터 using이 typedef와 비슷한 역할을 할수있다고 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <iostream>
using namespace std;
using myStruct = struct MyStructType {
int nNumber;
};
int main() {
myStruct test = {1};
myStruct test2 = {42};
cout << test.nNumber << endl;
cout << test2.nNumber << endl;
return 0;
}
실제로 코드가 잘 돌아간다.
2. 형 변환
사실 나는 C++에서 형변환을 할 때 그냥 C 형식으로 아래와 같이 많이 썼었다.
1
2
float float_num = 1.5;
int int_num = (int)float_num;
하지만 위와 같이 C형식으로 사용할 경우에는 아래와 같이 변경하는게 좋다고 한다.
1
2
3
4
static_cast<new_type>(value); /// 형변환 방법을 컴파일러가 아는 경우, 사용자 정의 자료형은 별도로 형변환 함수를 정의해주어야한다.
const_cast<new_type>(value); /// 일시적으로 const 지정 또는 해제 - 값 변경이 가능한 것은 아니나 포인터 지정등의 제한을 일시적으로 해제
reinterpret_cast<new_type>(value); /// 자료를 재해석하여 형변환하는 것으로 주로 포인터형에 사용한다. 기본적으로 Memory copy와 동일하다.
dynamic_cast<new_type>(value); /// 상속 관계 중 다형성을 사용할 수 있는 경우 up, down 형변환이다. 이후 추가로 예시를 들도록 하겠다.
C 형식으로 형변환시 클래스와 상속 관계 등의 구조로 만들어진 객체의 형변환을 컴파일 타임에 보증할 수 없다고 하는데, 이 경우는 실제로 한번 운용해보고 예시를 달 수 있다면 달도록 하겠다.
3. 변수와 상수
1) const, constexpr
객체를 불변으로 처리해버리는 예약어이다. const로 지정되어있다면 해당 값은 변경 할 수없다.
그리고 원래 const는 const 식별자 왼쪽에 정의된 자료형에 지정되는게 일반적이다.
1
int const a = 0;
그런데 사실 아래와 같이 더 많이 쓴다. 사실 나도 배울때 아래와 같이 배운 것 같다.
1
const int a = 0;
이게 포인터가 들어가는 순간 조금 복잡해진다.
const의 왼쪽에 붙은 것에 대해서 상수처리되기 때문에 아래와 같은 경우 int 값을 변경할 수 없으나 다른 주소를 지정할 수 있다.
1
2
3
4
int const * pointer1 = new int;
*pointer1 = 20;// 불가함, int에 대해 상수처리됨
delete pointer1;
pointer1 = new int; // 이건 가능
아래와 같이 정의된 경우 반대로 int 값은 변경 가능하나 다른 주소 지정이 불가능해진다.
1
2
3
4
int * const pointer2 = new int;
*pointer2 = 20; // 이건 가능
delete pointer2;
pointer2 = new int; // 이건 불가
constexpr는 컴파일 과정에서 체크하는 것인데, 읽기 전용 메모리에 배치해서 성능 향상을 하려고할때 사용한다.
2) static
정적 변수를 선언할 때 쓴다.
이해의 편의를 위해서 아래의 코드로 설명하겠다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <iostream>
using namespace std;
void funcCount() {
int count = 0;
count++;
cout << "Function called " << count << " times." << endl;
}
int main() {
for (int i = 0; i < 10; i++) {
funcCount();
}
return 0;
}
위 코드를 실행하면 Function called 1 times.이라는 문구만 10번 나오게 된다.
이는 funcCount함수의 count 변수가 해당 함수에서만 유효하기 때문에 함수를 벗어나면 없어지고 다시 함수 호출시 생성되며 0이 되기 때문이다.
하지만 아래의 코드를 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <iostream>
using namespace std;
void funcCount() {
static int count = 0;
count++;
cout << "Function called " << count << " times." << endl;
}
int main() {
for (int i = 0; i < 10; i++) {
funcCount();
}
return 0;
}
위 코드의 경우 funcCount 함수의 count 변수의 경우 static 선언을 했기 때문에 프로그램이 종료될때까지 해당 변수는 유지되며, 스택에 잡히는 지역변수와는 달리 전역변수가 있는 Data 영역에 같이 잡히게 된다.
따라서 출력값은 아래와 같이
1
2
3
4
5
6
7
8
9
10
Function called 1 times.
Function called 2 times.
Function called 3 times.
Function called 4 times.
Function called 5 times.
Function called 6 times.
Function called 7 times.
Function called 8 times.
Function called 9 times.
Function called 10 times.
나오게 된다.
굳이 이렇게 하지말고 전역변수로 선언하면 되지 않느냐고 말할 수 있다.
물론 그래도 된다. 하지만 전역 변수로 선언시 모든 곳에서 수정이 가능하기 때문에 에러 검출이 어려울 수 있으며 위와 같이 static으로 설정해두면 해당 함수내에서만 값을 변경할 수 있으므로 에러 제어에 큰 도움이 된다.
3) extern
코드를 짜다보면 소스 코드 파일 여러개에 나눠서 코드를 작성하게 될 때가 있다.
사실 어느정도 사이즈가 넘어가면 당연스럽게 소스코드를 나눠야하며, 이는 컴파일시 이점이 있다.
이렇게 다수의 소스코드 파일이 있을 경우 특정 변수를 각 소스코드 파일간에 공유해야할 때가 있는데 이때 필요한게 extern 식별자이다.
가령 a.cpp라는 파일에 int checkNum이라는 변수가 있다고 해보자.
이 파일의 checkNum이라는 변수를 b.cpp에서도 사용하고 싶다고 할때 가장 위에 아래와 같이 선언하면 된다.
1
extern int checkNum;
물론 위와 같이 선언한다는 건 다른 파일에 이미 checkNum이라는 변수가 선언되어있다는 가정하에 쓰는 것으로 다른 곳에 선언되어 있지 않다면 링킹 간에 에러가 발생하게 된다.
4) auto
자동으로 객체의 자료형을 결정해준다. 약간 javascript의 let이랑 비슷한 느낌이다. (애당초 javascript는 자료형 명시를 하는 경우가 드물지만)
1
2
auto a = 1;
auto b = 1.2;
5) decltype
이 역시 자동으로 객체의 자료형을 결정해주지만 기존에 존재하는 자료형으로 새로운 객체의 자료형을 결정한다.
1
2
auto a = 1;
decltype(a) b = 2;
6) typeinfo
자료형 id를 얻을 수 있는 명령어로 동적으로 자료형에 따라서 처리할 수 있다. typeinfo 헤더를 포함해야한다.
1
2
3
4
5
6
7
8
9
auto a = 123;
auto b = 33.222;
cout << typeid(a).name() << endl
<< typeid(b).name() << endl;
//출력 결과는 아래와 같다.
//i
//d