VLDB26' - SVFusion, A CPU-GPU Co-Processing Architecture for Large-Scale Real-Time Vector Search 분석
SVFusion
이번에 리뷰해볼 논문은 VLDB 26’에 발표된 CPU와 GPU를 동시에 사용하는 실시간 Vector DB에 대해 발표된 SVFusion이다.
벡터 검색 연구를 하는 입장으로써 GPU까지 사용하는 논문이 우후죽순처럼 나오는 가운데, CPU와 GPU를 같이 사용해볼 방법이 없을까?하고 고민하고 있다가 교수님께서 권해주셔서 보게 된 논문이다.
1. 문제 정의 및 배경
딥러닝이나 LLM은 텍스트, 이미지, 오디오와 같은 비정형 데이터를 위한 고차원 벡터 임베딩의 광범위한 사용을 촉진하고 있다. 이렇게 고차원 벡터 임베딩의 수요가 늘어남으로써 공급 역시 늘게 되었는데, 이를 이용하기 위해서 임베딩 벡터 검색이 나왔다. 그리고 임베딩 벡터 검색은 추천, 웹 검색, LLM 기반 어플리케이션에서 매우 중요해졌다. 임베딩 벡터 검색은 Brute force로 하지 않으면 확실하게 가까운 이웃을 찾을 수 없다. 하지만 Brute force로 검색을 하면 너무 오래걸리기 때문에 ANNS를 많이 사용한다. 이는 유사 최근접 이웃을 찾는 것으로 SLO(Service Level Objective)를 맞추기 위해서 많이 사용하며 그 중에서 특히 그래프 방식은 IVF 방식보다 좀 더 재현율이 높기 때문에 많이 사용한다.
다만 이러한 기존의 임베딩 벡터 Indexing 방식은 실시간 성이 매우 좋지 않다.
때문에 이러한 문제를 해결하기 위한 노력들이 나왔다. FreshDiskANN과 같은 것들은 실시간 ANNS를 지원했기 때문이다. 하지만 위와 같은 방식들은 CPU만 사용하는 방식이었다. GPU는 병렬 작업으로는 CPU와 비교도 못할만큼 최적화된 프로세서이기때문에 이 병렬성을 살릴 방법을 찾기 위해 많은 사람들이 노력했고, 실제로도 CPU와는 비교도 안될만큼 높은 처리량을 달성할 수 있었으나 문제는 이 GPU가 지원하는 방식은 정적 인덱싱에 한정되어있었다.
때문에 논문의 저자들은 GPU와 CPU를 모두 활용하는 것은 매우 당연한 접근 방식이라고 말하며 대규모 스트리밍 상황에서 벡터검색을 구현하기 위해 아래의 두 가지 과제를 해결해야한다고 말했다.
- 과제 1. GPU 용량 제약 : GPU로 데이터를 보내는데 GPU RAM 용량이 상대적으로 CPU RAM에 비해 작고 이 때문에 빈번한 전송이 이어진다. 이 전송 오버헤드가 커서 전체적인 지연시간이 증가하게된다.
- 과제 2. 빈번한 벡터 업데이트하에서의 성능 저하 : 동기식 삭제 마킹이나 주기적 재 구축은 지연시간 스파이크를 유발하고 응답성을 저해시킨다.
과제 1을 해결하기 위해 데이터 압축이나 양자화를 한다면 결국에는 전체의 Index를 다시 빌드하는 것과 다를바 없으므로 사용할 수 없다고 말하며 과제 2개를 모두 해결하는 하이브리드 해결 방식인 SVFusion을 제시했다.
2. SVFusion 및 구현 방식
1) SANNS를 위한 GPU-CPU-디스크 협업 프레임 워크 SVFusion
여기서 말하는 SANNS, Streaming ANNS를 말하는 것으로 스트리밍 환경에서는 ANNS를 말한다. SVFusion은 SANNS를 제공하기 위해 아래와 같은 구현이 필요했다고 말한다.
- 데이터셋 크기가 증가함에 따라 메모리 계층 간의 원활한 전환을 가능하게하는 계층적 그래프 기반 벡터 인덱스
- 데이터 상주 및 캐싱을 동적으로 관리하는 워크로드 인식 벡터 배치 전략
- 실시간 업데이트를 위한 동시성 제어
2) 실질적으로 SVFusion이 제공하는 기능
a. build
CAGRA에서 영감받은 GPU 병렬 전략으로 서브그래프를 GPU에서 빌드 후 CPU에서 통합하는 방식이다.
b. 검색
GPU에서 그래프 순회, GPU 메모리에 캐시되어있으면 GPU에서 하고, 아니면 CPU에서 보내거나 혹은 CPU에서 적응적으로 거리 계산
이때 GPU에 적재될 임베딩 벡터는 아래의 수식을 따른다. \(gain(x) = \lambda_{x} \cdot (T_{CPU}-T_{GPU}) - T_{transfer}\)
여기서 $\lambda_{x}$ 는 미래 엑세스 값을 말하며 $T_{CPU}$는 평균 CPU 계산시간, $T_{GPU}$는 평균 GPU 계산시간 $T_{transfer}$ 는 HOST RAM에서 GPU RAM으로 데이터 이동시 걸리는 시간을 말한다.
$\lambda_{x}$ 값은 알 수가 없기 때문에 아래의 추정 함수를 사용한다. \(\lambda_{x}=\lambda_{1}\cdot F_{reccent}(x,t)+\lambda_{2}\cdot \log(1+E_{in}(x))+\lambda_{3}\)
각각 항목에 대한 값은 아래와 같다.
- $F_{recent}$는 시간적 지역성 (최근 접근한거)
- $E_{in}(x)$는 내부 이웃 차수가 높은 값
- $\lambda_{1}$ 은 시간적 지역성의 가중치
- $\lambda_{2}$ 은 내부 차수에 대한 가중치
- $\lambda_{3}$ 는 편향
파라미터 중 $\lambda_{1}$ 과 $\lambda_{2}$ 는 비율은 고정하되 성능평가를 기반으로 값을 조절했다고 밝혔다.
※ 위 수식에 대한 당위성 증명
Vector Dataset workload를 분석해본 결과 시간적 지역성과 Edge가 많이 연결된 Node의 경우 사용률이 높았다고 밝혔다.
이 내용이 위 수식을 합리적인 것이라고 증명한다고 했다.
그래프는 아래를 참조하라.
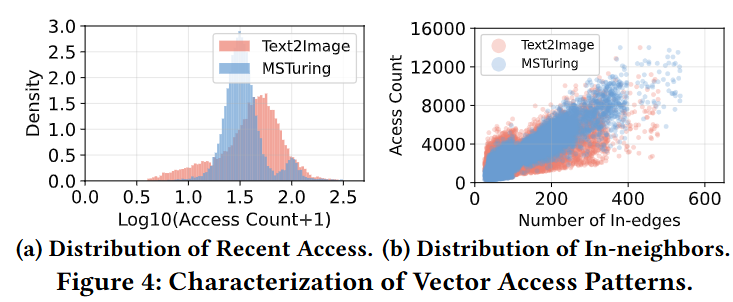
c. 삽입
GPU 기반 검색을 거쳐서 후보이웃을 식별한 뒤에 해당 후보들을 CPU로 보낸다. 후보 선택 시 이웃 목록 있는 각 후보에 대해서 이 후보를 포함하는 이전에 선택된 이웃이 몇개인지 계산한다. 이는 우회가능한 경로를 나타내며, 이 경로 수에 따라 오름차순 정렬 후 선택한다.
d. 삭제
경량 삭제 매커니즘 채택하여 즉각적인 구조 변경 없이 해당 벡터에 삭제 표시하고 당장은 넘어가는 지연 삭제를 제공한다. 이렇게 지우기 처리해두고 일정 임계(50%)가 넘은 점만 국소적으로 복구하게 되는데, 이 국소 복구란 삭제된 점이 연결하고 있던 이웃들을 근처 다른 점과 잇는 것이다. 하지만 이렇게 삭제가 쌓일 경우 그래프의 품질이 나빠지게 되는데 이를 방지하기 위해
삭제 비율이 미리 정의된 임계갑을 초과하면 삭제된 정점의 나가는 이웃으로부터 후보를 집계하여 모든 영향을 받은 이웃에 대해 전역 통합 수행한다. 이때는 멀티 버전 운용으로 인해 복사본에 대해 백그라운드에서 실행되기 때문에 삽입 및 쿼리 중단이 없다.
3) 기능 제공을 위한 세부 로직
a. SANNS를 위한 조정
- 검색은 다중 스트림 및 한 개의 쿼리를 다수의 스레드로 구동하는 멀티 CTA로 구동
- 검색 스트림 6개와 업데이트 전용 스트림
b. 적응형 리소스 관리
- gpu 메모리를 독립적인 세그먼트로 분할 하고 경량 스핀락으로 보호하며, 벡터는 식별자 해싱을 통해 세그먼트에 매핑됨
c. 콜드 스타트 관리
- GPU 전역 메모리에 벡터 스토리지를 사전 할당 및 CUDA 스트림 생성
- 캐시관리자의 매핑 테이블 준비 및 접근 추적 메타데이터 시작
- GPU 캐시 워밍업은 예측된 접근 횟수를 기반으로 벡터를 사전 로드하되 상위 순위의 높은 차수 벡터를 캐싱
d. 동시성 제어
2단계 동시성 제어 프로토콜을 사용한다.
- 로컬 동기화
- fine-grained locking
- 각 계층에서 검색시 read lock으로 탐색
- 삽입시 후보 탐색은 read lock으로 시작, 바꿀때만 write lock으로 탐색
- 계층간 조정
- 토폴로지 변경은 cpu에서 write로 커밋
- GPU 관련 엔트리는 비동기로 배치 전송
- 전파 전에 GPU Conflict 시 CPU 버전으로 fallback하기
- fine-grained locking
- 다중 버전 매커니즘 : 스냅샷을 이용해서 직렬 연산으로부터 분리하여 논 블로킹 가능
e. 적응형 배치 크기 지원
지연시간 SLO을 맞추기 위해 적응형으로 배치 크기를 변경한다.
4. 평가 및 분석
1) 실험 환경
a.하드웨어
dual-socket 서버(두 Intel Xeon Gold 5218)
DRAM $376\,$GB
GPU는 NVIDIA A100 with $40\,$GB HBM(PCIe 3.0)
로컬 SSD(Intel D3-S4510)
b. 운영체제
Ubuntu 18.04.6 LTS
2) 사용 데이터 셋
- Wikipedia: $35$M vectors, $D{=}768$.
- MSMARCO: $101$M vectors, $D{=}768$.
- MSTuring: $200$M vectors, $D{=}100$.
- Deep1B: $1$B vectors, $D{=}96$.
- Text2Image: $100$M vectors, $D{=}200$.
3) 워크로드
스트리밍 시나리오를 모사하는 아래의 네/다섯 유형
SlidingWindow, ExpirationTime, Clustered, MSTuring-IH 등. 각 워크로드는 삽입/삭제/검색 비율과 공간적·시간적 분포가 다름.
4) 전체 성능
a. 지연시간
QPS를 낮음(500)→중간(2000)→높음(10000)으로 확장한 실험 저부하에서는 p99가 약 몇 ms 수준(예: 전체적으로 < 10ms), 동기화 비용 때문에 약간의 오버헤드가 있었음. 중간 부하에서는 p50 ≈ 4.3ms, p99 ≈ 7.9ms(논문 지표). 고부하에서는 baselines의 p99가 > 900ms로 폭등한 반면 SVFusion은 검색 p99 ≈ 16.5ms, 삽입 p99 ≈ 45.3ms로 견고하게 유지되었다.
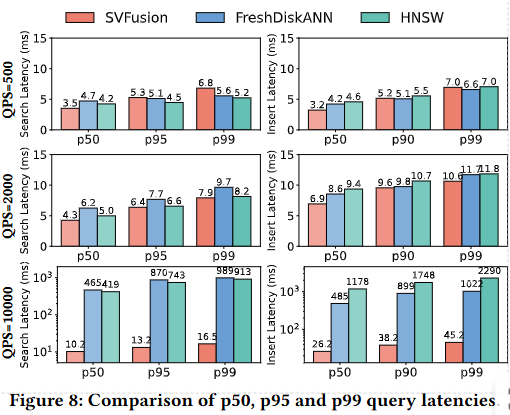
b. WAVP(Workload-Aware Vector Placement) 및 캐시 전략 효과
- 비교 대상 : SVFusion w/o WAVP, LRU, LFU, LRFU
- 결과 : WAVP 탑재시 최대 7.2배 개선 및 Latency 최대 5.1배 감소(특정 워크로드에 한해서)
- 메모리 비율(가용 GPU 메모리 비율)을 20%에서 100%로 변화시켜도 WAVP가 우수함
c. 디스크 확장(대규모 데이터, Deep1B) 결과
- 인덱스 구성 시간이 DiskANN 대비 5.26 배 빨라짐 (GPU 서브그래프 빌드 단계에서 약 9.1배 가속)
- Recall-Throughput-Delay 관점에서 SVFusion은 높은 recall 구간에서 DiskANN 대비 처리량은 2.3배 높았고 Letancy는 0.7~1.6% 저하가 관찰됨
d. 삭제·수복 전략 평가
- 실험 대상 : Lazy deletion만, Lazy + global consolidation, 논문 제안(논리적 삭제 + localized lightweight repair + 주기적 global consolidation).
- 결과 : 제안 방식이 recall에서 2.3% ~ 5.2% 개선을 보였고, global consolidation 대비 오버헤드가 57.6% 절감됨. 실시간 삭제 출적에 따른 그래프 단편화 문제에 더 탄력적인 것으로 판별됨
e. 비용 분해 및 확장성
- 삽입 성능 분해: 데이터 전송(약 $45.4\%$), 거리 계산(약 $33.6\%$), 후보 재정렬(약 $10.3\%$), reverse-add(약 $10.6\%$). 즉 데이터 이동 비용이 지배적.
- CPU 스레드 수 실험: 스레드 증가에 따른 처리량 향상은 $16$ 스레드까지 효과적, 그 이후로 수익 감소(락·동기화 오버헤드 영향).
- GPU-기반 비교: CAGRA·GGNN 등 GPU 전용 기법은 데이터 전체가 GPU에 올라가지 않으면 전송 병목으로 SVFusion에 비해 성능 저하가 큼. SVFusion은 CPU-GPU 공동처리로 대규모 스케일에서도 우수.
f. 일관성(Consistency) 보장 실험
- 스트레스 테스트(50% insert + 50% search; 배치 크기 10; QPS $500$→$10000$)에서
- 동기화(프로토콜 활성) 시 Recall@1이 안정적으로 $0.96$ 유지.
- 동기화 비활성화 시 Recall@1이 QPS 증가에 따라 $0.96 \rightarrow 0.18$까지 급감.
- 결론: fine-grained locking + 버전 기반 비동기 GPU 전파 + CPU 폴백 조합이 읽기-갱신 일관성(read-after-write)을 실용적으로 보장함. 다만 동기화는 p99를 증가시키는 비용(예: 최고 부하에서 p99 $4.8\,$ms → $33.2\,$ms)과 연관됨.
g. 파라미터 민감도
- 예측 함수 가중치: $F_\lambda(x) = \alpha F_{recent} + \beta \log(1+E_{in})$에서 $\frac{\alpha}{\alpha+\beta}$를 변화시킨 결과, 최근 접근($F_{recent}$)에 다소 높은 가중치(약 $0.6$ 비율)가 최적 miss-rate를 만들었다.
- 배치 크기 영향: 배치를 키우면 throughput은 증가하지만 recall 저하(그래프 업데이트 지연)와 latency 폭증(극단적으론 $>$ $1\,$s) 발생. 따라서 배치 크기 조절은 명확한 trade-off.
※ 추가 업데이트 및 검증 예정이다.
참고문헌
- Yuchen Peng, , Dingyu Yang, Zhongle Xie, Ji Sun, Lidan Shou, Ke Chen, and Gang Chen. “SVFusion: A CPU-GPU Co-Processing Architecture for Large-Scale Real-Time Vector Search.” (2026).
- Hiroyuki Ootomo, , Akira Naruse, Corey Nolet, Ray Wang, Tamas Feher, and Yong Wang. “CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs.” (2024).