SC21 - RIBBON 논문 분석
Ribbon Paper
1. 개요
슈퍼컴퓨터 21년도에 올라온 논문이다. 논문 풀네임은 “Ribbon: Cost-Effective and QoS-Aware Deep Learning Model Inference using a Diverse Pool of Cloud Computing Instances”이다. 직역하자면 “다양한 클라우드 컴퓨팅 인스턴스 풀을 활용한 비용 효율적이고 QoS를 생각하는 딥 러닝 모델 추론”이 되겠다.
딥러닝 모델을 제공하기 위해 적절한 인스턴스를 어떻게 지정할 것인가에 대한 논문 되겠다.
2. 딥러닝 모델 종류
이 논문에서는 대상 딥러닝 모델 종류를 아래와 같이 정의했다.

CANDLE
대규모의 완전 연결 딥러닝 모델로, 암 세포 예측에 사용된다.ResNet 마이크로 소프트에서 만든 합성곱 신경망으로 컴퓨터 비전에서 이미지 분류 및 개체 찾기 등에서 널리 사용된다.
VGG 합성곱 신경망으로 DLHUB에서 사용 가능하다. 이미지 인식 분야에서 많이 사용된다.
MT-WND Multi-Task Wide and Deep, 추천 모델. 여러 DNN 예측자를 병렬로 사용하여 클릭 처리율(CTR), 평점과 같은 여러 지표를 예측한다. YouTube 비디오 추천에 사용된다.
DIEN 알리바바에 의해서 만들어진 Deep Interest Evoluation Network이다. RNN의 변형인 GRU로 만들어졌으며 시계열 정보를 캡쳐하는데 사용한다. E 커머스에서 사용한다.
3. 대상 인스턴스
여기서는 AWS의 인스턴스들을 사용했다고 했다.
이는 다양한 Computing 인스턴스를 제공하기 때문이다.
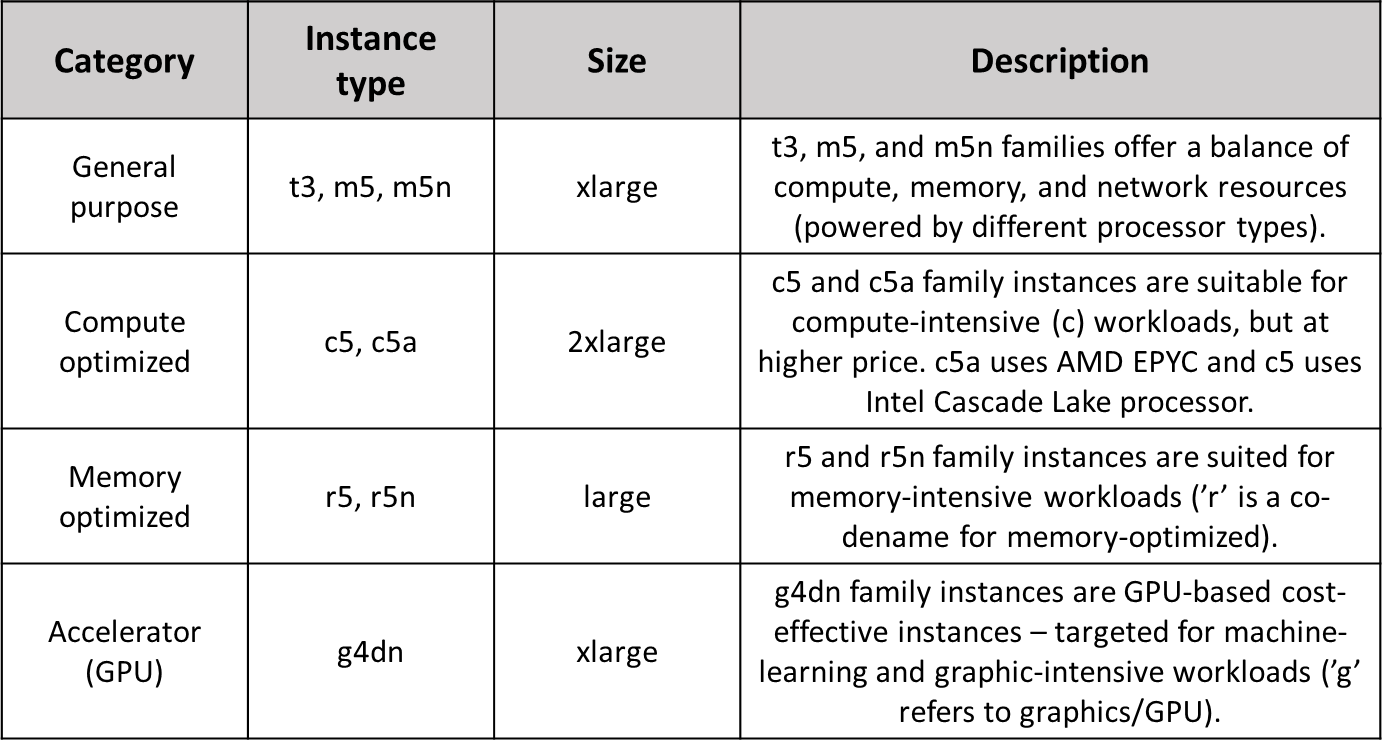
대략적인 설명은 아래와 같다.
t3, m5, m5n 은 cpu 성능과 메모리, 네트워크 대역폭등이 밸런스 있게 나눠진 인스턴스 타입으로 뒤에 n이 붙은건 인텔 Vector Neural Network Instructions를 지원하는 타입이다.
c5, c5a는 컴퓨트 성능 더 필요한 워크로드에 적합한 인스턴스 타입으로 a가 붙으면 amd cpu를 사용한다는 뜻이다.
r5, r5n은 메모리가 필요한 타입으로 다른 인스턴스에 비해 size가 올라갈 수록 메모리 할당량이 크게 늘어난다. 메모리 집약적 어플리케이션에 유용하기에 DB 같이 메모리를 많이 사용하는 워크로드에 적합하다.
g4dn은 GPU가 달린 인스턴스로 그래픽이나 머신러닝에 필요한 워크로드에 적합하다.
뭐 가격 차이가 얼마나 나길래 이렇게 다양하게 쓰는가 하겠지만 아래의 표를 보면 생각이 달라질 것이다.
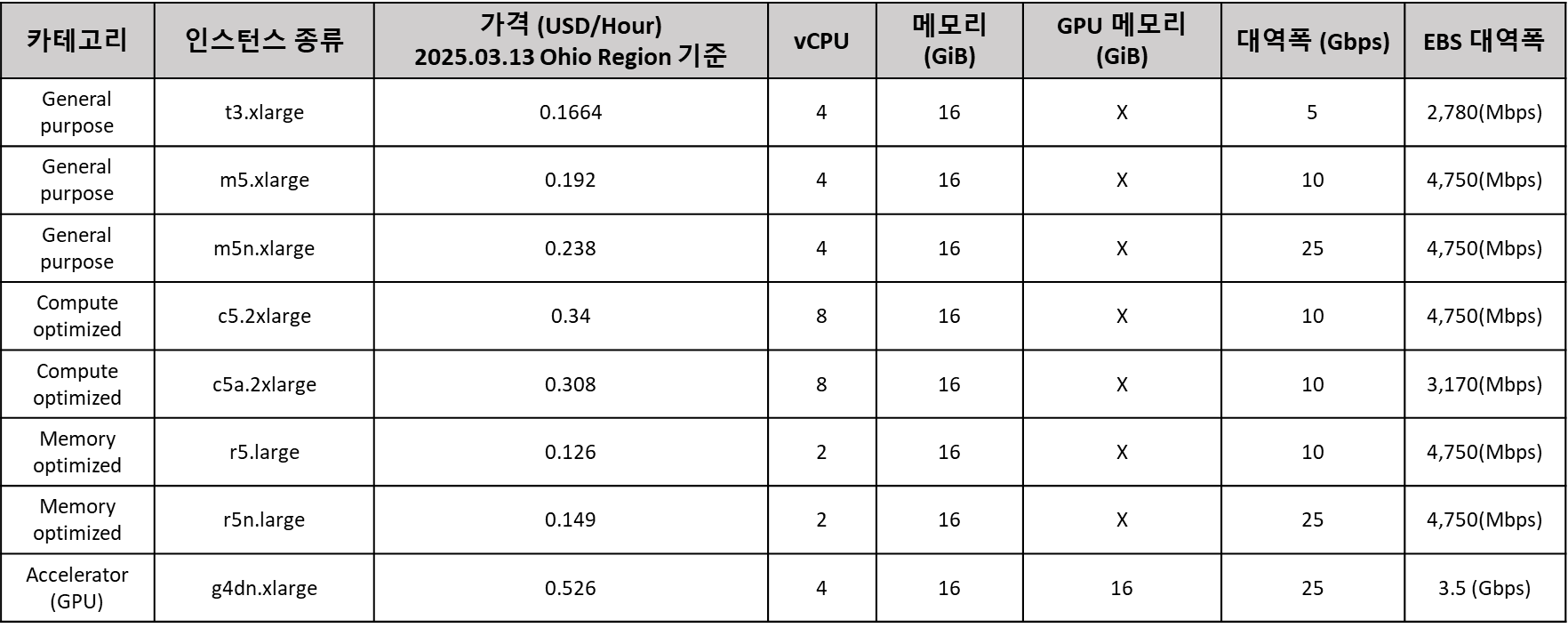
4. 각 모델의 인스턴스별 효율성
논문에서 갖고 온 아래의 그림을 보자.
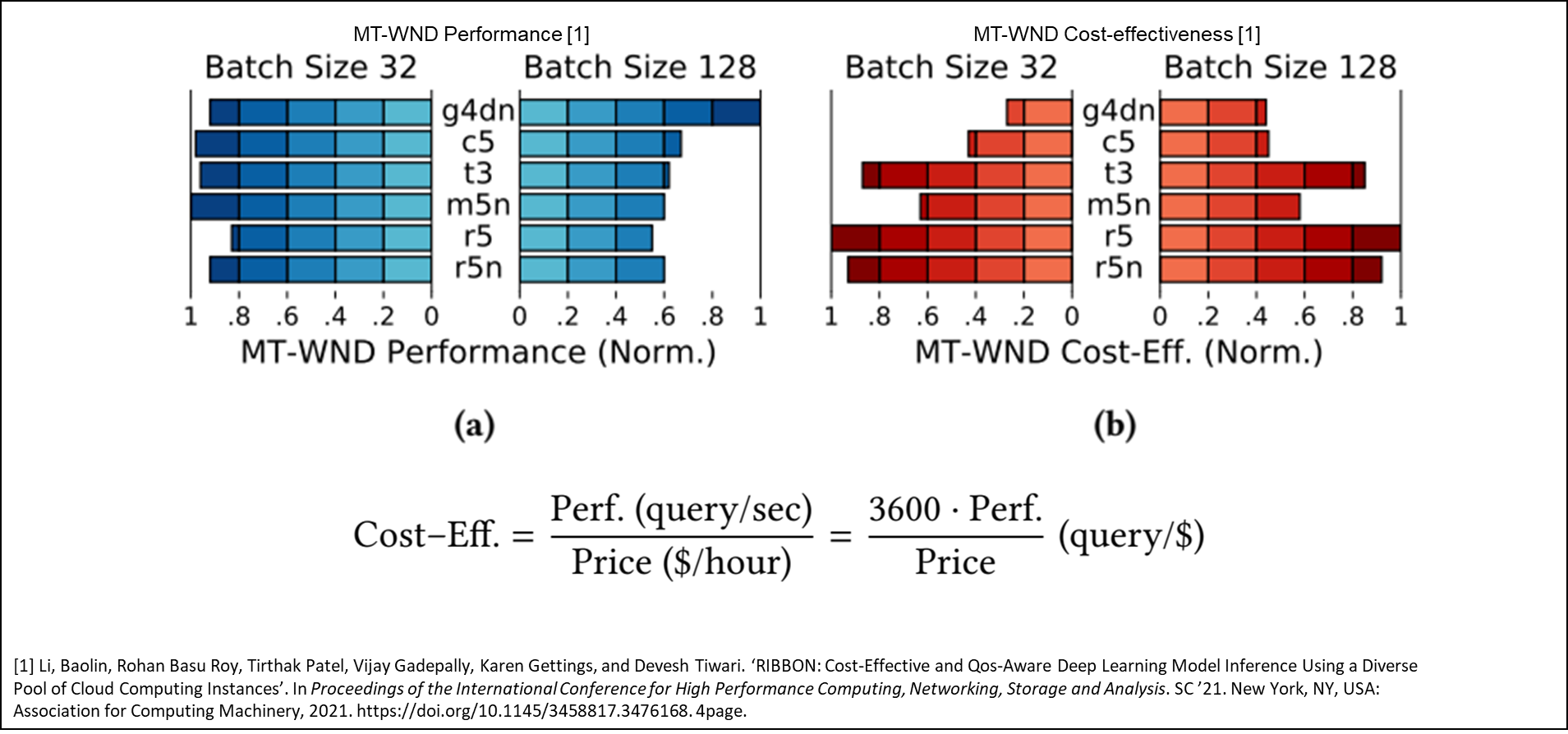
유튜브에서 우리를 유혹하는 알고리즘인 MT-WND를 기준으로 성능과 비용 효율성을 나타낸 그래프이다. 그래픽 카드가 들어간 g4dn계통 인스턴스는 성능이 좋지만, 비용이 높고, 다른건 대부분 성능은 낮지만, 비용이 낮다. 단, 그중에서 메모리 집약적 타입인 r계통에서는 가성비가 준수하게 나오는데, 이렇게 AI 모델별로 메모리 집약적이냐 컴퓨팅 집약적이냐 혹은 GPU 집약적이냐에 따라 각기 다른 최적의 해가 있는것이다. 문제는 이뿐만이 아니다.
5. QoS 만족
서비스라면 사용자의 요청에 대해서 특정 시간내에 응답을 해야하는 의무를 지닌다.
Quality of Service란 해당 서비스의 품질을 말하는 것인데, 여기서 QoS를 응답시간으로 지정했다.
아래의 그래프를 보자.
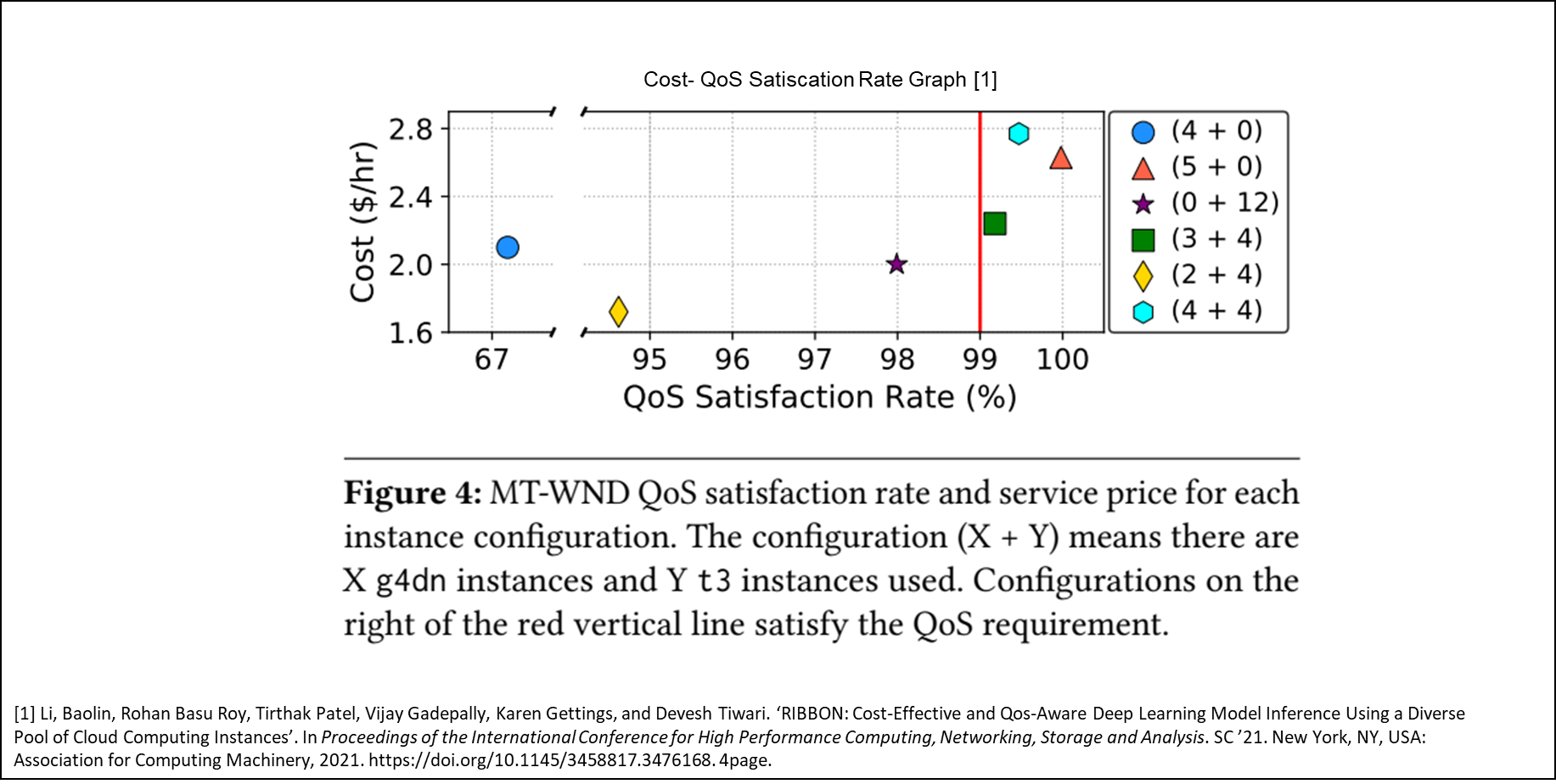
그림은 X+Y의 조합시 MT-WND 모델의 QoS를 만족하는 것에 대한 그래프이다. 여기서 앞의 숫자 X는 g4n 인스턴스의 개수, Y는 t3 인스턴스의 개수이다. g4dn는 t3에 비해 3배 정도 비싼데, 이를 조합해서 QoS를 만족하며 비용에 대한 최적이 가능한지를 가늠할 수 있다.
위 그래프를 보면 두 가지를 알 수 있다.
- 비용이 비슷한 구성도 QoS 만족도가 상당히 다를 수 있음
- 비용이 상당히 다른 구성도 QoS 만족도가 비슷할 수 있음
위 사실에 근거하여 논문에서는 최적의 조합을 찾는 법에 대해서 말한다.
6. 최적해 찾기
기본적으로 이 문제는 아래의 문제를 내포하고 있다.
- 검색 공간이 너무 크다
- 풀 구성과 QoS 만족도 간의 상호작용을 수학적으로 나타내기 어렵다
- 특정 배치 크기와 쿼리에 해당하는 사전 지식이 없음을 가정해야 한다
그래서 이 논문 저자들이 제안하는 방법은 바로 베이지안 최적화이다.
7. 베이지안 최적화를 기반으로 한 Ribbon의 솔루션
기본적으로 베이지안 최적화라는 것은 대리 모델과 Acquisition Function로 이루어진 최적화 방식이다.
사실상 이 대리모델을 학습시키는 방법이라고 보면 되며 어떤 값을 뽑아서 학습시킬지는 Acquisition Function이 정하는 것이다. 기본적으로 가우시안 모델을 대리모델로 사용하는데, 이 경우 연속값을 가지는 변수에 대해서 작동하게끔 되어있기에 이를 범주형 데이터를 사용할 수 있게끔 함수 내부에서 Round 값을 취해준다.
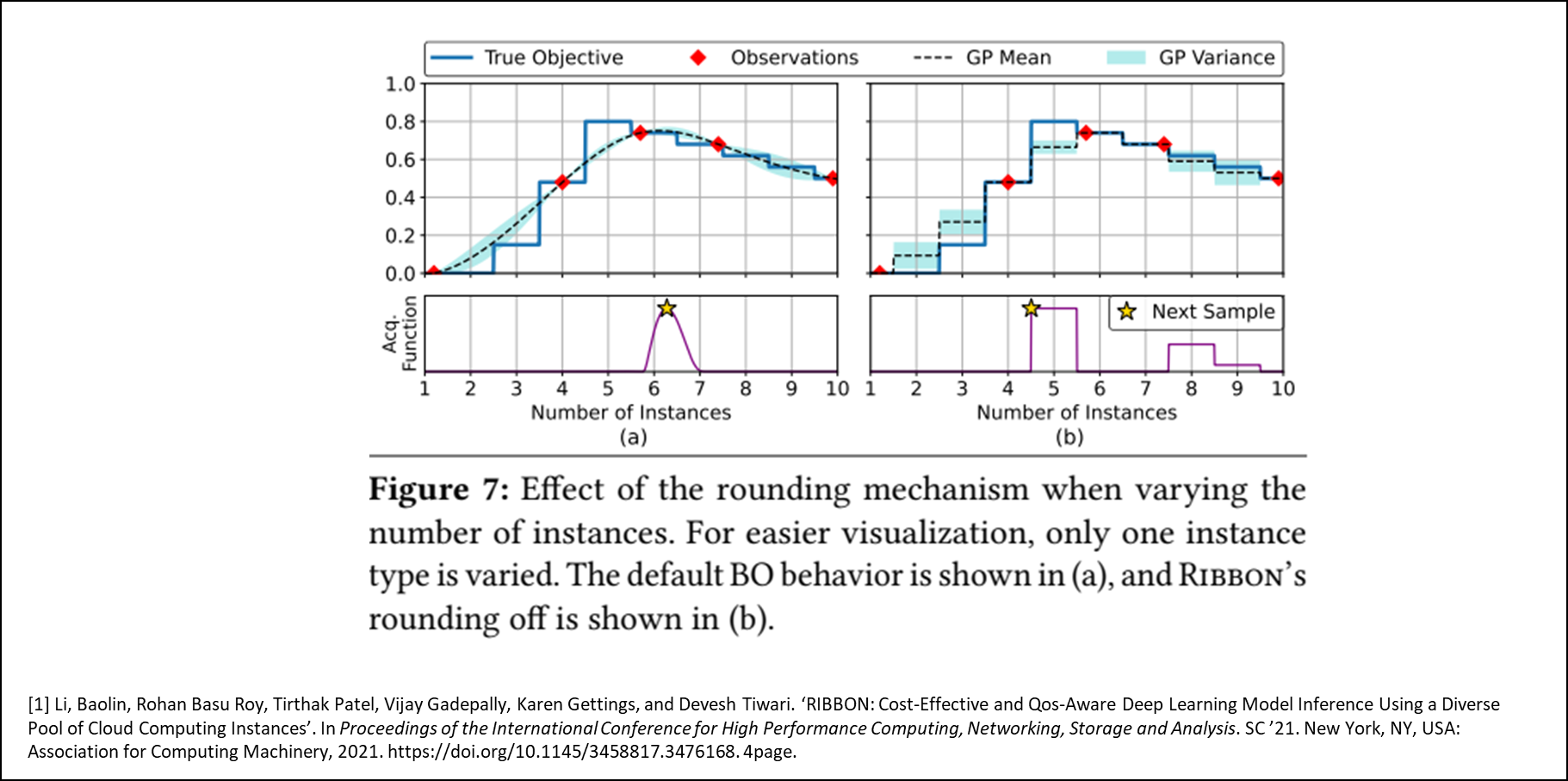
그렇다면 이제 중요한 어떻게 쿼리 Load를 체크할 것이냐 인데, 이는 간단하다.
쿼리 큐와 QoS 만족 수치를 주기적으로 모니터링하면 알 수 있다.
쿼리 큐가 지속적으로 늘어나면서 QoS 만족도가 떨어진다면 실질적으로 쿼리의 양이 늘어난 것이므로 인스턴스 확장이 필요한 시점이다.
이후 쿼리 양이 늘어난다면 탐색된 전체 기록을 가지고 인스턴스를 조정하게 되는데 이때 확장시에 이전 탐색 기록에서 이전 최적값과 같거나 낮은 QoS 구성은 가지치기 집합 S로 두고 가지치기 해버린다. 여기서 S값은 이후 선형적인 측정 값으로 예측에 사용된다. 가령 이전 최적 구성을 A라고 하고 S 집합의 다른 구성을 B라고 한다. A가 이전 부하에 대해 99.9%의 만족도를 가지고 있고 새 부하에 대해 33.3%의 만족도를 가지고 있고 B가 이전 부하에 대해 90%의 만족도를 가지고 있다면, B는 새 부하에 대해 30%의 만족도를 가진다고 추정하는 식이다.
8. 평가와 분석
배치 크기 분포는 Heavy-tail log-normal distribution을 따르게 했다고 하는데 이는 기존 연구에 따르면 실제 워크로드를 잘 반영한다고한다. 쿼리 도착 시간 분포는 포아송 분포를 따르며 QoS의 기준은 아래와 같다.
- 99번째 백 분위수를 기준
- MT-WND : 20ms
- Dien : 30ms
- CANDLE : 40ms
- ResNt50 : 400ms
- VGG19 : 800ms
그리고 각 모델별 인스턴스 풀은 아래와 같이 지정했다고 한다.
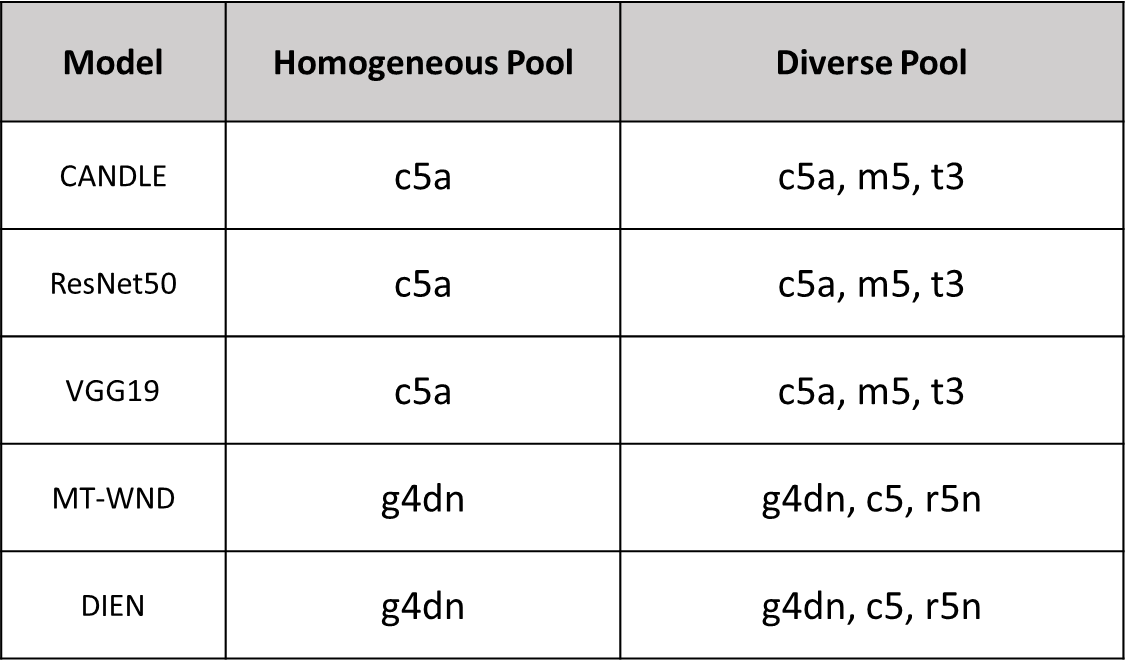
동종 풀과 이기종 풀 두가지로 지정되어있는데 이는 비교를 위해서라고 할 수 있다. 동종 구성과 이기종 구성의 비용차이는 아래의 그래프를 보면 알 수 있다.
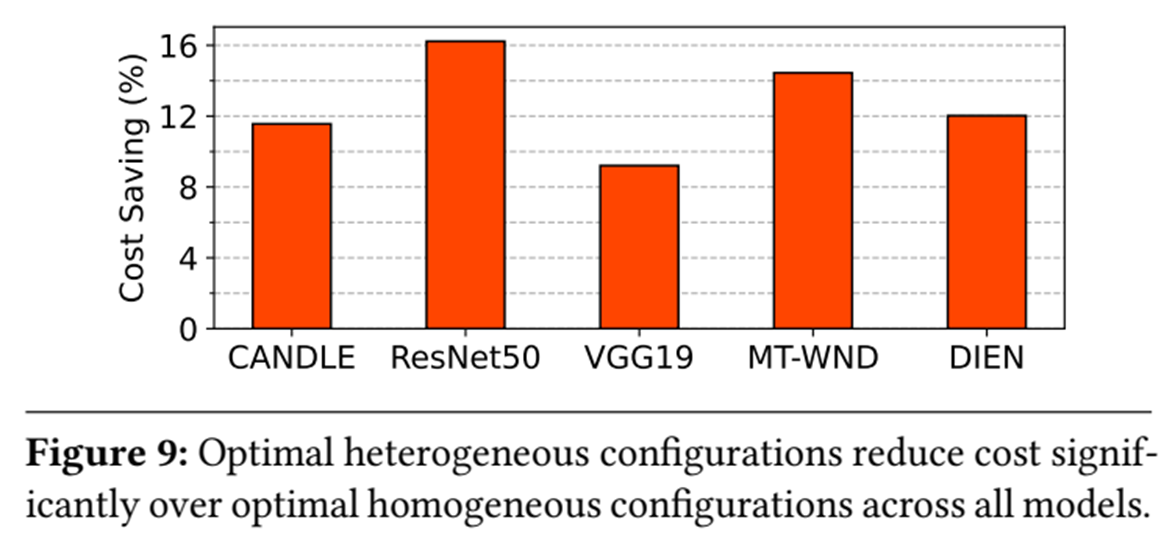
실질적으로 효과를 보였으며 VGG의 경우 9%, ResNet50에서는 16% 비용이 개선되었다고 한다.
쿼리가 다른 분포를 따르면 이 효과가 달라지는지 확인하기 위해 정규분포 형태로 쿼리를 사용해서 테스트한 결과도 있다.
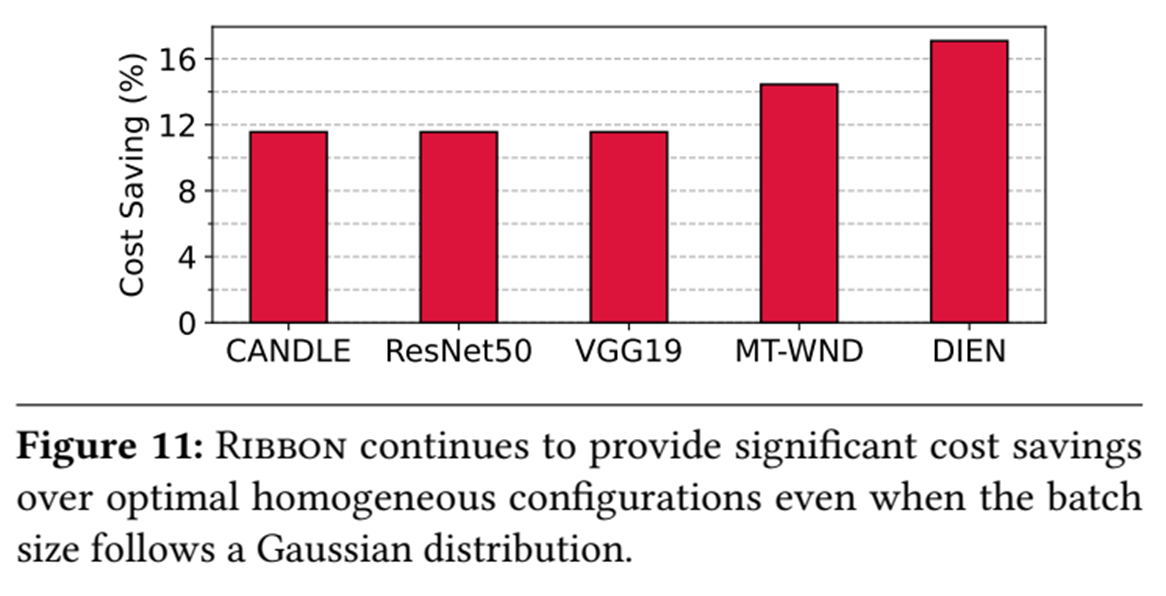
이 역시 효과적이며 쿼리의 분포 형태에 따라 큰 영향을 받지 않는 것을 알 수 있다.
아무래도 논문에 기재되려면 기존 것보다 낫다는 식의 평가가 편하고 알아보기 쉽다. 따라서 Ribbon에서는 세 가지 기존 방법 대비 Ribbon 솔루션이 낫다는 것을 제시한다. 이 세가지 솔루션은 아래와 같다.
Random
검색 공간에서 무작위 구성을 평가한다. 더 많은 인스턴스를 가진 이전 구성이 QoS를 만족 못할 경우, 더 적은 수의 인스턴스를 가진 이전 구성이 더 낮은 비용으로 QoS를 충족하는 경우 무작위 선택 구성을 평가하지 않음Hill Climbing
Hill Climbing 최적화 기법을 기반으로 한 탐색 방이다. QoS와 비용을 기반으로 인스턴스 개수를 동적으로 조정하도록 최적화되어있다.RSM
고정된 샘플 수 내에서 최적 구성을 찾기 위해 사용되는 고급 기법이다.
위 세가지 솔루션과 Ribbon을 같이 분석할 것이다. 아래는 목표 달성을 위한 샘플링 수에 대한 내용이다.
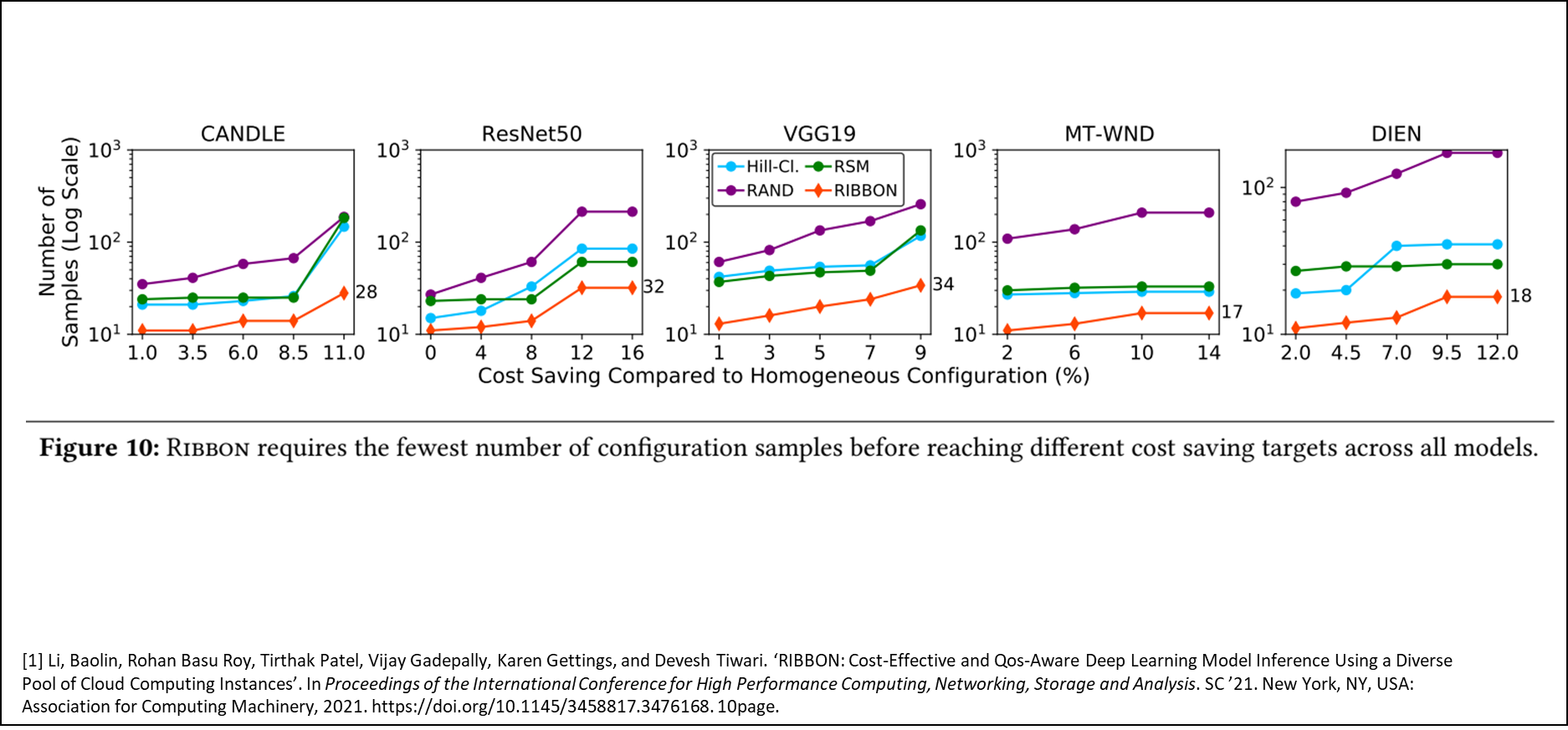
최대 비용 절감 효과 를 얻기 위해 Ribbon이 평가한 구성 개수의 경우
- CANDLE 모델: 약 40개 미만
- MT-WND 및 DIEN 모델: 20개 이하
따라서 다른 경쟁 기법 대비해서 CANDLE 모델에서는 다른 기법보다 10배 이상 적은 샘플 만 필요하고 ResNet50, VGG19, MT-WND, DIEN 모델에서도 2~3배 이상 적은 샘플 로 최적 구성 도달하는 것을 알 수 있다.
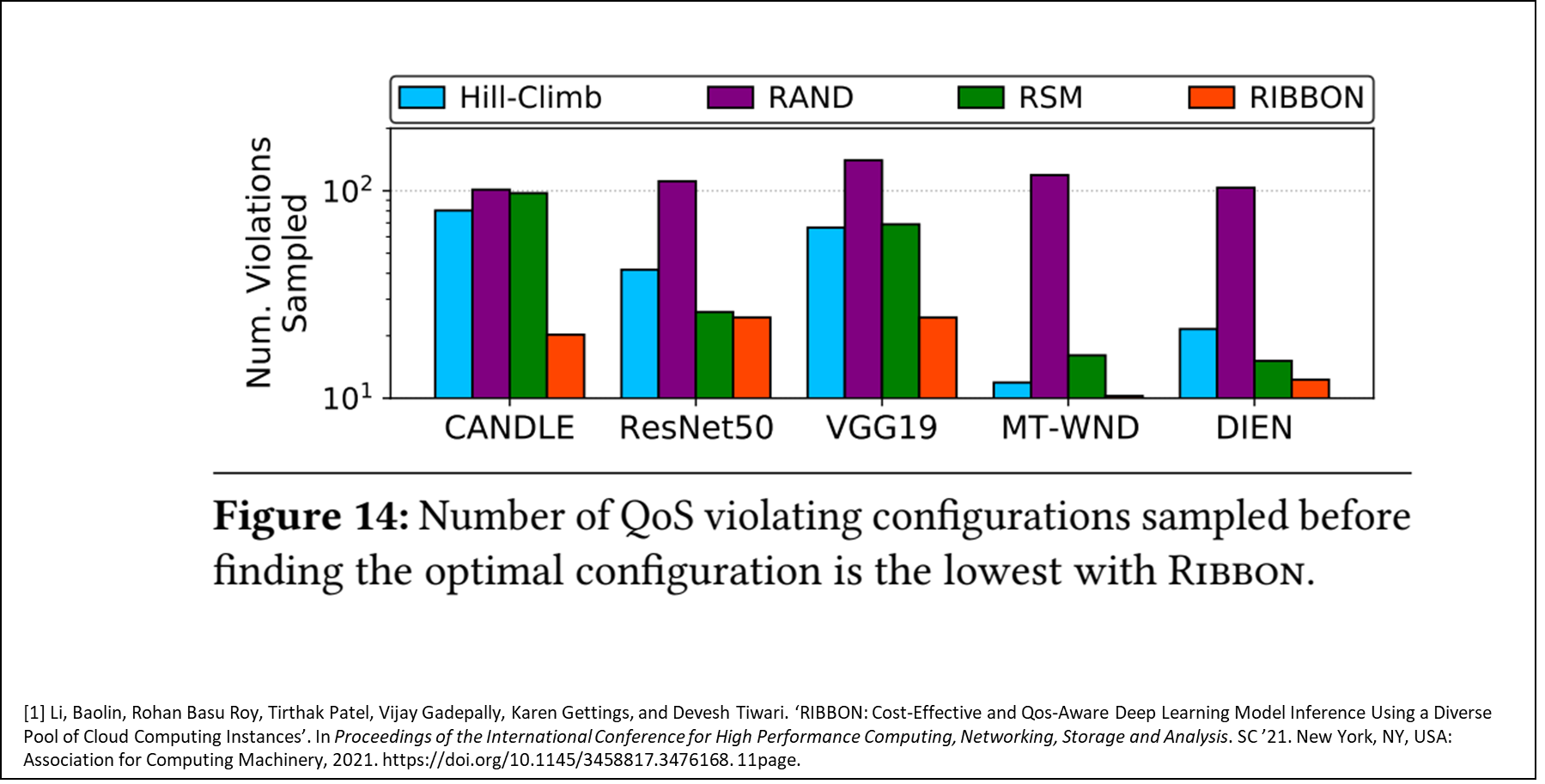
아래는 최적 구성 탐색전까지 QoS 위반 구성의 수이다.
이는 서비스 입장에서는 매우 중요한게, 잠깐 오버스펙으로 세팅되더라도 QoS를 유지하는게 서비스를 제공하는 입장에선 더 중요하다.
(괜히, 기업에서 안되면 돈 들여서 서버 증설하는게 아니다.)
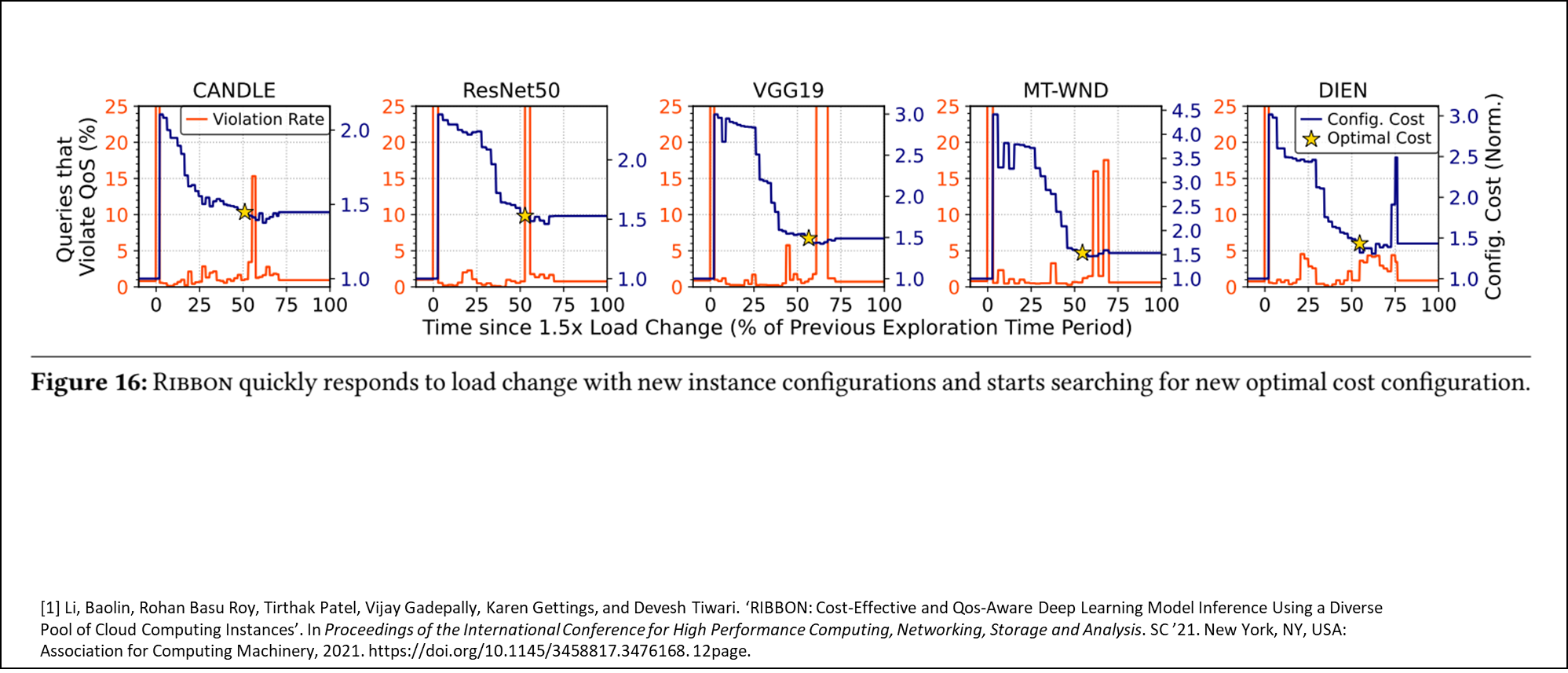
마지막으로 아래는 쿼리 증가 감지 후 최적구성까지 도달하는 시간에 대한 그래프이다.
이 그래프를 보면서 개인적으로 조금 분석하기 어렵다는 생각을 좀 했는데 해석해보면 아래와 같다.
X축 : 부하 증가전 최적 구성을 찾는데 걸린 시간을 100%로 환산(초기 구동후 최적 구성을 찾는 시간) Y축 : 좌측, 오렌지색 - 쿼리가 QoS를 위반하는 비율, 우측, 파란색 - 설정 비용
x축의 0%부터 부하증가가 발생하기 때문에 오랜지색 선이 튀는걸 발견 할수 있다. (QoS 위반 비율) 그러다가 파란색 곡선이 점점 내려오면서 오렌지색도 내려오는걸 볼 수 있는데, 설정 비용을 초기에 크게 잡고 내려오면서 QoS를 계속 유지하다가 QoS를 위반하는 지점에 도달하면 바로 직전 설정으로 롤백하는 것을 볼 수 있다. 기본적으로 초기 설정 시간대비 75% 이하로 시간이 드는걸 보면 변동성에 대응하는게 빠르다고 볼수도 있을 것 같다.
9. 개인적으로 생각하는 논문의 한계
일단 각 AI 모델을 어떻게 하이레벨 단에서 분할 해서 각 인스턴스에 돌린건지 알 수가 없다.
물론 참고 문헌에 쿼리를 분할해서 오프로딩하는 부분에 대한 연구(Deeprecsys, 아래 참고 문헌 참조)가 나와있다 아마 그 논문 방식대로 한게 아닌가 싶긴한데, 확실하지 않다.
실험간 인스턴스 조정 시간이 %로 나와있는데 사실 이 시간이 짧을 것 같지는 않다.
AWS를 운용해본바로는 Instance 올라오고 내려가는데 약 몇분의 시간이 소요되기 때문이다. 물론 그래도 조금 더 효율적으로 보인다는 점은 다르지 않긴 하다.
※ 추가 업데이트 및 퇴고 예정
참고문헌
- Li, Baolin, Rohan Basu, Roy, Tirthak, Patel, Vijay, Gadepally, Karen, Gettings, and Devesh, Tiwari. “RIBBON: cost-effective and qos-aware deep learning model inference using a diverse pool of cloud computing instances.” . In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. Association for Computing Machinery, 2021.
- 베이지안 최적화
- Udit Gupta, Samuel Hsia, Vikram Saraph, Xiaodong Wang, Brandon Reagen, Gu-Yeon Wei, Hsien-Hsin S Lee, David Brooks, and Carole-Jean Wu. Deeprecsys: A system for optimizing end-to-end at-scale neural recommendation inference. arXiv preprint arXiv:2001.02772, 2020.