기계학습 - Deep learning - Transformer
Transformer and “Attention Is All You Need”
1. 개요
기본적으로 언어라는 것은 순서가 있다. 각각의 단어들이 위치와 앞뒤 단어와의 연관성에 따라 관계를 가지고 뜻을 형성한다. 이는 이전에 포스팅했던적 있는 LSTM과 GRU가 등장하게 된 계기다.
기존 딥러닝 모델에 비해서 순차 데이터 처리에는 LSTM과 GRU가 탁월했지만 이 역시 길이가 너무 길어지면 정보 소실 현상이 일어난다.
흡사 사람도 말이 길어지면 논지가 불분명해질수있듯이 망각하는 현상이 일어나는 것이다.
이를 위해 Attention이라는 기술이 등장하여 이전 데이터를 다시 주의(Attention)를 일깨워주는 방식으로 정확도를 올렸지만 이 역시 조금 더 길이가 길어졌을 뿐 고질적인 문제는 해결할 수 없었다.
하지만 2017년에 구글 브레인(현재는 알파고를 만든 딥마인드사와 합병했다)에서 발표한 혁신적인 논문으로 인해 딥러닝과 LLM의 판도와 완전히 뒤바뀌는 사건이 일어났다.
간단하게 말하자면 이 “Attention Is All You Need” 논문의 핵심은 번역 같은 순차적 작업에서 LSTM/GRU 같은 재귀(recurrent) 구조를 완전히 제거하고 자기-어텐션(self-attention) 만으로 인코더-디코더를 구성해 더 빠르게 병렬 처리할 수 있다는 내용이다.
위에서 주장하는 내용을 바탕으로 층으로 이루어진 구조가 현재의 LLM과 언어모델의 기본이 되었는데 이를 Transformer라고 한다. 이번 포스팅에서는 Transformer에 대해서 알아보겠다.
2. 구조
1) 어텐션(Attention)
어텐션은 입력 시퀀스의 각 요소(토큰)가 시퀀스의 다른 요소들과 어떤 관련(중요도)을 가지는지를 학습해 가중합으로 문맥을 만드는 메커니즘이다. Transformer에서 주로 사용하는 형태는 Scaled Dot-Product Attention이다.
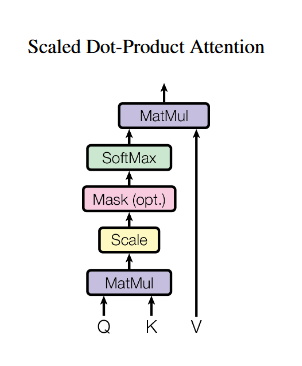
“Attention is all you need” 논문에서 발췌
여기서 Q는 Query, K는 Key, V는 Value를 뜻하며 각각 값은 벡터이다.
이는 입력 임베딩의 서로 다른 선형 투영이며 $d_{k}$ 는 key 벡터 차원이다.
$d_{k}$값에 루트가 씌워진 이유는 key 차원이 커질 경우 분모값이 커지는데 소프트맥스 함수 특성상 기울기가 0에 가까워지기 때문이다. 이를 어느정도 막고자 루트를 씌워서 분모값이 급격히 커지는 것을 막는다.
간단히 말하자면 현재 처리중인 토큰이 의미 결정에 영향을 많이 준다면 value 벡터가 더 큰 가중치로 합쳐져서 최종 결과에 영향을 많이 준다.
※ 선형 투영
입력 벡터에 학습 가능한 행렬을 곱해 다른 차원 혹은 다른 기저로 선형 변환하는 것을 말한다.
아래의 예시를 보자, 임베딩 한 벡터 x = [1,2]가 있고 투영행렬 W가 아래와 같이 있다고 해보자.
이때 선형 투영 결과 y=xW면 아래와 같이 계산될 수 있다.
- 1 X 1 + 2 X 1 = 1 + 2 = 3
- 1 X 1 + 2 X (-1) = 1 - 2 = -1
위 결과는 y=[3,-1]로 나타낼 수 있게 된다. 이렇게 입력을 다른 축 혹은 기저로 재표현 하는 것을 말한다.
어텐션에서는 각기 다른 가중치 형렬을 곱하며 여기서는 아래와 같은 Q,K,V를 사용한다.
\(Q=XW^{Q}\)
\(K=XW^{K}\)
\(V=XW^{V}\)
기본적으로는 편향(bias)는 생략해서 설명하지만 실제 구현에서는 포함될 수 있다.
2) Multi-Head Attention
어텐션은 어떤 특정 종류의 관계만 다룰수 있으므로 Transformer에서는 여러개의 어텐션을 병렬로 운용하는데 Multi-Head Attention이라고 한다.
각 헤드는 위에서 봤던 서로 다른 선형 투영 \(QW^{Q}_{i}, KW^{K}_{i}, VW^{V}_{i}\) 를 통해 입력을 변환해 독립적으로 어텐션을 계산하고 그 결과를 이어 붙인다음에 다시 선형 변환 \(W^{O}\)를 한다. 이를 논문에 나타난 수식을 표현하면 아래와 같다. 그 아래의 그림 역시 논문에 표현된 그림이다.
\(MultiHead(Q,K,V) = Concat(head_{1},...,head_{h})W^{O}\)
\(where head_{i} = Attention(QW^{Q}_{i},KW^{K}_{i},VW^{V}_{i})\)
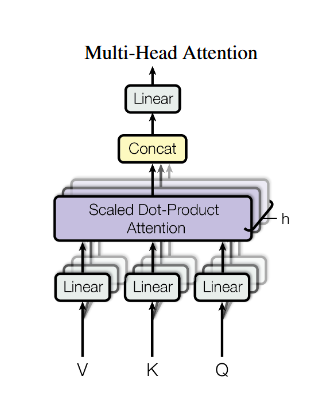
각 헤드는 주어-동사 관계나, 수식적 일치, 의존성들을 각기 다르게 담당하여 처리하기 때문에 표현력이 크게 올라간다.
3) 위치 정보 추가
순서를 명시적으로 처리하지 않는 순수 어텐션 구조에서는 토큰의 순서 정보가 입력에 주어져야 한다. 논문에서는 아래와 같이 단어 임베딩에 다음과 같은 사인/코사인 기반의 위치 인코딩을 더한다.
\(PE_{pos,2i} = sin(\frac{pow}{10000^{2i/d_{model}}})\)
\(PE_{pos,2i+1} = cos(\frac{pow}{10000^{2i/d_{model}}})\)
이 논문 이후에는 상대적 위치 인코딩, RoPE 등 다른 대체 방식이 많이 제안되었다.
4) Transformer
Transformer는 인코더(encoder)와 디코더(decoder) 를 각각 여러 층(layer)로 쌓은 구조이다. 논문에서는 각각 6개 층으로 구성했다.
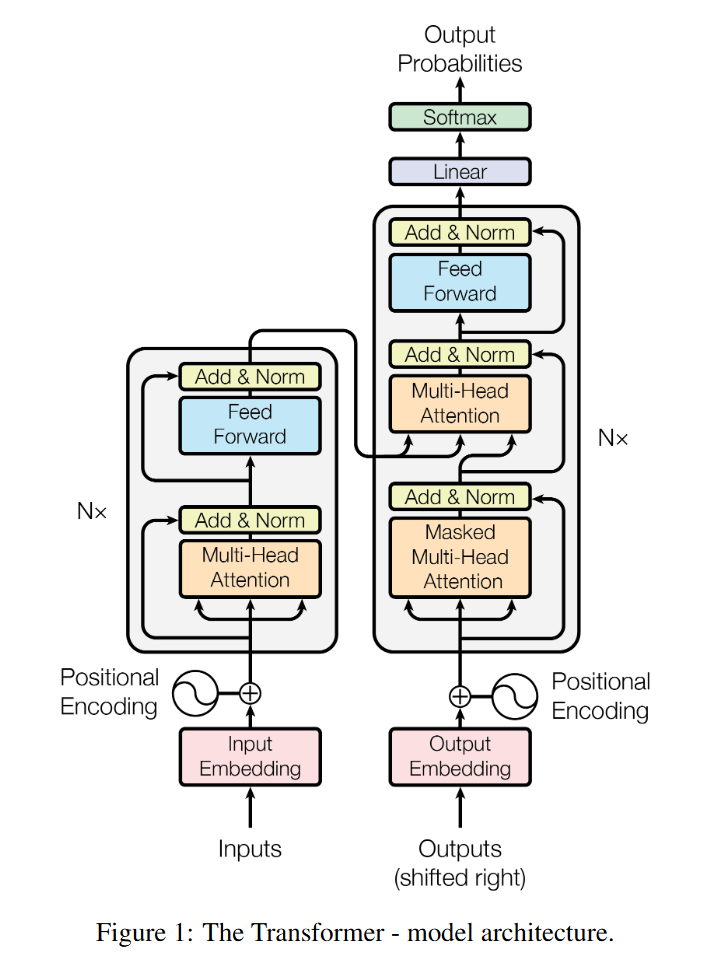
a. 인코더 블록(한 층)
- Multi-Head Self-Attention (입력 토큰들 간의 self-attention)
- Add & LayerNorm (잔차 연결 + 층 정규화)
- Position-wise Feed-Forward Network (FFN)
$FFN(x) = max(0,xW_{1}+b_{1})W_{2}+b_{2}$ : 모든 위치에 같은 FFN을 적용 - Add & LayerNorm
여기서 잔차 연결(residual connection)과 LayerNorm은 학습 안정성과 정보 흐름을 돕는다.
b. 디코더 블록(한 층)
- Masked Multi-Head Self-Attention (미래 토큰 마스킹)
- Add & LayerNorm
- Multi-Head Encoder-Decoder Attention (쿼리는 디코더, 키/값은 인코더 출력)
- Add & LayerNorm
- FFN + Add & LayerNorm
디코더의 3단계는 디코더가 인코더에서 인코딩된 문맥(소스 언어)을 참조하도록 해준다.
※ Add
여기서 말하는 Add는 Residual Connection, 즉 잔차 연결을 말하는 것으로 입력을 변환한 결과(attention)에 원래 입력을 그대로 더해주는 방식을 말한다.
수식으로 나타내면
형태로 표현되는데 여기서 f(x)는 어텐션이나 FFN의 출력을 말한다.
위와 같이 처리되면 기울기 소실 및 폭주 문제를 어느정도 완화할 수 있다.
※ LayerNorm
신경망 각 층의 출력을 특징(feature) 차원 단위로 정규화하는 것이다. 입력 벡터 x (차원 d)에 대해서 평균과 분산을 계산하고 정규화하는 것이다.
$\mu$ : 해당 벡터의 평균
$\sigma$ : 표준 편차
$\gamma, \beta$ : 학습 가능한 스케일/시프트 파라미터
LayerNorm은 한 시퀀스의 한 토큰 벡터 내부에서 정규화를 하기 때문에 시퀀스 길이/배치 크기와 무관하게 안정적으로 학습할 수 있으며, 출력 분포를 일정하게 맞춰주므로 학습이 더 안정되고 빠르다
3. 응용
1) 기계 번역, Seq2Seq
애당초 Attention is all you need 논문 자체가 RNN을 대체한 기계 번역 논문이었다.
2) 사전학습 언어모델 - Bert(Transformer encoder 기반)
Transformer에서 인코더 블록만을 쌓아 만든 모델로, 입력 문맥의 좌우 모두를 보는 사전 학습 모델이다. 입력 토큰의 일부를 [MASK]로 바꾸고 그 마스크된 토큰을 문맥 좌우로 예측하도록 학습한다.
일반적으로 이 BERT 모델은 분류, 질의응답, 개체명 인식, 문장 유사도 등 이해 중심 업무에 널리 사용된다.
3) 대규모 생성형 언어모델(Large Language Model) - GPT 계열(Transformer decoder 기반)
Transformer의 디코더(그대로 사용하는 경우도 있고 변경해서 사용하기도한다)만을 사용하여 만든 모델이다.
Generative Pre-trained Transformer의 약자로 GPT 라고 불리며 이를 해석하면 사전 학습된 생성형 언어 모델이다.
우리가 많이 사용하는 Chat Gpt나 제미나이, 그록 같은것들은 모두 GPT 계열이다.
토큰을 왼쪽에서 오른쪽 순서로 예측하도록 학습되었기 때문에 자연스러운 생성에 강하다.
하지만 이 경우 없는 사실을 만들어내는 환각(Hallucination) 현상이나 편향적 대답, 유해한 정보등이 포함될 수 있어서 이를 줄이기 위해 많은 노력을 기울이고 있다.
그 외에도 Attention과 Transformer 기법은 사실상 기본적인 모델로써 자리잡았다.
설명이 어렵다 싶은 부분은 내용 추가 업데이트 예정, 내용 추가 검증 예정
참고 자료
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, & Illia Polosukhin. (2023). Attention Is All You Need.
- IBM - What is positional encoding?
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, & Kristina Toutanova. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Alec Radford at al, Improving Language Understanding by Generative Pre-Training