OPENSTACK - Swift
Swift
1. 개요
고가용성이며 분산된 오브젝트 파일 저장소이다. 싸고 편하고 안전하게 데이터를 보관하는게 이 프로젝트의 목적이다. AWS에 대해서 아는 사람들이라면 S3를 생각하면 이해하기 쉬울 것이다.
REST API 형태로 요청을 받을 수 있게 구현되어있으며 인증 토큰을 통해 사용자를 식별하여 권한이 주어진다.
2. 논리적 구조
REST API를 이용하여 SWIFT에 요청할때 아래와 같은 URL 구조를 갖는다
1
{계정}/{컨테이너}/{객체}
이는 논리적으로도 해당 구조를 갖기 때문인데 아래와 같다.
1) 계정
계정은 구조적으로 최상위 계층이며 컨테이너를 위한 이름공간이라고 할 수 있다. 컨테이너는 계정 내에서 유일한 이름을 갖는다. 오픈 스택내에서 계정은 프로젝트나 사용자와 동의어이다.
2) 컨테이너
객체에 대한 이름공간을 지정한 것을 컨테이너라고 한다. 이 컨테이너의 이름은 계정 내에서 유일하며 계정이 다르다면 동일한 이름을 가질 수 있다. 계정은 다수의 컨테이너를 소유할 수 있으며 이 컨테이너에는 객체를 다수 포함 시킬 수 있다. 물론 액세스 제어목록(ACL)을 사용하여 객체에 대한 엑세스를 제어할 수 있고 객체의 버전 관리나 여러 저장 정책들을 설정 할 수 있다.
3) 객체
문서, 이미지와 같은 데이터와 사용자 지정 메타 데이터를 객체라 말한다.
API를 이용하면 아래와 같은 작업을 할 수 있디.
- 객체의 개수 제한 없이 저장할 수 있다.
- 각 객체는 기본적으로 최대 5GB까지 저장할 수 있으나, 최대 객체 크기를 설정할 수 있다.
- 대용량 객체 생성을 통해 크기에 제한 없이 객체를 업로드하고 저장할 수 있다.
- 객체 보안을 관리하기 위해 교차 출처 리소스 공유(CORS)를 사용할 수 있다.
- 콘텐츠 인코딩 메타데이터를 사용하여 파일을 압축할 수 있다.
- 콘텐츠 디스포지션 메타데이터를 사용하여 객체에 대한 브라우저 동작을 재정의할 수 있다.
- 객체 삭제 일정을 설정할 수 있다.
- 한 번의 요청으로 최대 10,000개의 객체를 대량 삭제할 수 있다.
- 아카이브 파일을 자동으로 추출할 수 있다.
- 객체에 대해 제한된 시간 동안 GET 액세스를 제공하는 URL을 생성할 수 있다.
- 양식 POST 미들웨어를 사용하여 브라우저에서 객체 스토리지 시스템으로 객체를 직접 업로드할 수 있다.
- 다른 객체에 대한 심볼릭 링크를 생성할 수 있다.
3. 물리적 구조
위의 논리적 구조를 구현하기 위해 물리적 구조는 아래와 같이 되어있다.
큰 그림은 아래와 같다.
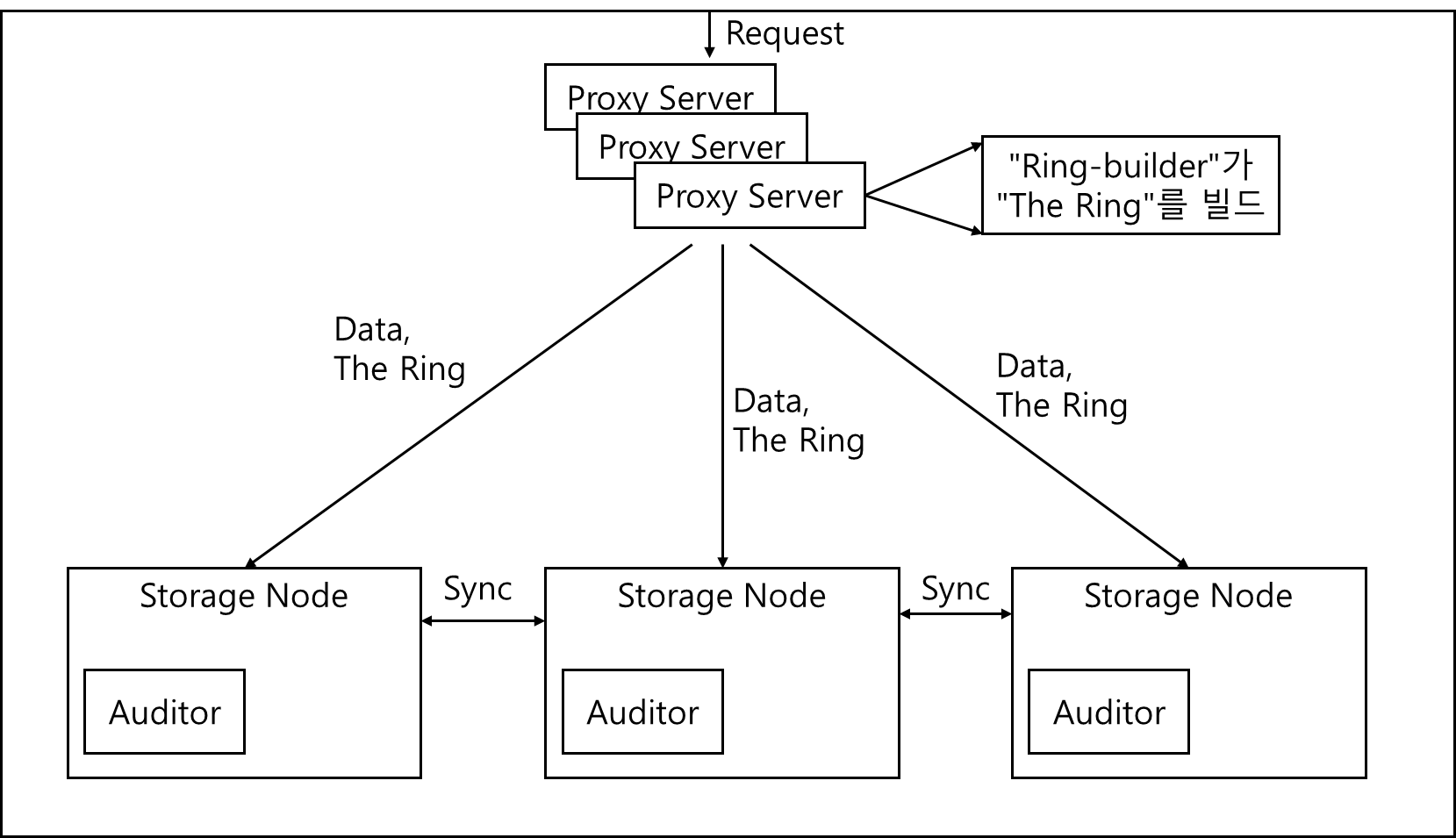
1) 프록시 서버
스위프트의 요소들을 하나로 엮는 역할을 한다. 각 요청에 대해 링에서 계정, 컨테이너, 객체의 위치를 조회하고 그에 대한 요청을 라우팅하며 Erasure Code 유형 정책의 경우 개체 데이터를 인코딩하고 디코딩하는 역할도 한다.
많은 수의 실패 역시 프로시 서버에서 제어한다. 가령 서버가 객체에 대해 PUT 요청을 사용할 수 없을 경우 대체할 만한 서버를 링에 확인하여 그쪽으로 라우팅한다.
객체가 객체 서버로 스트리밍되어 들어가거나 나올때 프록시 서버를 거쳐서 이동한다.
2) 링(The Ring)
링은 디스크에 저장된 엔터티 이름과 물리적 위치 간의 매핑을 나타낸다. 계정, 컨테이너 및 저장 정책당 하나의 객체 링이 각각 존재한다. 다른 구성 요소가 객체, 컨테이너 또는 계정에 대해 작업을 수행해야 할 때 적절한 링과 상호작용하여 클러스터 내의 위치를 결정한다.
링은 영역, 장치, 파티션 및 복제본을 사용하여 이 매핑을 유지한다. 기본적으로 각 파티션은 클러스터 내에서 3번 복제되며, 해당 파티션의 위치는 링에서 유지 관리되는 매핑에 저장된다. 링은 또한 장애 상황에서 대신 사용할 장치를 결정하는 역할을 한다.
각 파티션의 복제본은 가능한 한 많은 고유한 지역, 영역, 스토리지 노드 및 장치에 분산된다. 특정 계층 내에서 고장 도메인(서버, 디바이스 등)의 수가 부족하거나 용량이 균형을 이루지 못하면 복제본 간의 완전한 격리 및 균등한 용량 분배가 어려워질 수 있다. 이러한 경우, 링 관리 도구가 경고를 표시하여 운영자가 클러스터 토폴로지를 평가할 수 있도록 한다.
데이터는 클러스터 내 가용 용량에 균등하게 분배되며, 장치 가중치를 사용해 이 분배를 조정할 수 있다. 이는 예를 들어, 서로 다른 크기의 드라이브를 사용하는 경우 유용하다. 또한, 가중치를 조정하여 클러스터에 용량을 추가하거나 제거할 때, 복제 대역폭이 허용하는 한에서 파티션 재배치 횟수를 제어할 수 있다.
장치가 클러스터에 추가되는 경우와 같이 파티션을 이동해야 할 때, 링은 한 번에 이동하는 파티션 수를 최소화하며, 한 번에 하나의 파티션 복제본만 이동하도록 보장한다.
링은 프록시 서버 및 복제와 같은 여러 백그라운드 프로세스에서 사용된다.
3) 객체 서버
객체 서버는 로컬 장치에 저장된 객체를 저장, 검색 및 삭제할 수 있는 간단한 블롭(blob) 스토리지 서버이다. 객체는 파일 시스템에 바이너리 파일로 저장되며, 메타데이터는 파일의 확장 속성(xattrs)에 저장된다. 따라서 객체 서버에서 사용하는 파일 시스템은 파일의 xattrs를 지원해야 한다다. 예를 들어, ext3 파일 시스템은 기본적으로 xattrs가 비활성화되어 있다.
각 객체는 객체 이름의 해시와 작업의 타임스탬프를 기반으로 경로를 생성하여 저장된다. “마지막 쓰기” 원칙이 적용되어 최신 버전의 객체만 제공된다. 삭제 작업은 파일의 버전으로 간주되며, “.ts“(tombstone)로 끝나는 0바이트 파일로 저장된다. 이를 통해 삭제된 파일이 올바르게 복제되며, 장애 상황으로 인해 이전 버전이 갑자기 다시 나타나는 것을 방지한다.
4) 컨테이너 서버
컨테이너 서버의 주요 역할은 객체 목록을 처리하는 것이다. 컨테이너 서버는 해당 객체들이 어디에 있는지는 알지 못하며, 특정 컨테이너에 어떤 객체가 있는지만 알고 있다. 목록은 SQLite 데이터베이스 파일로 저장되며, 객체와 유사하게 클러스터 내에서 복제된다. 또한, 해당 컨테이너의 총 객체 수와 총 스토리지 사용량과 같은 통계도 추적한다.
5) 계정 서버
계정 서버는 컨테이너 서버와 매우 유사하지만, 객체 대신 컨테이너 목록을 처리한다는 점이 다르다.
6) 복제
기본적으로 Swift는 고가용성, 내결함성을 위하여 각 스토리지 노드를 복제해서 사용하길 권장한다. 각 스토리지 노드는 서로 데이터를 비교하여(아래 Auditors 참조) 무결성을 확인하며 문제 발견시 복구한다.
복제기는 이 과정에서 데이터가 시스템에서 제거되도록 보장한다. 계정이나, 컨테이너, 객체 같은 아이템이 삭제되면 묘비(tombstone)을 세팅해두는데 복제기는 이 묘비를 확인하고 전체 복제본에서 해당 아이템을 삭제할 수 잇게 보장한다.
7) 감사자(Auditors)
서버를 체크하여 객체와 컨테이너, 계정 정보의 무결성을 체크하고 문제가 발생된 걸 확인할 경우 해당 파일을 격리하고 다른 복제본에서 파일을 갖고와 대체한다. 만약 다른 문제를 감지할 경우에는 로깅한다.
※ 추가 업데이트 예정