OPENSTACK - Placement
Placement
1. 개요
Placement는 원래 노바 프로젝트 내에 있다가 이후에 별도의 프로젝트로 분리되었으며 리소스 공급에 대한 여러 사용량들을 추적하는데 사용되는 API 스택과 데이터 모델이다.
여기서 컴퓨팅 노드, 공유 스토리지 풀, IP 할당 풀등에서 메모리 사용량과 CPU 사용량, 잔여 스토리지, 잔여 IP 등을 추적할 수 있다.
이러한 리소스들은 클래스로 제공되며 위에서 언급한 메모리, 디스크 잔여, vCPU에 관한 것들은 표준 리소스 클래스 집합으로 제공된다. 또한 별도로 필요한 리소스는 클래스로 정의할 수 있다.
기본적으로 nova를 위해 만들어진 것이기 때문에 nova에 가장 적합하다고하지만 다른 서비스에서도 적용할 수 있을만한 디자인으로 구성되었기에 다른 서비스와도 연동이 가능하다고 되어있다.
2. 구조
각 인스턴스에 붙어서 관련 메트릭에 대해서 직접적으로 DB에 전달해주는 식이다.
이는 마이크로 서비스까지는 아니지만 최대한 시스템에 무리가 가지 않게하기 위해 이러한 형태를 하게 되었다고 한다.
프로젝트 nova에서 파생된 프로젝트이니 프로젝트 nova의 구조를 따와서 설명하자면 아래와 같다.
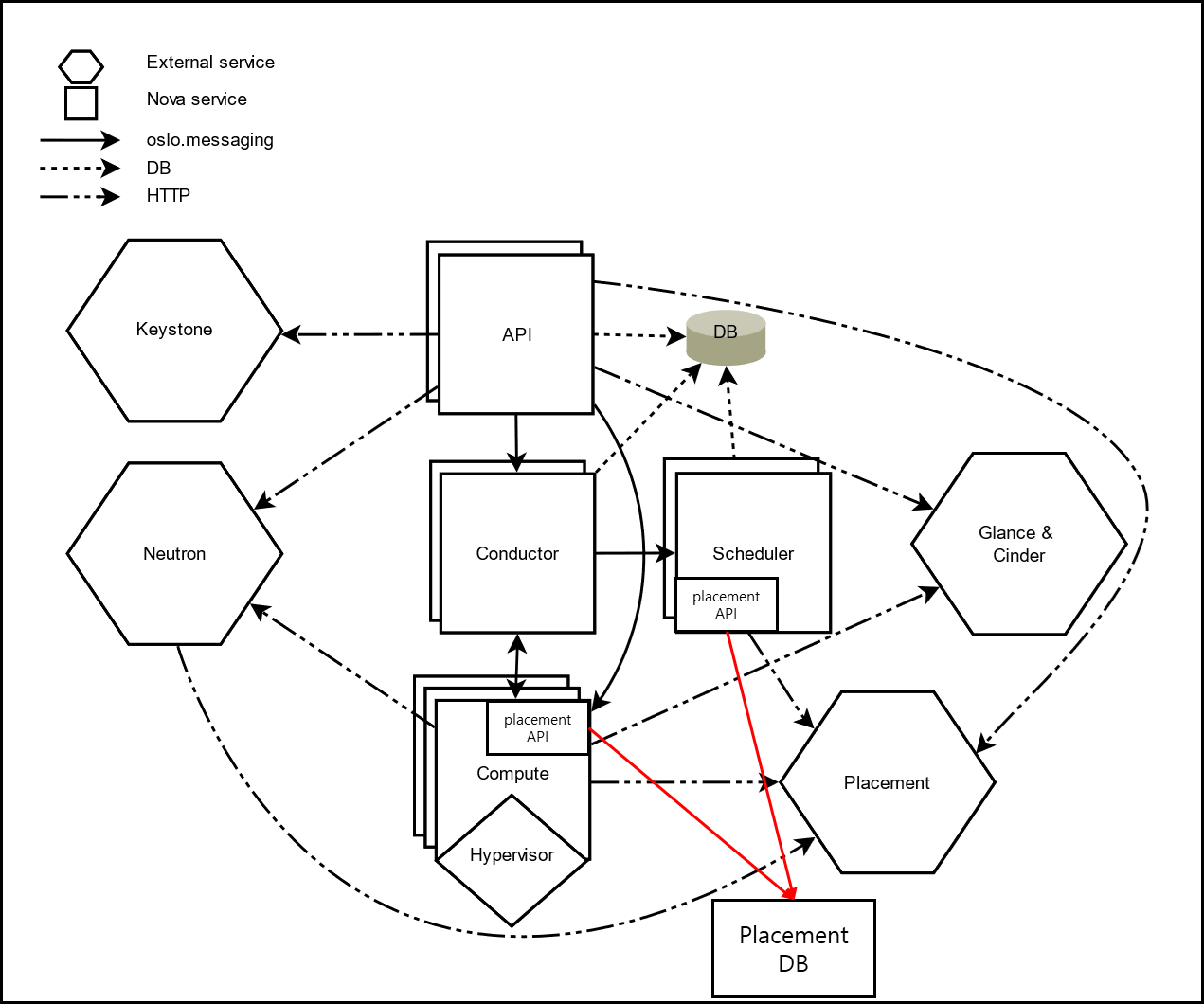
Nova에서 Placement가 가장 많이 사용되는 부분은 바로 compute 부분과 scheduler에 placement를 부착하고 운용하는 방식이다. 동일한 하드웨어일수도 있고, 다른 하드웨어일 수도 있기 때문에 각각 프로세스에 placement가 붙어서 리소스 트래킹을 하고 있다는 표현이 좀 더 적합할 듯하다.
nova-compute compute 프로세스에서 리소스 추적기로 작동하는 placement용 리소스 추적기는 컴퓨팅 호스트에서 해당 리소스의 사용량에 대해 트래킹한다. 이후 vCPU와 같이 정량적 리소스와 STOARGE_DISK_SSD와 같은 정성적 리소스를 설정하여 수집한다.
nova-scheduler 스케줄러는 이전 nova 포스팅에서도 언급했지만 할당 후보를 정하는 역할을 하는데 placement가 수집 요청은 할당 후보 목록부터 시작되는데 요청에는 정량적, 정성적, 특정 집합에 대한 개수 뿐만 아니라 복잡한 경우 관련 리소스의 토폴로지 까지 포함된다.
nova 프로젝트의 경우 위와 같이 운용되지만 다른 프로젝트의 경우에는 다른 방식으로 운용 될 수 있으며 각 프로세스가 구동되는 환경에서 필요한 지표를 지정하면 해당 지표를 수집할 수 있다.