Google 논문 - MUVERA, Multi-Vector Retrieval via Fixed Dimensional Encodings 분석
Muvera
1. 문제 정의
Neural embedding 모델은 현대 정보 검색 파이프라인의 핵심 구성 요소가 되었다. 이는 어떤 문서를 임베딩 벡터화 했을 때 다수의 문서 중에서 가장 거리가 가까운 값일 수록 해당 문서에 가깝다는 것이 알려졌기 때문이다. 이러한 원리를 이용하여 데이터를 벡터화하여 벡터화한 데이터를 Search하는 방법들이 많이 등장했고 발달하고 있다.
기존의 Vector Search에서 말하는 Vector는 단일 벡터를 다루는 일이 많았다.
여기서 말하는 단일 벡터란, 한 개의 Document를 한 개의 임베딩 벡터로 만드는 것을 말한다.
Document 값이 얼마나 크든 간에 내용이 어떻든 상관없이 한 개의 벡터로 만들어버리므로 의미 손실이 일어난다.
가령 컴퓨터의 역사에 대해서 논하는 Document가 있다고 해보자, 컴퓨터의 역사를 서술했지만 하드웨어 위주로 조명하여 서술한 Document라고 할때 하드웨어에 대한 내용은 소실되고 컴퓨터의 역사라는 것만 남는 식이다.
사용자는 하드웨어 관점의 컴퓨터 역사를 알고 싶다고 할 때 위와 같이 소실된 형태의 벡터가 Document 나타낸다면 찾아내지 못할 가능성이 있다.
이 때문에 Multi-vertor 기법이 나왔는데 이는 한 개의 Document를 토큰, 문장, 섹션등 여러 벡터로 표현해서 쿼리의 특정 부분과 문서의 특정 부분을 직접 매칭 할 수 있기 때문에 정밀도가 올라간다. 이 기법 중에 가장 대표적인 것이 바로 ColBERT이다.
방금 언급했듯이 ColBERT 계열은 쿼리/문서를 토큰별 여러 임베딩(멀티벡터)으로 표현하는데 이렇게 표현하면 각 문맥에 대해서 의미 손실이 적어져 검색 품질은 좋아지지만 시간이 많이 들고 복잡한 연산이 되어버린다. 왜냐면 문서 하나에 다수의 벡터가 나오기 때문에 쿼리 역시 여러 임베딩으로 만들어 이를 각기 계산해주어야하기 때문이다. (이 연산을 MaxSim 혹은 Chamfer Similarity라고 한다)
또한 기존의 1개의 Document에서 1개의 임베딩 벡터가 나왔던것과 달리 다수의 임베딩 벡터가 생성하기 때문에 용량도 커지게 된다.
특히 이 Chamfer Similarity 방식은 이전에 전통적인 Single Vector Search 방식을 사용하지 못한다. 따라서 이를 문제로 본 google research 팀은 솔루션으로 Muvera를 제시했다. MUVERA는 이 멀티벡터 유사도(Chamfer / MaxSim)를 단일 벡터(inner-product) 검색으로 근사하여 기존의 고속 MIPS(Maximum inner product search) 인덱스(예: DiskANN)를 그대로 쓸 수 있게 하는 방식이다.
※ MaxSim or Chamfer similarity
쿼리의 토큰 임베딩 집합 $Q$ 와 문서의 토큰 임베딩 집합 $P$ 가 있다고 할 때 각 집합의 원소를 아래와 같이 정의할 수 있다.
\(Q = \{q_1, q_2, \dots, q_{|Q|}\}\)
\(P = \{p_1, p_2, \dots, p_{|P|}\}\)
여기서 $ q_i, p_j \in R^d $ 이며 d는 임베딩 차원의 벡터이다.
어떤 쿼리와 문서의 토큰 임베딩인 $q$ 와 $p$ 에 대해서 내적을 구하는데 어떤 쿼리 $q$ 에 대해서 문서의 모든 토큰 임베딩에 대해서 내적을 구한다.
그러면 총 문서의 토큰 임베딩 수 만큼의 내적이 나오는데, 그 중에서 가장 최고 값을 찾는다.
\[\max_{p \in P} \langle q, p \rangle\]이는 특정 쿼리 토큰에 대해 문서 내에서 가장 잘 매칭되는 토큰을 찾는 과정이다.
이 과정을 모든 쿼리 임베딩 토큰에 대해서 반복하고 찾을 최고 값들을 모두 더한다.
위 계산은 한 개의 Document에 대해서만 이뤄진 것이다. 만약 가장 가까운 Document를 찾고 싶다면 모든 문서에 대해서 Chamfer similarity를 구해서 그 중에 가장 값이 높은 것을 찾으면 될 것이다.
2. 핵심 아이디어
각 쿼리/문서의 멀티 벡터를 고정 차원 싱글 벡터로 변환하여 이 두 벡터의 내적이 Chamfer similarity를 근사하도록 설계하는 것이다.
1) 공간 분할
한 개의 문서에 다수의 임베딩 벡터가 있다. 이를 SimHash로 latent space를 B개 cluster로 나눈다. 이렇게 나눌 경우 가까운 포인트가 같은 cluster에 들어갈 확률이 높다. SimHash로 나눌 경우 B는 아래의 값이 된다.
\[B = 2^{K_{sim}}\]K-means로 나눌 수도 있지만 SimHash가 데이터에 구애받지 않기 때문에 좀 더 우수하다고 한다.
(데이터에 구애받으면 한쪽으로 쏠림 현상이 일어날 수 있다)
위 함수를 $ \phi $ 라고 하면 이 함수는 d차원의 실수를 B로 사상시킨다.
\[\phi: R^d \rightarrow [B]\]※ SimHash
simHash는 문서(또는 문자열)의 ‘특징’을 고정된 길이의 비트(예: 64비트)로 요약해서, 비트 간의 해밍거리(Hamming distance)를 통해 문서 유사도를 빠르게 계산하게 해주는 기법이며 LSH(지역 민감 해시)이다. 일반 Hash는 충돌이 적으면 적을 수록 좋은 반면, 지역 민감 해시는 비슷한 것들끼리 해시값이 비슷하게 만든다.
FDE 생성 절차간 simHash의 절차는 아래와 같다.
- 랜덤 가우시안 벡터 샘플링을 이용한 simHash 함수 생성
- SimHash 값을 계산하여 각 토큰 임베딩에 대한 클러스터 할당
사실 이렇게 들으면 전혀 이해가 가지 않을 것이다. 4) 예시를 보는게 빠를 수도 있다.
# Hamming distance
해밍 거리란 두 값이 얼마나 차이가 있냐는 나타내는 거리이다.
어떤 이진수 11001101과 10111011가 있다고 할 때 이 두 값의 해밍 거리는 아래와 같이 구할 수 있다.

XOR 한 값의 1이 5개이므로 해밍거리는 5이다.
2) 블록 구성
각 cluster k에 대해 쿼리 블록은 그 cluster 에 속한 쿼리 벡터들의 합
\[q^{(k)} = \sum_{q \in Q, \phi (q) = k} q\]문서 블록은 그 cluster가 속한 문서 벡터들의 평균으로 둔다.
\[p^{(k)} = \frac{1}{\left|P \cap \phi^{-1}(k)\right|} \sum_{p \in P, \phi(p)=k} p\]이렇게 각 Cluster마다 d차원의 블록을 만든다.
이 BLOCK들을 다 붙여서 임시 FDE를 만든다.
임시 FDE의 차원은 블록 개수가 B이고, 차원이 d라고 한다면 $Bd$ 로 표현할 수 있다.
단, 어떤 cluster에 그 문서의 토큰이 하나도 없으면 0으로 두지 않고, 그 cluster에 ‘가장 가까운’ 문서 토큰을 대신 넣어 근사 실패(빈 충돌)를 줄인다.
이러한 작업은 문서 FDE에만 적용하며 쿼리 FDE에는 적용하지 않는다.
이렇게 만들어지면 데이터 불변(data-oblivious)한 변환으로 멀티벡터 유사도를 단일 내적으로 근사하게 된다.
3) 내부 및 최종 투영
임시 FDE는 블록을 단순히 붙여서 차원이 매우 높다. 차원이 높으면 계산하는데 문제가 생기므로 각 블록의 차원을 적절하게 줄이는 과정이 필요하다.
이를 위해서는 투영 함수가 필요한데, 논문에서는 투영 함수를 아래와 같이 정의한다.
여기서 x는 투영될 원래의 블록 벡터 $ q^{(k)} $ 또는 $ p^{(k)} $ 의 값이며
S는 +1과 -1로 구성된 랜덤 행렬이다.
해당 S 행렬을 곱함으로써 $d$ 차원을 $d_{proj}$으로 줄일 수 있다.
\(d_{proj}\) 값은 값을 실험적으로 튜닝하는 경우가 많으며 논문에서는 8, 16, 32값으로 세팅했다.
정확도를 높이기 위해서 위 과정을 서로 다른 무작위 분할 및 투영을 사용하여 1회 이상 독립적으로 반복한다.
최종 FDEs는각 반복에서 얻은 투영된 블록 벡터들을 최종적으로 모두 연결하여 FDE의 차원을 더욱 늘리고 정확도를 높일 수 있다.
※ 투영(Projection)
고차원의 데이터를 저차원의 데이터로 변환한다고 생각하면 편하다.
예를 들어보자, 원래 데이터가 아래와 같다고 해보자.
원래는 2차원의 데이터이다. 이를 위의 식 $ \psi(x) = \left( \frac{1}{\sqrt{d_{proj}}} \right) Sx $ 을 써서 투영한다고 해보자
$d_{proj}$ 는 d보다 작아야하니, 1로 하고, $Sx$는 임의로 {+1,-1}로 두었다. 이를 가지고 계산해보면 아래와 같다.
위 계산 결과 $ [x_{1}, x_{2}] $ 에서 $ [x_{1} - x_{2}] $ 로 1차원으로 변환되었다. 이를 투영이라고 한다.
4) FDE 생성 예시
원본 논문도 온갖 수식이 난무한다. 수학을 잘하면 그냥 봐도 이해하겠지만, 포스팅을 하는 필자부터가 수학을 잘 못한다.
그래서 일단 하나하나 예시를 들어가면서 설명하는게 내가 설명하기에도 편하고 보는 이도 편할 것이다.
a. 문서 및 쿼리 벡터화
일단 문서와 다중 벡터화한다. 이거까지 설명하기는 어렵다. 문장, 구 등 여러 단위로 토큰화해서 임베딩 벡터로 만든다.
이 과정에 대해서는 Colbert 논문을 참고하는게 빠를것이다.
예시로 쓸 문서 토큰 임베딩 집합 $P$ 에는 1개의 문서가 있는데, 이 문서는 2개의 토큰($p_{1},p_{2}$)으로 이루어져있으면 차원은 3이고 값은 아래와 같다.
\(P = \{p_1, p_2\}\)
\(p_1 = [0.7, 0.7, 0.1]\)
\(p_2 = [-0.5, 0.5, 0.7]\)
b. simHash 함수 생성
$k_{sim}$ 개의 랜덤 가우시안 벡터 샘플링을 통해 simHash 함수를 생성한다.
랜덤 가우시안 벡터는, 랜덤 가우시안 변수를 원소로 하는 벡터인데 여기서 랜덤 가우시안 변수라는 것은 가우시안 분포(표준분포) 를 따르는 값으로 축약하자면 그냥 가우시안 분포를 따르는 값으로 이루어진 벡터라고 생각하면 된다.
이 값들을 기준으로 공간을 초편면으로 나눈다. 여기서는 $k_{sim}=2$ 로 2개의 3차원 랜덤 가우시안 벡터를 샘플링하여 아래의 2개 값을 만들었다.
\(g_1 = [0.1, -0.9, 0.2]\)
\(g_2 = [-0.8, 0.3, 0.6]\)
c. SimHash 값 계산
토큰 임베딩 x에 대해서 simHash 함수인 $\phi(x)$ 는 아래와 같이 정의된다.
\[\phi(x) = (\mathbf{1}(\langle g_1, x \rangle > 0), \ldots, \mathbf{1}(\langle g_{k_{sim}}, x \rangle > 0))\]여기서 $ \mathbf{1}(\cdot) $ 은 지시 함수로 괄호안의 조건이 참이면 1이고 거짓이면 0을 반환한다. x를 이 함수에 넣으면 1과 0으로 만들어진 비트 스트링(Bit string)이 주어지는데 이를 십진수로 변환하여 해당 토큰 임베딩이 어느 클러스터에 속할지 정하는 클러스터 인덱스를 얻을 수 있다.
$ p_1 = [0.7, 0.7, 0.1] $ 에 대해 아래와 같이 연산된다. \(\langle g_1, p_1 \rangle = (0.1 \cdot 0.7) + (-0.9 \cdot 0.7) + (0.2 \cdot 0.1) = 0.07 - 0.63 + 0.02 = -0.54\) \(\mathbf{1}(\langle g_1, p_1 \rangle > 0) = 0\)
\(\langle g_2, p_1 \rangle = (-0.8 \cdot 0.7) + (0.3 \cdot 0.7) + (0.6 \cdot 0.1) = -0.56 + 0.21 + 0.06 = -0.29\) \(\mathbf{1}(\langle g_2, p_1 \rangle > 0) = 0\)
따라서 $p_{1}$ 의 비트스트링은 (0,0)이다. 총 2bit의 크기이니 4개의 클러스터가 가능하며, 00을 십진수화하면 0번이니 0번 클러스터에 매핑된다.
$ p_2 = [-0.5, 0.5, 0.7] $ 에 대해 아래와 같이 연산된다. \(\langle g_1, p_2 \rangle = (0.1 \cdot -0.5) + (-0.9 \cdot 0.5) + (0.2 \cdot 0.7) = -0.05 - 0.45 + 0.14 = -0.36\)
\(\mathbf{1}(\langle g_1, p_2 \rangle > 0) = 0\)
\(\langle g_2, p_2 \rangle = (-0.8 \cdot -0.5) + (0.3 \cdot 0.5) + (0.6 \cdot 0.7) = 0.40 + 0.15 + 0.42 = 0.97\)
\(\mathbf{1}(\langle g_2, p_2 \rangle > 0) = 1\)
따라서 $p_{2}$ 의 비트스트링은 (0,1)이다. 01을 십진수화하면 1번이니 1번 클러스터에 매핑된다.
d. 클러스터별 FDE 블록 생성
먼저 클러스터를 초기화한다. 총 3차원이고 4개의 블록으로 이루어져있다.
또한 평균을 내기 위해서 블록에 몇 개의 토큰이 포함되었는지 카운터가 필요하다.
따라서 아래와 같이 초기화한다.
\(p_{block}^{(0)} = [0,0,0], p_{block}^{(1)} = [0,0,0], p_{block}^{(2)} = [0,0,0], p_{block}^{(3)} = [0,0,0]\) \(count_p^{(0)}=0, count_p^{(1)}=0, count_p^{(2)}=0, count_p^{(3)}=0\)
p1은 아래와 같이 클러스터 0에 할당된다.
\(p_{block}^{(1)} \leftarrow p_{block}^{(1)} + p_1 = [0,0,0] + [0.7, 0.7, 0.1] = [0.7, 0.7, 0.1]\)
\(count_p^{(1)} \leftarrow 1\)
p2는 아래와 같이 클러스터 1에 할당된다.
\(p_{block}^{(2)} \leftarrow p_{block}^{(2)} + p_2 = [0,0,0] + [-0.5, 0.5, 0.7] = [-0.5, 0.5, 0.7]\)
\(count_p^{(2)} \leftarrow 1\)
이렇게 되면 클러스터 0과 1에 대해서 각각 1개씩 토큰 임베딩이 포함되었다.
각각 클러스터 블럭에 대해서 평균을 내줘야한다.
현재는 각각 1개씩만 들어있어서 값이 그대로 유지되만 다수개가 포함된다면 그만큼 나눠지게 된다.
나머지 2,3번 클러스터는 카운터가 0이기 때문에 당장은 초기화된 그대로 유지된다.
e. 빈 클러스터 채우기
문서 FDE에만 적용되는 것으로 빈 클러스터에서 가장 가까운 해밍 거리를 가진 문서 토큰 임베딩 값을 가져와서 채운다.
클러스터 2의 비트 스트링은 10이다. $p_{1}$ 과 $p_{2}$ 의 비트 스트링 값은 00과 01이다. 이를 해밍거리로 계산시 00은 1, 01은 2이므로 00인 $p_{1}$ 이 선택되어 클러스터 2에 채워진다.
\(p_{block}^{(2)} \leftarrow p_1 = [0.7, 0.7, 0.1]\)
클러스터 3도 마찬가지이다. 비트스트링은 11이며, $p_{1}$ 과 $p_{2}$ 에 대해서 해밍거리 계산시 이를 해밍거리로 계산시 00은 2, 01은 1이므로 00인 $p_{2}$ 가 선택되어 클러스터 3에 채워진다.
\(p_{block}^{(3)} \leftarrow p_2 = [-0.5, 0.5, 0.7]\)
앞서 언급했듯이 문서 FDE에만 적용하기 때문에 쿼리 FDE에서는 해당 클러스터는 초기화된 그대로 남아있다.
f. FDE 블록 연결 및 내부 무작위 선형 투영
이때까지의 절차로 아래와 같은 문서 블록이 생성되었다.
\[p_{block}^{(0)}=[0.7,0.7,0.1], p_{block}^{(1)}=[-0.5,0.5,0.7], p_{block}^{(2)}=[0.7,0.7,0.1], p_{block}^{(3)}=[-0.5,0.5,0.7]\]이 차원은 현재 차원인 3보다 더 작은 차원으로 투영하는데, 이 투영을 위해서 랜덤 행렬 $S_{inner}$ 을 생성한다. 그리고 각 블록에 대해서 곱해주면 된다.
$p_{block}^{(0)}$ 만 예시를 들어보자면 아래와 같이 표현할 수 있다.
랜덤 행렬 $ S_{inner} = [1, -1, 0] $ 라 할 때
\[p_{block}^{(0),\psi} = \psi(p_{block}^{(0)}) = [0.7 - 0.7 + 0.0] = [0.0]\]나머지도 동일한 랜덤 행렬로 곱해준 뒤에 투영되어 차원이 축소된 차원 블록들을 연결하여 하나의 반복에 대한 임시 FDE 벡터를 생성한다.
g. 반복
위 a ~ f 까지의 단계를 반복하는데 매 반복마다 랜덤 가우시안 벡터 $g_{i}$ 와 랜덤 행렬 $ S_{inner} $ 을 사용해서 a ~ f 까지의 단계를 반복한다. 각 반복마다 얻은 임시 FDE를 모두 연결하여 최종 FDE 벡터를 완성한다.
3. 실험 및 평가
1) 데이터 셋
성능 실험을 위해 사용된 데이터 셋은 아래와 같다.
| MS MARCO | HotpotQA | NQ | Quora | SciDocs | ArguAna | |
| 쿼리개수 | 6,980 | 7,405 | 3,452 | 10,000 | 1,000 | 1,406 |
| 문서개수 | 8.84M | 5.23M | 2,68M | 523K | 25.6K | 8.6K |
| 문서당 평균 임베딩 개수 | 78.8 | 68.65 | 100.3 | 18.28 | 165.05 | 154.72 |
2) Offline Evaluation of FDE Quality
FDEs(Fixed Dimensional Encodings)가 Chamfer Similarity를 얼마나 잘 근사하는지, 그리고 실제 검색 성능에 어떤 영향을 미치는지 재랭킹이나 ANNS 알고리즘 적용 없이 순수하게 FDE 자체의 품질만을 평가하며 FDEs가 이상적인 상황(예: 완전 탐색)에서 얼마나 정확한 유사도를 제공하는지 측정한 것이다.
반복 횟수와 simHash 비트수와 내부 투영 차원의 값을 아래와 같이 두고 격자 탐색(Grid Search)를 진행했다.
\(R_{reps} = {1,5,10,15,20}\) \(k_{sim} = {2,3,4,5,6}\) \(d_{proj} = {8,16,32,64}\)
Recall@N (예: Recall@100, Recall@1k, Recall@10k)을 사용하여 측정했으며 이는 실제 Chamfer Similarity에 따라 가장 유사한 문서 N개를 PDE 내적 순으로 N개 후보 안에서 얼마나 찾아내는지를 나타낸다.
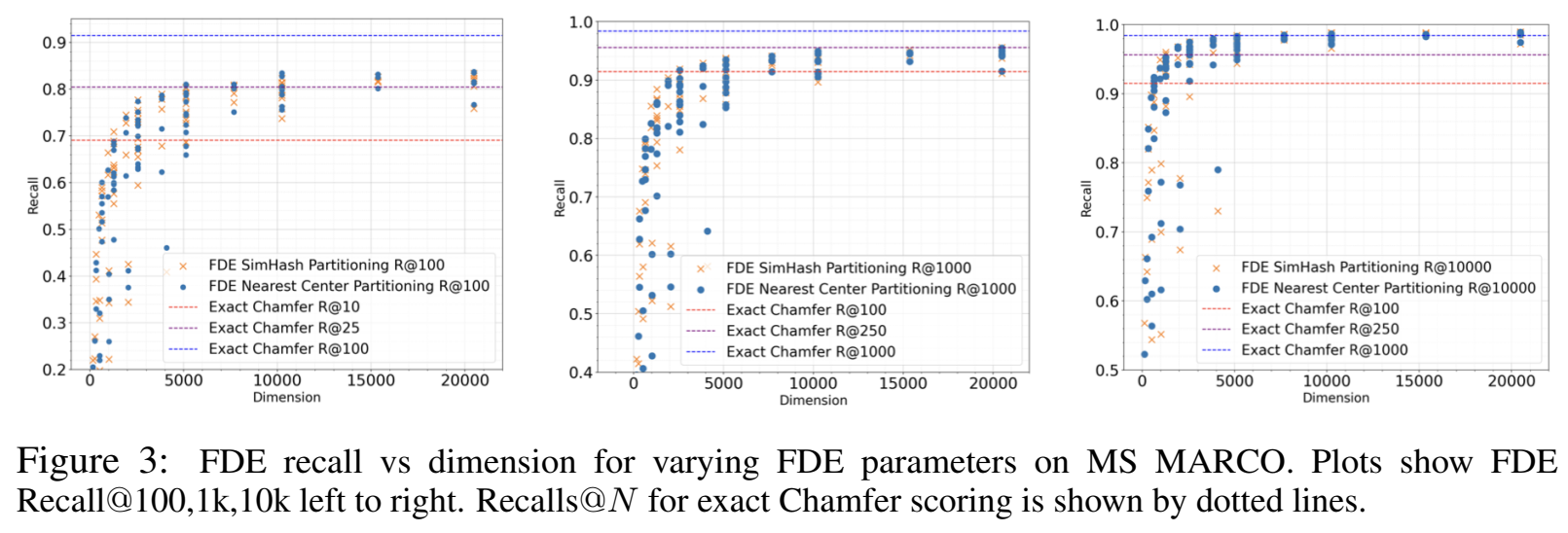
위 그래프를 볼 때 기본적으로 FDE의 차원이 증가할 수록 재현율이 꾸준히 향상되는 경향을 보이며 simHash 비트수와 투영차원 수는 반복 값에 비해서 품질 향상에 있어서 비교적 덜 중요한 역할을 한다. 또한 (Rreps, ksim, dproj) ∈ {(20, 3, 8), (20, 4, 8)(20, 5, 8), (20, 5, 16)}는 각각의 차원(즉, Rreps · 2ksim · dproj)에 대해 모두 파레토 최적(Pareto optimal)이었다.
클러스터링 방식을 simHash가 아닌 K-means로 클러스터링시에 파레토 경계에서 종종 품질 향상을 제공하지 않으며 종종 더 나쁘게 나오는 경우도 있다. 또한 k-means를 사용하는 경우, FDE를 구성하는 과정이 데이터의 분포에 의존하게 되어, 데이터 비의존적(data-oblivious)인 SimHash의 장점을 잃게 된다는 것을 알 수 있다.
3) Single Vector Heuristic vs. FDE retrieva
멀티 벡터 검색을 위한 대체제로서 FDE의 품질을 이전에 설명한 SV 휴리스틱과 비교한다. 이 SV 휴리스틱은 PLAID의 기반이다.
쿼리의 임베딩 벡터에 대해 문서의 토큰 임베딩 벡터의 집합에서 가장 가까운 것부터 K개까지를 찾아내고, 동일한 문서를 가리키고 있다면 중복을 제거하여 K개까지 맞추는 과정을 거친다. 이 방식을 SV-DEDUP이라고 정의할 때 FDE 방식과 SV, SV-DEDUP과의 재현율에 대한 비교는 아래와 같다.
4) Online Implementation and End-to-End Evaluation
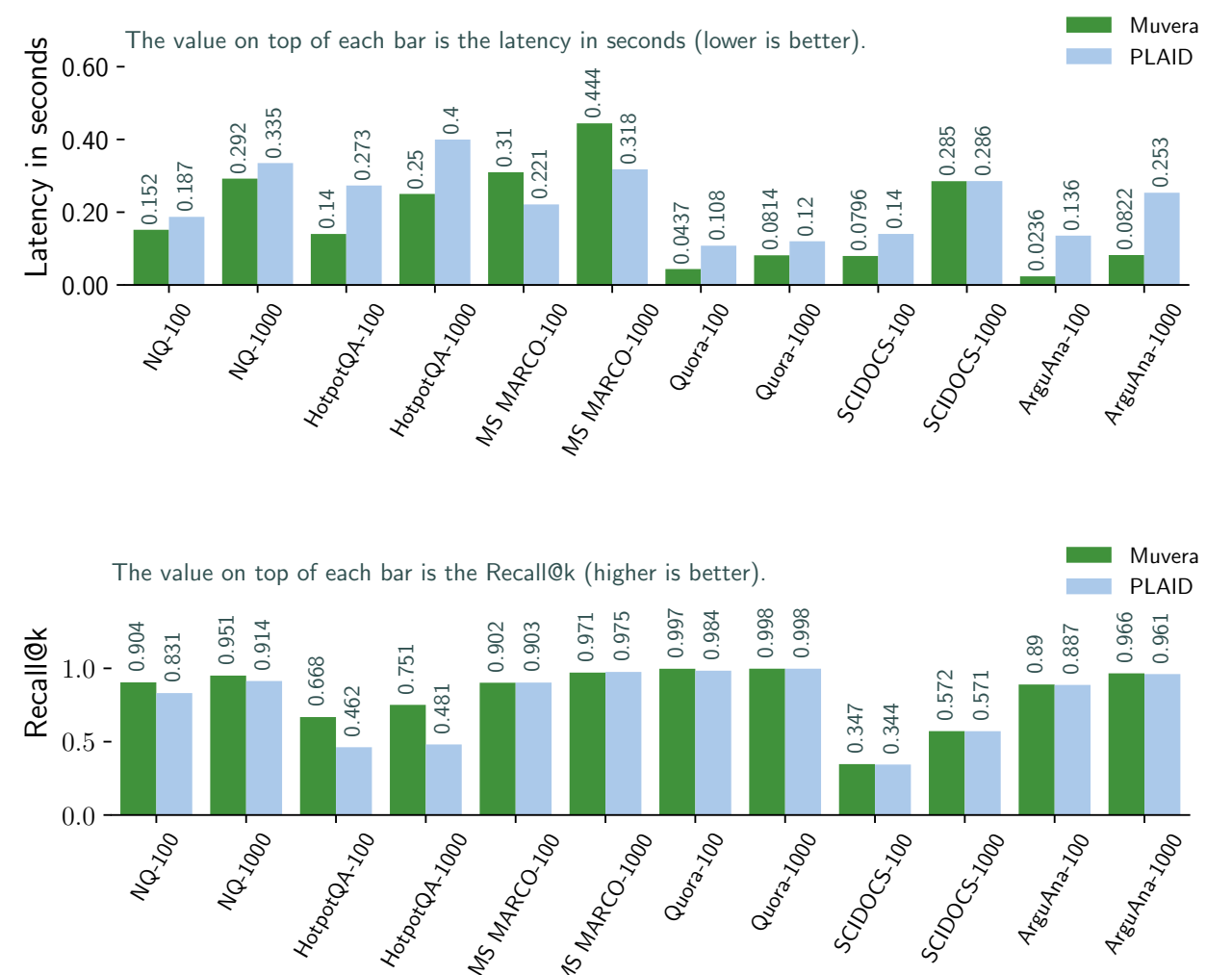
논문에서는 해당 실험에 대해서 DiskANN 으로 검색을 구현하고, ANN 뽑은 후보군에 대해서 Reranking을 진행했다고한다. DiskANN을 사용할때 유일하게 튜닝한 인자는 W값이라고 말했으며, 이는 빔 서치간 한번에 서치하는 정도이다.
메모리 사용량을 줄이기 위해 연속된 8개 차원 세트를 256개 중심 중 하나로 압축하여 Product Qunatization을 했으며 QPS 실험은 176개의 하이퍼 스레드를 지원하는 가상머신에서 구동하여 테스트를 했고, 대기 시간 실험은 단일 스레드를 사용했다고 한다.
각 데이터셋에 대해 PLAID와 Muvera의 재현율과 지연시간에 대한 그래프는 아래와 같다.
참고문헌
- Dhulipala, Laxman, Majid Hadian, Rajesh Jayaram, Jason Lee, and Vahab Mirrokni. ‘MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings’. arXiv [Cs.DS], 2024. arXiv. http://arxiv.org/abs/2405.19504.
- Khattab, Omar, and Matei, Zaharia. “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT.” . In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 39–48). Association for Computing Machinery, 2020.