병렬분산컴퓨팅 - 분산 시스템 - Synchronization and Coordination
분산 시스템 - Synchronization and Coordination
1. Synchronization and Coordination 이 필요한 이유
앞서 했던 포스팅에서 분산 시스템을 제대로 구현하기 어려운 이유는 아래의 세가지 이유가 있다 했다.
- 각 Node 별 정확한 시간을 맞출 수 없다.
- 네트워크 자체가 신뢰하기 어렵다. (여러가지 이유로 단기 혹은 장기로 지연되거나 끊기거나 보낸 순서와 받은 순서가 일치하지 않을 수 있음)
- 다른 노드 간에 동시에 프로세스가 실행되는데 순서에 대한 보장이 어렵다.
위와 같은 분산시스템의 어려움은 사실상 아래의 3가지를 유지하기 어렵다는 사실로 환원이 가능하다.
- 서로 다른 노드 간에서 발생한 이벤트간 순서 맞춤
- 복제본 간의 일관성 유지 (같은 순서의 명령어 및 작업을 보장해야 일관성이 유지됨)
- 서로 다른 노드가 동일한 공유 자원 접근시 발생할 수 있는 충돌 회피
위와 같은 3가지 내용은 동기화와 조정(Synchronization and Coordination)이 필요하다는 이유가 된다.
2. 시간과 이벤트 순서
1) 순서가 중요한 이유
아래의 세 가지 이유로 인해서 순서는 매우 중요하다.
A. 사용자 경험
순서가 지켜지지 않는다면 순차적으로 나타나야할 것들의 순서가 뒤바뀌어서 나타날 수 있다(ex - 댓글과 대댓글의 순서, 게시판 글 번호 순서 역전)
이런 문제가 발생하면 사용자 경험에 혼란이 생긴다.
B. 응용 정확성
만약 어떤 파일을 생성 후에 삭제를 요청했다고 해보자.
하지만 요청의 순서가 바뀌어버리는 바람에 삭제 처리 후(없으니까 삭제 처리는 안됨)에 생성이 되었다고 할때 원래대로라면 삭제되어 없어져야할 파일이지만 생성이 마지막에 되어버렸으므로 결과가 동일하지 않다.
이는 응용 프로그램의 최종 결과의 정확성을 해치게 된다.
C. 복제본 일관성
어떤 DB의 가용성을 위해 복제본으로 운용하고 있다고 해보자. Write와 Read를 담당하는 Primary Node와 Read를 담당하는 Secondary Node 1과 2 이렇게 총 3개의 복제본 노드가 있다고 해보자. Primary Node에서 Secondary Node 1과 2로 X라는 값을 1로 변경하라고 하고, 이후에 2로 변경하라고 했을 때
Node 1은 X를 1로 변경,X를 2로 변경 순으로 전달받았지만 Node 2가 X를 2로 변경,X를 1로 변경 순으로 전달 받은 경우 Node 1과 2의 데이터 일관성을 깨지기 때문에 사용할 수 없게 된다.
2) 물리적 시간 동기화
정말로 물리적 시간을 맞출순 없을까? 이러한 여러 노력이 있었고, 그래도 시간 자체는 비슷해야하기에 아래와 같은 방법들을 사용한다.
A. 물리 시간 동기화가 힘든 이유
Clock drift라는 현상때문이다. 모든 Node는 각기 물리적인 Clock을 이용해서 시간을 측정하는데 이 Clock들은 하드웨어 문제로 인해
시간이 흐르는 정도가 완벽하게 동일하지 않다. 이로 인해 각기 Node의 Local time들이 틀어지기 시작한다.
B. 발생하는 문제점
타임스탬프의 일관성 유지가 어려움
동일한 시점에 발생한 이벤트라도 서버마다 Local time이 다르기 때문에 기록되는 시가이 달라진다.이벤트 순서의 오류
물리적 시간이 Node마다 다르기 때문에 다른 서버에서 전달받은 이벤트의 timestamp가 현재 서버의 timestamp보다 빠르다고 먼저 발생한 이벤트라고 단정지을 수 없다.
C. 물리 시간 동기화 하는법
- NTP (Network Time Protocol)
- 소프트웨어 기반
- 인터넷을 통해 동기화 된다
- 밀리초 단위의 정확도가 보장된다
- PTP (Precision Time Protocol)
- 하드웨어의 도움으로 유지된다.
- 데이터센터나 산업 시스템에서 사용된다.
- 마이크로초 단위의 정확도가 보장된다.
- GPS Clock
- 전역적인 위치를 위한 시스템이다.
- 높은 정확도의 시간이 제공된다.
- 제일 상위 소스 시간으로 사용된다.
D. 물리 시간 동기화시 이벤트 순서를 맞출 수 있는가?
물리 시간이 완전히 동일하다고 해도 이벤트 순서를 단정 지을 순 없다. 총 아래의 4가지 이유때문이다.
- 예측 불가한 네트워크 딜레이
- 변동하는 클럭 동기화 에러
- 동일한 Timestamp가 인과 순서를 보장하진 않음
- 동시에 발생한 이벤트의 경우 순서가 어떻게 될지 모름
3) Happen-before Relation
분산 시스템에서 Happened-before 관계는 이벤트 간의 인과 관계(Causality)를 파악하고 논리적인 순서를 정하기 위해 사용되는 핵심 개념이다.
이벤트의 간의 상관관계를 통해 선후 관계를 추론하기 위해 사용한다.
A. Happend-before rule
Happen-before Relation를 나타내기 위한 룰은 아래와 같다.
- 로컬 순서 (Local Order): 동일한 프로세스 내에서 발생한 두 이벤트 A와 B에 대해, A가 B보다 먼저 실행되었다면 A→B로 표현할 수 있다.
- 메시지 순서 (Message Order): 이벤트 A가 메시지를 보내는 행위이고, 이벤트 B가 그 메시지를 받는 행위라면 A→B로 표현할 수 있다.
- 추이성 (Transitivity): 만약 A→B이고 B→C라면, A→C가 성립한다.
만약 어떤 이벤트 A,B 사이에 위 3가지에 해당하는게 하나도 없다면 둘 관계는 Concurrent Relation이라고 하며 A||B 로 표현할 수 있다.
B. 예시
아래의 그림을 보자.
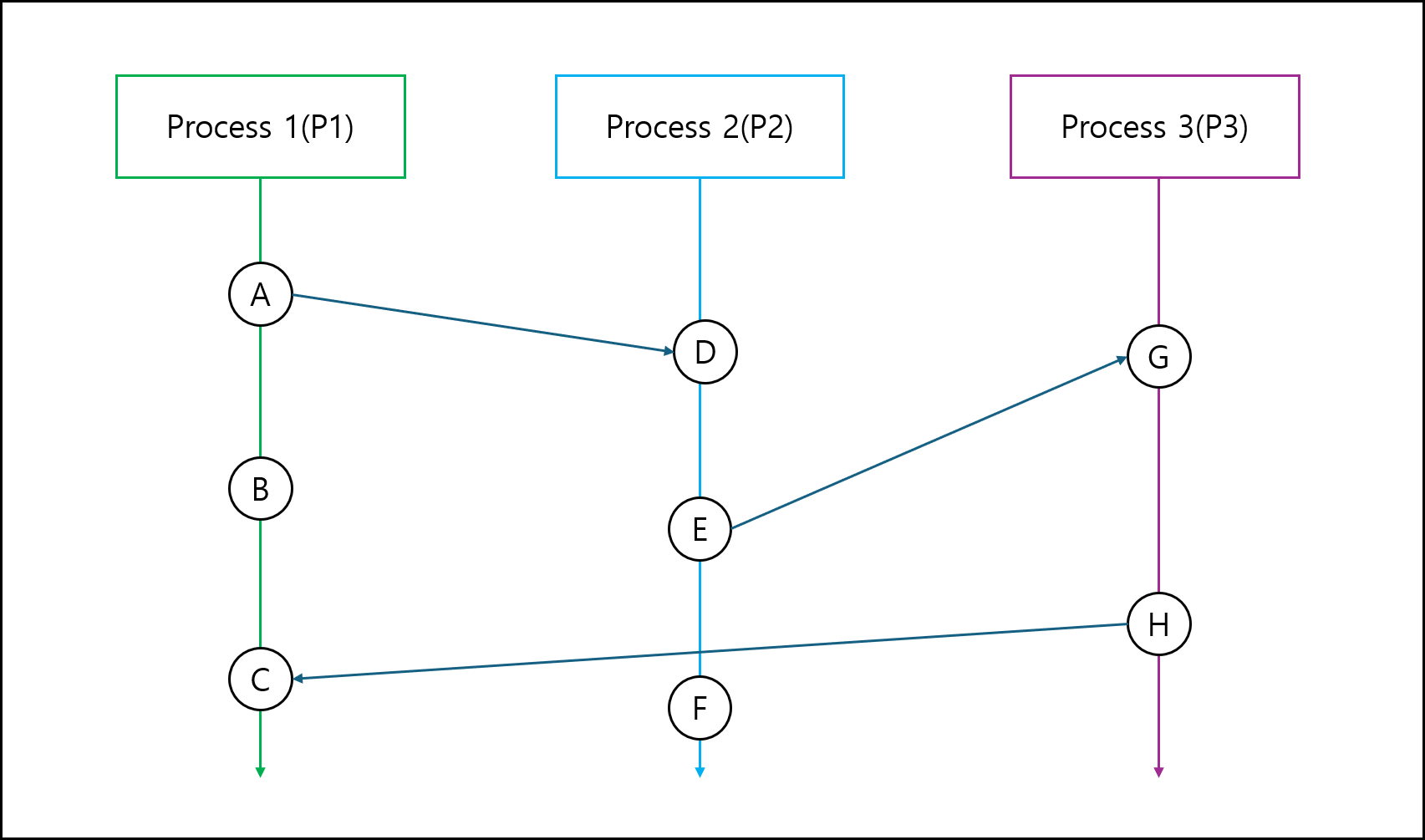
각 프로세스 P1, P2, P3가 있고 이벤트 A~H이며, 각 이벤트에 연결된 화살표의 경우 시작점 프로세스에서 도착점 프로세스로 데이터를 받아서 처리하는 것이라고 해보자. 그러면 아래의 관계로 표현 할 수 있다.
- Happend-before
1 2 3 4 5 6 7 8
A→B→C (동일 프로세스) D→E→F (동일 프로세스) G→H (동일 프로세스) A→D (P1 -> P2 메세지 전달) E→G (P2 -> P3 메세지 전달) H→C (P3 -> P1 메세지 전달) A→D→E→G (추이성) A→D→E→G→H→C (추이성)
- Concurrent
1 2 3 4 5
B || D C || D F || H B || E F || G
B. Lamport Logical Clock
앞서 설명한 Happend-before 관계를 기반으로 논리적 순서를 정한 것이다. 각 프로세스 P에 대해서 논리적 클럭을 $LC_{P}$ 라고 할때 $LC_{P}$ 는 아래의 알고리즘에 따라 정해진다.
a. Lamport Logical Clock 구현
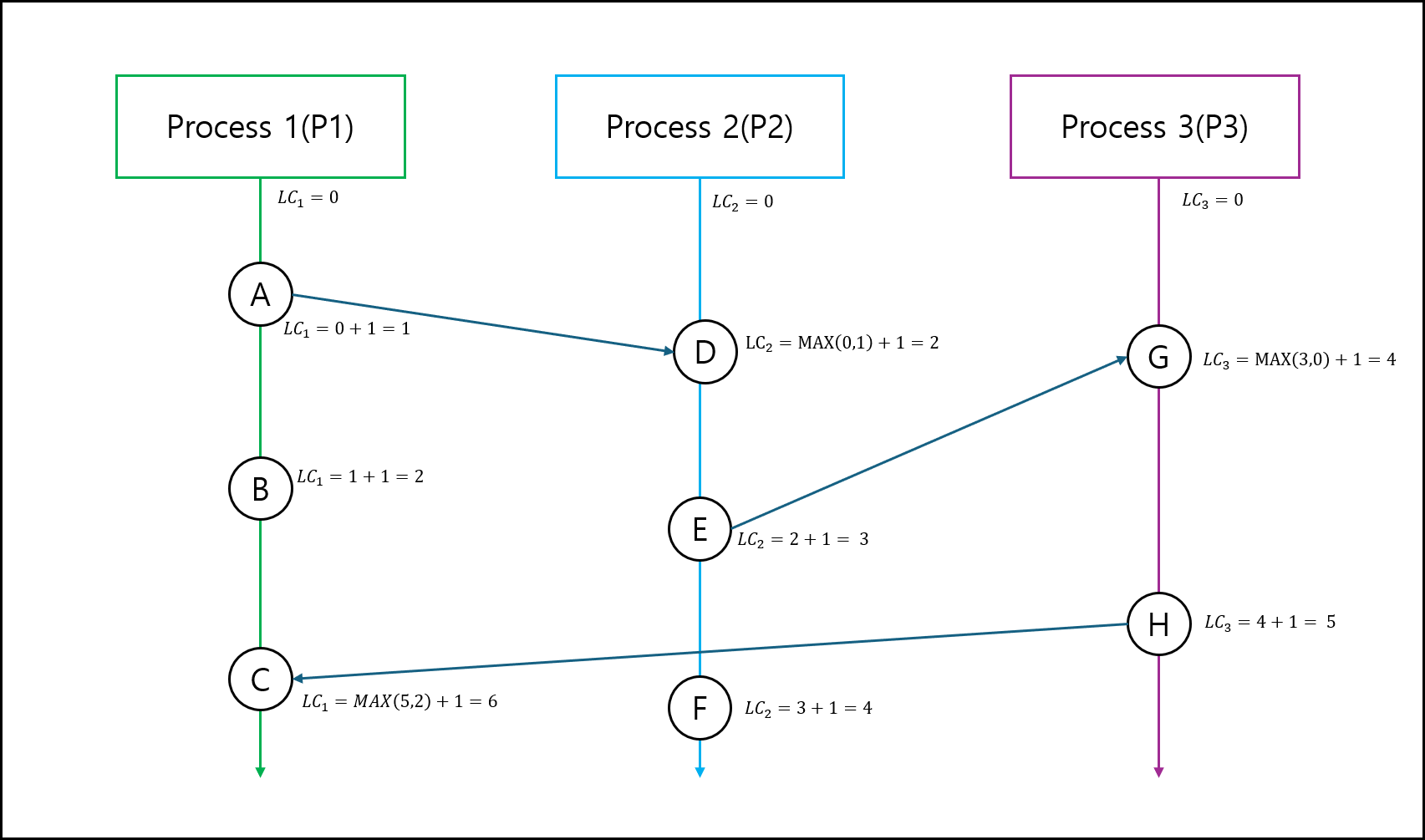
- 모든 프로세스는 $LC_{P} = 0$ 으로 초기화한다.
- 각 프로세스에서 전송이 동반하지 않은 이벤트가 발생한 경우 $LC_{P}$ 에 1을 추가한다.
- 다른 프로세스로 전송 이벤트 발생시 이전의 $LC_{P}$ 에서 1을 추가하여 메세지에 추가하여 보낸다.
- 다른 프로세스에서 이벤트를 수신 할 시 이전의 $LC_{P}$ 와 수신 받은 메세지 포함된 $LC_{P}$ 중에 큰 것을 골라서 1을 추가하여 유지한다.
Happen-before Relation에서 설명했던 예시를 가지고 Lamport Logical Clock을 그려보면 아래와 같다.
b. Lamport Logical Clock을 쓰는 곳
아래와 같은 두 개의 예시를 들 수 있다.
분산 로그
Kafka의 경우 각 parttion 내에서의 순서만 보장하므로 Lamport clock이 적당하다.분산 데이터 베이스
각 트랜잭션은 순서가 중요하므로 Lamport clock을 사용하면 순서에 논리적 순서에 따른 일관성이 보장된다.
c. Lamport Logical Clock의 한계
어떤 프로세스 1의 이벤트 시점 A와 프로세스 2의 이벤트 시점 B가 있을 때 A와 B가 Happend-before 관계가 있고 LC가 A가 B보다 작으면 A는 B와 인과관계가 있다고 할 수 있다. 하지만 반대로 LC(A) < LC(B)일때, A는 B와 인과관계가 있는가?는 보장할 수 없다.
둘 사이에 Happend-before 관계인지 혹은 Concurrent 한 관계인지 알수가 없기 때문이다.
따라서 LC에 대한 정보가 있다고 한들 두 시점의 관계를 알 수가 없다면 사용하기 어렵다.
C. Vector Clock
Lamport Clock은 스칼라 값 하나만으로 계산한다면 Vector Clock은 프로세스 수만큼의 차원을 가진 Vector 값을 가지고 계산하는 방법이다.
이전에 Happend-before 관계인지 아닌지 계산할 수 없었던 Lamport Clock의 약점을 보완해서 나온 것이다.
프로세스 P1~P3까지 있다고 할때 Vector Clock을 구하는 방법은 아래와 같다.
- 먼저 각 Vector clock을 프로세스 수만큼 차원을 확보한뒤 0으로 초기화 한다.
ex) 3개 프로세스이므로 [0,0,0] = $\left[ P_{1},P_{2},P_{3} \right]$ - 각 프로세스에서 전송이 동반하지 않은 이벤트가 발생한 경우 해당 프로세스 차원 값에 1을 추가한다.
ex) 원래 값 $\left[ 0,0,0 \right]$ 에서 P1에서 발생시 $\left[ 1,0,0 \right]$ - 다른 프로세스로 전송 이벤트 발생시 이전의 해당 프로세스 차원 값에 1을 추가하여 메세지에 포함하여 보낸다.
ex) 원래 값 $\left[ 0,0,0 \right]$ 에서 P1에서 송신시 $\left[ 1,0,0 \right]$ - 다른 프로세스에서 이벤트를 수신 할 시 받은 Vector Clock 값과 원래 가지고 있던 Vector Clock 값을 비교하여 각 원소의 Max값을 취한 후 받은 프로세스 위치의 값을 1 더해줌
ex) 원래 값 $\left[ 1,1,3 \right]$ 에서 P2가 P1으로부터 메세지를 받았을때 메세지에 Vector Clock $\left[ 4,2,1 \right]$ 가 포함되어있다면 각 원소의 최대값을 취해서 Vector Clock을 새로 만든 뒤 수신 프로세스 위치의 원소를 1 증가시키킨다. $\left[ 4,3,3 \right]$
위 Vector Clock를 구하는 방식을 앞서 설명했던 Happen-before Relation에서 설명했던 예시로 그려보겠다.
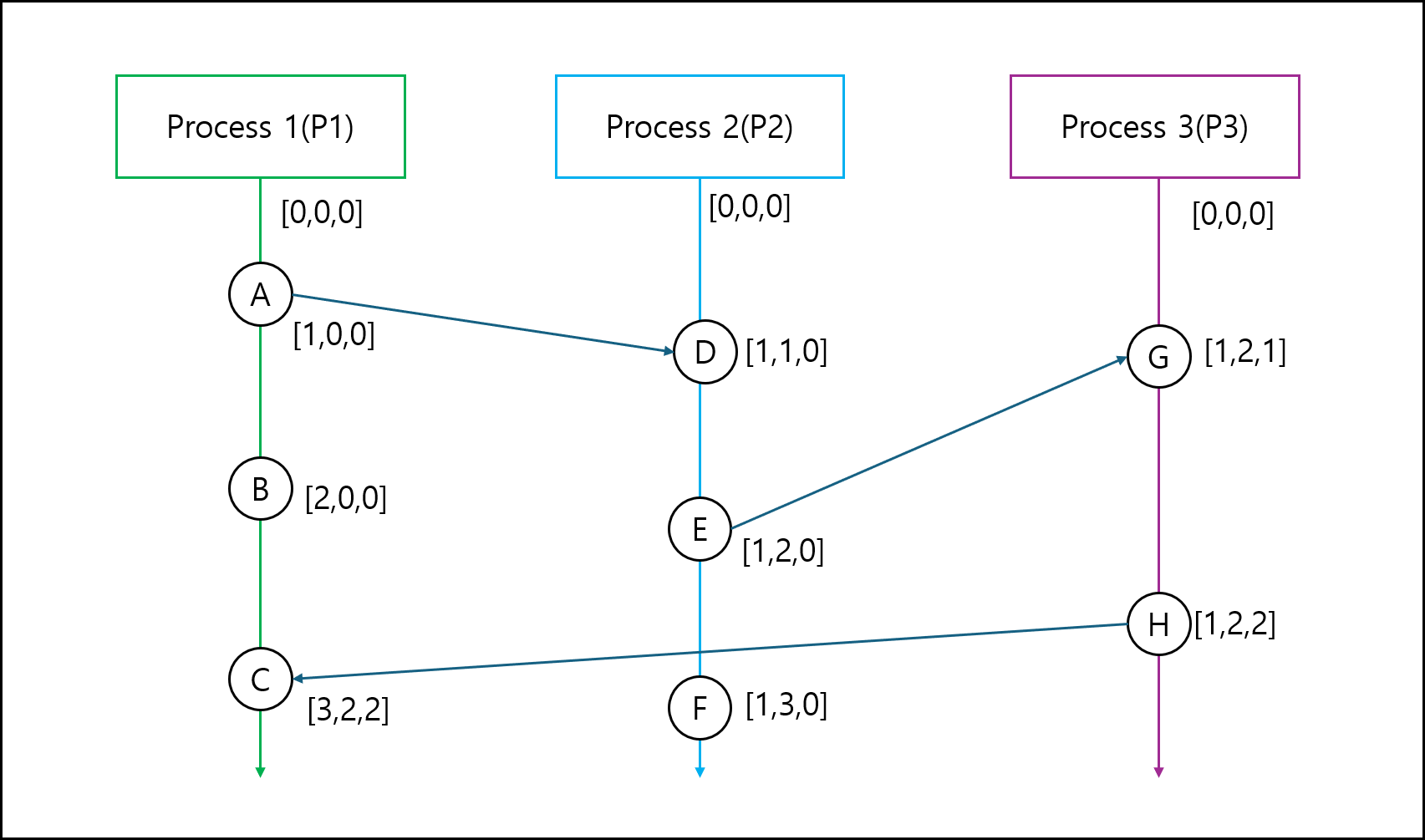
이러한 Vector Clock의 좋은 점은 서로 다른 Vector Clock 값을 가지고 두 이벤트 지점이 서로 Happen-before Relation이 있는지 확인할 수 있다는 점이다.
가령 A와 F를 보자 A는 $\left[ 1,0,0 \right]$ , F는 $\left[ 1,3,0 \right]$ 이다. 둘 간의 Happen-before Relation이 있는지 확인하고 싶다면
A의 F의 Vector Clock의 각 원소의 크기를 비교하면 된다. A의 모든 원소는 F보다 작다. 그러면 A->F 관계가 성립하는 것이다.
2. 메세지 순서(Message Ordering)
어떤 프로세스에서 다른 다수의 프로세스들에게서 메세지를 받았다고 해보자. 앞서 설명한 바와 같이 신뢰성이 낮은 네트워크 환경과
Global clock의 부재로 인해 해당 메세지들의 순서는 받는 순서라고 보기 어려울수도 있다.
때문에 메세지를 받은 프로세스에서 메세지의 순서를 재정렬할 필요가 있을 수 있다.
이때 순서를 정하는 방식은 크게 3가지가 있다.
1) FIFO Ordering
각 프로세스에서 전달하는 순서만 지켜주는 방식이다.
아래의 그림을 보자.
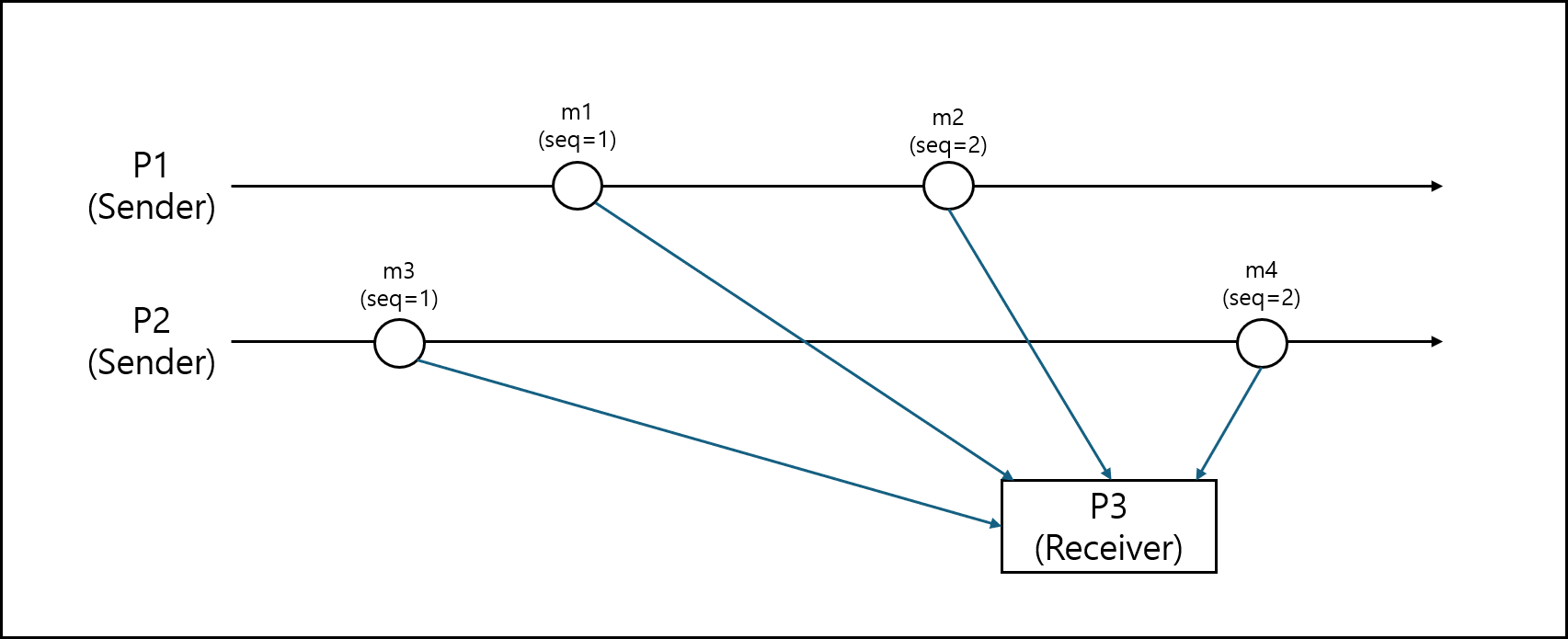
P1에서 m1과 m2를 P2에서 m3와 m4를 P3에게 전달하고 있다.
이를 FIFO 방식으로 정렬하면 아래와 같이 정렬 할 수 있다.
- m1->m2->m3->m4
- m1->m3->m2->m4
- m3->m1->m2->m4
- m1->m3->m4->m2
말 그대로 P1에서 전송한 메세지인 m1과 m2의 순서와, P2에서 전송한 메세지인 m3, m4의 순서만 지켜지면 되기 때문이다.
이러한 방식을 구현할때는 보내는 프로세스에서 Sequence Number가 유지하여 메세지에 포함해주면 되므로 Lamport clock이나 Vector clock이 필요없다.
2) Causal Ordering
인과 관계의 순서를 지켜주는 방식이다. 이 방식은 기본적으로 FIFO는 유지하되 인과 관계까지 지켜주는 방식이라 생각하면 된다. 아래의 그림을 보자.
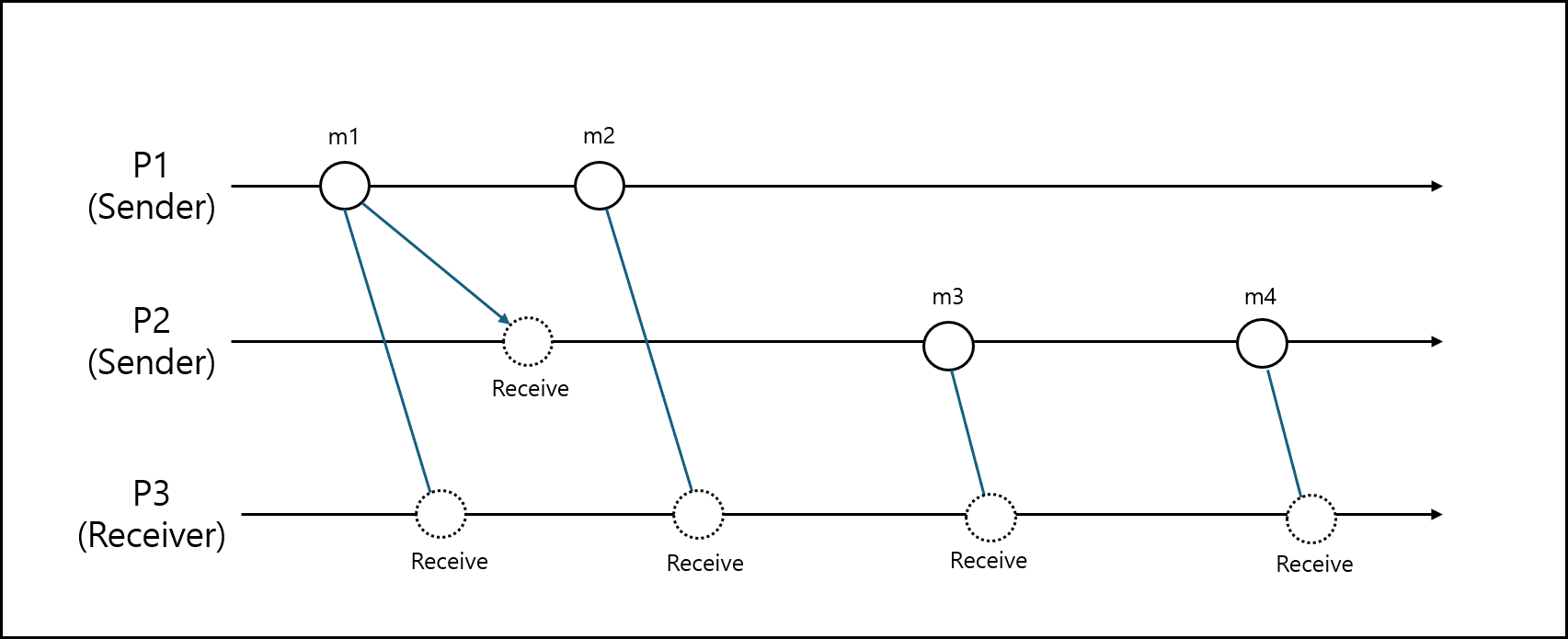
이번 예시에는 인과 관계가 추가되었다. P1에서 전달한 메세지 m1이 P3뿐만 아니라 P2에도 전달되었다.
이 경우 FIFO 방식이라면 m1과 m2, m3와 m4의 순서만 지켜주면 되겠지만 Causal Ordering은 인과 관계도 지켜주어야한다.
따라서 m1 다음에 m3 그 다음에 m4까지 지켜주어야한다.
따라서 가능한 순서는 아래와 같다.
- m1->m2->m3->m4
- m1->m3->m2->m4
- m1->m3->m4->m2
인과 관계를 확인할 수 있어야하므로 이를 구현할때는 Vector Clock을 유지한다.
※ FIFO -> Causal Ordering?
Causal Ordering -> FIFO는 맞지만, 역은 성립하지 않는다.
즉 FIFO Ordering이라고 Causal Ordering은 아니라는 말이다.
앞서 Causal Ordering를 설명했던 예시에서 아래의 순서를 보자.
- m3->m1->m2->m4
P1에서 m1과 m2, P2에서 m3와 m4의 FIFO 순서는 지켜졌지만 정작 m1->m3->m4와 같은 Causal Ordering은 지켜지지 않았다.
따라서 FIFO Ordering -> Causal Ordering 은 성립하지 않는다.
3) Total Ordering
다수의 Receiver가 있다고 할 때 모든 Receiver가 동일한 순서로 메세지를 정렬했다면 이를 Total Ordering이라고 한다.
FIFO Ordering 일 필요도 Causal Ordering 도 없이 말 그대로 모든 Receiver가 동일한 순서로 메세지를 정렬했을때를 말한다.
하지만 그렇게 되서야 쓰는 의미가 없다. 따라서 이 Total Ordering에는 두 가지 방식으로 구현한다. 먼저 아래의 그림을 보자.
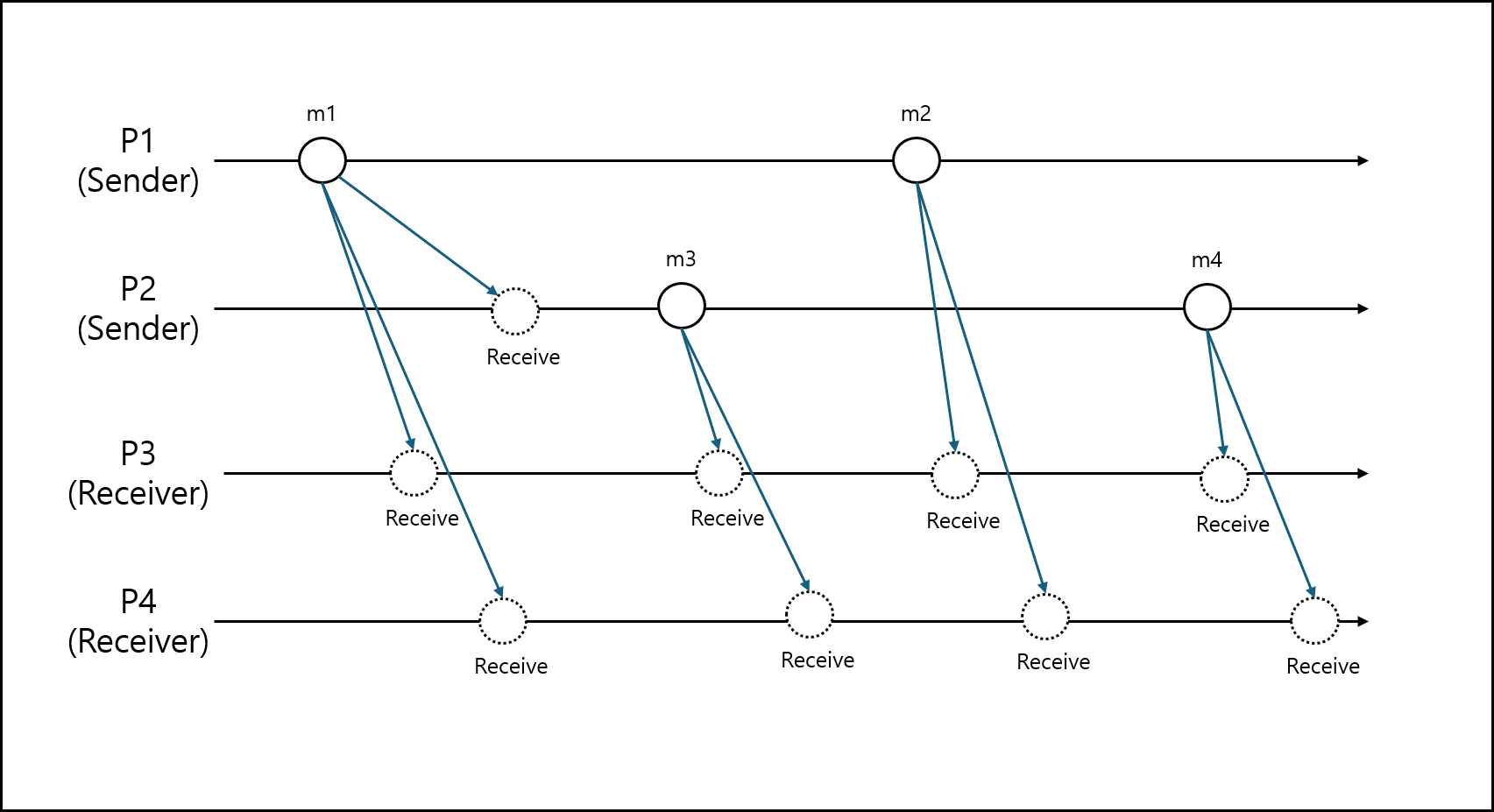
인과 관계가 있는 메세지이며 수신자는 P3와 P4이다. 이를 두 가지 방식에 따라서 설명해보겠다.
A. Total Ordering(FIFO)
모든 Receiver에서 정렬한 순서가 FIFO 방식과 동일하다.
P3와 P4에서 수신한 메세지들이 동일한 Order를 유지하되 순서가 FIFO면 되는 것이다.
아래의 순서가 가능하다.
- m1->m2->m3->m4
- m1->m3->m2->m4
- m3->m1->m2->m4
- m3->m4->m1->m2
B. Total Ordering(Causal)
모든 Receiver에서 정렬한 순서가 Causal Ordering 방식과 동일하다. P3와 P4에서 수신한 메세지들이 동일한 Order를 유지하되 순서가 Causal Ordering면 되는 것이다. 아래의 순서가 가능하다.
- m1->m2->m3->m4
- m1->m3->m2->m4
※ 각 방식의 사용하는 예시
FIFO
Kafka에서 각 파티션 내에서 순서를 보장할때 사용Causal Ordering
구글 docs나 CRDTTotal Ordering
Key-value 저장소나 복제본 데이터 베이스
3. 분산상호배제(Distributed Mutual Exclusion)
분산 환경에서 다수의 노드간에 공유 자원에 접근할 때 어떤식으로 상호 배제를 지켜서 데이터 작업의 일관성을 지킬지에 대한 내용이다.
1) 상호배제 알고리즘 요구사항
이러한 상호배제를 구현하기 위한 알고리즘은 아래의 3가지의 요소를 지켜야한다.
A. Safety
임계구역에 한번에 한 프로세스만 접근하게 제어됨
B. Liveness
데드락이 발생하지 않기 때문에 무한 대기가 없음, 때문에 언젠가 진행이 보장됨
C. Fairness
한 프로세스가 lock을 공정하게 제공받지 못해서 starvation이 생기는일이 없음
2) 성능 지표
A. Message per CS Entry (Total Message Cost)
어떤 프로세스가 임계 구역에 접근할 때 발생하는 총 메세지의 개수
여기서 말하는 메세지는 요청, 응답, 승인, 해제, 토큰 전달 등등 모든 이벤트를 말한다.
바꿔서 말하자면 임계 구역 한번 접근당 발생하는 네트워크 트래픽양으로 말할 수 있다.
이 트래픽이 크다면 네트워크 대역폭에 부하를 줘서 좋지 않으며 확장성과도 관련이 있다.
B. Entry Delay (Request to Enter Delay)
어떤 프로세스에서 임계 구역 접근을 요청하고 난 뒤에 실질적으로 임계 구역을 접근하기까지의 시간을 말한다.
요청 후에 얼마나 빠른 시간내에 임계 구역에 접근 할 수 있는지를 나타내기 때문에 중요한 지표이다.
C. Synchronization Delay (Handover Delay)
임계 구역에 접근하여 작업하고 난 프로세스가 자원 점유를 풀고, 그 다음에 임계 구역 접근을 요청한 프로세스가 임계구역에 접근하기 까지의 시간을 말한다. 시스템 오버헤드와 조정 지연이 포함되며, 전체 시스템의 처리량(Throughput)과 자원 활용도에 직접적인 영향을 미친다.
D. Fairness
프로세스들의 요청이 공정한 방식(FIFO, Timestamp 등)으로 처리되어 기아(Starvation) 상태에 빠지는 프로세스가 없는지 측정하는 것이다.
E. Scalability
프로세스 수(N)가 늘어날 수록 지표(메시지 비용, 지연시간) 등이 어떻게 증가하는지를 나타낸다.
시스템 규모가 커질 때 해당 알고리즘이 얼마나 잘 작동하는지를 보여주는 지표이다.
F. Fault Tolerance / Robustness
장애(프로세스 충돌, 메세지 유실, 토큰 분실)가 발생했을 때 알고리즘이 어떻게 대처하는지를 평가한다.
실제 분산환경에서 신뢰성과 가용성을 결정짓는다.
3) 알고리즘 1 : 중앙화(Centralized)
모든 프로세스가 임계구역에 접근하고 싶을 때 Lock manager에게 요청 후 lock을 받아 접근하는 방식.
Lock manager는 각 프로세스에서 요청을 수신하면 FIFO Queue에 넣고 순차적으로 Lock을 제공한다.
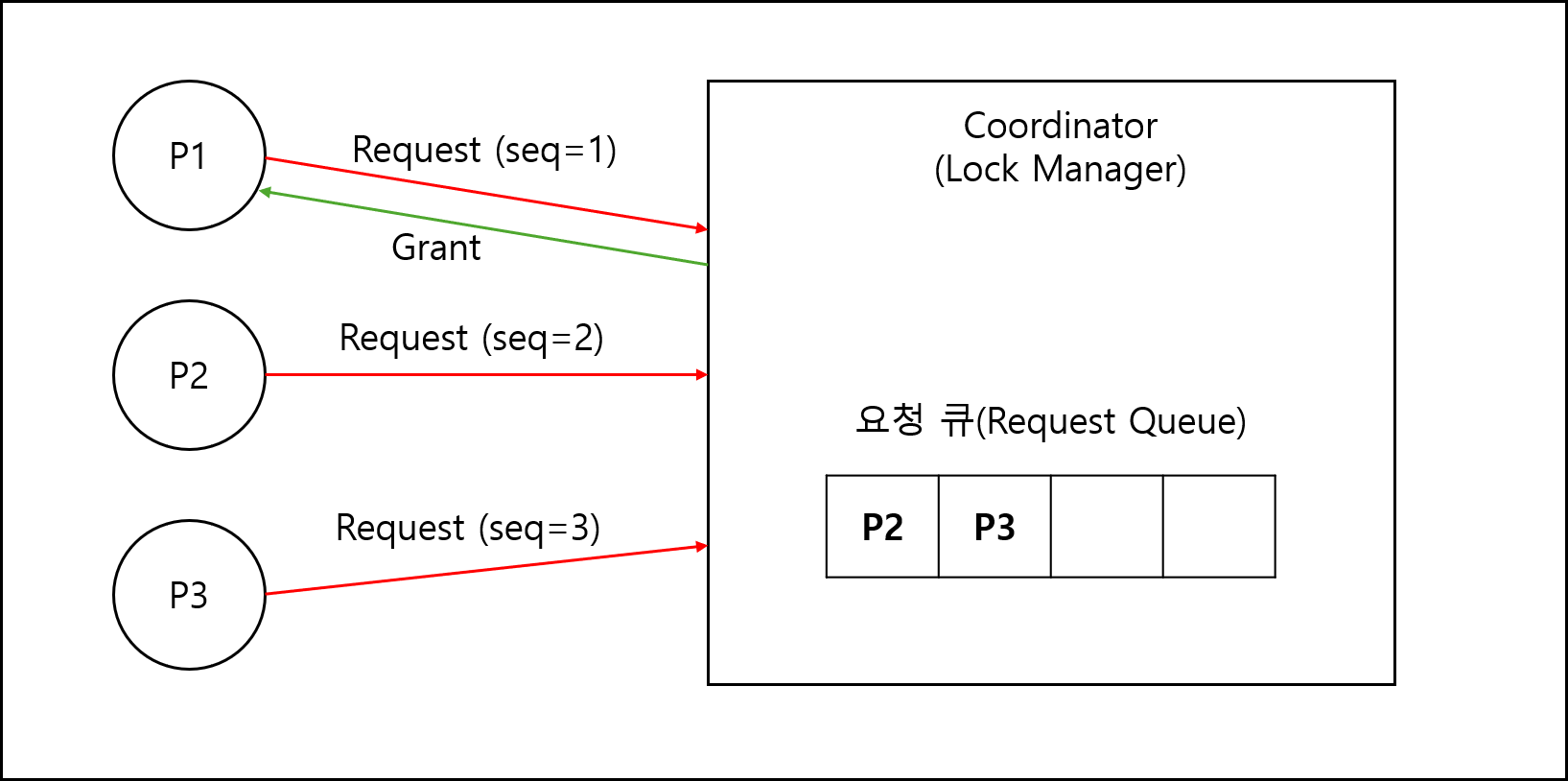
4) 알고리즘 2 : 토큰 기반(Token-Based, Token Ring)
모든 프로세스가 Ring과 같이 연결되어 Ring을 순환하여 Token이 전달되고, 프로세스는 Token을 갖고 있을 때만 임계구역에 접근 가능한 방식.
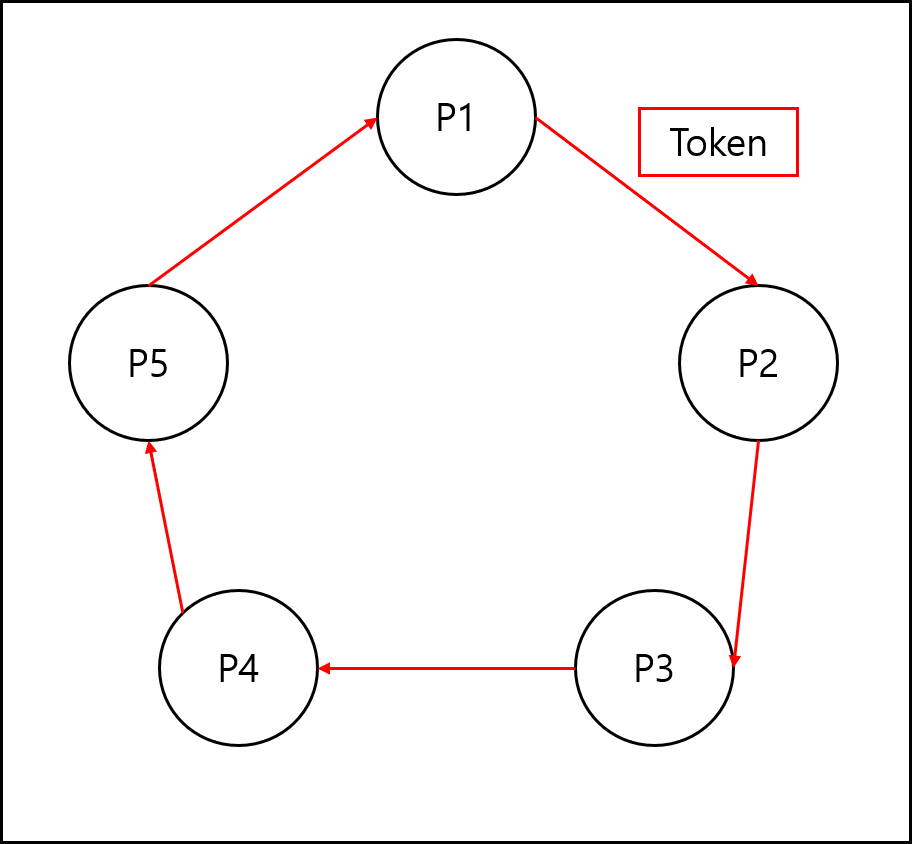
위와 같이 토큰 링 형태로 구성하면 해당 프로세스가 어느시점쯤에 임계 구역에 접근할 수 있게 될지 어느정도 예측이 가능하게 된다.
물론 프로세스가 임계구역에서 작업 가능한 최대 시간을 지정해주어야하지만, 어느정도 예측가능하다는 장점이 있으며
만약 특정 프로세스가 임계구역에서 접근을 많이해야하고 다른 프로세스에서는 상대적으로 적을때 임계구역에 접근을 많이해야하는 프로세스에 Token 할당을 상대적으로 많이 해줌으로써 Fairness를 약간 희생하고 성능을 올릴 수도 있다.
5) 알고리즘 3 : 허가 기반(Permission-Based, Ricart-Agrawala)
임계구역에 접근하고자하는 프로세스는 다른 모든 프로세스에게 임계구역에게 접근해도 되는지 확인 요청을 보낸다. 요청을 받은 프로세스는 자신이 임계구역에 접근하지 않고 있을 경우 요청한 프로세스에게 접근 가능하다고 응답을 보낸다.
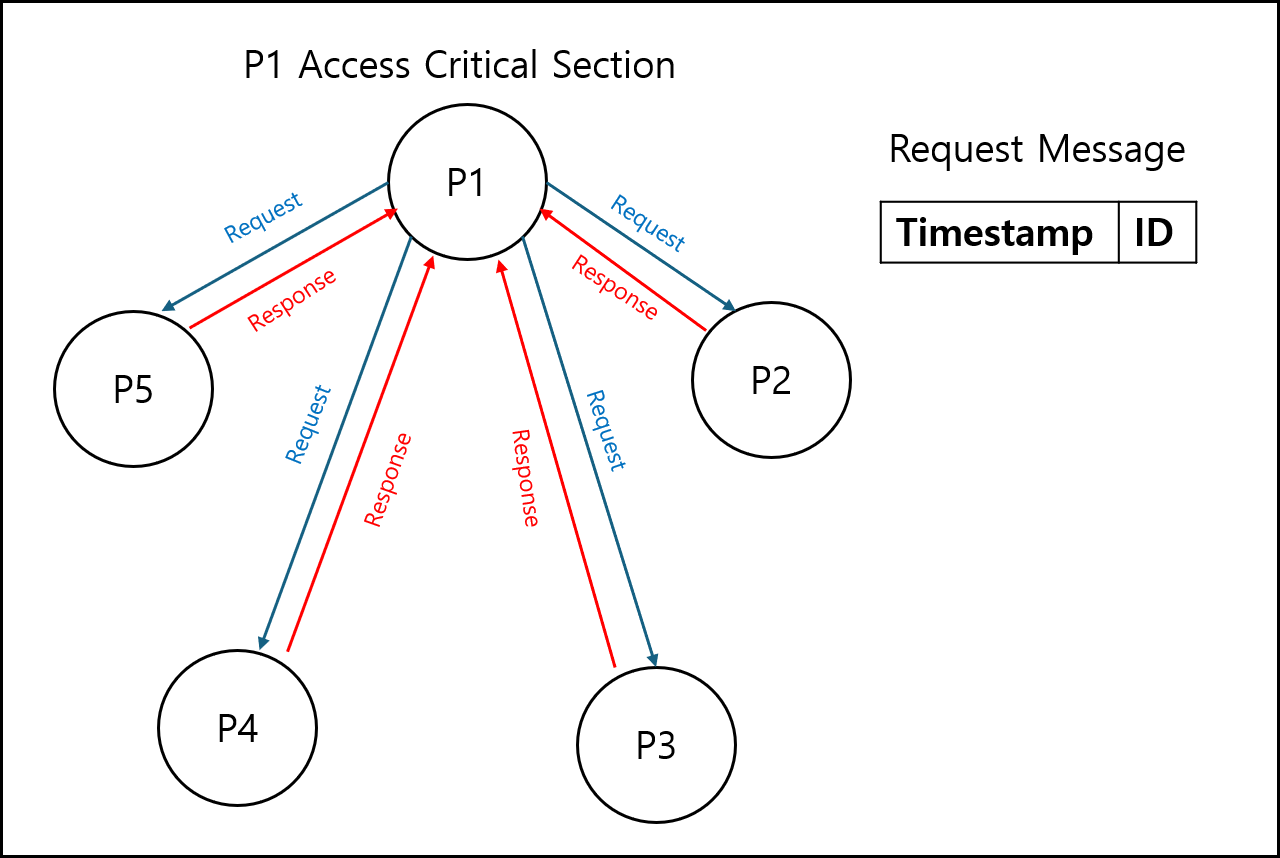
만약 아래와 같이 프로세스 1이 다른 노드들에게 임계구역 접근 요청을 했는데, 프로세스 2 역시 임계 구역 접근 요청을 하게 되면 어떻게 될까?
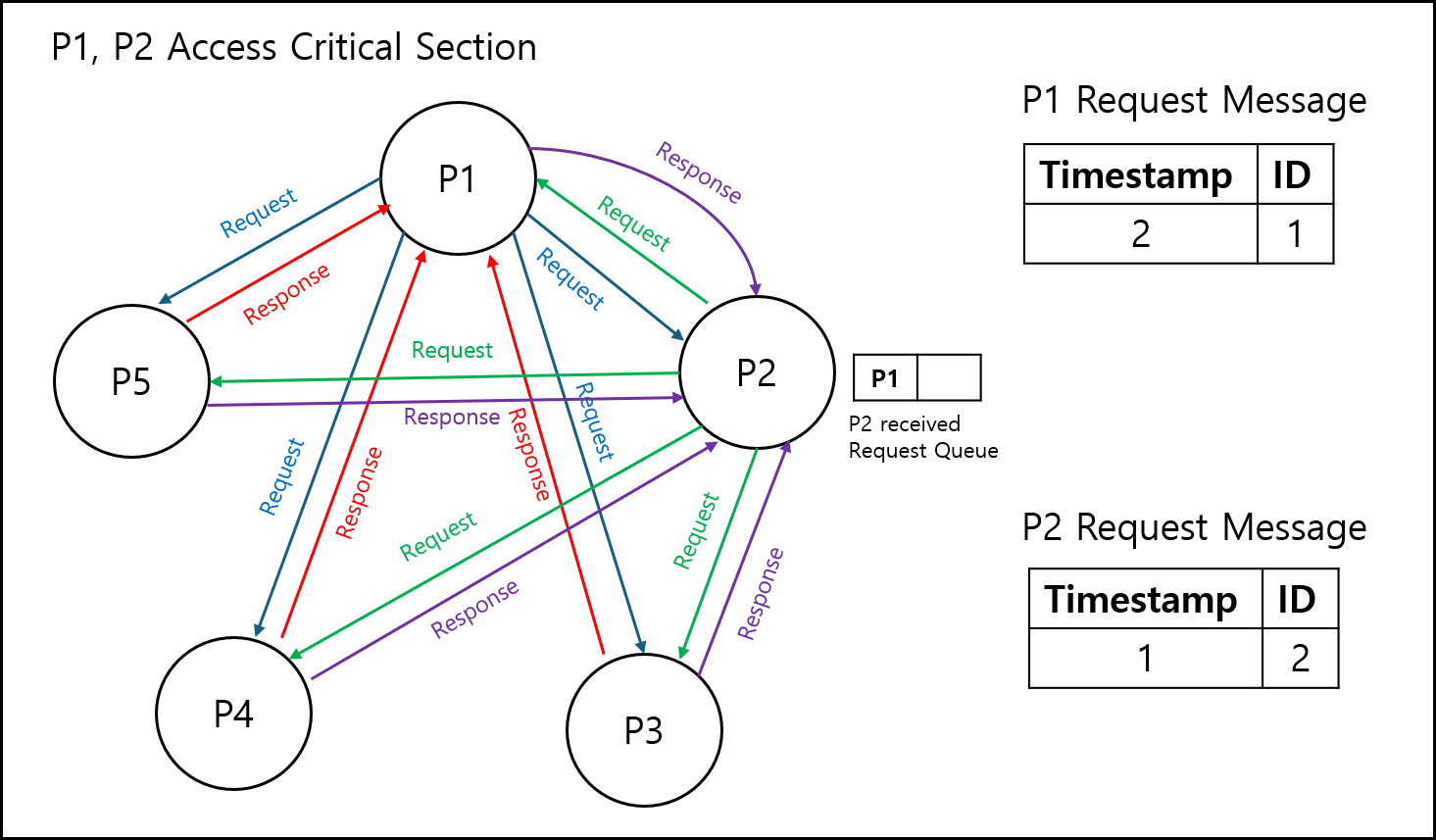
먼저 프로세스 1은 다른 프로세스에게 요청을 보낸다. 그리고 프로세스 2 역시 다른 프로세스에게 요청을 보낸다. 프로세스 1과 2를 제외한 다른 프로세스는 둘 다에게 접근 가능 응답을 보낸다.
여기서 결정해야할게 프로세스 1과 프로세스 2 중에 누가 먼저 접근할 것인가에 대한 내용이다.
각 프로세스는 다른 프로세스에게 요청을 보낼때 Lamport clock과 같은 논리적인 Timestamp와 자신의 ID를 포함하여 전달한다.
이 경우 프로세스 1과 프로세스 2가 서로의 응답을 기다리는 상황이 될 시에 그림에서와 같이 프로세스 1보다 프로세스 2의 Timestamp가 작은 경우 프로세스 2가 먼저 접근 권한을 갖게 된다. 따라서 프로세스 1은 자신의 순위가 뒤쳐지는 것을 계산하고 프로세스 2에게 접근 가능 응답을 보낸다. 프로세스 2의 경우 자신의 순서가 먼저인 것을 확인하고 프로세스 1에게 받은 요청을 Queue에 넣어둔다 이후 임계 구역에 접근하여 작업을 했다면 Queue에 넣어둔 프로세스 1의 요청을 꺼내어 응답한다. 그러면 프로세스 1은 임계 구역에 접근이 가능하게 된다.
※ Timestamp가 동일할 경우?
만약에 프로세스 간 요청이 겹칠 경우 Timestamp가 다르다면 작은 것에 권한을 먼저 주면 되지만 Timestamp가 동일하다면 어떻게 해야할까? 이 경우 ID 값을 사용한다. 이 ID 값은 프로세스 각자 고유한 번호로 작은 ID가 우선 순위를 갖게 된다.
참고자료
- 서강대학교 박성용 교수님 강의자료 - 병렬 분산 컴퓨팅
원문 참고자료들
- G. Coulouria, J. Dollimore, T. Kindberg, and G. Blair, Distributed Systems: Concepts and Design, 5 th Edition, Pearson, 2012, ISBN 978-0-273-76059-7
- M. van Steen and A. S. Tanenbaum, Distributed Systems, 3 rd Edition, 2017
- Martin Kleppmann, Designing Data-Intensive Applications, 1 st Edition, O’Reilly Media, 2017, ISBN 978-1491903070 (또는 2nd Edition in February 2026)