컴퓨터 구조 - 메모리 구조
메모리 구조
어떤 종류의 컴퓨터이든 간에 컴퓨터는 어떤 정보를 연산 한 뒤에 저장할 공간이 필요하다.
이를 메모리라고 한다. 현대 컴퓨터에서 메모리라고하면 주 기억장치인 DRAM을 대부분 말한다. 이번 포스팅에서는 DRAM과 SRAM 약간에 대해서 알아보도록 하겠다.
1. 개요
흔히들 메모리라고하면 크게 종류가 두 개이다. 바로 DRAM과 SRAM인데, 이는 구성요소가 다르고 성능이 다르다.
1) SRAM(Static Random Access Memory)
플립플롭으로 이루어진 메모리이다. 두 개의 not gate로 이루어져있으며 bitline 쪽에 1이 들어가면 $ \overline{bitline} $ 쪽에는 0, 반대의 경우에도 서로 NOT이 인가되는 구조이다.
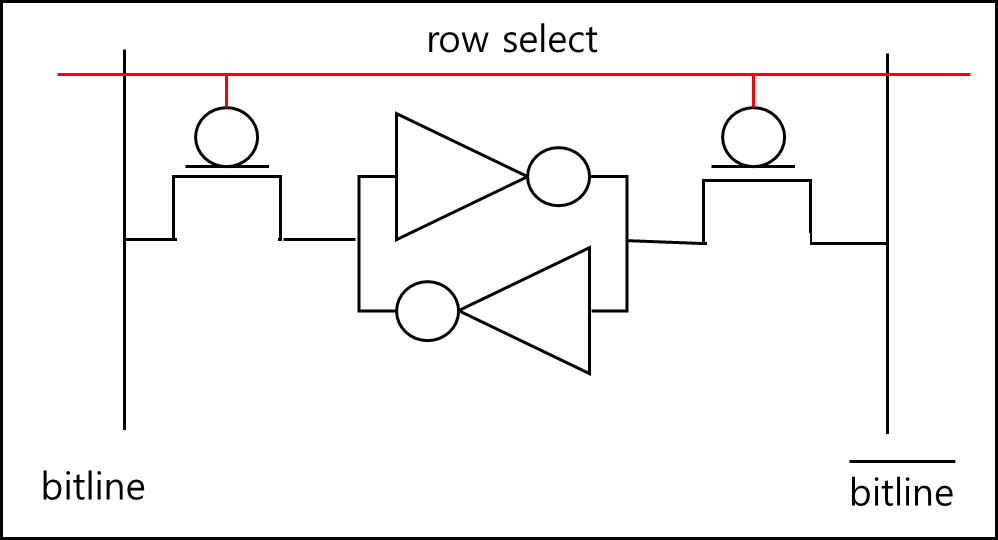
이렇게 셀 하나의 구조와 위와 같고 위 같은 셀들을 아래와 같이 2차원 Array 구조로 나열한다.
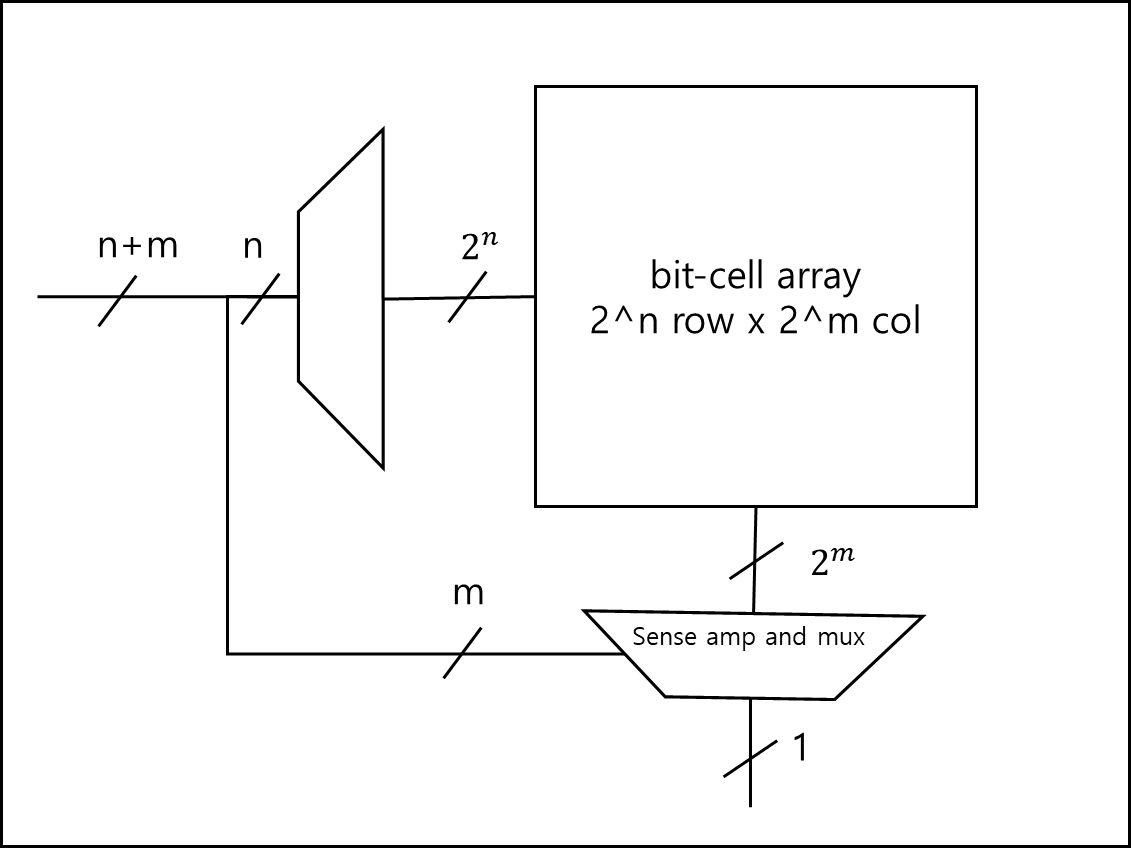
위와 같은 구조에서 읽기를 하기 위해서는 아래와 같은 절차를 거친다.
- 주소를 받으면 행 디코더가 어떤 행을 선택하는지 결정한다.
- 디코딩 결과로 특정 행이 활성화된다.
- 활성화된 셀은 각각 bitline 쌍에 미세한 전압차이를 만들어낸다.
- sense amp는 이 미세한 전압차이를 증폭하여 감지하게 된다.
- 감지된 값은 data bus를 통해 전달되고 버퍼로 보내진다.
- 이후 읽고 혹은 쓰기를 위해 각 셀은 precharge로 돌아간다.
2) DRAM(Dynamic Random Access Memory)
플롭플롭 대신에 Capacitor로 전하가 인가되는 구조의 메모리이다.
성능 상으로는 SRAM이 우월하나 SRAM을 구현하기 위해서 사용되야하는 트랜지스터가 많으므로 큰 용량으로 구현하기 어렵기 때문에 비교적 큰 용량을 구현하기 쉬운 DRAM으로 메인 메모리를 구성한다.
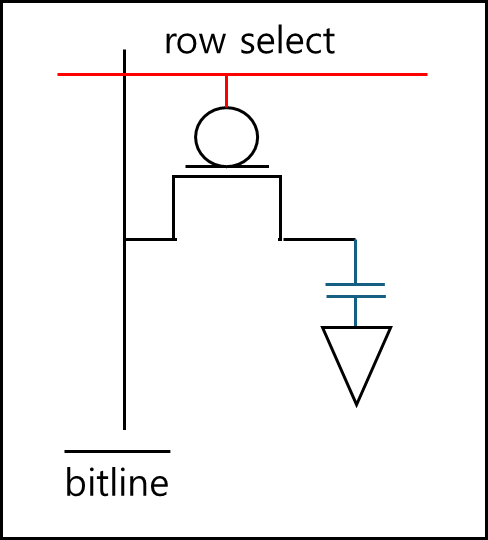
하지만 SRAM과 달리 Capacitor 에 주기적으로 전하를 충전해줘야하는 refresh 과정을 거쳐야하며 이 refresh 과정 중에는 아무 작업도 하지 못한다.
이 refresh 과정은 DRAM의 사이즈가 커지면 커질 수록 더욱 부담스러운 작업이 되는데 전체 소자에 전하 충전시켜줘야하는 양이 더 커지기 때문이다.
이러한 작업은 DRAM Controller에서 주기적으로 해줘야한다.
DRAM의 구조는 크게보면 SRAM과 많이 다르지 않다.
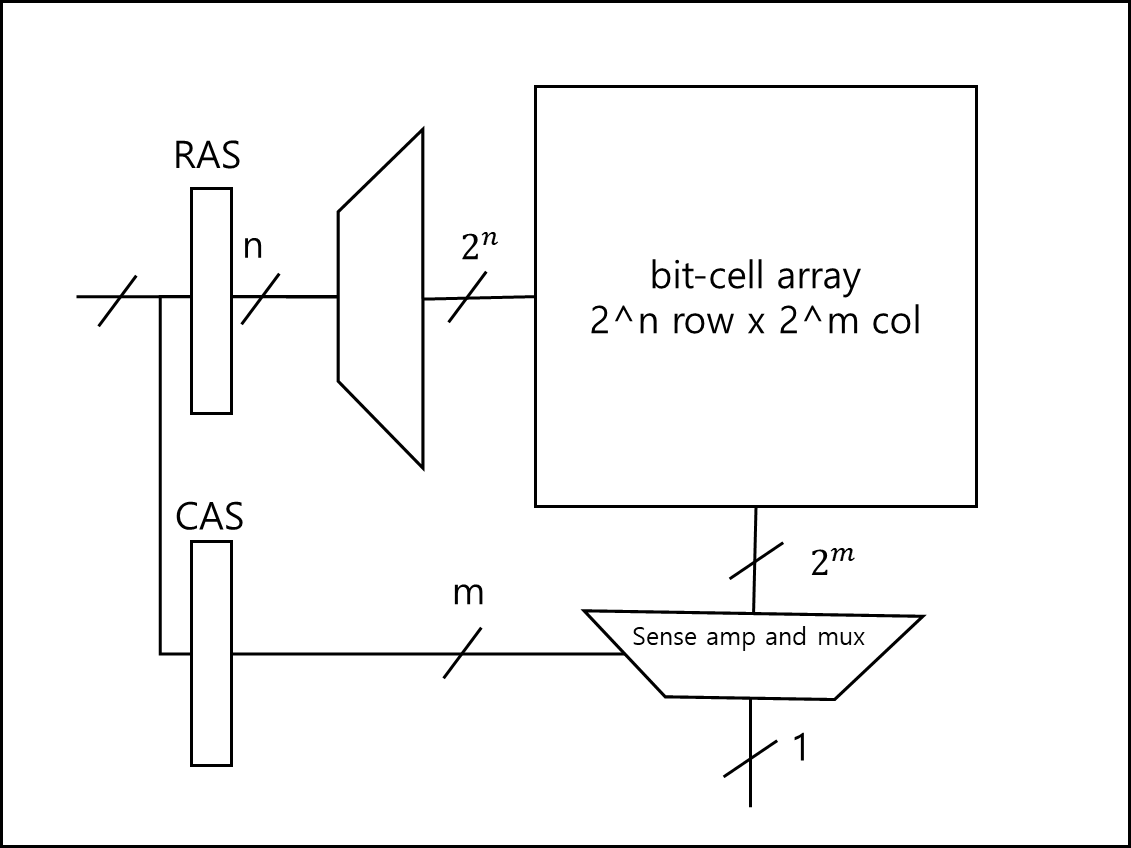
이 역시 읽기를 하는데 아래와 같은 절차를 거친다.
- 주소를 받으면 행 디코더가 어떤 행을 선택하는지 결정한다.
- 디코딩 결과로 특정 행이 활성화된다.
- 활성화된 셀은 각각 bitline 쌍에 미세한 전압차이를 만들어낸다.
- sense amp는 이 미세한 전압차이를 증폭하여 감지하게 된다.
- 감지된 값은 data bus를 통해 전달되고 버퍼로 보내진다.
- 이후 읽고 혹은 쓰기를 위해 각 셀은 precharge로 돌아간다.
SRAM과 동일하게 보이는가? 맞다. 사실 크게 다르지 않다. 다만 SRAM과 다른 점은 DRAM의 경우 Capacitor에서 읽게되면 전하가 없어지는데 이를 그대로 다시써주는 refresh 회로가 추가적으로 동작한다.
2. 메인 메모리의 계층적 구조
1) Channel
메모리 컨트롤러와 메모리 모듈(DIMM) 간의 데이터 전송 경로이다.
하나의 채널은 여러 개의 DIMM 슬롯을 지원할 수 있으며, 각 채널은 독립적으로 데이터를 전송할 수 있어 병렬 처리가 가능하다.
실제 컴퓨터를 보면 아래의 그림과 같이 Memory를 꽂을 수 있는 곳이 있는데 같은 채널에 다른 색깔로 구분되어있는 경우도 있고, 같은 색깔에 따로 표기가 되어있는 경우도 있다.

듀얼 채널을 지원하는 경우 4개의 메모리 슬롯에서 2개씩 채널을 하나씩 지원하는 것 같다.
2) DIMM (Dual in-line memory module)
우리가 생각하는 그냥 메모리 하나를 DIMM이라 부른다.

위 사진은 DIMM 하나를 앞 뒤로 보여준 것이다.
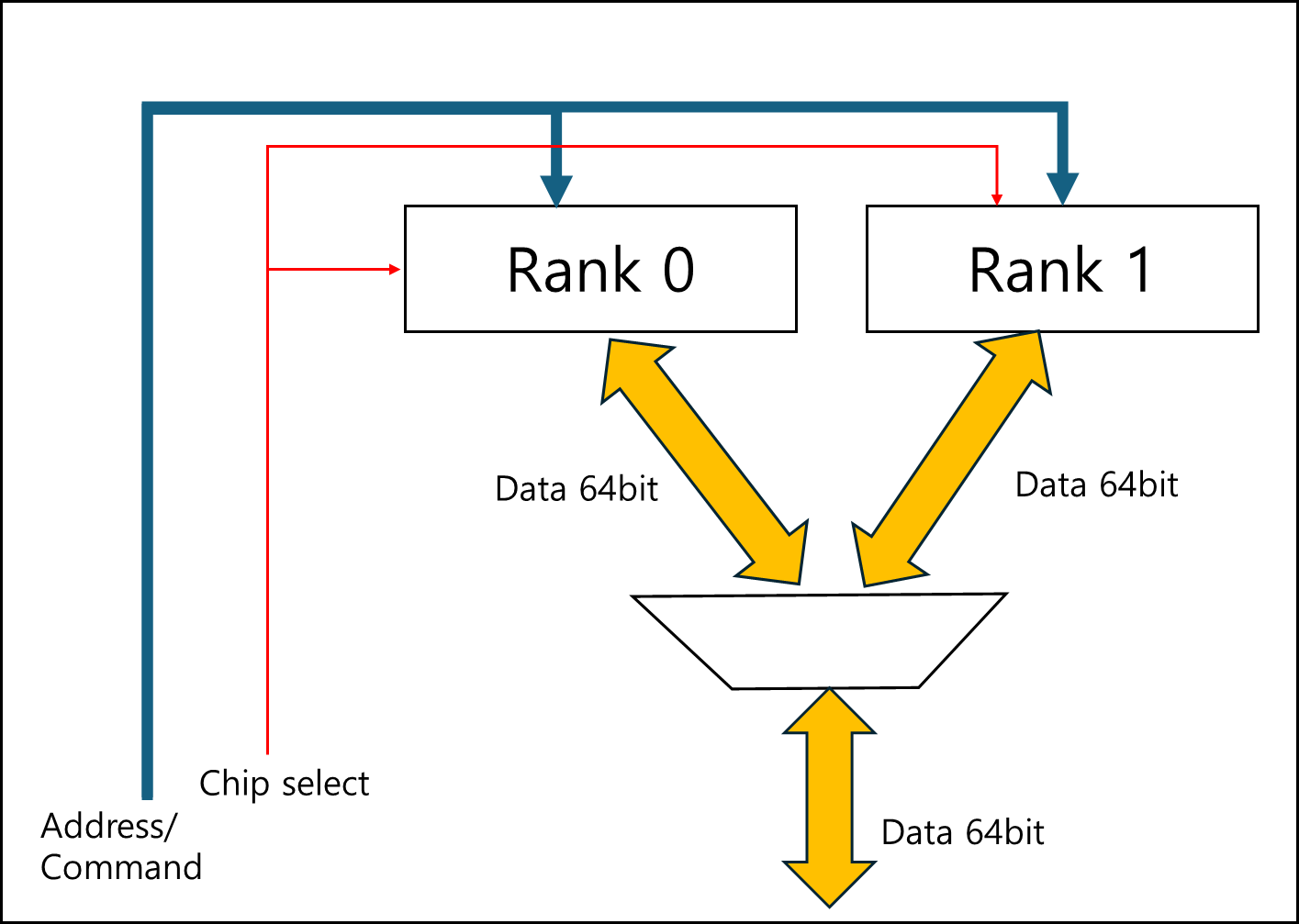
3) Rank
DIMM의 한 면을 RANK라고 부른다.

빨간색으로 표기된 면을 RANK 0, 파란색으로 표기된 면을 RANK 1이라고 한다.
데이터는 아래와 같이 갖고 오게 된다.
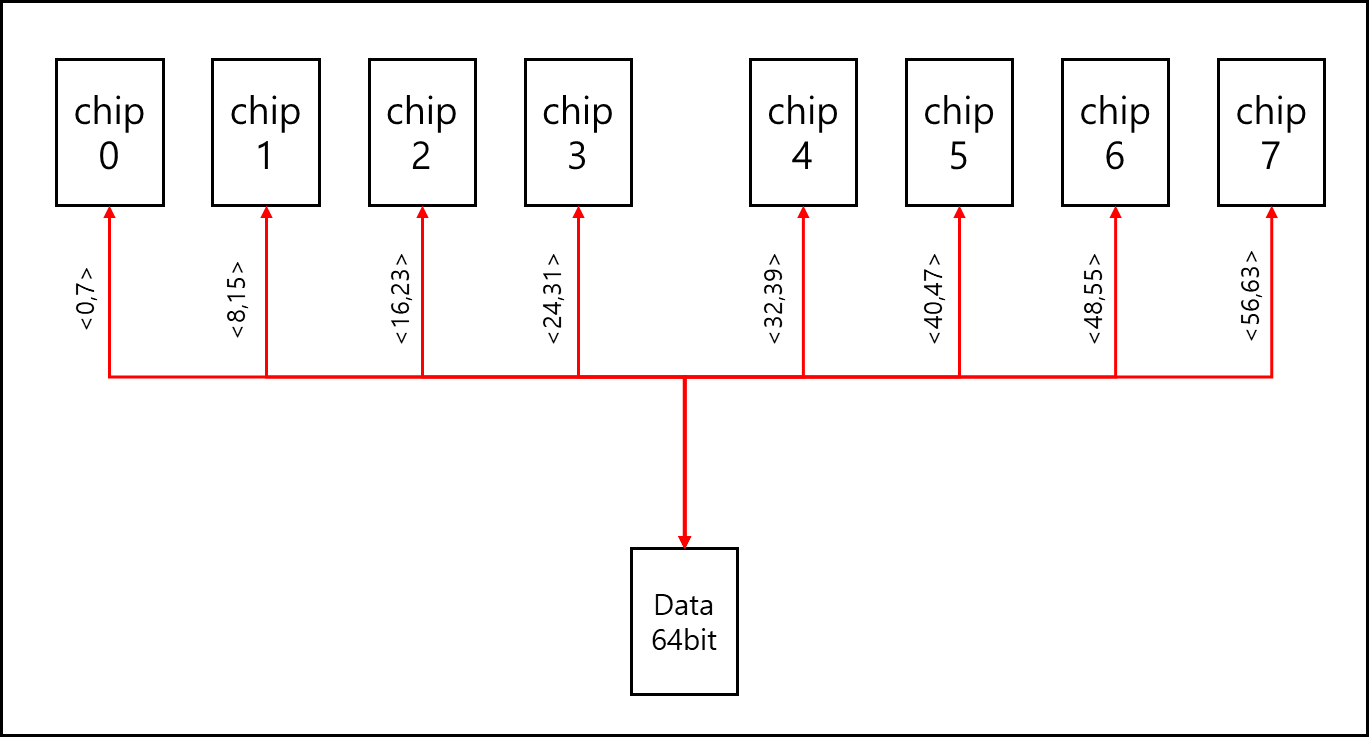
4) Chip
각 RANK당 사진에서 보이는 검은색 회로가 8개 달려있는데 이를 chip이라고 부른다.
RANK 마다 8Bytes를 전달하는데 이를 위해서 각 chip은 아래와 같이 통신한다.
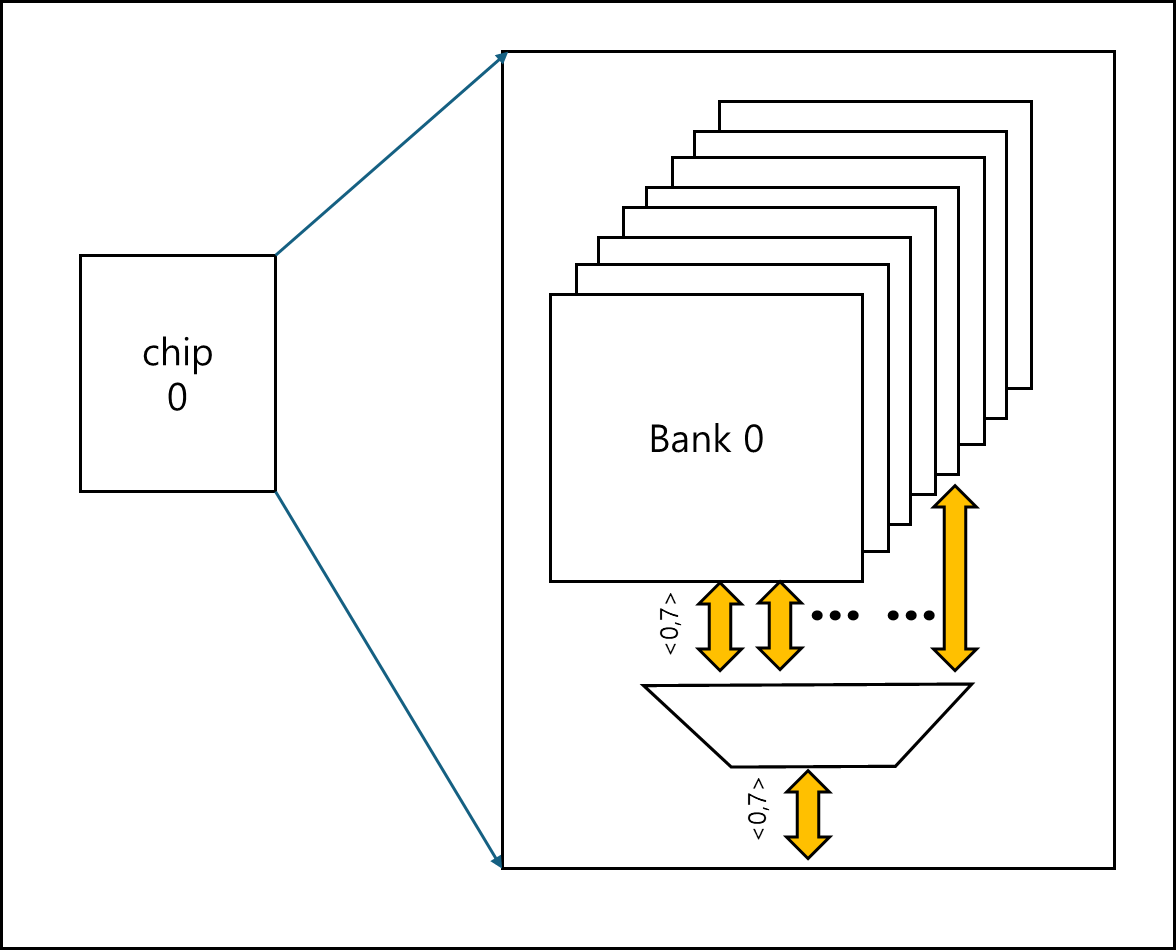
5) Bank
한 개의 chip은 다수의 Bank로 이루어져있다. Bank를 선택하여 bank당 1bit를 출력하는 것이다.
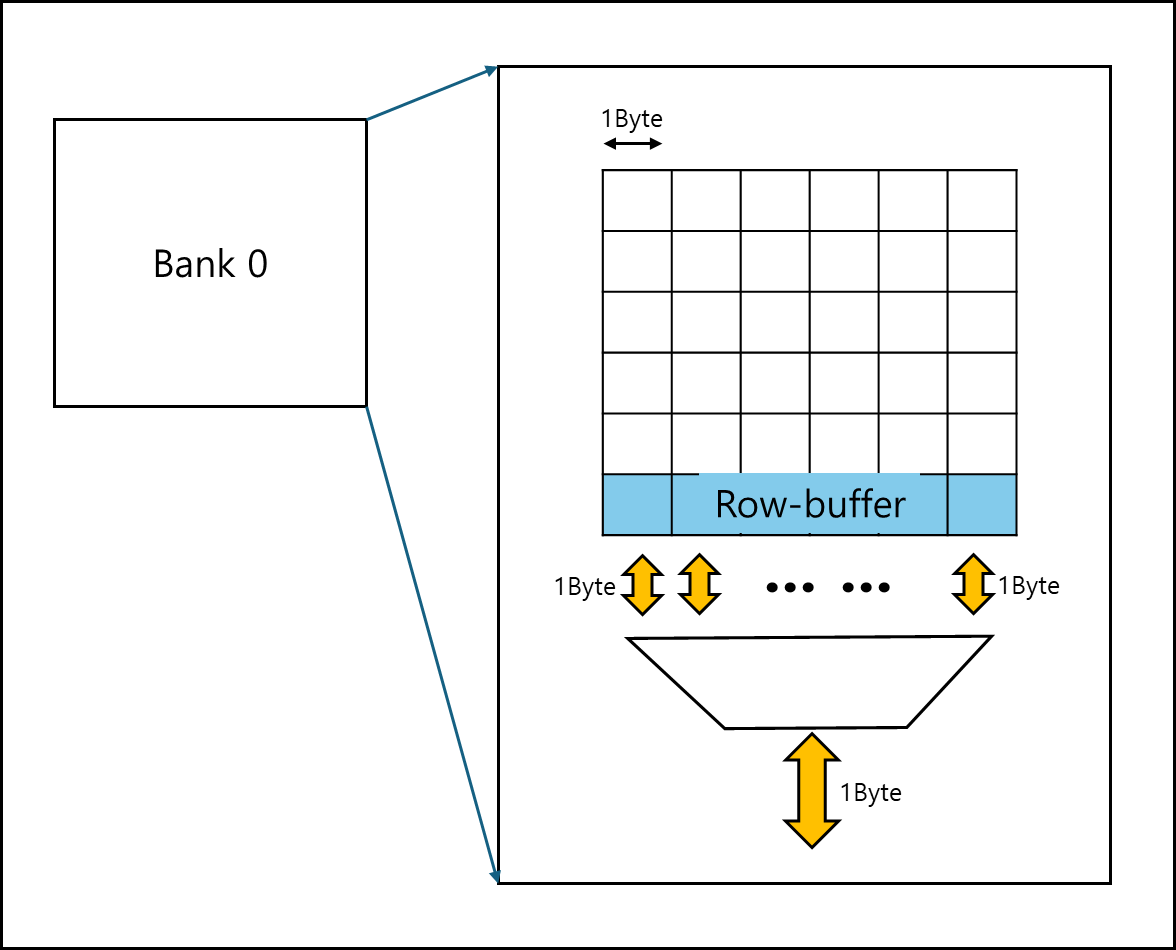
6) Row/Column
각 Bank는 Row와 Column으로 이루어져있다. 각 Column 마다 1bit로 이루어져있고 제일 아래에는 Sense amplifiers를 겸하는 Row-buffer가 있다.(이 내용은 아래에서 추가적으로 더 자세히 설명할 예정이다),
3. 데이터를 읽어오는 과정
가령 어떤 데이터를 읽어와야한다고 하자. 0x0부터 0x40(즉 64Bytes)를 읽어와야한다면 아래와 같은 순서로 이루어진다.
1) 채널로 해당 요청 보내기
CPU에 붙어있는 DRAM Memory Controller으로 읽어들일 주소를 보낸다.
채널당 DRAM Memory Controller가 하나 필요하므로 어떤 채널로 보내야하는지는 이후 서술 하겠다.
2) 대상 DIMM과 RANK로 요청 보내기
물리 Address가 어떻게 DRAM에 Mapping되어있는지는 이미 DRAM Memory Controller에서 모두 알고 있으며 몇번 DIMM의 몇번 RANK를 쓸지 이미 다 디코드 되서 요청이 가게 된다.
3) 대상 Rank 전체 Chip에 요청 보내기
여기서 chip은 한 rank에 8개가 붙어있는데 각 chip을 선택하여 데이터를 요청하는 것이 아니라 해당 Rank의 전체 chip에 데이터를 요청하게 된다.
4) Chip에 어떤 Bank를 사용할지 확인 후 row와 column 선택하여 데이터 보내기
각 chip은 요청을 받은 후에 address 정보에 포함된 bank 정보로(어떤 식을 포함되는지 차후 설명) bank를 선택후에 대상 ROW를 precharge하고 각 Column을 선택하여 row-buffer로 내리면서 각 데이터에서 1bit씩 보낸다.
DRAM에서는 8개의 Chip에서 전달되는 각 8bit의 값들을 모두 취합하여 보내고 다시 취합하여 보내는 식으로 전달한다.
요컨대 각 chip 한 개에 8개의 데이터가 쭉 있는게 아닌, 각 chip에 걸쳐서 8bit의 데이터가 있다고 생각하면 된다.
3. Address Mapping
DRAM의 특정 값을 갖고오기 위해서는 주소가 필요하다. 이는 물리적 주소를 말하는데, 이 물리적 주소를 어떻게 설계하느냐에 따라서 성능은 완전히 달라지게 된다.
또한, Single channel이냐 Multiple channel이냐에 따라 달라지며, bank 주소를 어떻게 Mapping 할 것이냐에 따라서도 달라지게 된다.
1) Single channel
일단 우리가 보려는 시스템의 스펙이 아래와 같다고 가정해보자.
- Single-channel에 8bytes memory bus
- 2GB Memory
- 8 Bank
- 16K Rows & 2K columns per bank
a. Row interleaving
Row interleaving 방식으로 Address Mapping을 하게 되면 아래와 같다.

row 갯수가 16K라고 했으니 $2^{14}$ 가 16K쯤이므로 14bits
bank 개수는 8개이니 $2^{3} = 8$ 이므로 3bits
Column 개수는 2K라고 했으니 $2^{11}$ 이 2K쯤이므로 11bits
마지막으로 메모리 bus가 8bytes짜리라고 했으니 3bits이다.
위 주소는 특정 데이터에 대해서 한 Bank에 대해서 1개의 Row에 대해서 전체를 읽어온 뒤 그다음 Bank에 Access하여 1개의 Row에 대해서 읽어오는 방식이다.
b. Cache block interleaving
Cache block interleaving 방식으로 Address Mapping을 하게 되면 아래와 같다.

row 갯수가 16K라고 했으니 $2^{14}$ 가 16K쯤이므로 14bits
bank 개수는 8개이니 $2^{3} = 8$ 이므로 3bits
Column 개수는 2K라고 했으니 $2^{11}$ 이 2K쯤이므로 11bits
마지막으로 메모리 bus가 8bytes짜리라고 했으니 3bits이다.
사실상 주소의 비트수는 동일하지만 다른 점이 있따면 Column 중간에 Bank를 선택하는 것으로 Address가 Mapping이 되어있다는 점인데, 이는 $8 \times 8 $bytes만큼을 읽어오면 그다음 Bank에서 데이터를 읽어 오게 된다.
※ Row interleaving vs Cache Block Interleaving
데이터를 읽기전의 과정을 생각해보자 Bank의 해당 Row를 Precharge 후 대상 Column에 대해서 open하여 buffer로 내려보내고 그 buffer에서 다시 전달한다.
Row Interleaving이라면 각 Bank별로 위와 같은 작업을 진행할 필요없이 한 개의 Bank만하게되면 $2^{11}$ 만큼의 연속된 데이터를 읽어오는데 별다른 처리를 해줄 필요가 없다.
하지만 Cache block interleaving는 각 Bank 별로 처리를 해주어야한다. 따라서 실행하고자하는 프로그램의 Spacial Locality가 많다면 Row Interleaving 방식이 성능이 더 나온다. 그렇다면 Row Interleaving의 성능이 좋을까? 그건 아니다.
각 Bank 별로 따로 운용되기 때문에 Cache block interleaving이 Random Access에서 성능이 좀 더 높게 나온다고 한다. 따라서 현대에 많이 쓰이는건 Cache block interleaving 방식이다.
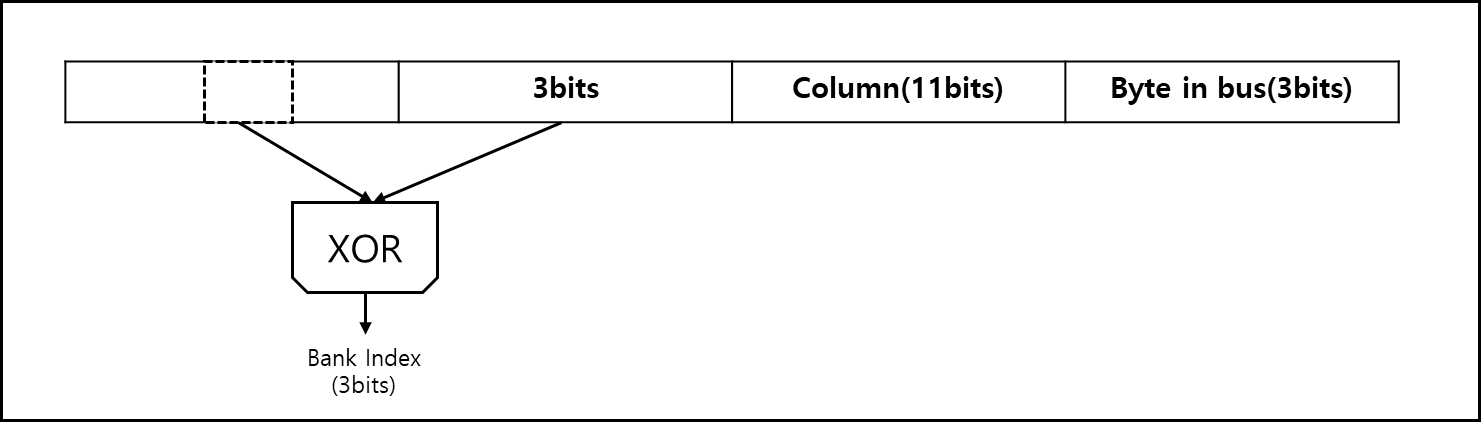
※ Bank Mapping Randomization
Mapping을 하다보면 한 개의 Bank에만 계속해서 데이터를 읽고 쓰고 하게 될 수가 있다. 이는 Bank conflict를 야기할 수 있고, 해당 Bank의 수명을 줄일 수 있다. 따라서 쓰고 읽을때 Bank를 섞어주면 여러모로 좋을 것이라는 판단에서 나온 방식이다.
방식은 간단하다 실제 Bank를 선택하는 3bits와 상위 3bit를 XOR하여 Hashing하듯이 처리해주고 나온 값을 Bank index로 삼아서 엑세스하면 된다.
2) Multiple channel
a. Channel bit 위치에 따른 Mapping
멀티 채널의 경우 물리 주소에 어떤 채널로 요청을 보낼 것인지에 대한 정보가 들어있어야한다.
이때 2개의 채널이라 bit 하나로 구분하면 될때, 이 bit의 위치에 따라서 성능과 접근 방식이 완전히 달라진다.
아래는 채널 비트를 각 위치에 따라서 넣을 예시이다. 제일 아래를 1번, 제일 위를 5번 방식이라 하고 연속적으로 엑세스하고 있다고 가정하자.
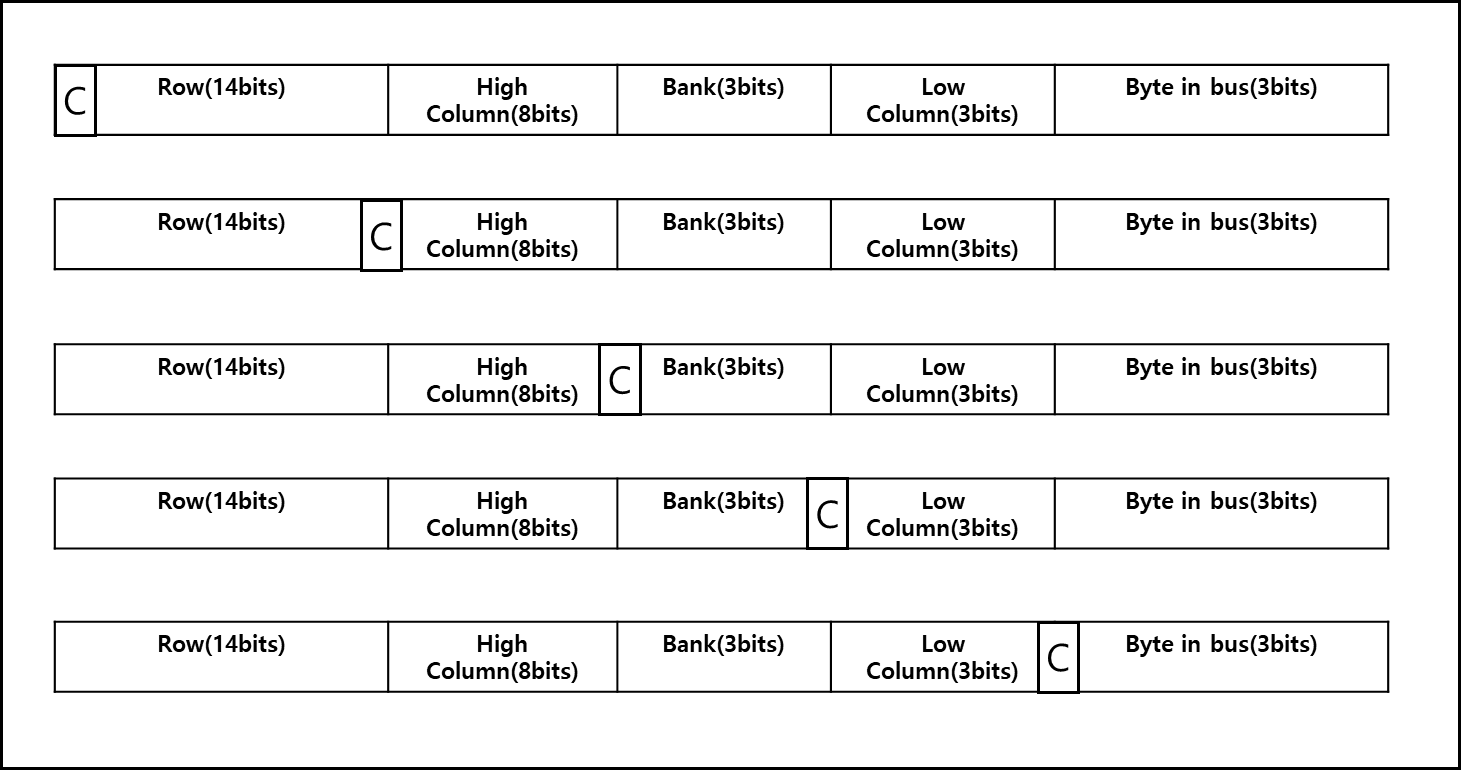
1번 방식
8bytes 마다 channel을 변경해가면서 요청하고 받는 식이다. 만약 캐시 블록 사이즈가 64 Bytes라고 할때 1개의 캐시 블록 사이즈도 안되는 값을 각각의 채널에서 받아오는 것인데 병렬성에서 보면 최고지만, 이 데이터를 취합하는게 문제다. CPU에서 요하는건 캐시 블록 사이즈의 데이터이기 때문에 메모리 컨트롤러가 각각의 8Bytes 씩을 받아 8개를 취합해서 64Bytes로 만들어줘야하기 때문이다.2번 방식
캐시 블록 사이즈 만큼 요청할때 마다 채널을 변경한다.3번 방식
캐시 블록 사이즈 $\times$ 8 만큼 요청할때마다 채널을 변경한다.4번 방식
Row 전체 하나를 다 요청하고 난 뒤 채널을 변경한다.5번 방식
전체 Row에 대해서 다 요청하고 난 뒤 채널을 변경한다.
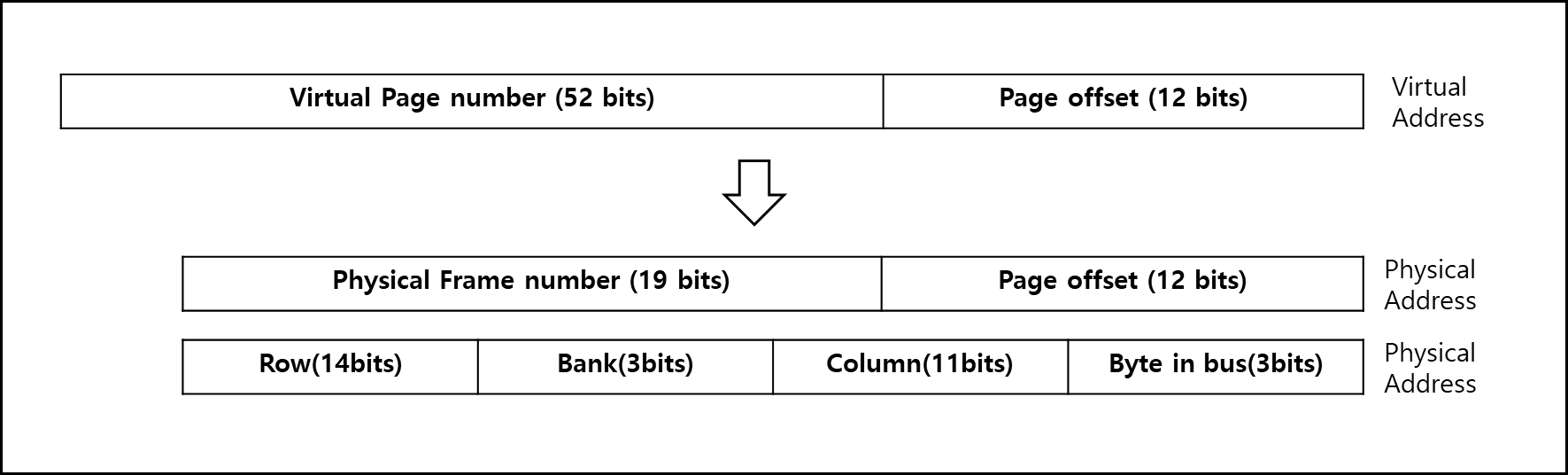
b. 가상 주소와 물리 주소 Mapping
64bit 아키텍처일때 가상 주소는 64bit의 주소를 갖는다.
이를 물리 주소로 매핑할때 OS는 페이지를 랜덤하게 Bank와 Channel쌍으로 Mapping할 수 있으며 응용단에서는 어떤 Bank에 접근하는지 알 수 없다.
4. DRAM Refresh
앞서서 설명했듯이 DRAM은 캐피시터로 이루어져있기 때문에 주기적으로 전하량을 충전해줘야한다.
이를 Refresh라고 하며 이렇게 Refresh하는 시간동안에는 DRAM은 읽고 쓰기를 포함해서 아무런 작업도 할 수 없다.
일반적으로는 64ms 마다 전체 bit를 충전시켜주어야하며 크게는 두 가지 방법으로 나눌 수 있다.
Burst Refresh
한번에 모든 row에 대해서 Refresh를 하는 방법이다.Distributed Refresh
각 row를 다른 시간에 일정한 텀을 두고 Refresh 하는 방법이다.
참고자료
- Computer Organization and Design-The hardware/software interface, 5th edition, Patterson, Hennessy, Elsevier
- 서강대학교 이혁준 교수님 강의자료 - 고급 컴퓨터 구조
- 다나와 - MSI B450M 박격포
- 위키백과 - DDRM2_SDRAM
{kind=link}