기계학습 - Deep learning - 워드임베딩
Deep learning
워드임베딩(Word Embedding)
1. 개요
단어를 벡터로 표현하는 방법으로, 단어를 밀집 표현(Dense Representation)으로 바꾸는 것을 말한다.
이 밀집 표현에 대해서 알기 위해서는 희소 표현(Sparse Representation)에 대해 먼저 알아야한다.
1) 희소표현(Sparse Representation)
벡터 또는 행렬의 대부분이 0을 표현되는 방법을 희소표현이라고 한다.
예를 들어 원-핫 인코딩의 결과인 원-핫 벡터의 경우 아래와 같은 형태로 표현된다.

단어 리스트와 벡터 표현이 1대 1로 Mapping 되어 해당 단어를 나타내는 것이 아니라면 모두 0으로 처리한다. 이를 희소 표현이라고 하며 공간의 낭비가 매우 심한데 만약 100개의 단어를 표기하고 싶다면 길이 100의 벡터가 필요한 셈이다.
2) 밀집표현(Dense Representation)
지정된 차원의 크기로 표현하는 방법이다. 희소표현에서 밀집표현으로 바꾸는 여러 알고리즘을 거쳐서 나타낸다.
처리된 희소표현은 0과 1이 아닌 지정된 차원의 크기만큼 실수로 표현된다.
희소표현보다 적은 차원을 써서 밀집된 형태를 띄기에 밀집 표현이라고 부른다.
이러한 밀집 표현을 만드는 방법은 아래에 이어서 서술하겠다.
2. 종류
1) Word2Vec
기본적으로 2개의 방식을 말하는데 CBOW(Continuous Bag of Words)와 Skip-Gram 두 가지 방식이 있다.
a. CBOW(Continuous Bag of Words)
어떤 문장을 학습하는데 있어서 주변에 있는 단어를 입력으로 중간의 단어를 예측하는 방법이다.
아래와 같은 예문이 있다고 가정해보자.
[“The”, “fat”, “man”, “sat”, “on”, “the”, “chair”]
index 0부터 끝까지 중심단어(Center word)로 선택하여 학습을 한다고 할때 주변의 몇 번째 단어까지 볼지 결정해야한다. 이 범위는 윈도우(Window)라고 한다.
윈도우 크기가 2이고, 중심단어가 “man”이라고 한다면 주변단어로 “the”,”man”과 “on”,”the”를 사용한다. 이름 원-핫 벡터로 나타낸다면 아래와 같다.
중심단어 : [0,0,1,0,0,0,0]
주변단어 : [1,0,0,0,0,0,0],[0,1,0,0,0,0,0],[0,0,0,1,0,0,0],[0,0,0,0,1,0,0]
이를 처음부터 끝 단어까지 모두 중심단어로 선정하여 일종의 데이터 셋을 만든다.
이 방법을 슬라이딩 윈도우라고한다.
이렇게 슬라이딩 윈도우를 만들었다면 아래 그림을 보자
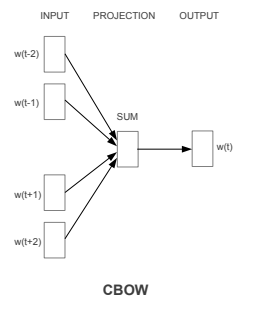
CBOW는 위와 같은 구조로 되어있다. 위 그림은 Word2Vec가 처음 발표된 “Efficient Estimation of Word Representations in Vector Space” 논문에서 발췌한 것이다.
먼저 Input에 원-핫 벡터로 Mapping한 값들을 각각 넣고, 투사층(Projection Layer)라고 불리는 은닉층을 통과시켜 출력층을 뽑아낸다. 여기서 Projection Layer는 활성화 함수가 존재하지 않는 은닉층으로 생각하면 편하며 결과 값으로는 중심 단어의 원-핫 벡터와 비교하여 역전파로 학습을 하면 된다.
입력값에서 나오는 값과 곱해지는 W값과 투사층에서 나오는 값과 곱해지는 W’값을 학습하는게 목표이다. 총 단어집합의 크기 V와, 지정한 차원 M이라면 W값은 V x M이고 W’은 M x V 형태의 행렬이 된다.
W와 W’을 이용하여 각 값을 곱해서 나온 결과 값은 사실상 W행렬의 i번째 행을 그대로 lookup해오는 것과 같기에 W행렬의 곱을 lookup table이라고 부른다.
실질적으로 학습시킨 결과는 윈도우 크기의 중간이므로 곱한 값들에 대해 평균을 구해줘야 실질적으로 구하려는 값을 구할 수 있다. 따라서 슬라이드 안의 값들을 W로 곱한 것에서 평균 값을 구하고, 이후에 W’ $\times$ v 를 해준뒤 크로스 엔트로피 함수를 이용하여 다시 원-핫 벡터에 매핑시키면 원래 값으로 나오게 할 수 있다.
b. Skip-Gram
CBOW에서 주변 단어를 통해 중심 단어를 예측했다면, Skip-gram은 중심 단어에서 주변 단어를 예측한다. 이전과 같이 윈도우 크기가 2이고, 중심단어가 “man”이라고 한다면 주변단어로 “the”,”man”과 “on”,”the”를 사용한다. 이름 원-핫 벡터로 나타낸다면 아래와 같다.
중심단어 : [0,0,1,0,0,0,0]
주변단어 : [1,0,0,0,0,0,0],[0,1,0,0,0,0,0],[0,0,0,1,0,0,0],[0,0,0,0,1,0,0]
이를 인공 신경망으로 도식화해보면 아래와 같다.
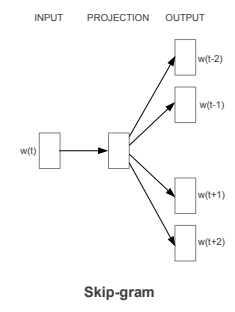
아까와는 다르게 input이 1개고 투사층을 지나서 4개로 나뉜 것을 볼 수 있다. 절차에 대해서는 크게 다르지 않다. 단, 평균 값은 내지 않으며 각 W’ 값을 곱해서 나온 결과를 크로스 엔트로피 함수를 취해서 각 데이터의 원-핫 벡터로 변환할 수 있다.
기본적으로 Skip-gram이 CBOW보다 성능이 좋으나 윈도우의 크기에 따라 임베드 벡터로 변환하는 시간이 좀 더 오래 걸린다고 한다.
2) Glove(Global Vectors for Word Representation)
2014년도에 스탠포드 대학에서 개발한 워드 임베딩 방법으로 카운트 기반과 예측 기반을 모두 사용한다. 카운트 기반의 LSA(Latent Semantic Analysis)와 Word2Vec의 단점을 보완하는 목적으로 등장했다.
LSA는 전체적인 통계정보를 고려하지만 단어 의미간의 유추작업에는 약하고, Word2Vec은 유추작업은 뛰어나지만 전체적인 통계정보가 반영하지 못한다는 점에서 이 둘을 보완하는 방식을 사용한다.
a. 윈도우 기반 동시 등장 행렬(Window based Co-occurrence Matrix)
단어의 동시 등장 행렬은 행과 열을 전체 단어 집합의 단어들로 구성하고, i 단어의 윈도우 크기(Window Size) 내에서 k 단어가 등장한 횟수를 i행 k열에 기재한 행렬을 뜻한다.
아래의 세 문장이 있다고 할때
- i love you
- i like you
- i want you
윈도우 크기가 N일 때는 좌, 우에 존재하는 N개의 단어만 사용한다. 윈도우 크기가 1일 때 윈도우 동시 등장 행렬로 만들면 아래와 같다.
| i | love | like | want | you | |
| i | 0 | 1 | 1 | 1 | 0 |
| love | 1 | 0 | 0 | 0 | 1 |
| like | 1 | 0 | 0 | 0 | 1 |
| want | 1 | 0 | 0 | 0 | 0 |
| you | 0 | 1 | 1 | 1 | 0 |
전치 행렬로 만들어도 동일한 행렬이 된다.
b. 동시 등장 확률(Co-occurrence Probability)
동시 등장 확률 $ P(k|i) $ 는 동시 등장 행렬로부터 특정 단어 i의 전체 등장 횟수를 카운트하고, 특정 단어 i가 등장했을 때 어떤 단어 k가 등장한 횟수를 카운트하여 계산한 조건부 확률이다.
$ P(k|i) $ 에서 i를 중심 단어(Center Word), k를 주변 단어(Context Word)라고 했을 때, 위에서 배운 동시 등장 행렬에서 중심 단어 i의 행의 모든 값을 더한 값을 분모로 하고 i행 k열의 값을 분자로 한 값이다. Glove의 논문에서 갖고온 아래의 표로 예시를 들어보자.
| 동시 등장 확률과 크기 관계 비(ratio) | k=solid | k=gas | k=water | k=fasion |
| P(k l ice) | 0.00019 | 0.000066 | 0.003 | 0.000017 |
| P(k l steam) | 0.000022 | 0.00078 | 0.0022 | 0.000018 |
| P(k l ice) / P(k l steam) | 8.9 | 0.085 | 1.36 | 0.96 |
위의 표를 본다면 ice가 등장했을 때 solid가 등장할 확률이 steam이 등장했을 때 solid가 등장한 확률보다 높다.
단단함이 증기보다는 얼음과 연관이 있는 단어긴 하니 어찌보면 당연해보이기도 한다. 이걸 각각의 비로 나타낸다면 $ P(solid | ice) / P(solid / steam) $ 이고 이는 8.9이다. 즉 ice일때 solid일 확률이 8.9배라는 뜻이다.
k값을 바꾸어 water로 바꾸면 둘다 비슷한 비인 1에 가까운 값이 나오고 k를 gas로 바꾼다면 steam이 더 높게 나온다.
즉 단어간의 상관 관계를 알수 있다.
이를 바탕으로 아래의 손실함수를 설계해볼 수 있다.
c. 손실 함수(Loss function)
손실함수를 정의하기 전에 몇가지 용어를 정리하고 들어가야한다.
- $X$ : 동시 등장 행렬(Co-occurrence Matrix)
- $X_{ij}$ : 중심 단어 i가 등장했을 때 윈도우 내 주변 단어 j가 등장하는 횟수
- $X_{i}$ : $ \sum_{j}^{}X_{ij} $ : 동시 등장행렬에서 i행의 값을 모두 더한 값
$P_{ik}$ : $ P(k i) = \frac{X_{ik}}{X_{i}} $ : 중심단어 i가 등장했을 때 윈도우 내 주변 단어 k가 등장할 확률 ex) $ P(solid ice) $ = 단어 ice가 등장했을 때 단어 solid가 등장할 확률 - $\frac{P_{ik}}{P_{jk}}$ : $P_{ik}$를 $P_{jk}$로 나눠준 값
ex) P(solid | ice) / P(solid | steam ) = 8.9 - $W_{i}$ : 중심 단어 i의 임베딩 벡터
- $\tilde{W_{k}}$ : 주변 단어 k의 임베딩 벡터
GloVe를 한마디로 말하자면 ‘임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것’이다. 즉, 이를 만족하도록 임베딩 벡터를 만드는 것이 목표이다. 이를 식으로 나타낸다면 아래와 같다.
\[dot product(w_{i},\tilde{w_{k}}) \approx P(k|i) = P_{ik}\]위의 식까지 유도하는 과정은 아래와 같다.
어떤 벡터 $ w_{i},w_{j},w_{k} $를 가지고 함수 F를 적용하면 $\frac{P_{ik}}{P_{jk}}$ 가 나온다는 가정을 한다.
b의 예시를 들어 설명하면 아래와 같은 것이다.
일단 위 가정을 두고 우리는 함수 F를 찾아야한다. 먼저 $ w_{i} ,w_{j} $ 의 차이를 함수 F의 입력으로 사용한다고 가정하자.
\[F(w_{i}-w_{j},\tilde{w_{k}}) = \frac{P_{ik}}{P_{jk}}\]좌변은 벡터값이고 우변은 스칼라이니 F의 입력값을 내적하여 형태를 맞춰준다.
\[F((w_{i}-w_{j})^{T}\tilde{w_{k}}) = \frac{P_{ik}}{P_{jk}}\] \[F(w_{i}^{T}\tilde{w_{k}}-w_{j}^{T}\tilde{w_{k}}) = \frac{F(w_{i}^{T}\tilde{w_{k}})}{F(w_{j}^{T}\tilde{w_{k}})}\]이후 F의 조건에 대해서 생각해보면 아래와 같다.
- $W_{i}, W_{k}$의 순서가 바뀌어도 같은 값을 반환
- 말뭉치 전체에서 구한 X는 대칭 행렬이므로 함수 F는 이러한 성질이 있어야함
- 함수 F는 준동형(Homomorphism)을 만족해야함 -> $F(a+b) = F(a)F(b)$ 혹은 $ F(a-b)=\frac{F(a)}{F(b)} $ 를 만족해야함
이를 살펴보니 지수함수 형태면 위 세가지를 만족한다.
따라서 F를 지수함수 exp 라고 할 때 아래와 같이 표현할 수 있다.
두번째 식으로부터 아래와 같은 식을 얻을 수 있다.
\[w_{i}^{T}\tilde{w}_{k} = logP_{ik} = log(\frac{X_{ik}}{X_{i}})=logX_{ik} - logX_{i}\]$w_{i},\tilde{w_{k}}$는 두값의 위치를 서로 바꾸어도 식이 성립해야한다.
때문에 $ \tilde{w_{k}} $에 대한 편향 $\tilde{b_{k}}$ 를 추가한다.
위의 식은 손실 함수의 핵심이 되는 식이다. 위의 식을 기준으로 손실함수를 일반화 하면 아래와 같다. 여기서 V는 단어 집합의 크기를 말한다.
\[Loss function = \sum_{m,n=1}^{V}(w_{m}^{T}\tilde{w}_{n}+b_{m}+\tilde{b}_{n}-logX_{mn})^{2}\]위 식에서 $log X_{ik}$에서 $X_{ik}$가 0이 될 수 있고, 동시 등장 행렬 X가 희소 행렬일 경우 0에 가까운 값을 갖게 되어버리기에 아예 가중치 함수 $F(X_{ik})$ 를 손실함수에 도입하는 것으로 해결했다. 가중 치 함수 $f(x)$ 의 식은 아래와 같다.
\[f(x)=min(1,(x/x_{max})^{3/4})\]이를 다 고려하여 일반화된 손실함수는 아래와 같다.
\[Loss function = \sum_{m,n=1}^{V}(w_{m}^{T}\tilde{w}_{n}+b_{m}+\tilde{b}_{n}-logX_{mn})^{2}\]3) FastText
페이스북에서 개발한 워드임베딩 방식이다.
기존에 나온 워드임베딩 방식은 학습하지 않은 단어는 학습할 수 없다.
특히 단어a + 단어b로 형성된 복합어의 경우도 각각의 단어는 학습하지 않은 단어기 때문에 사용할 수 없는데 FastText를 사용하면 단어를 SubWord 형태로 잘라서 학습하기 때문에 각각의 단어를 사용할 수 있다.
기본적인 방식은 Word2Vec과 같다. 다만 FastText에서는 각 단어는 글자 단위 n-gram의 구성으로 취급한다. n의 값이 얼마인지에 따라 단어들이 얼마나 분리되는지 결정되는 것이다. 가령 n이 3이고 단어가 banana라면 단어를 3개 글자로 분리하되 시작 글자 앞에는 <를 끝글자="" 뒤에는="">를 붙여서 나눈다. 표현하면 아래와 같다.
1
<ba, ban, ana, nan, ana, na>
그리고 전체 단어 앞 뒤에 <>를 붙여서 하나 더 추가한다.
1
<ba, ban, ana, nan, ana, na>,<banana>
이렇게 생성된 7개의 토큰을 벡터화 하는 것이다. 일반적으로는 n이 딱 한 개로 정해져 있지 않고 범위로 설정 되며 n값의 범위대로 단어가 토큰화된 뒤 벡터화된다. 이 벡터에 대해서 Word2Vec를 시행하는 것이므로 banana의 벡터값은 위 벡터와 같은 값들의 총 합으로 구성합니다
1
banana = <ba + ban + ana + nan + ana + na> + ... + <banana>
이렇게 해두면 각각의 부분단어에 대해 학습이 되기에 학습된 단어들의 조합으로 이루어진 복합어에 대해서도 학습한 것과 같은 효과가 나며 한 단어를 중첩해서 학습한 효과가 나기 때문에 등장빈도가 낮은 단어에 대해서도 일정 성능을 보인다.
참고 자료
- 위키독스 - 딥 러닝을 이용한 자연어 처리 입문
- Tomas Mikolov et al, “Efficient Estimation of Word Representations in Vector Space”, arxiv, 2013
- Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, Doha, Qatar. Association for Computational Linguistics.
- Bojanowski, Piotr, Edouard Grave, Armand Joulin, and Tomas Mikolov. ‘Enriching Word Vectors with Subword Information’. arXiv [Cs.CL], 2017. arXiv. http://arxiv.org/abs/1607.04606.