병렬분산컴퓨팅 - 분산 시스템 간접 통신 패러다임
분산 시스템 간접 통신 패러다임
1. 직접 통신 방식의 불 충분성
RPC와 같은 직접 통신 방식은 실시간성에는 좋지만 실제 환경에서의 작업은 대부분 비동기적으로 이루어진다.
직접 통신만으로 구성되면 아래와 같은 문제가 발생한다.
- 갑작스런 요청의 폭증에 대비할 수 없다.
- 서버에서 작업의 처리 시간이 꽤 걸리는 경우에는 다른 일을 처리할 수가 없다.
- 서버가 다운되거나 재구동시 서비스 다운이 일어날 수 있다.
- 클라이언트가 응답을 기다리는 동안 다른 작업을 못한다.
위와 같은 문제들은 결국 사용자 경험이 저하로 이어지기 때문에 간접(Indirect) 방식의 통신으로 시스템을 구성하기 시작했다.
2. 간접 통신 (Indirect Communication)
간접 방식의 통신은 서버와 클라이언트가 직접 통신하는 것이 아닌, 그 사이에 Broker를 두고 통신하는 방식을 말한다.
여기서 클라이언트는 Sender, 서버는 Receiver라고 칭하겠다.
간접 통신 방식은 아래와 같은 특징을 갖는다.
1) 공간 분리 (Space decoupling)
- Sender는 Receiver가 누군지, 어디에 있는지 굳이 알 필요가 없다. (Broker에 Receiver가 등록 되어 있기 때문에 Sender에서 알 필요 없음)
2) 시간 분리 (Time decoupling)
- Sender와 Receiver가 똑같은 서버 타임을 가지지 않아도 된다. (시간 동기화 문제 없음)
- Sender와 Receiver는 꼭 같은 시간에 통신을 하지 않아도 된다.
3) 동기화 분리 (Synchronization decoupling)
- Sender는 Receiver가 사용가능한 상태일때까지 기다릴 필요가 없다. (한번 보내두면 Broker가 Receiver가 사용가능할때 전달함)
※ 간접 통신의 예시
이러한 간접 통신 방식은 아래와 같은 두 가지 예시가 있다.
- Message queuing systems
- Publish/Subscribe systems
아래에서 위 두 가지 예시를 좀 더 자세히 알아보겠다.
3. 메세지 큐 시스템(Message queue system)
메세지 큐 시스템을 그려보면 아래와 같다.
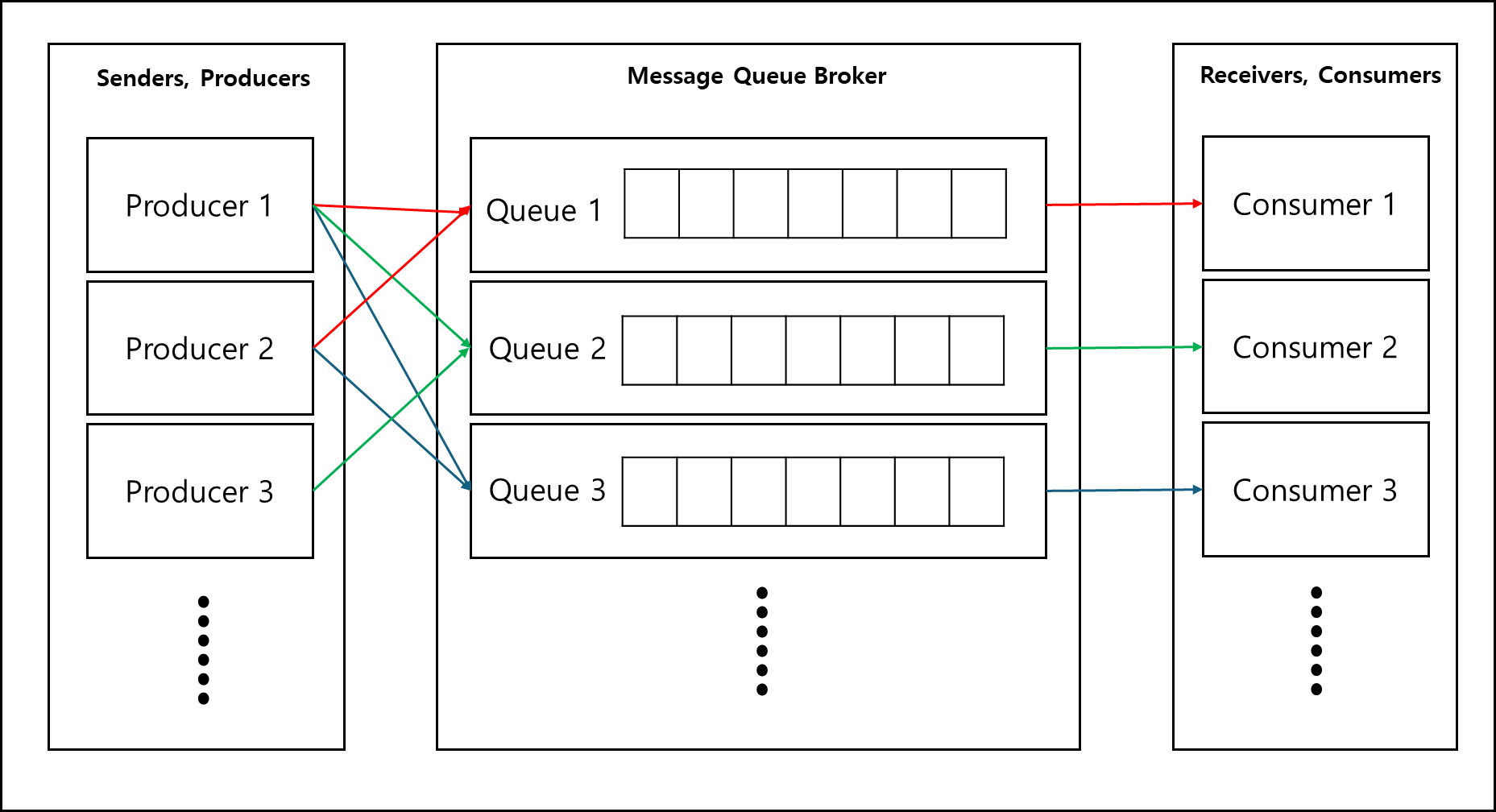
기본적으로 Producer라고 불리는 보내는 쪽에서 Consumer 쪽으로 직접 보내는게 아니라 메세지 큐 브로커에게 요청을 보내고
이 요청은 Queue에 들어갔다가 Consumer에게 전달된다.
여기서 Queue는 단일 큐, 다중 큐 모두 가능하며 한 개 혹은 다 중 큐에 들어간 요청이 단일 Consumer에 전달될수도 혹은 다수의 Consumer에게 전달 될수도 있다.
메세지 큐 브로커를 통해 전달되기 때문에 Producer가 브로커로 메세지를 보내두면 Consumer가 브로커에 요청해서 메세지를 가져가든(Pull)
아니면 브로커가 Consumer에게 전달(Push)하여 처리하기 때문에 꼭 동기적으로 움직일 필요는 없으며 다수의 Consumer를 운용할 수 있기
때문에 처리량 역시 증가 할 수 있다.
1) Push / Pull Model
위에서 Push 모델과 Pull 모델에 대해서 간단하게 설명했는데 좀 더 자세히 설명해보겠다.
a. Push
브로커가 Consumer에게 일방적으로 메세지를 전달하는 방식이다.
브로커가 되는대로 Consumer에게 메세지를 전달하기 때문에 상대적으로 낮은 지연시간을 갖는다.
다만 브로커가 주도해서 전달하기 때문에 Consumer가 메세지를 전달 받을 수 있는 상태여야한다.
실시간 시스템이나 이벤트 주도 응용 프로그램에 어울리는 방식이다.
b. Pull
Consumer가 브로커에 요청해서 메세지를 전달 받는 식이다.
Consumer가 주도하여 메세지를 전달 받기 때문에 빈도나 처리량에 대해서 Consumer 측에서 조절이 가능하며
상대적으로 부하가 큰 처리를 요하는 메세지이거나 혹은 Consumer에서 메세지 처리가 느릴때 좋다.
일괄 처리 프로그램이나 Worker 스타일의 응용 프로그램에 잘 어울리는 방식이다.
2) 일반적인 작동 흐름
일반적으로 메세지 큐 시스템의 작동 흐름은 아래와 같다.
a. 전달
Producer가 메세지 큐로 메세지를 전달한다.
이 경우 비동기로 전달할 수도 있고, 동기적으로 브로커에게 전달 할 수 있는데 동기적으로 브로커에게 전달시, 브로커가 저장까지 하고 응답할 수도 있고, 수신까지만 하고 응답할 수도 있다.
이는 설정에 따라 달라질 수 있다.
b. 저장
메세지 큐가 전달 받은 메세지를 영속적인 스토리지에 저장한다.
이는 메세지 큐의 중단이나 혹은 Consumer의 중단에 대응하여 신뢰성 있는 작동을 보장하기 위함이다.
c. 전달
메세지 큐가 메세지를 Consumer에게 전달한다.
한 개 이상의 Consumer가 해당 메세지를 전달 받을 수 있으며 다수의 Consumer가 메세지를 전달 받을시 병렬 처리 역시 가능하다.
d. 처리
Consumer가 메세지를 처리한다.
e. 응답
Consumer가 처리를 완료하면 브로커에게 응답을 보낸다. 이 응답을 받으면 메세지 큐는 해당 메세지를 큐에서 삭제하며
만약 응답이 모종의 이유로 소실 될시에 메세지 큐에서 Consumer에게 다시 메세지를 전달 할 수 있다.
3) 메세지 큐 설계시 주요 이슈들
a. 확장성 (Scalability)
수많은 Producer와 Consumer가 방대한 양의 메시지를 생성할 때, 시스템에 병목 현상(Bottleneck)이 발생하지 않고 확장 가능해야 한다. 이를 위해 메세지 큐는 Producer와 Consumer를 분리하여 시스템이 독립적으로 확장하고 증가하는 작업 부하를 처리할 수 있게 한다.
- Load Smoothing : 큐가 트래픽 급증(Burst)을 흡수하여 부하 스파이크를 완화한다
- Elastic Worker Scaling : 처리량을 높이기 위해 Consumer 측에 더 많은 워커(Worker)를 유연하게 추가할 수 있다
- Decoupled Scaling : 수요에 따라 Producer와 Consumer가 서로 영향을 주지 않고 독립적으로 확장할 수 있다
- 효율적인 자원 사용 : 비동기 처리를 통해 시스템 자원을 효율적으로 사용할 수 있다. (Elastic Worker Scaling, Decoupled Scaling에 의해 효율적 사용 가능)
※ 주의사항
높은 처리량과 병렬성은 순서 보장 기능을 약화시킬 수 있는 트레이드오프 관계에 있다.
이는 다수의 Consumer를 이용해서 병렬 처리시 각 Consumer의 처리 속도 차이로 인해 먼저 들어온게 나중에 처리 될 수 있기 때문이다.
b. 신뢰성 (Reliability)
브로커(Broker)나 소비자가 실패(Crash)할 경우 메시지가 유실될 수 있으며, 분산 시스템의 특성상 발생하는 다양한 실패들이 불확실성을 초래한다. 이를 위해 메세지 큐 시스템은 메시지 버퍼링, 영구 저장, 재시도 메커니즘을 통해 신뢰성을 향상시킨다.
- Durable Storage : 메시지를 전달하기 전 디스크에 기록하여 브로커나 시스템 충돌 시에도 데이터가 유실되지 않도록 보호한다
- ACK / Retry (Redelivery) : Consumer가 성공적으로 처리한 후 확인 응답(ACK)을 보내지 않으면 메시지를 재전송한다
- Failure Isolation : 특정 Consumer가 실패하더라도 다른 Consumer들은 처리를 계속할 수 있어 단일 장애점(Single point of failure)을 방지한다
- 비동기 복구 : Producer는 일시적인 장애에 차단(Block)되지 않으며, 시스템은 데이터 손실 없이 복구된다
※ 주의사항
재 시도나 혹은 영속적인 스토리지에 저장을 함으로써 좀 더 나은 신뢰성을 보장하기 때문에 이러한 방식은 높은 지연시간과 추가적인 오버헤드를 야기한다. 즉, 높은 신뢰성과 낮은 지연시간은 트레이드 오프 관게이다.
c. 순서성 (Ordering)
여러 Consumer가 병렬로 메시지를 처리하면 전체 처리량(Throughput)은 향상되지만, 메시지가 큐에 들어온 순서(Enqueue Order)와 처리가 완료된 순서(Completion Order)가 달라질 수 있다.
이러한 문제가 발생할 수 있는 이유는 아래와 같다.
- 각기 다른 처리 시간 : 어떤 메세지는 처리하는데 시간이 더 걸릴 수 있다.
- Worker 들의 다른 성능 : 동일한 메세지라도 처리하는 Worker의 성능이 다르다면 처리하는 시간이 다를 수 있다.
- 병렬 처리 : 메세지가 한번에 병렬로 처리되기 때문이다.
이를 해결하기 위한 방법은 아래와 같은 방법이 있다.
- Single Consumer : Consumer를 하나만 운용하는 것, 글로벌 순서를 가장 강력하게 보장하지만 처리량이 가장 낮다.
- Partitioning / Sharding : 특정 키나 파티션으로 나누어 키나 파티션별로 순서를 보장하며 파티션 간 높은 처리량을 유지한다.
- 순서 키/시퀀스 번호 : 메시지에 순서 정보를 담아 소비자 측에서 다시 정렬한다. (사실상 재정렬이므로 오버헤드 매우 큼)
- FIFO Queue : 브로커 레벨에서 지원할때 가능한 방식으로 브로커에서 자체적으로 FIFO를 지원하게 만드는 것이다. (구현 복잡도 높음, 오버헤드 클 수 있음)
각 시스템은 어떤식으로 구현하는지에 대한 예는 아래와 같다.
- 채팅 시스템이라면 roomid를 기준으로 partitioning하여 같은 roomid 내에서는 순서성을 보장하는 식으로 구현할 수 있을 것이며
- 주문 서비스라면 주문 ID 기준으로 partitioning 하여 제공할 것이다.
- 금융 관련된 서비스의 경우에는 단일 consumer를 사용하거나 혹은 MQ 자체에서 strict FIFO를 지원하는 방식을 사용해서 구현하여 순서성을 보장할 것이다.
위에서 봤듯이 대부분의 시스템은 Partitioning(key ordering)을 사용한다.
※ 주의사항
높은 순서성을 보장할 수록 확장성과 처리량이 낮아지게 된다. (순서성과 확장성은 트레이드 오프)
이는 앞서 언급한 순서성 보장 방식을 생각해보면 자연스럽게 이해될 수 있다.
d. 의미 전달론 (Delivery Semantics)
응용 프로그램의 성격에 따라 서로 다른 메시지 전달 보장 수준을 요구한다.
- 보장 수준
- At Most Once (0 또는 1번): 딱 한번만 보내는 방식으로 중복은 없으나 메시지가 유실될 수 있다. 지연 시간이 낮아 메트릭이나 로깅에 적합하다.
- At Least Once (1번 이상): 답변이 없다면 몇번이든 다시 요청하는 방식으로 유실은 없으나 중복 전달될 수 있다. 소비자는 중복 처리를 방지하기 위해 멱등성(Idempotent)을 가져야 하며 이메일 전송 등에 사용된다.
- Exactly Once (정확히 1번): 답변이 없다면 다시 요청을 보내는데 내부적으로 중복 처리 로직이 포함되어있어 유실과 중복이 모두 없다. 가장 강력한 보장이지만 복잡도와 오버헤드가 가장 높으며 금융 거래 등 중요한 작업에 필수적이다.
※ RPC Delivery Semantics vs MQ Delivery Semantics
RPC에서 Maybe 방식은 MQ에서의 At Most Once 방식과 비슷하다.
RPC에서 At Least Once 방식은 MQ에서 AT Least Once 방식과 비슷하며 RPC에서 At Most Once 방식은 MQ에서 Exactly Once 방식과 약간 다른데 거의 비슷하다.
이는 RPC에서 At Most Once 방식은 중복 제거에 좀 더 초점이 맞춰져 있으며 MQ에서의 Exactly Once는 end-to-end에서 메세지가 신뢰성 있게 한번 전달 되는 것에 초점이 가 있기 때문이다.
e. 흐름 제어 및 후방압력 (Flow control & Backpressure)
Producer의 메시지 생성 속도와 Consumer의 처리 속도가 크게 다를 때 메세지 큐에 과부하가 올 수 있다. 갑자기 Producer에서 메세지가 폭증하거나 할때도 동일한 문제가 발생할 수 있는데 이때 필요한게 흐름 제어이다.
흐름제어는 메세지 큐의 과부하를 막기 위한 방법으로 크게는 아래와 같이 두가지 방법으로 나눌 수 있다.
- Backpressure : 메세지 큐 시스템에 압력이 가해질 때 Producer에게 전송 속도를 늦추거나 중단하도록 신호를 보내는 피드백 메커니즘이다.
- 제어 기법 : 생산 속도를 제한하는 Rate Limiting, 최대 큐 크기를 제한하는 Queue Capacity Limits, 큐 상태에 따라 생산자를 일시 정지시키는 Producer Pausing 등이 있다.
이러한 흐름제어는 아래와 같은 도움을 줄 수 있다.
- 메세지 생성 비율 조절 : MQ의 과부하를 막는다.
- 큐 사이즈를 안전 범위에서 유지 : 안정성과 예측 가능성을 유지시킨다.
- 지연시간 및 실패 리스크를 줄인다 : 메세지 큐가 길어지는 것을 방지함으로써 timeout을 피한다.
- 전체적인 시스템의 회복력을 증가시킨다 : 메세지 폭증 및 다양성을 제어함으로써 가능하다.
f. 라우팅과 분리 (Routing & Decoupling)
분리(Decoupling)할 경우 Producer와 Consumer는 서로의 존재를 알 필요가 없으며, 한쪽의 변경이 다른 쪽에 영향을 주지 않고 독립적으로 변경할 수 있다.
수많은 Producer와 Consumer 사이에서 메시지를 효율적으로 경로 배정(Routing)을 해야하는데 메세지 큐 브로커는 Producer와 Consumer 사이에서 규칙에 따라 메시지를 효율적으로 경로를 배정한다
- 주요 라우팅 패턴
- Direct: 특정 키와 정확히 일치하는 경로로 배정
- Topic: 와일드카드를 사용한 패턴 일치 방식
- Fanout: 연결된 모든 큐로 메시지를 브로드캐스트
- Headers: 메시지의 헤더 속성을 기반으로 배정
대규모 시스템의 경우에는 메세지 큐 시스템은 다수의 브로커를 차용한다. 다수의 브로커를 사용하는 이유는 아래와 같다.
- 확장성 : 각 브로커간의 트래픽 분리 및 대규모 워크로드 지원
- 고가용성 : 하나의 브로커가 실패해도 서비스 유지 가능, 복제 시스템 운용시 신뢰성 상승
- 로드 밸런싱 : 큐와 Consumer를 다수개 운용함으로써 시스템 과부하 방지
- 지역 분산 배포 : 브로커가 각 리전과 데이터센터들 너머 퍼져서 운용 가능
위와 같이 다수의 브로커를 운용할 수 있기 때문에 특정 메세지는 다른 적합한 Consumer에 도달하기 위해 브로커 간의 Routing 이 필요할 수 있다.
※ 주의사항
높은 라우트 유연성은 운용과 설정간의 높은 복잡성을 야기할 수 있으며 잘못된 설정은 메세지 유실 및 예상치 못한 전달을 유발할 수 있다.
※ 각 이슈들의 관계
위에서 설명했듯이 각 이슈들을 커버하는 과정에서 아래의 Trade-off가 생긴다.
- 확장성 증가시 : 순서성을 보장하기 어려워 짐
- 신뢰성 증가시 : 높은 지연시간과 추가적인 오버헤드가 생김
- 순서성 증가시 : 낮은 확장성과 낮은 처리성
- 지연시간 감소시 : 신뢰성 감소
4. 발행/구독 시스템(Publish & Subscribe system)
1) Publish & Subscribe 구조가 필요한 이유
a. 기존 RPC 통신
1대 1 통신 방식으로 Sender가 Receiver를 아는 방식으로 긴밀하게 연결되어있으며
Sender와 Receiver가 모두 가용한 상태여야한다.
또한 다수의 서비스에서 동일 데이터가 필요한 상황일 때 더 큰 요청을 받기 위해 아키텍처를 확장하기가 매우 어렵다.
b. MQ(Message Queue) 방식
메세지 큐 방식은 RPC 보다는 좀 더 확장성면에서는 낫다. 그러나 기본적으로 하나의 메세지는 단 하나의 Worker에게 전달되는 방식으로 메세지가 전달된게 확인되면 메세지 큐에서 삭제된다. (물론, 최근에는 다수의 worker에게 동일한 메세지를 전달하는 기능이 추가되긴했지만 해당 기능은 태생적으로 있던 기능은 아니다) 때문에 동일 메세지를 다수의 서비스로 전달하는데 적합하지 못하다. 또한 메세지를 조건에 맞는 지 필터하고 적합한 Worker에 Routing 해야하는데 이러한 기능이 전반적으로 부족한다.
c. Publish / Subscribe 방식
하나의 이벤트로 다수의 서비스에게 전달하는 대규모 서비스를 구현하는데 적합한 형태를 가지고 있다. 이는 아래의 4가지 특징 때문이다.
Decoupled
메세지 큐도 그러하지만 Producer와 Consumer가 동일하게 가용할 필요는 없기 때문에 확장성이 보장된다.Flexible Filtering & Routing
어떤 메세지가 발생하면 Broker가 해당 메세지를 필터링하고 routing하는데 특화되어있다.Scalable Fan-out
Producer 변경 없이 Consumer를 추가하는데 용이하다.Reliable & Replayable
발생한 메세지는 신뢰성있고 재 전달 가능한 형태로 Broker가 가지고 있기 때문에 필요시 다시 전달할 수 있다.
2) 기본적인 Pub/Sub 구조
기본적인 구조도는 아래와 같다.
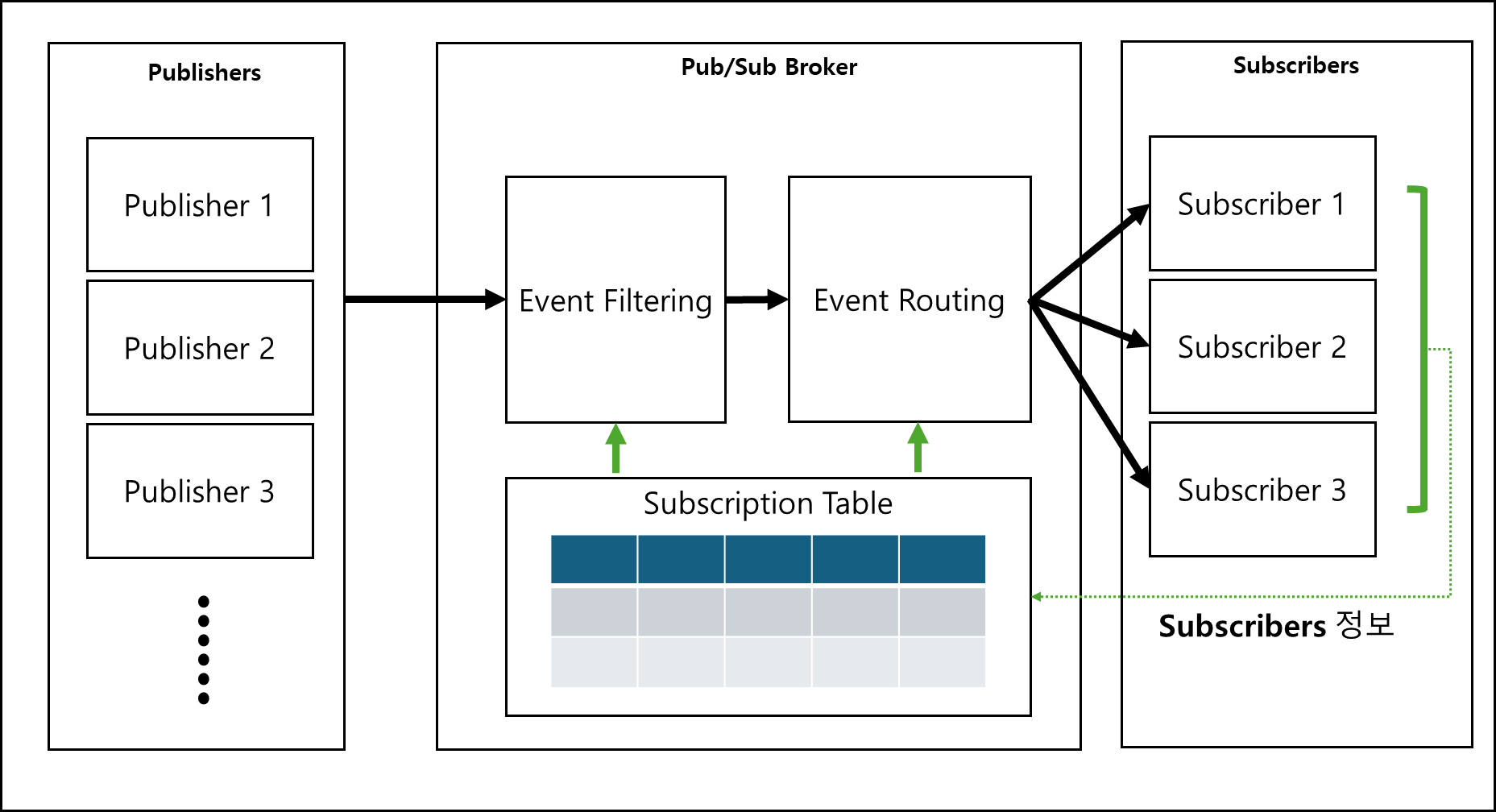
그림에 나와있는 Publisher와 Broker, Subscriber가 하는 일은 아래와 같다.
- 발행자 (Publisher): 발행자는 특정 수신자를 지정하지 않고 브로커에게 이벤트를 전송한다.
- 브로커 (Broker) : 브로커는 구독 테이블(Subscription Table)을 참조하여 들어온 이벤트가 어떤 구독자의 관심사와 일치하는지 평가하고(Filtering), 해당되는 구독자들에게만(Routing) 이벤트를 전달한다
- 구독자 (Subscriber): 구독자는 브로커에게 자신이 관심 있는 이벤트의 조건(필터)을 등록한다.
위의 일에 맞춰서 End-to-End 흐름을 설명하자면 아래와 같다.
- 이벤트(Message) 발생전에 Subscriber는 자신의 받고자하는 내용을 등록한다.
- 브로커는 Subscriber의 요청을 영속적으로 저장한다.
- Publisher가 이벤트(Message)를 발생시킨다.
- 브로커는 Publisher가 발생한 메세지를 2번에서 저장했던 요청을 통해 Filtering한다.
- Fiterling된 메세지는 브로커의 라우팅을 통해 해당하는 Subscriber로 전달된다.
- Subscriber가 메세지를 수신하게 되고 해당하는 Event가 비동기적으로 발생한다.
3) Pub/Sub 구조를 만들 때 핵심 도전과제
Pub/Sub 시스템을 만들기 위해서는 아래의 6가지 핵심 과제가 있다.
a. Scalability
ⓐ 도전과제
- 높은 팬아웃(High Fan-out): 하나의 이벤트가 수많은 구독자에게 동시에 전달되어야 할 때 발생하는 부하이다.
- 동시 발행 부하: 수많은 발행자가 동시에 이벤트를 생성할 때 브로커가 이를 수용할 수 있어야 한다.
- 많은 토픽과, 채널과 구독자를 관리하기 위한 방법이 필요하다.
- 불균형한 워크로드: 특정 토픽에 관심이 쏠리는 ‘핫 토픽(Hot topics)’ 현상으로 인해 특정 브로커에 부하가 집중될 수 있다.
- 네트워크 오버헤드: 브로커 간에 불필요한 이벤트 복제가 발생하면 네트워크 대역폭이 낭비된다.
ⓑ 해결방법
- 토픽/채널 파티셔닝(Partitioning): 모든 데이터를 한 곳에 두지 않고, 토픽이나 채널별로 데이터를 나누어 여러 브로커에 분산 배치한다.
- 브로커의 수평적 확장(Horizontal Scaling): 브로커 여러 대를 추가하여 처리 용량을 선형적으로 늘린다.
- 효과적인 라우팅(Efficient Routing): 모든 이벤트를 모든 브로커에 뿌리는 플러딩(Flooding) 방식 대신, 구독 정보가 있는 경로로만 이벤트를 보내는 랑데부(Rendezvous) 라우팅 등을 사용하여 불필요한 트래픽을 최소화한다
- 구독 및 연결 분산: 구독자들의 연결을 여러 브로커에 골고루 분산시키고, 가능한 한 구독자와 가까운 로컬 브로커에서 이벤트를 전달(Local delivery preference)하여 지연을 줄인다.
- Local delivery preference : 구독자에게 가장 가까운 브로커에게 이벤트 전달을 맡긴다.
- Backpressure & flow control : 구독자가 느린 경우에 시스템의 안정성을 유지하기 위해서 흐름제어와 백프레셔를 제공한다.
b. Matching
Matching을 위한 Filtering에는 크게 두 가지 방식이 있다.
ⓐ 토픽 기반 매칭 (Topic-based)
이벤트를 미리 정의된 카테고리(채널)별로 분류하는 방식이다. 브로커는 이벤트의 토픽만 확인하면 되므로 매칭 속도가 매우 빠르고 확장성이 뛰어나지만, 정교한 필터링은 어렵다.
ⓑ 콘텐츠 기반 매칭 (Content-based)
이벤트 내부의 데이터 속성(예: 가격 > 100, 지역 = “서울”)을 직접 검사하는 방식이다. 구독자는 매우 세밀한 조건으로 이벤트를 필터링할 수 있어 유연성이 높지만, 브로커가 모든 이벤트를 전수 조사해야 하므로 매칭 비용(계산 오버헤드)이 높다.
c. Routing
Filtering된 메세지를 적절한 구독자에게 보내기 위해서는 적절한 라우팅 기법이 필요하다.
이는 실제 서비스에서 단일 브로커가 아닌 확장성을 위해 다수의 브로커를 운용하기 때문이다.
이렇나 다수의 브로커를 통해서 라우팅하는 방식은 아래와 같다.
ⓐ 플러딩 (Flooding / Broadcast)
이벤트를 인접한 모든 브로커에게 무조건 전달하는 방식이다. 구현은 매우 단순하고 견고하지만, 관심 없는 브로커에게도 데이터가 전송되어 네트워크 대역폭 낭비와 트래픽 오버헤드가 매우 크며 확장을 위하여 브로커를 추가시 이벤트 전달량이 크게 늘어나기 때문에 확장성에서도 떨어진다.
구현이 간단하기에 작은 시스템 같은 경우에는 효율적일 수도 있다.
ⓑ 구독 기반 라우팅 (Subscription-based)
구독 정보가 네트워크를 통해 미리 전파되어 라우팅 경로를 형성한다. 이벤트는 구독자가 존재하는 경로로만 전달되므로 불필요한 트래픽을 획기적으로 줄일 수 있는 지능형 방식이다.
플러딩 방식과의 차이는 플러딩 방식의 경우 모든 이벤트를 인접한 모든 브로커에게 전달하지만, 구독 기반 라우팅의 경우에는 구독자 정보만 모든 브로커에게 전달하므로 트래픽의 양 차이가 크다. 구독자 정보 변경 보다는 이벤트의 발생량이 월등히 많기 때문이다.
ⓒ 랑데부 라우팅 (Rendezvous-based)
해시(Hash) 함수 등을 이용해 특정 토픽이나 필터를 담당할 전담 브로커(랑데부 브로커)를 미리 정해둔다. 모든 관련 이벤트와 구독 신청이 해당 브로커로 모이기 때문에 효율적인 매칭이 가능하며, 부하 분산(Load Balancing)에도 유리하다.
이 방식도 Topic-based와 Contents-based로 나눌 수 있다.
Topic-based Rendezvous Routing
- 특정 토픽을 다음의 식과 같이 해시함수를 통해 어떤 Broker가 담당할지 지정한다.
$R=hash(T) mod N$ : 여기서 N은 브로커의 개수이며, T는 토픽, R은 브로커의 ID이다. - Subscriber가 구독을 하면 1에서 정의한 함수를 통해 구독한 토픽 T를 담당하는 브로커 R에게 자신의 구독 여부를 알린다.
- Publisher가 토픽 T에 대해서 이벤트를 발생시키면 브로커 R은 해당 이벤트를 수신하게 된다.
- 브로커 R은 토픽 T에 대해서 매칭되는 걸 확인하고 토픽 T에 대해서 구독한 Subsciber에게 이벤트를 전달한다.
- 특정 토픽을 다음의 식과 같이 해시함수를 통해 어떤 Broker가 담당할지 지정한다.
Contents-based Rendezvous Routing
콘텐츠 기반 랑데부 라우팅은 이벤트 발생을 수신하는 것과 이벤트 송신 대상 정보를 동일 브로커가 가지고 있어야한다는 점이 매우 어렵다.
또한, 특정 토픽이 아닌 다수의 속성(attribute)를 갖고 있는 Contents를 다루는데 이러한 속성이 많으면 필터링 하기가 매우 어려우며
Subscriber가 요하는 속성도 토픽 기반 방식보다 더 복잡해서 어렵다. 토픽 기반 방식에서 사용하던 hash 기반 방식도 사용할 수 없기에 아래의 방식 중 하나로 routing을 진행한다.- Attribute partitioning
각 랑데부 브로커들이 각기 다른 attribute를 담당하여 발생한 이벤트를 필터링한다. - Replication of Subscriptions
구독자의 상태를 다수의 랑데부 브로커들이 복제해서 가지고 있고 이벤트를 수신하면 각 랑데뷰 브로커가 가지고 있는 필터로 처리하여 전송한다.
- Attribute partitioning
※ Intersection Problem
콘텐츠 기반에서 랑데부 라우팅에서 구독자의 구독정보에 맞는 이벤트가 해당 구독자에게 전달되기 위해서는 구독자 정보와 해당 이벤트 정보가 같은 랑데부 브로커에 있어야한다. 이를 Intersection Problem이라고 한다. 이를 바꿔말하면 말하면 어떤 구독자 s의 정보를 가지고 있는 랑데부 노드의 집합 S와 특정 속성 e를 담당하는 랑데부 노드의 집합 E 간에 교집합이 있어야 된다는 말이다. 이를 Intersection rule이라고 한다.
ⓓ 계층적 라우팅 (Hierarchical)
로컬, 지역, 글로벌 브로커로 계층을 나누어 관리한다. 지역성(Locality)을 활용하여 광역 네트워크(WAN) 트래픽을 줄이는 데 효과적이다.
d. Reliability & Durability
Reliability는 총 3 step으로 나눠서 생각할 수 있다.
ⓐ Publisher -> Broker로 신뢰성있게 전달
Publisher에서 브로커가 이벤트를 받으면 Ack를 전달해줘서 해당 이벤트를 수신했음을 알려준다. 이때 Ack를 전달하는 시점은 아래의 2가지로 나눌 수 있다.
- 브로커가 이벤트를 수신하고 메모리에 수신된 이벤트가 적재된 이후
- 수신된 이벤트가 영속적인 스토리지에 저장된 이후
따로 영속성이 보장된 경우 브로커 서버가 shutdown 된다고 하더라도 이벤트가 소실되지 않으므로 신뢰성은 더 높지만 스토리지까지 저장된뒤에 ACK를 전달하므로 지연시간은 좀 더 높은 편이다.
ⓑ Broker 내에서 신뢰성 유지
브로커 내에서의 신뢰성을 유지하기 위해서는 아래의 2가지를 이용한다.
- 이벤트의 영속적인 저장
- 다중 브로커
브로커가 갑작스럽게 중지되어도 이벤트의 유지를 위해선 영속적인 저장 매체를 통해 이벤트 내용을 저장함으로써 신뢰성을 유지한다. 또한 앞서 설명했듯이 확장성을 위해서 브로커는 하나만 쓰는 것이 아닌 다수의 브로커를 운용하는데 이는 하나의 브로커가 중지되어도 다른 브로커가 서비스를 유지할 수 있게끔 가용성과 신뢰성을 보장해준다.
ⓒ Broker에서 Subscriber로 신뢰성있게 전달
이 경우 브로커가 구독자에게 이벤트를 전달해주면 구독자도 브로커에게 Ack를 전달하는데 이 과정에서 필요한게 Delivery Semantics이다.
e. Delivery Semantics
앞서 메세지 큐에서 설명한 내용과 동일한 내용으로 아래의 세가지로 나뉘며 세부 내용 역시 동일하다.
- At most once
- At least once
- Exactly once
f. Ordering
이 역시 앞서 메세지 큐에서 설명한 내용과 동일한 내용이다.
순서성을 지키는 범위가 중요하며 확장성이 늘어나면 순서성을 지키기 어려워지므로 이 사이에 밸런스를 잡는게 중요하다.
g. Flow Control & Backpressure
Publisher의 이벤트 발생량은 많으나 Subscriber의 이벤트 처리량이 적다면 브로커에 과부하가 생기는데 이를 어떻게 처리해야하는지에 대한 내용이다.
실질적인 내용은 메세지 큐에서 설명한 내용과 동일하다.
Pub/Sub의 가장 대표적인 예시인 Kafka는 이에 대해 다룬 포스팅 카프카 개요 , 카프카 구조 이 있으니 참고하면 된다.
참고자료
- 서강대학교 박성용 교수님 강의자료 - 병렬 분산 컴퓨팅
원문 참고자료들
- G. Coulouria, J. Dollimore, T. Kindberg, and G. Blair, Distributed Systems: Concepts and Design, 5 th Edition, Pearson, 2012, ISBN 978-0-273-76059-7
- M. van Steen and A. S. Tanenbaum, Distributed Systems, 3 rd Edition, 2017
- Martin Kleppmann, Designing Data-Intensive Applications, 1 st Edition, O’Reilly Media, 2017, ISBN 978-1491903070 (또는 2nd Edition in February 2026)