컴퓨터 구조 - CPU 구조 - Cache 성능
Cache 성능
1. 개요
기본적으로 Memory에 대한 성능을 이야기 할때 AMAT(Average Memory Access Time)를 가지고 말한다. 이 AMAT는 아래와 같이 산출한다.
\[AMAT = Hit Time + Miss Rate + Miss Penalty\]- Hit Time : Cache에 data가 있고 이 데이터를 갖고 오기까지의 시간을 말한다.
- Miss Rate : Cache에 접근시 어느정도 비율로 Cache miss가 나는지를 말한다.
- Miss Penalty : Cache miss가 발생시 하위 메모리 층에서 데이터를 갖고 오는 시간을 말한다.
따라서 성능이 높다는 것은 AMAT이 작다는 뜻이고, 이 AMAT을 줄이기 위해서는 위 세 요소를 줄여야하는 것이다.
2. Cache miss
Hit Time 이전에 Cache miss에 대해서 알아보도록 하겠다.
일반적으로 우리가 Cache miss라 부르는 것은 사실 총 3가지 경우가 있다.
1) Compulsory or cold misses
프로그램 시작시 모든 Cache가 비어있기 때문에 어쩔수없이 발생하는 Cache miss이다.
피할수 없기 때문에 Compulsory 혹은 Cold(예열되지 않았음) miss로 불린다.
이런 경우는 미리 Cache에 데이터를 넣어두면 피할 수 있다. 이를 pre-fetch라고 한다.
2) Conflict or interference misses
대상 Index에 목표하는 데이터가 아닌 다른 데이터가 점유하고 있어서 Conflict로 인해 발생하는 Cache miss이다.
hashing collision 문제와 비슷하다고 생각하면 된다.
이는 Cache를 associativity 하게 구성하면 conflict 가 덜 발생하게 된다.
3) Capacity misses
Cache 용량이 크지 않아서 생기는 문제이다.
어차피 Cold misses 제외하고는 Cache 크기가 작아서 생기는 문제가 아닌가? 할 수 있겠지만 좀 다르다.
정확하게는 Cache가 Working set, 즉 프로그램을 구동할때 필요한 최소한의 명령어와 데이터를 다 담지 못하기 때문에 발생하는 문제이다.
이는 Cache 용량을 늘리거나, 데이터의 양을 줄이면 해결된다.
※ Capacity misses와 Conflict misses를 구분하는 법
그럼에도 불구하고 현재 발생중인 Cache miss가 Capacity misses인지 Conflict misses인지 헷갈린다면, 현재 구동중인 Cache 구조가 Fully associative cache라고 생각해봤을때도 해당 문제가 발생한다면 이는 Capacity misses인 것이다.
3. Cache block
1) Cache block 크기와 Address의 상관 관계
여기서 말하는 Block이란 Cache의 실질적인 Data가 담겨있는 곳의 크기를 말한다.
그리고 Cache miss시에 메모리에서 한번에 읽어오는 크기를 말하기도 한다. Cache block에 대한 크기는 Address와 Tag bit와 Index bit, 그리고 전체 bit만 주면 유추해볼 수 있다.
예를 들어 가령 아래와 같은 구조라고 해보자.
- 총 Address bit : 32
- Tag bit : 20
- Index bit : 8
- byte offset bit : 4
Direct Mapped Cache라고 할 때, block의 크기는 어떻게 되며 총 Cache의 크기는 어떻게 될까?
먼저 block의 크기는 간단한데 bit offset의 크기를 승수로 계산하면 된다.
총 16bytes의 크기이며, 1 word를 4bytes라고 한다면 4 word만큼 들어갈 수 있다.
캐시 block 크기를 산정했으니 총 Cache Data의 크기도 산정해볼 수 있다.
index만큼 cache 블럭 수가 있기 때문이다.
총 256개의 블럭이 있고 블럭마다 사이즈가 16bytes이니
\[256 \times 16 = 4096 = 4 \times 1024 = 4KB\]Cache의 총 Data block는 4KB가 되는 것이다.
2) Cache block과 성능
이 Cache block의 크기에 따라 성능이 달라진다.
만약 Cache block이 커진다고 가정해보자. 그러면 전체 Address는 동일하고, 전체 Cache의 사이즈가 이전과 동일하다면 전체 Cache Block 수가 줄어든다. Block이 커졌기에 한번에 갖고 오는 연속 데이터가 커지니 Spatial locality 가 높은 프로그램의 경우 성능이 올라가나, Block 개수가 줄었기 때문에 Temporal Locality가 높은 프로그램의 경우 성능이 저하되며 Memory bandwidth를 많이 요한다.
그렇다면 반대로 생각해서 block 사이즈가 작아진다면 어떻게 될까? 동일하게 Address, 전체 사이즈가 동일하다면 전체 Cache block 수가 많아지나, Block이 작아졌기에 Spatial Locality 가 높은 프로그램이라면 성능이 떨어지지만 Cache block의 개수가 많아졌기 때문에 Temporal Locality가 높은 프로그램이라면 오히려 성능이 올라갈 수 있다.
이를 그림으로 그려보면 아래와 같다.
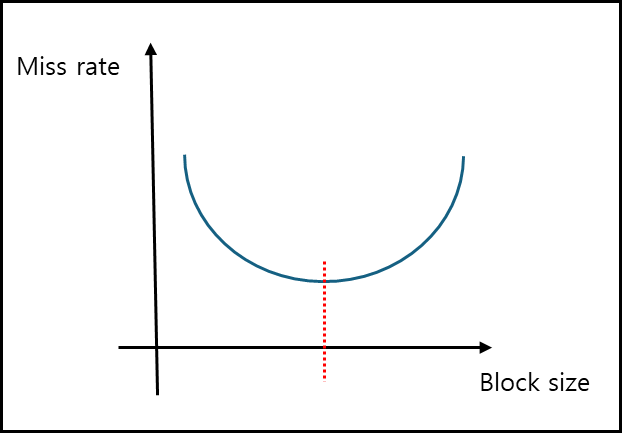
Block 사이즈가 커지면 Miss Rate가 내려가다가 일정 지점을 이후로 쭉 올라가는 걸 볼 수 있는데 이 지점이 가장 최적의 사이즈이고, 최근 일반적으로는 이 사이즈가 64Bytes로 잡혀있다.
4. Hit time 줄이기
1) 상위 Memory는 사이즈를 작고 간단하게 만든다.
기본적으로 상위 Memory는 아주 빨라야한다. L1 Cache의 경우 1 ~ 3 cycle 안에 데이터를 가져와야한다. 따라서 작고, 간단하게 만들어져야한다.
기본적으로 작다는 것은 칩 안에 있을 수 있다는 것이고 칩 밖으로 나가면 거리가 늘어나기 때문에 시간이 느려진다.
L1 캐시의 경우 Direct Mapped Cache로 만들어지는데, associative cache가 아닌 이유는 associative 하게 만들려면 별도의 회로가 필요하고 이 회로가 성능을 떨어뜨리는 원인이 되기 때문이다.
아래의 그림을 보자
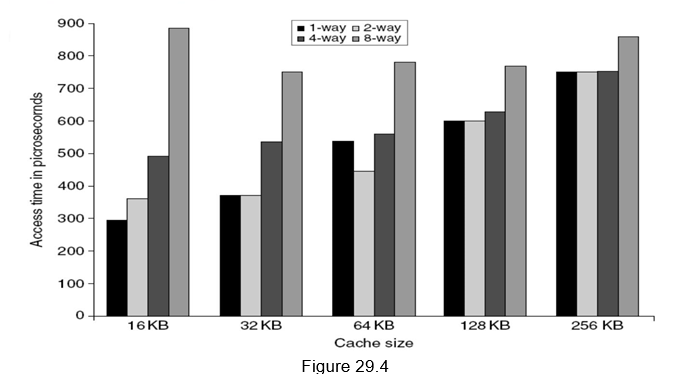
출처 : Computer Architecture, Dr Ranjani Parthasarathi
위의 그림을 보면 간단하고 작은 사이즈일 수록 속도가 빨라짐을 알 수 있다.
2) Psuedo-Associative Cache
위에서 간단한 게 빠르다곤 했지만 사실 n-way associative cache로 만들면 cache conflict가 n분의 1만큼 줄어드므로 이를 포기하기엔 아쉽다.
따라서 이 n-way associative cache 와 유사하게 만들되 성능 감소가 적은 방법이 있을지 누가 생각했다.
아래의 그림을 보자
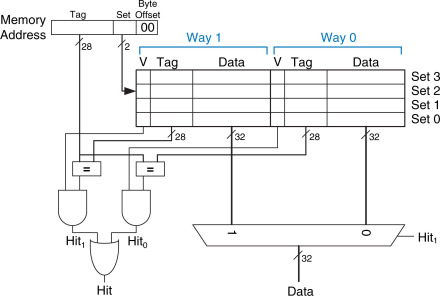
출처 : ScienceDirect - Set-Associative Cache
위 그림은 2-way associative cache이다.
잘 보면 mux를 통해 Data가 나가는 것을 볼 수 있다. MUX 회로는 way가 많아질 수록 느려지고 복잡해진다.
이는 다수의 게이트를 거쳐야하기 때문에 느려지는 것이다.
따라서 이 mux를 없애버릴 방법만 찾으면 되었다. 그렇게 해서 개발 된 것이 Prediction하는 방식이다. 이는 흡사 branch prediction 같이 prediction하는 것으로 LRU 카운터를 재 사용하는 방식으로 구현할 수 있다.
해당 캐시 블럭에 Write/Read를 하게되면 그 캐시 블럭의 LRU Count를 0으로 하고 원래 Count 값보다 작았던 다른 블럭의 Count를 1씩 증가시키는 방식으로 구현하게 되면 Count가 0인 블럭은 MRU(Most Recently Used)이고, Count가 가장 큰 블럭은 LRU 값인것이다. 여기서 제일 먼저 Prediction 대상이 되는것은 MRU 블럭이다.
최초 MRU 블럭이 대상 블럭이 맞다면 바로 사용할 수 있되, 대상이 아니면 그 다음 MRU 블럭을 선정하는식으로 체크하며 만약 캐시 블럭 way가 n개 라면 최대 n번 까지 체크하여 사용하게 된다.
이게 효과가 있을까 싶지만 기본적으로 Cache 자체가 Locality를 이용해서 성능을 높이는 방법이기 때문에
꽤나 효과적으며 현대 CPU에서도 많이 사용되는 기법이라고 한다.
5. 캐시 Bandwidth 늘리기
1) 캐시 파이프라인
캐싱에 관한 부분도 파이프라인을 하면 성능이 올라간다.
CPU 파이프라인에 대해서 말하는게 아니라, 여기서는 캐시 사용하는 부분을 파이프라이닝했다는 뜻이다.
캐시 데이터를 갖고오는 과정을 간단하게 말하자면 컴퓨터에서 운용중인 가상 주소를 TLB로 메칭해서 실제 물리 페이지 번호를 갖고와서 캐시에 대조해보고 이를 가지고 DATA를 갖고오는 식인데 이를 물리주소 갖고 오는 Stage와 물리주소로 Cache에서 Data를 대조해보는 Stage로 나누어 파이프라인으로 처리할 수 있다.
캐싱 파이프라인 적용한 경우는 꽤나 많은데, 펜티엄 시리즈의 경우 펜티엄 4당시에 이 cache pipeline 깊이가 4였다. 이렇게 파이프라인을 적용하면 Throughput 이 증가하니 당연히 성능이 올라간다.
하지만 분기 예측에 실패하면 패널티가 더 커지는데, 이는 분기 예측 실패시 캐시 파이프라인안에 있는 데이터를 모두 flush 해야하기 때문에 이에 대한 패널티까지 가중되기 때문에 그러하다.
2) Multi-ported/Multi-banked 캐시
한번에 많은 양을 읽어올 수 있거나 많이 쓸수 있다면 성능이 올라간다.
왜냐면 처리량이 올라가기 때문이다.
이 방식을 구현하기 위해서는 두 가지로 나눌 수 있다.
a. Multi-ported cache
진짜 한 개의 캐시에 다수 접근이 가능하게끔 만든 캐시이다.
이 경우 1개 이상의 접근이 가능하나 두 가지 문제점이 생긴다.
- 캐시 영역이 커진다 (회로가 복잡하기 때문에 영역을 많이 차지한다)
- hit time이 늘어난다(회로가 복잡하기 때문에 delay가 생긴다)
b. Multi-banked cache
한번에 한 개만 접속할 수 있는 캐시를 병렬적으로 연결한 형태의 캐시이다.
이렇게 만들면 회로가 복잡하지도 않고 병렬성도 챙길수 있어서 이득이지만 접근 데이터가 같은 캐시에 들어있다면 병렬성을 살릴 수 없다(bank conflict) 따라서 데이터 배치 방식이 중요한 방법이다.
3) Non-blocking or Lockup Free Cache
일반적으로 Cache miss가 나면 stall을 통해서 data를 갖고올때까지 기다리지만(blocking)
Non-blocking cache(혹은, Lockup Free Cache) 구조의 캐시는 일단 어디에 기재해두고 계속해서 진행하는 형태이다.
miss를 처리하는 동안 hit를 처리할 수 있으며(hit-under-miss), miss간에도 miss를 허용하는 것(miss-under-miss)
이 두 가지 아이디어가 기반이 되어 만들어진 캐시로, 이 miss를 얼마나 용인하고 기재할 것인가는 Cache의 정책과 하드웨어에 달려있다.
이를 운용하기 위해선 특별한 하드웨어가 필요한데 이를 Miss Status Handling Registers(MSHR)이라고 부른다.
어느부분이 cache에 데이터를 갖고오기를 기다리고 있다는 일종의 메모장이다.
아래와 같은 구조를 가진다. (세부 bit는 설계에 따라 달라질 수 있다.)
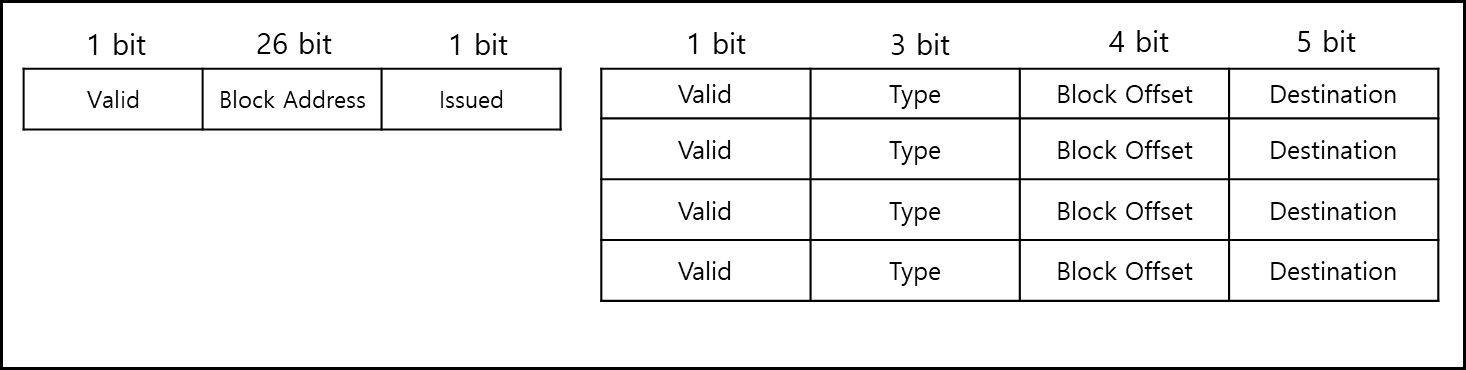
왼쪽을 가칭으로 address block, 오른쪽을 offset block이라고 해보자. address block은 다수의 offset 블록과 같이 엮여있다. 위와 같은 구조에서 아래와 같은 명령어 셋이 있다고 해보자.
1
2
lw $1, 100($2)
sw $3, 104($2)
만약에 100($2) 주소의 Block Address가 502(Decimal), Block Offset이 4(Decimal)이고 Cache miss가 났다면?
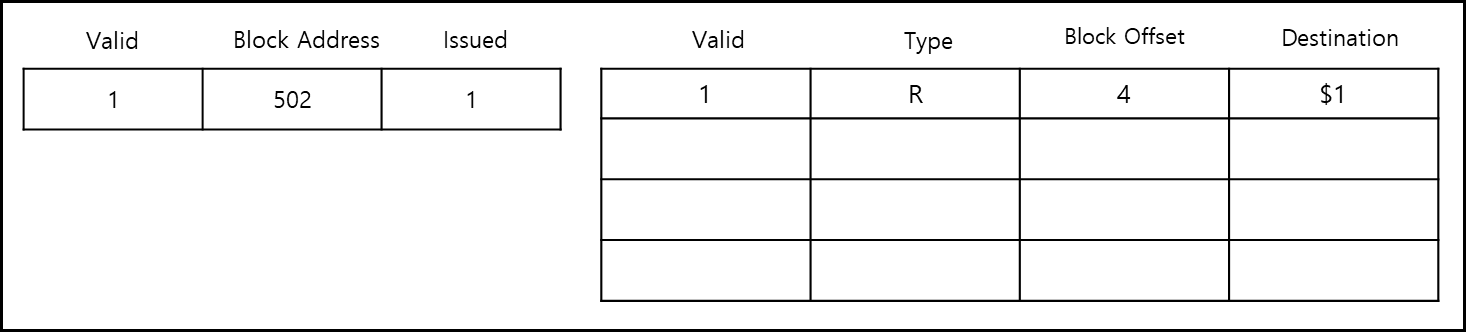
위와 같이 block address가 기재되고, offset Block에 세부 내용이 기재된다. address block의 Valid는 유효한 값인지, Block Address는 Address가 어떻게 되는지, Issued는 해당 내용을 메모리에 요청했는지이다. offset Block의 경우, Valid는 유효한 값인지, Type은 어떤 연산인지, Block offset은 offset이 어떤 값인지, 갖고 온 값이 어느 레지스터로 가야하는지이다.
그 다음 sw의 명령어의 경우 104($2) 주소가 Block Address가 502에 offset이 5라고 한다면 아래와 같이 된다.
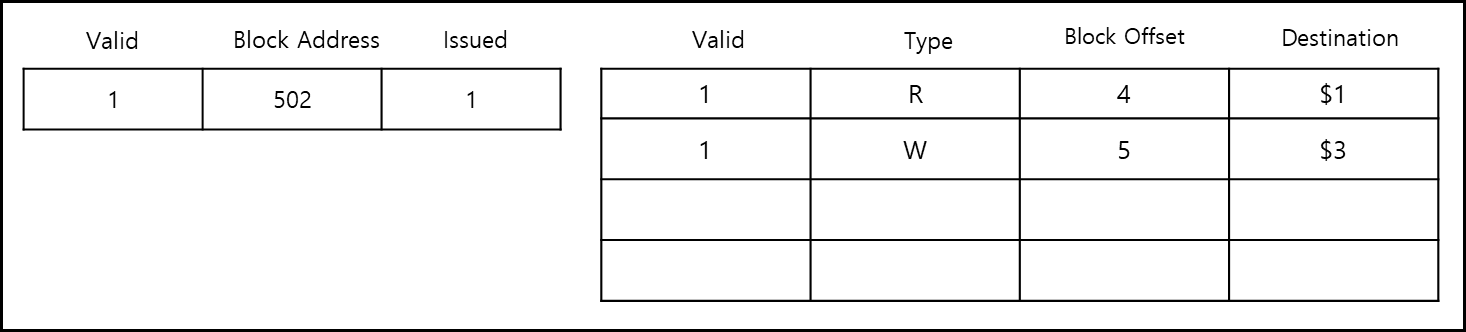
요청한 값이 cache에 왔다면 offset Block에 Valid를 0으로 처리해주고, 모든 offset Block에서 처리가되었다면 Address block의 Valid 역시 0으로 처리해준다.
만약 처리과정에서 offset Block의 슬럿이 꽉 찼다면 어떻게 될까?
그땐 빈 슬럿이 날때까지 stall로 기다리게 된다.
※ 정말 효과가 있을까?
얼핏 생각했을 때는 비동기적으로 구동해서 stall을 줄이니까 썩 괜찮다고 생각이 드는데, 좀 생각해보면 정말로 그러한가라는 생각이 든다. 이는 명령어간의 의존성으로 인해 이전 명령어 수행 결과가 나와야 하는 경우에는 어차피 stall을 해야하는거 아닌가 싶은 것이다 하지만 아래의 그래프를 보면 실제 각 벤치마크의 결과간에서 Miss를 허용하는 개수가 늘어날 수록 AMAT이 유의미하게 줄어드는 것을 볼 수 있다.
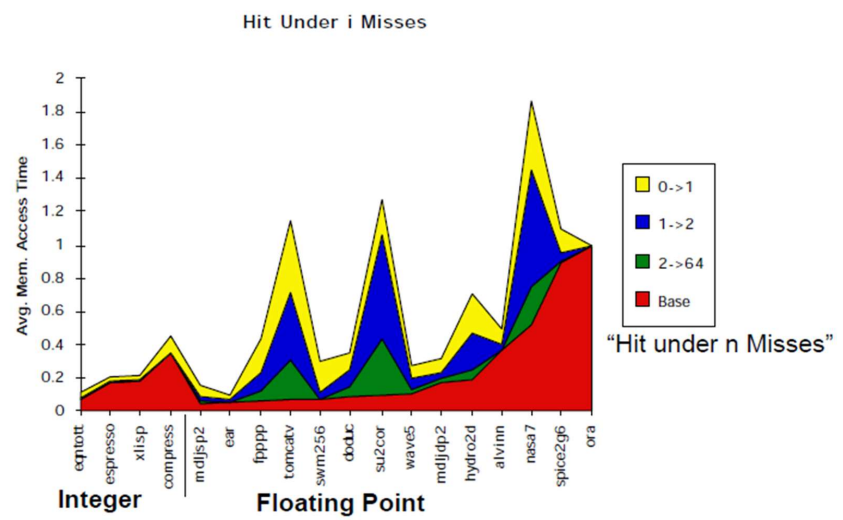
출처 : 강의 자료(차후 실제 출처 추가 예정)
6. Miss 패널티 줄이기
1) 중요한 Word부터 먼저 갖고 오기
가장 필요한 Word부터 갖고 오자는 아이디어에서 시작된 내용이다.
블럭 단위로 Cache를 패치한다고 하지만 Cache와 Memory간에 패치가되는건 Word 단위라고 생각하면 된다.
그렇기 때문에 여기서 이야기하는건 가장 중요한 Word부터 갖고 와서 Cache에 업데이트 해주는 것이다. (Block의 워드 단위로 패치해주므로)
물론 이게 되려면 해당 Memory에서 해당 부분을 지원해줘야 가능한 부분이다.
(Standard한 규약에서 벗어나는 부분이라고 한다)
2) 멀티 레벨 캐시
현대 CPU에서 흔히들 차용하는 방식이다.
어떤 CPU를 검색해보더라도 계층별 캐시구조가 되어있지 않은 것을 찾기 어려울 정도이다.
빠르고 작은 L1 캐시, 그보다 크고 조금 느린 L2, 그보다 더 크고 조금 더 느린 L3 식으로 구조를 갖고 가는 것이다.
물론 하위 단계일 수록 속도가 느려지지만 그래도 Memory에 다녀오는 것보다는 빠르므로 사용한다.
일반적으로 L2까지는 코어 안에 있으나, L3부터는 코어 밖에 위치하며 속도도 매우 느리다(물론 메모리에 다녀오는 것 보단 빠르다)
또한 각 레벨별 캐시의 설계 구조와 사이즈도 다르다.
- L1 : Direct-mapped 혹은 4-way associative, 1~3 사이클만에 엑세스, 8KB ~ 64KB
- L2 : 4~8 way associative, 256KB ~ 512KB
- L3 : Multi-bank, 높은-associative, L2보다 압도적으로 큰 용량
※ L2까지 있는 CPU에서 L1 AMAT 구하기
일단 L1 AMAT의 수식은 아래와 같다.
\[L1 AMAT = HitTimeL1 + MissRateL1 \times MissPenaltyL1\]여기서 MissPenaltyL1은 아래와 같이 나타날 수 있다.
\[MissPenaltyL1 = HitTimeL2 + MissRateL2 \times MissPenaltyL2\]여기서 MissPenaltyL2는 아래와 같이 나타날 수 있다.
\[MissPenaltyL2 = DRAMaccesssTime + (BlockSize/Bandwidth)\]여기서 L2 miss Rate는 총 두가지로 나뉠 수 있는데 아래의 그림을 보자.
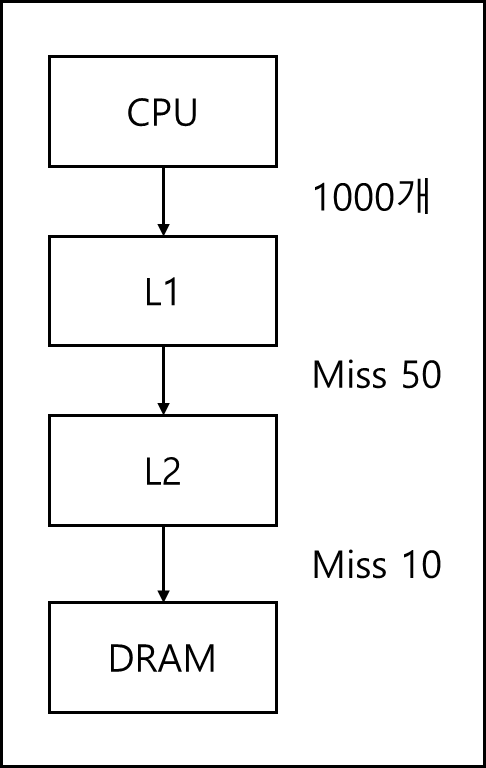
위 그림을 보면 총 1000개를 L1에서 찾을 때, L1에서 Miss가 50개가 나서 L2에 요청이 갔고 L2에서 Miss가 10개 나서 DRAM에 요청이 갔다.
이 경우 L1의 Miss Rate는 아래와 같다.
\[L1 Miss Rate = \frac{50}{1000} = 5\text{%}\]L2는 아래와 같다.
\(Global L2 Miss Rate = \frac{10}{1000} = 1\text{%}\)
\(Local L2 Miss Rate = \frac{10}{50} = 20\text{%}\)
Global Miss Rate 전체 요청 중에서 L2에 몇 개의 Miss가 났는지, Local MissRate는 L1에서 내려온 요청중 L2에서 몇개의 Miss가 났는지를 말하는 것이다.
3) 희생자 캐시(Victim Cache)
간단히 말해서 L1에다가 작은(4 ~ 16 Blocks) Fully associative cache를 달아서 L1에서 Replace 되는 워드들을 Victim 캐시에 담아두는 것이다.
그리고 L1 캐시에 접근할때나 L1에서 Miss가 나서 L2에 접근하기전에 Victim 캐시에 먼저 접근하는 식으로 구현되는데 작은 associativity 때문에 생기는 conflict를 상당수 피할 수 있으며 비효율적인 Replacement 정책으로 생기는 문제도 해결 가능하다.
7. Miss Rate 줄이기
1) Skew associative 캐시
Associative가 낮은 Cache의 경우 conflict Miss가 많이 나게 된다.
이는 동일한 Index에 대해서 적은 개수의 slot을 갖고 있기 때문이다. 결론적으로 동일한 Index에 대해서 좀 더 많은 개수의 slot을 갖게 되면 해결될 문제이기도하다. 이러한 생각에서 시작된게 Skew-Associative Cache이다.
원래는 index bit만을 가지고 캐시의 slot을 찾았다면 Tag와 Index 모두를 써서 일종의 Hasing을 한 뒤에 나오는 값으로 캐시의 slot을 찾아서 기재하는 방식이다.
주소상 동일한 Index를 가지더라도 Hasing된 값으로 입력되기때문에 Conflict miss는 줄어든다. 하지만 Hash 함수를 거치는 latency는 추가적으로 들어가게된다.
8. Miss penalty나 Miss Rate를 병렬화를 통해 줄이기
1) Prefetching
미리 Fetch를 해두면 Cold miss를 회피할 수 있다. 이는 Programmer가 할 수 있고 Compiler가 할 수도 있으며, Hardware가 할수도 있다.
이 Prefetch는 꽤나 고려해야할 것이 많은데 너무 빨리해서도 안되고 늦어서도 안된다. 그리고 필요한 것만 갖고와야하는데, 쓸데없는 데이터가 많아진다면 정말 필요한 데이터를 갖고오는데 시간이 더 걸리기 때문이다.
a. Software prefetching
Software 적인 방법으로는 아래와 같은 상황을 예시로 들 수 있다.
1
2
3
4
5
for (i=0;i<N;i++) {
__prefetch(a[i+8]);
__prefetch(b[i+8]);
sum += a[i]*b[i]
}
앞에 __prefetch 는 전처리 지시자로 구성된 LW 명령어라고 생각하면 된다.
어떤 값을 더할 것인데, 8 Loop 이후의 데이터를 미리 Cache에 올려두는 것이다.
(당연하지만 위 방식으로 이득을 보려면 non-blocking cache 여야한다)
왜 8 Loop 이후냐고 한다면 이는 기계에 맞춰진 값이다.
이런식으로 Software를 통해 prefetching을 한다면 기계마다 다른 값을 줘야하기 때문에 이식성이 떨어지는 코드가 되고, 경험적으로 어떤 값이 가장 빠른지 알고 있어야 사용할 수 있다.
b. Hardware prefetching
소프트웨어로 구현되었던 것을 하드웨어로 만들면 몇가지 이점이 있다.
- 소프트웨어로 구현되었던 것을 배제해도 되기 때문에 이식성 높은 코드를 만들 수 있다.
- 시스템에 좀 더 최적화된 형태로 구현 가능하다.
- prefetch를 위해 명령어 bandwidth를 낭비하지 않아도 된다.
하지만 하드웨어로 prefetch를 구현하기 위해서는 꽤나 생각해야할게 많다.
prefetch 된 데이터를 cache에 바로 넣을 것인가? 넣는다면 어느 레벨 캐시에 넣을 것인가? 언제 prefetch를 할 것인가? 등 여러가지를 고려해야한다.
ㄱ. Simple Sequential Prefetching
Cache miss가 날 경우 2개의 연속적인 Memory block을 미리 fetch해두는 방법이다.
“Adjacent Cache Line Prefetch”나 인텔에서는 “Spatial Prefetch”라고 부르기도한다.
미리 N개를 갖고 왔을때 만약 다음에도 Sequential한 block을 요할 경우 차후 N-1번까지는 Cache miss를 피할 수 있다.
ㄴ. Stream Prefetching
Simple Sequential Prefetching의 경우 N개를 갖고왔다고 해도 차후 N번째에 대해서는 결국에는 miss가 일어난다.
때문에 아예 연속적인 데이터를 순차적으로 갖고와두면 어떨까 하는 생각에서 만들어진게 Stream Prefetching이다.
기본적으로 Stream Buffer가 미리 다음 Address에 대해서 데이터를 갖고와서 갖고 있다가 Cache에 밀어넣어주는 형태로 구현이 된다.
일종의 슬라이드 윈도우 방식을 생각하면 편하겠다.
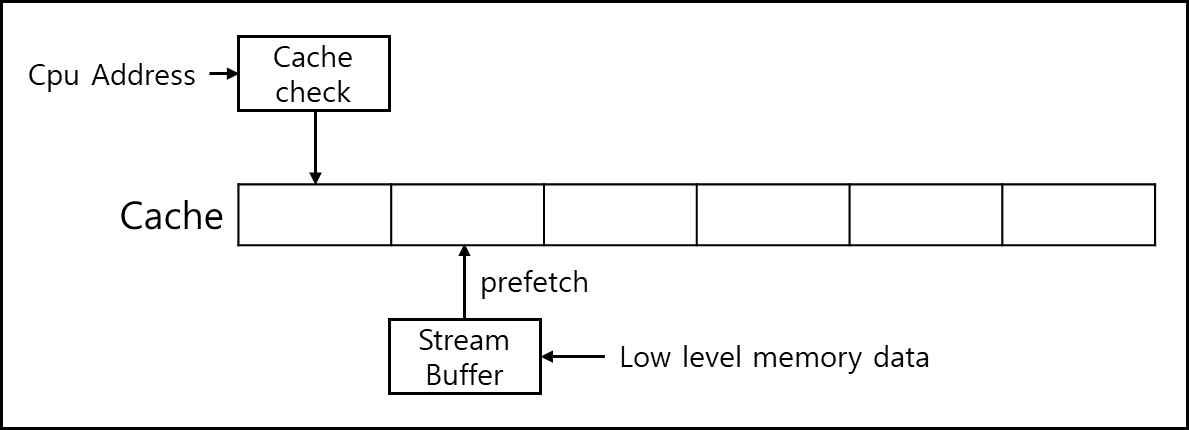
ㄷ. Strided Prefetching
위의 2 방식은 정말로 순차적인 데이터일때만 효과적이다. 만약에 순차적이지 않고 일종의 Stride를 두고 엑세스를 한다면 어떨까?
아래의 코드를 보자
1
2
3
for(i=0;i<N;i++) {
A[i*1024]++;
}
loop안의 데이터가 (1024 * 자료형 크기) 만큼의 stride를 갖고 있다.
프로그램상에서 이런 경우는 생각보다 꽤 잦으며 앞선 Sequential한 방법으로는 해결하기 어렵다.
이런 경우를 대비하여 prefetch 를 하는게 바로 Stride Prefetching이다.
아래의 그림을 보자
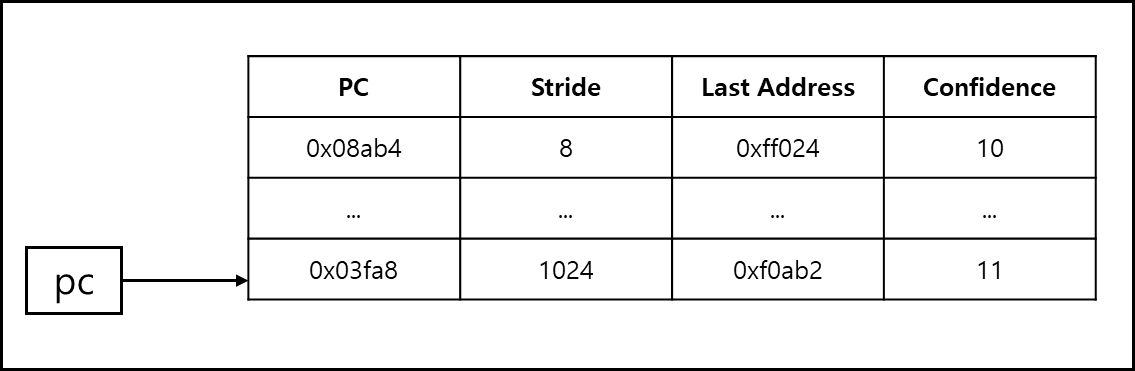
기본적으로 Strided prefetch를 위한 PC 기반의 table이 있다.
이 table은 PC값, Stride, 마지막 주소, confidence값(위 예시의 경우 2 bit로 이루어짐)을 갖고 있다.
PC에서 엑세스할때 이전 PC값을 빼서 stride 값을 산정하여 기재한다.
이후에 또 엑세스할때 이전 PC값을 뺐을때 이전과 동일한 stride가 나온다면 confidence 값을 1 증가시키고 다른 stride라면 1을 감소시킨다.
이후 엑세스할때 동일한 stride가 나온다면 confidence값은 이진수로 11, 즉 3이 된다.
이 값은 2bit로 나타낼 수 있는 최대치이고 confidence가 최대치를 찍었으니 믿을만한 값이 된다. 이후로는 prefetch를 하는 것이다.
이 방법은 꽤나 성능이 좋아서 현대 프로세서에서 많이 차용하고 있는 방식이다.
참고자료
- Computer Organization and Design-The hardware/software interface, 5th edition, Patterson, Hennessy, Elsevier
- 서강대학교 이혁준 교수님 강의자료 - 고급 컴퓨터 구조
- Computer Architecture, Subtitle:Engineering And Technology ,Author:Dr Ranjani Parthasarathi
- ScienceDirect - Set-Associative Cache
- Inoue, Koji, Tohru, Ishihara, and Kazuaki, Murakami. “Way-Predicting Set-Associative Cache for High Performance and Low Energy Consumption”. (1999).