기계학습 - Deep learning - 과적합 방지와 기울기 소실, 폭주
Deep learning
1. 과적합
1) 개요
이전에 역전파 과정에서 비용함수로 산출된 오류값에 근거하여 학습률을 곱하여 각 퍼셉트론의 가중치와 편향을 조정하는 것을 보였는데 특정 데이터가 다른 데이터와 동떨어져있다고 가정해보자. 그러면 해당 데이터가 보이는 양상과는 달리 기울기와 편향이 다르게 조정될 수 있다.
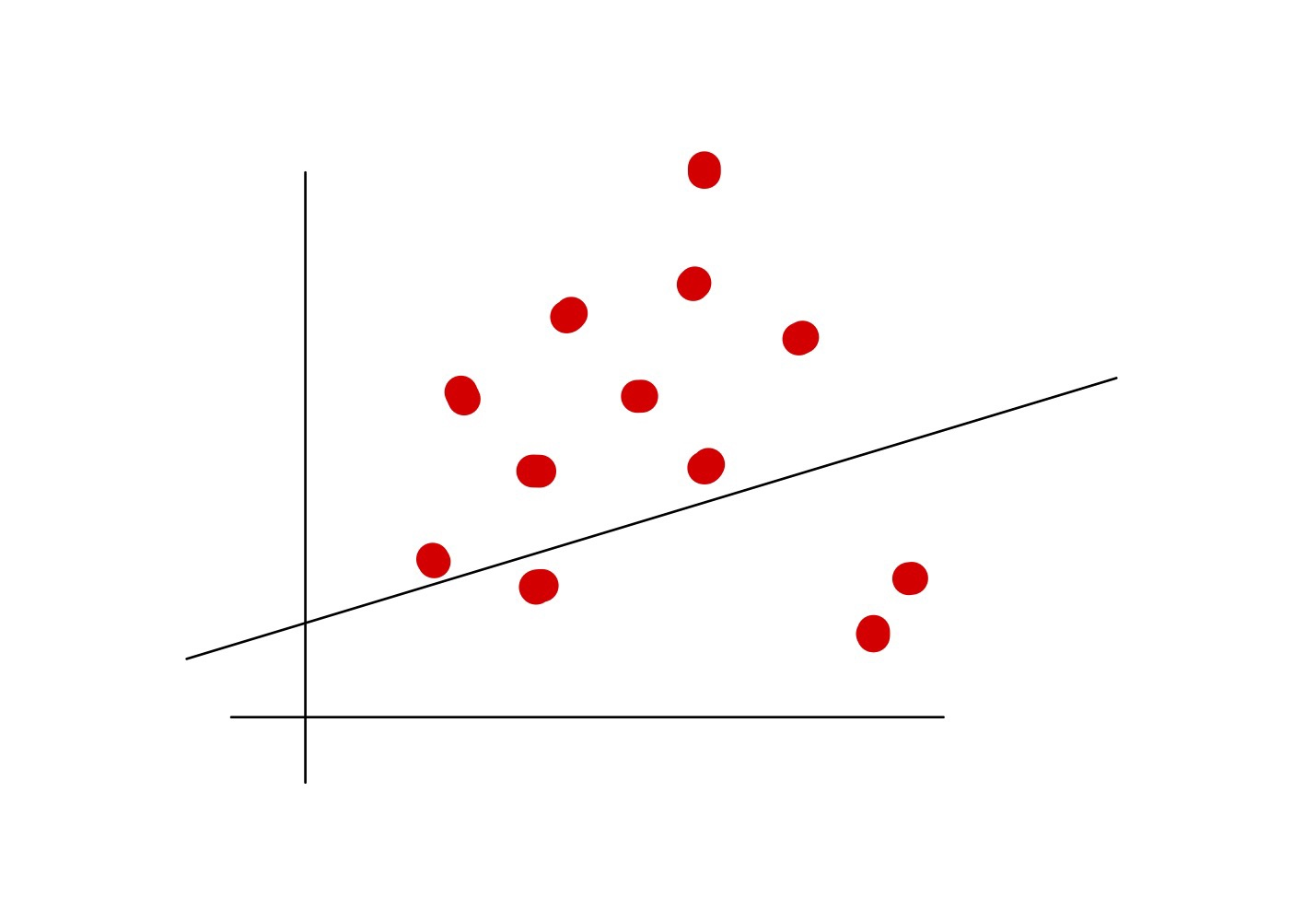
위와 같이 우리가 원하는 형태의 기울기와 편향이 잡히지 않는다면 해당 데이터는 우리가 원하는 형태의 예측값을 내놓지 않는다. 이런 경우를 과적합이라고 한다. 한마디 딥러닝 모델을 학습하는 과정에서 원래 학습되야할 데이터만 학습될게 아니라 혼자 동떨어진 데이터까지 모두 학습되어 모델 전체의 성능이 떨어진 상태를 말한다.
2) 해결법
과적합을 해결하는 방법은 여러가지가 있다.
a. 데이터 양을 늘린다.
모델 학습시 데이터의 양이 적을 경우 각 데이터에 대해서 더 크게 반영이 되므로 과적합이 일어날 가능성이 높아진다. 때문에 데이터 양을 늘릴 수록 동떨어진 데이터, 즉 노이즈에 대한 반영도가 떨어져 전체 패턴에 대해 학습할 수 있게 되므로
데이터 양이 많을 수록 과적합을 방지 할 수 있다.
하지만 모델 학습시 항상 많은 양의 데이터를 구할 수는 없는데, 이를 위해서 기존 데이터를 변경하거나 추가하여 데이터양을 늘리는 방식을 사용한다 이를 데이터 증식 혹은 증강(Data Augmentation)이라고 한다. 이미지는 이미지를 회전시키거나 별도의 필터를 통해 노이즈를 추가하거나 일부 그림을 변경하는 등으로 데이터를 증식 시키며 텍스트의 경우 변역 후 재번역하는 역번역(Back Traslation) 등의 방법을 사용한다.
b. 모델의 복잡도를 줄인다.
인공 신경망 모델의 복잡도는 은닉층(hidden layer)의 수나 매개변수의 수 등으로 결정 된다. 은닉층의 수와 매개변수의 수에 따라 복잡도는 증가하고 복잡도가 높을 수록 과적합이 잘 일어날 수 있다. 따라서 과적합이 일어났을 때 은닉층의 수를 조정하거나 매개 변수의 수(모델의 수용력(capacity)이라고도 한다)를 줄여 복잡도를 줄이는 것으로 조치를 할 수도 있다.
c. 가중치 규제를 적용한다.
은닉층의 개수나 매개변수의 개수는 유지하되 복잡한 모델을 좀 더 간단하게 하는 방법으로 가중치 규제(Regularization)가 있다.
L1 규제(L1 노름) : 가중치 w들의 절대값 합계를 비용 함수에 추가한다.
\(\lambda \left | w \right |\)L2 규제(L2 노름, 가중치 감쇠) : 모든 가중치 w들의 제곱합을 비용 함수에 추가한다.
\(\frac{1}{2}\lambda w^{2}\)
여기서 $\lambda$ 는 규제의 강도를 정하는 하이퍼파라미터이다. $\lambda$ 가 크다면 모델이 훈련 데이터에 대해서 적합한 매개 변수를 찾는 것보다 규제를 위해 추가된 항들을 작게 유지하는 것을 우선한다는 의미이다.
d. 드롭아웃 (Drop out)
드롭아웃은 학습 과정에서 신경망의 일부를 사용하지 않는 방법으로 학습시 일부 뉴런을 사용하지 않는 것을 뜻한다.
이런 드롭아웃은 학습시에만 사용하고 추론(Inference) 시에는 사용하지 않는게 일반적이다.
드롭아웃을 이용하면 특정 뉴런이나 특정 조합에 의존적이게 되는 것을 방지해주기 때문에 과적합을 방지할 수 있게 된다.
2. 기울기 소실과 폭주
1) 개요
깊은 인공 신경망 모델에서 출력층에서 입력층으로 역전파를 통해 학습과정에서 기울기(Gradient)가 점차 작아지는 현상이 발생할 수 있다. 이는 출력층에 가까운 층들은 업데이트가 잘 되는 반면 입력층에 가까운 층들이 업데이트가 제대로 되지 않는 것인데, 이를 두고 기울기 소실(Gradient Vanishing) 이라고 한다. 이와 반대로 기울기가 너무 커져서 비정상적으로 큰 값이 되버려 발산해버리는 경우도 있다. 이를 기울기 폭주(Gradient Exploding)이라고 한다.
2) 해결법
a. 활성화 함수 변경
활성화 함수를 시그모이드 함수나 하이퍼볼릭탄젠트 함수로 사용한다면 입력의 절대값이 클 경우에 기울기가 0에 가까워진다.
따라서 기울기 소실 문제가 발생하기 쉬워진다.
그래서 은닉층의 경우에는 ReLU나 leaky ReLU와 같은 변형 함수를 쓰면 기울기가 0에 가까워지는 것이 방지되어 어느정도 해결된다.
b. 그래디언트 클리핑(Gradient Clipping)
그래디언트 클리핑은 말 그대로 기울기 값을 자르는 것을 말한다. 임계값을 넘지 않도록 값을 자르는 것으로 기울기 폭주를 막을 수 있다.
c. 가중치 초기화(Weight initialization)
같은 모델이라고 하더라도 초기 가중치가 어떠냐에 따라 모델의 훈련 결과가 달라지기도 한다.
따라서 가중치 초기화를 적절해 해주면 기울기 소실 문제를 완화시킬수있다.
- 세이비어 초기화(Xavier Initialization)
2010년에 나온 세이비어 글로럿과 요슈아 벤지오가 쓴 논문에서 나온 방식으로 세이비어 초기화 혹은 글로럿 초기화라고 한다. 이 방법은 총 두 가지 초기화 경우를 나누는데 균등 분포(Uniform Distribution) 또는 정규 분포(Normal distribution)로 초기화할 때 두 가지 경우로 나뉜다.
균등 분포
$ n_{in} $ 이 이전 층의 뉴런의 개수 뜻하고, $ n_{out} $ 이 다음 층의 뉴런 개수라고하면 아래 범위에서 가중치를 사용하라고 한다.
\(W \sim Uniform( -\sqrt{\frac{6}{n_{in}+n_{out}}}, +\sqrt{\frac{6}{n_{in}+n_{out}}})\)정규 분포
정규분포의 경우 평균이 0이고, 표준편차 $ \sigma $ 가 다음을 만족도록 한다.
\(\sigma = \sqrt{\frac{2}{n_{in} + n_{out}}}\)
- He 초기화(He initialization)
위의 세이비어 초기화는 시그모이드 함수나 하이퍼볼릭 탄젠츠 함수와 S자 함수는 성능이 좋지만, ReLU와 사용할 경우 성능이 별로인데, 이때 사용하면 좋은 방식이 He 초기화이다.
He 초기화 역시 균등 분포와 정규 분포 두 가지로 나뉜다.
균등 분포
$ n_{in} $ 이 이전 층의 뉴런의 개수 뜻하고, $ n_{out} $ 이 다음 층의 뉴런 개수라고하면 아래 범위에서 가중치를 사용하라고 한다.
\(W \sim Uniform( -\sqrt{\frac{6}{n_{in}}}, \sqrt{\frac{6}{n_{in}}})\)정규 분포
정규분포의 경우 평균이 0이고, 표준편차 $ \sigma $ 가 다음을 만족도록 한다.
\(\sigma = \sqrt{\frac{2}{n_{in}}}\)
d. 배치 정규화(Batch Normalization)
배치 정규화는 인공 신경망의 각 층에 들어가는 입력을 평균과 분산으로 정규화하여 학습을 효율적으로 만드는 방법이다.
이 방식에 앞서 내부 공변량 변화(Internal Covariate Shift)에 대해 알아야하는데, 내부 공변량 변화란 층 별로 입력 데이터 분포가 달라지는 현상을 말한다. 배치 정규화를 주장한 이는 이 내부 공변량의 변화로 인해 폭주나 기울기 소실이 발생한다고 주장하여서 이 입력값의 변차를 줄여보고자 한게 이 배치 정규화의 시작이라고 할 수 있겠다.
한번에 들어오는 배치 단위로 정규화를 하는 것을 뜻하며, 활성화 함수를 통과하기전에 수행된다.
입력에 대해 평균을 0으로 만들고, 정규화를 한 뒤 정규화된 데이터에 대해서 스케일로 시프트를 수행한다.
입력값 : 미니 배치 B = { $ x_{i}, x_{2}, … ,x_{m} $ }
출력값 : $ y_{i} = BN_{\gamma ,\beta}(x_{i})) $
이라고 할때 아래의 순서대로 계산한다.
* 미니 배치에 대한 평균 계산
\(\mu_{B} \leftarrow \frac{1}{m}\sum_{i=1}^{m}x_{i}\)
* 미니 배치에 대한 분산 계산
\(\sigma^{2}_{B} \leftarrow \frac{1}{m}\sum_{i=1}^{m}(x_{i}-\mu_{B})^{2}\)
* 정규화
\(\hat{x}_{i} \leftarrow \frac{x_{i}-\mu_{B}}{\sqrt{\sigma^{2}_{B}+\varepsilon }}\)
* 스케일 조정( $\gamma$ )과 시프트( $\beta$ )를 통한 선형 연산
\(y_{i} \leftarrow \gamma \hat{x}_{i} + \beta = BN_{\gamma,\beta}(x_{i})\)
d. 층 정규화(Layer Normalization)
기본적으로 동일한 정규화이다. 훈련 데이터의 입력 인덱스 단위로 정규화를 했던 배치 정규화와는 달리 훈련 데이터의 층 단위로 정규화를 한다는 점이 다르다. 아래의 그림을 본다면 이해가 될 것이다.
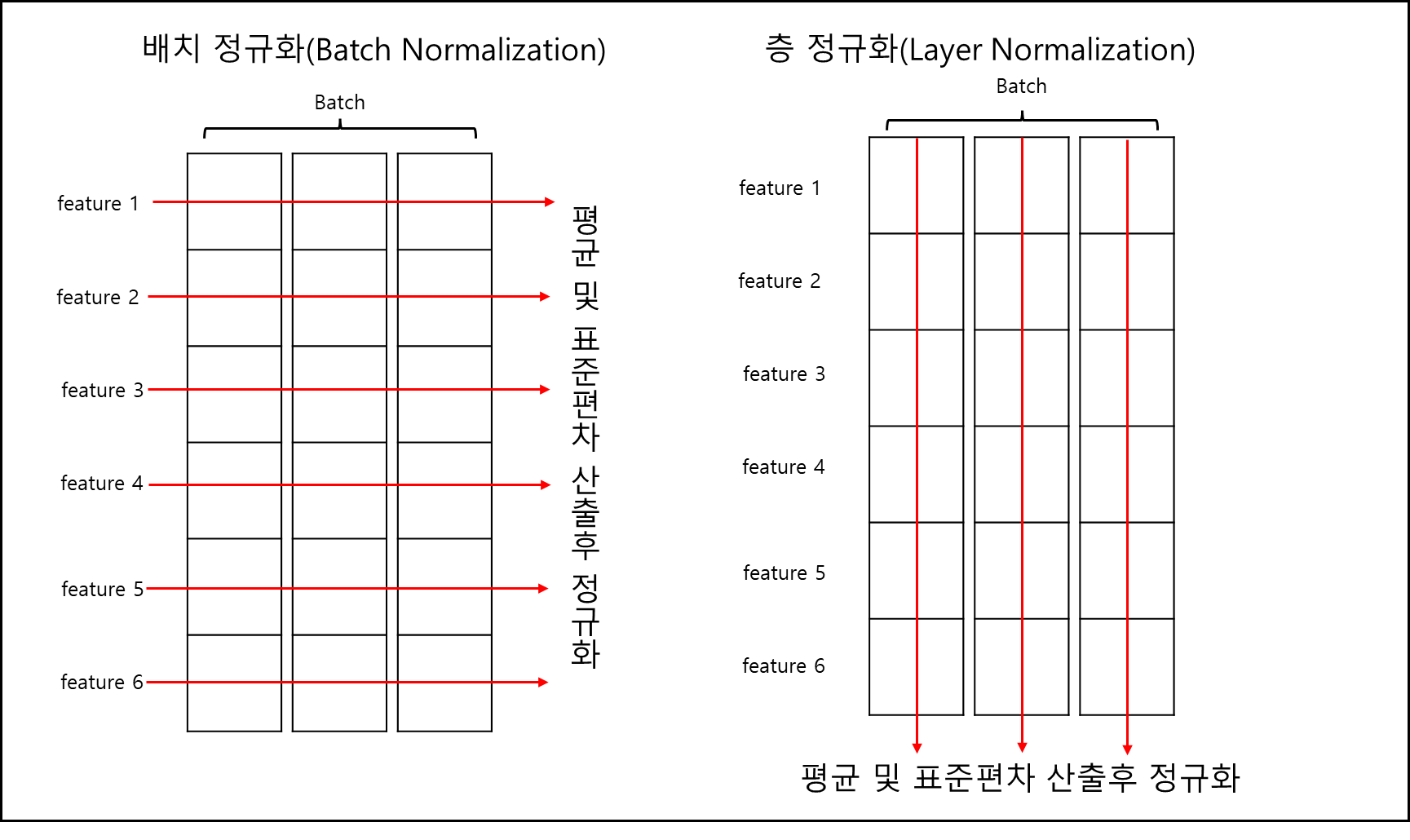
참고 자료
- 인공지능 개념 및 응용 3판 Artificial Intelligence Concepts and Applications (2013년) - 도용태, 김일곤, 김종완, 박창현, 강병호 저, 사이텍미디어
- 위키독스 - 딥 러닝을 이용한 자연어 처리 입문
- Machine Learning, Tom Mitchell, McGraw Hill, 1997.
- geeksforgeeks - Type of machine learning