컴퓨터 구조 - 병렬 처리 - Cache coherence
병렬 처리 - Cache coherence
1. 개요
UMA든, NUMA든 각 프로세스나 코어는 캐시를 가진다.
UMA인지 NUMA인지를 구분하는게 메모리이기 때문이다.
이 경우 매우 일이 복잡해지는데 각 코어나 프로세스가 가지는 캐시 값을 동기화해주어야하기 때문이다.
이를 Cache coherence라고 하며 이를 위한 여러가지 방법들이 있다.
2. 기본적 접근법
다중 프로세서에서 실행되는 프로그램은 일반적으로 동일한 데이터를 여러 캐시에 복사해 둔다. 별로 드문상황이 아니고 꽤나 자주 일어나는 상황으로 소프트웨어에서 공유를 회피하려 하기보다는, SMP(Symmetric Multiprocessor) 시스템에서 하드웨어 프로토콜을 사용해 캐시 일관성을 유지한다.
이 경우 아래의 두개가 공유 데이터 성능의 핵심이다.
1) 캐시 값 이동
하나의 캐시에서 다른 캐시로 데이터를 옮겨서 사용한다. 원격에 할당된 공유 데이터 접근 시 지연(latency)과 메모리 대역폭 요구를 모두 줄인다.
2) 캐시 값 복사
동시에 읽히는 공유 데이터에 대해, 각 캐시가 로컬에 복사본을 만들어서 사용한다. 접근 지연과 읽기 시 발생하는 경쟁(contension)을 모두 줄여준다.
3. 캐시 동기화 규약 (Cache Coherence Protocols)
1) 스누핑(Snooping)
A. 개요
- 데이터를 복사한 모든 캐시는 해당 블록의 공유 상태 정보도 로컬에 보유하되, 중앙집중식 상태 정보는 없다.
- 모든 캐시는 버스나 스위치 같은 브로드캐스트 매체를 통해 서로 접근 가능하다
- 각 캐시 컨트롤러는 매체를 감시(snoop)하여, 버스나 스위치 요청 시 자신이 해당 블록을 가지고 있는지 판단한다.
- 대체적으로 서로 공유하는 회로가 복잡하기 때문에 확장성 면에선 떨어진다.
B. 세부 설명
각 데이터를 갖고 있는 캐시의 경우 두 가지의 경우로 서로 Coherence를 맞춰줄 수 있다.
다른 캐시의 데이터를 Invalid하게 만들기 위해 다른 캐시에 Invalidation을 보내는 방식이거나 혹은, 다른 캐시에 자신의 값을 보내주는 Update 방식이 있다. Update 방식의 경우 core를 연결하는 bus의 대역폭을 많이 먹기 때문에 잘 사용하지 않으며 Invalidation 방식이 주를 이룬다.
2) 디렉토리 기반(Directory based)
A. 개요
- 물리 메모리 블록의 공유 상태 정보를 단 하나의 장소(디렉토리)에만 저장이다.
- 브로드캐스트가 아닌 포인트 대 포인트(point-to-point) 통신 방식이다.
- 스누핑에 비하여 확장성(scalability)이 우수한 구조이다.
4. 캐시 동기화 세부 설명
※ 캐시 동기화 대상
지금 설명하는게 L1 캐시 대상인지, 혹은 L2 캐시대상인지 먼저 설명하고 가는게 맞는것 같다.
아래에서 설명하는 캐시 동기화의 대상은 L2 캐시대상이다.
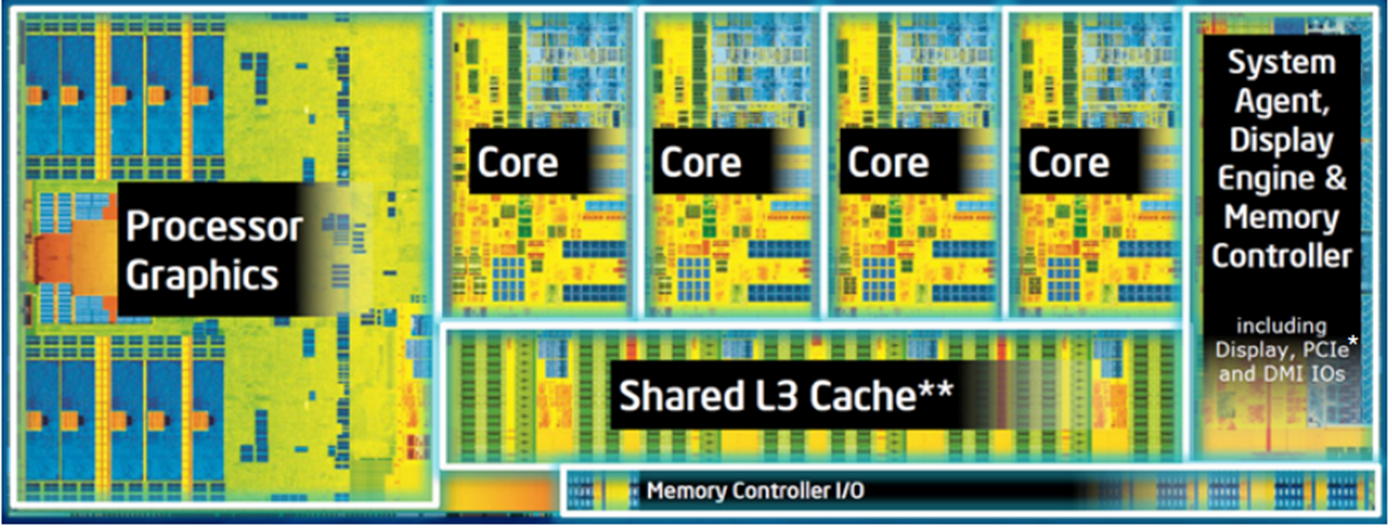
출처 : Introduction to Intel® Architecture, The Basics
L1과 L2는 어디에 있냐고 물어볼 수 있는데 기본적으로 L2까지는 코어에 붙어있고, 여기서 말하는 동기화의 대상은 코어가 각자 갖고 있는 캐시를 대상으로하고 있다. 그리고 L2 캐시가 기본적으로 L1 캐시를 포함하고 있는 형태(Include)의 구조이기 때문에 캐시 동기화가 가능하다.
물론 L2에서 바뀌면 L1캐시에, L1에서 바뀌면 L2 캐시에 Update해주는 로직은 추가적으로 필요하다.
※ 캐시 상태 정의
캐시 공유 이전에 write back 방식의 캐시 상태는 총 3가지가 있었다.
- Invalid
- valid dirty
- valid non-dirty
위 상태를 아래와 같이 바꿔서 부르기로 정의하고 들어가겠다.
- Invalid
- valid dirty -> Modified, Exclusive
- valid non-dirty -> Shared (잠재적으로 공유되어있을 수 있음)
1) Snooping
a. Write-thru Invalidate
아래와 같은 상황이라고 가정해보자.
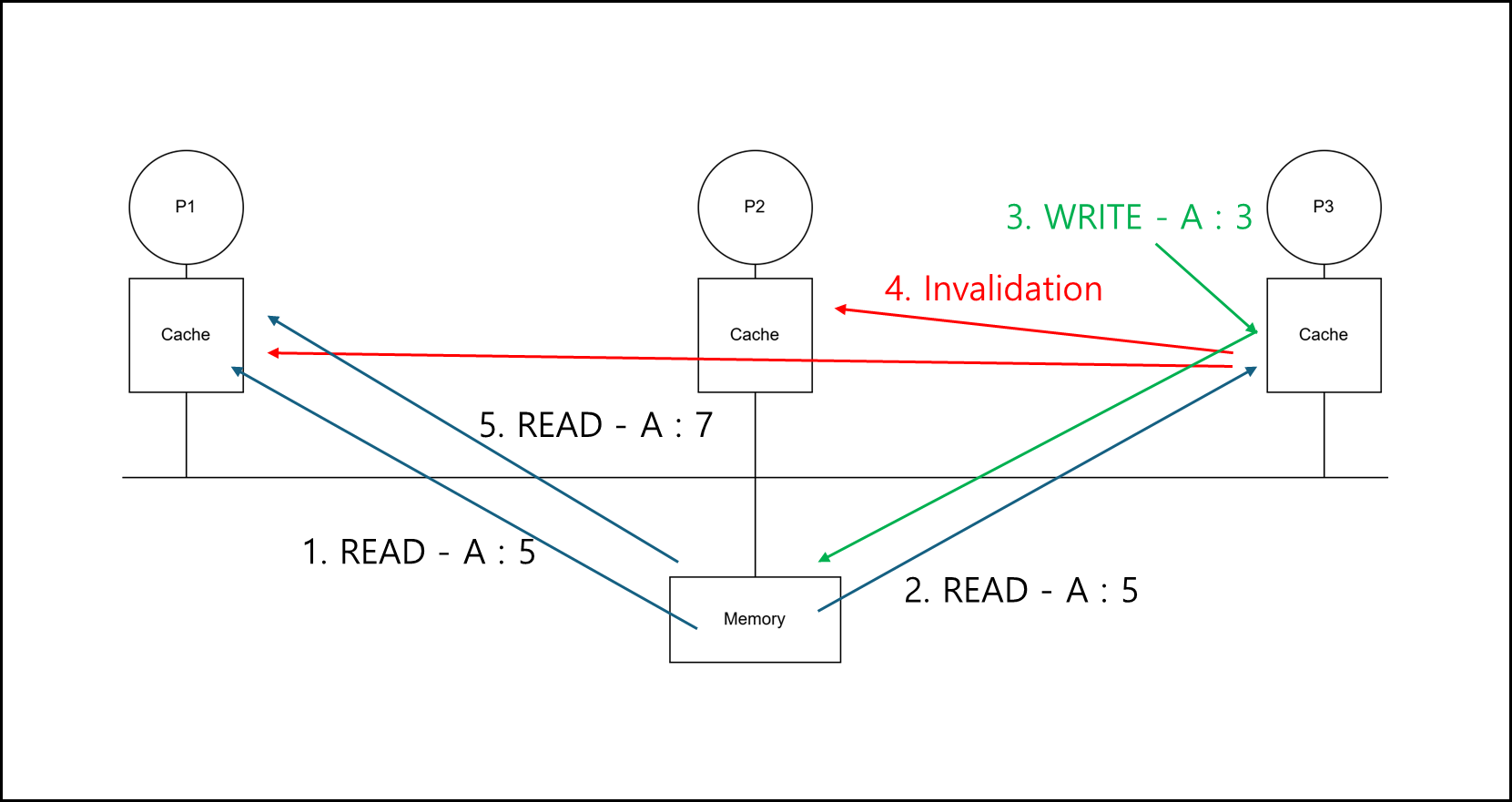
Write-thru 캐시 구조에 Update가 아닌 Invalidate로 Cache 동기화를 하는 구조이다.
아래의 순서대로 동일한 캐시 slot의 요청이 있다고 해보자.
1
2
3
4
P1 : READ A
P3 : READ A
P3 : WRITE A
P1 : READ A
그러면 아래와 같이 작동하게 된다.
- P1 : A:5 값을 메모리에서 갖고옴
- P3 : A:5 값을 메모리에서 갖고옴
- P3 : A를 7로 변경하고 메모리에 반영, 동시에 전체 프로세서들에게 A값을 Invalid 처리하라고 Invalidation을 전송
- P1 : 갖고 있던 A값을 Invalid 처리해버리고, 차후 필요하다면 메모리에서 갖고와서 사용
그림으로 나타내면 아래와 같다.
b. Write-back Invalidate(MSI)
기본적으로 Invalidation을 사용하는 방법이다. MSI라고 줄여 부르는 이유는 Modified, Shared, Invalid 이렇게 세 가지 State를 사용하기 때문이다.
이를 표현하기 가장 좋은건 Finite State Machine(이하 FSM), 유한 상태 기계로 표현하는 것이다.
아래의 FSM은 CPU에서 오는 요청만 그린 것이다.
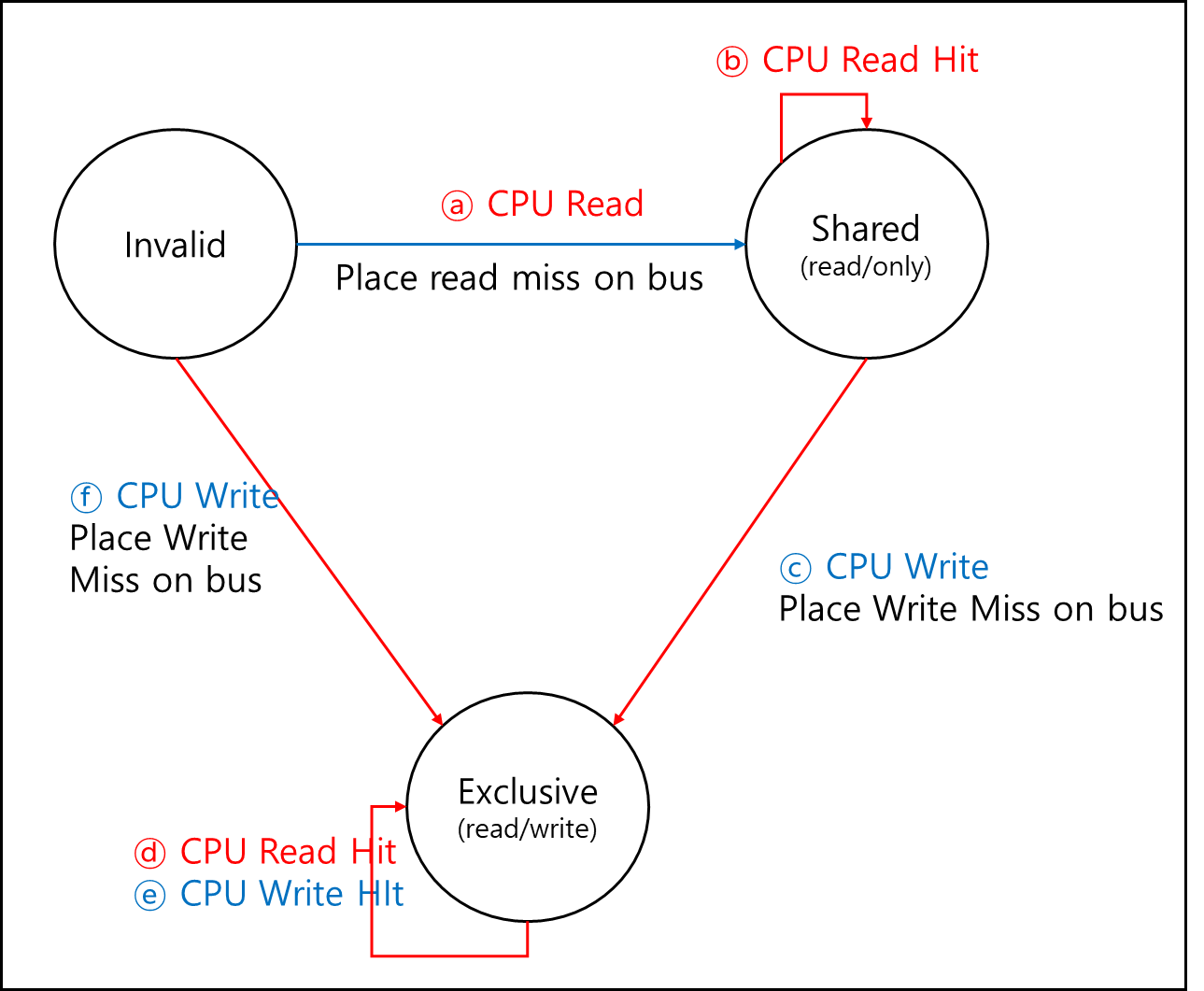
먼저 기본적으로 모든 캐시는 초기에 Invalid 상태로 있다.
- ⓐ : 여기서 cpu가 read 요청을 했을 때 당연히 miss가 나게되고, 메모리 혹은 다른 코어가 갖고 있는 캐시에다가 데이터를 요청하게 된다. 그렇게 갖고온 데이터는 shared 상태가 된다.
- ⓑ : shared인 캐시는 데이터를 갖고 있다는 것이므로 read시 cache hit가 되고 상태는 유지된다.
- ⓒ : shared에서 데이터를 수정하려면 exclusive로 변경해야한다. exclusive로 변경 후 데이터를 수정한다.
- ⓓ : exclusive일때 read는 hit가 나고 상태도 그대로이다.
- ⓔ : exclusive일때 write는 hit가 나고 상태도 그대로이다.
- ⓕ : Invalid일때 어떤 데이터를 쓰게되면 해당 내용을 Cache로 갖고와서 쓰게 되는데 바로 exclusive로 상태를 변경하고 쓴다.
위에는 캐시에 연결된 cpu에서 오는 요청으로 인한 상태 변화만 그린것이다. 아래는 Bus를 통해 다른 cpu에서 오는 요청을 그린 FSM이다.
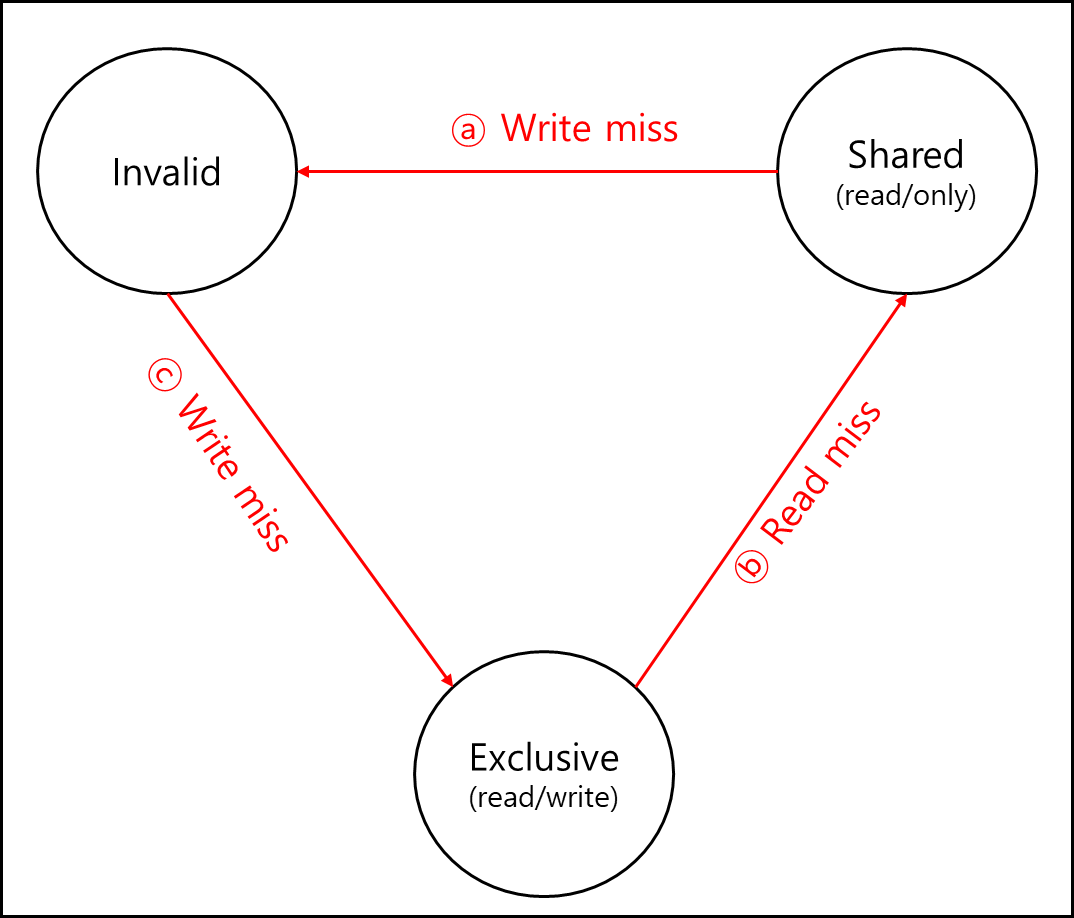
현재 해당 Cache가 있는 코어를 A 코어, 다른 코어를 B코어라고 할때
- ⓐ : B코어에서 A코어 캐시가 갖고 있는 데이터를 Write 하겠다고 수신하면 Shared 상태는 Valid가 되어야한다.
- ⓑ : B코어에서 Exclusive 상태인 데이터를 읽겠다고하면 A코어 캐시에서는 해당 값을 전달 후에 Shared로 상태를 변경한다.
- ⓒ : B코어에서 Exclusive 상태인 A 코어 캐시의 데이터를 쓰겠다고하면 해당 데이터를 보내고 A 코어 캐시 데이터는 Invalid로 변경한다.
아래는 Replacement 정책과 State에 대한 FSM이다.
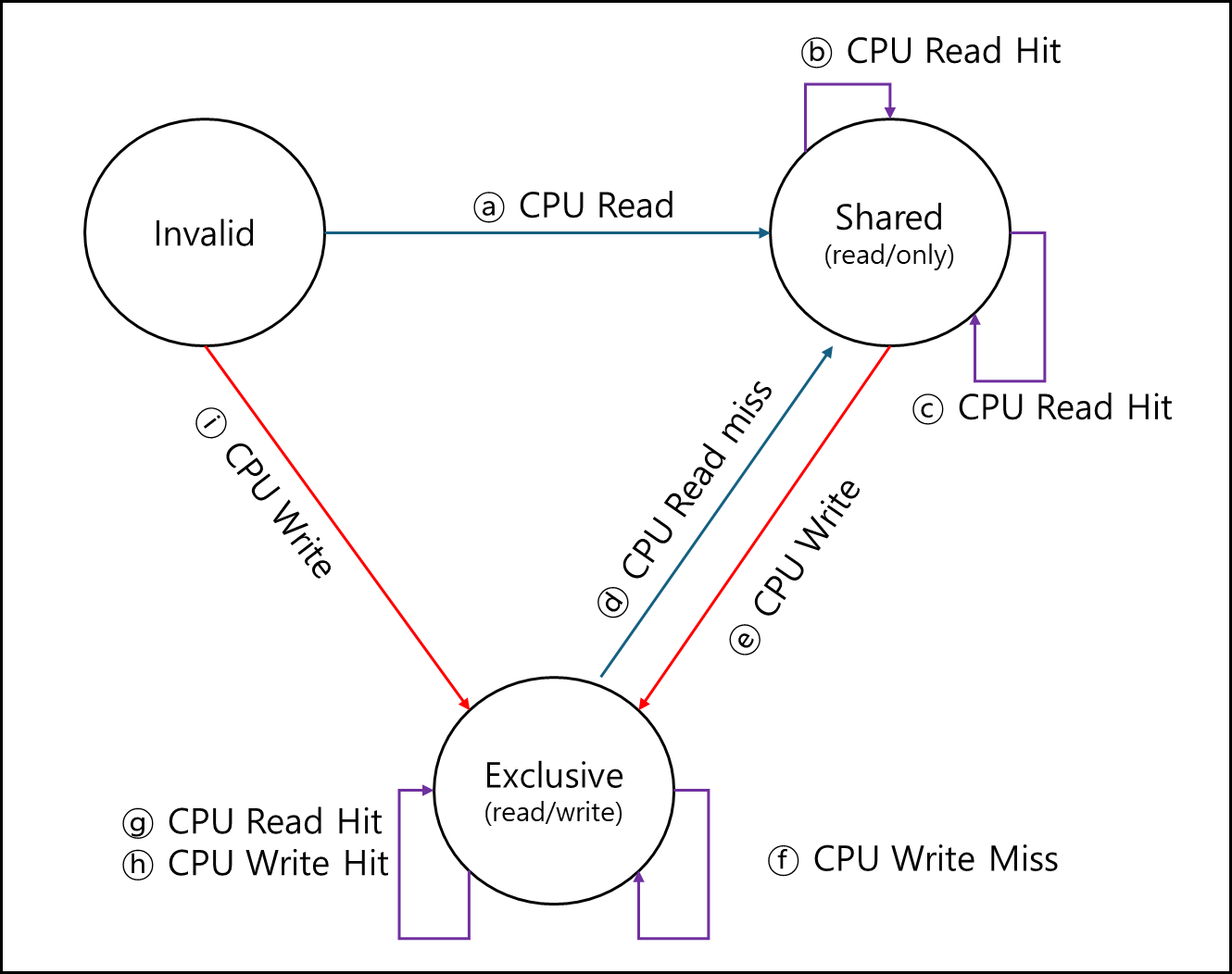
현재 해당 Cache가 있는 코어를 A 코어, 다른 코어를 B코어라고 할때
- ⓐ : A코어 캐시가 캐시 미스가 나서 어떤 값을 하위 메모리 혹은 다시 B 코어 캐시와 같은 다른 캐시에서 갖고오게 되면 기본적으로 Shared로 상태가 세팅된다.
- ⓑ : A코어 캐시에서 해당 값이 Read hit가 났다면 상태가 바뀔일이 없다.
- ⓒ : A코어 캐시에서 해당 값이 Read miss가 났다면 데이터를 갖고오고 나서 Shared로 세팅하기 때문에 상태는 그대로다.
- ⓓ : Exclusive인 캐시 블록이 대체될때 갖고온 데이터 블럭은 Shared로 세팅된다.
- ⓔ : Shared 상태인 캐시 블록 위치에 어떤 데이터를 갖고 와서 써야한다면 Exclusive로 세팅된다.
- ⓕ : 어떤 캐시 블록을 써야한다면 Exclusive 상태로 변경된다. 이는 Shared 였건 Exclusive였건 동일하다.
- ⓖ : 이미 Exclusive인 어떤 데이터를 읽어야한다고 해도 굳이 Shared로 바꾸진 않는다.
- ⓗ : 이미 Exclusive인 어떤 데이터를 써야한다해도 Exclusive는 유지한다.
- ⓘ : 전혀 없는 데이터를 갖고와서 써야한다면 Exclusive로 세팅하고 쓴다.
c. MESI(Modified, Exclusive, Shared, Invalid)
이전에 Modified, Exclusive는 Modified이고 Exclusive는 별도의 상태가 있다. 정확한 정의는 아래와 같다.
- M : 독점하고 있고 변경됨
- E : 독점중이나 변경되진 않음
- S : 공유중
- I : 의미 없음
FSM의 대상 캐시가 프로세서1(이하 P1)에 붙어서 구동되고 있다고 할때 아래의 FSM으로 나타낼 수 있다.
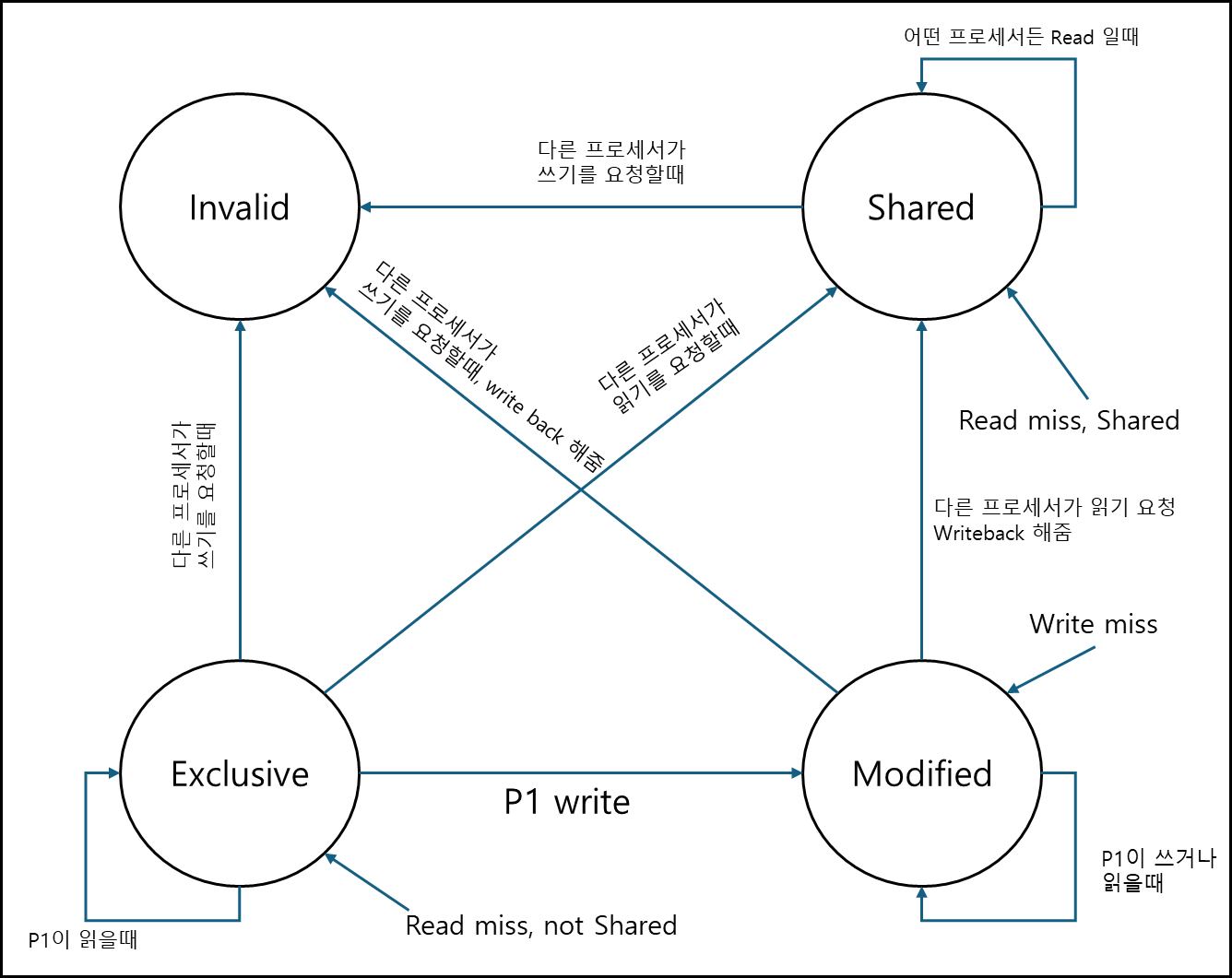
위와 같은 방식은 쓸데없는 브로드 캐스트를 처리하기 위함이고 snooper가 L2 캐시 앞에 붙어서 자신과 관련없는 요청부분은 Ignore해버리기 때문에 처리하지 않아도 되는 부분에 대해서는 L2 캐시에서는 신경쓰지 않아도 된다.
※ Memory Intervention
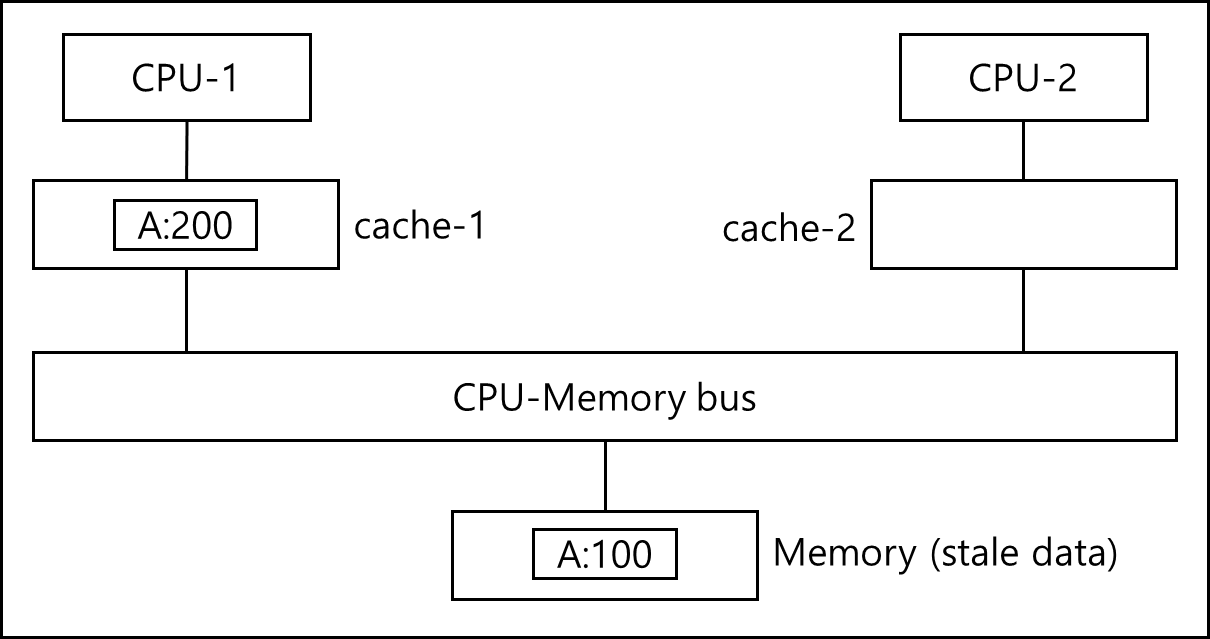
위와 같은 상황이 있다고 하자. MSI, MESI건 write-back invalidate 알고리즘이라고 할때 CPU-2가 A slot에 대한 값을 요청 할 때 Memory와 cache1에 대해 두 군데 모두 요청이 들어간다.
이 경우 가장 최신의 데이터를 주어야한다. 이 경우 어떻게 할 것인가가 Memory Intervention이라고 할 수 있다.
사실 문제는 간단하다, 위 그림을 제대로 다시 그린다면 아래와 같다.
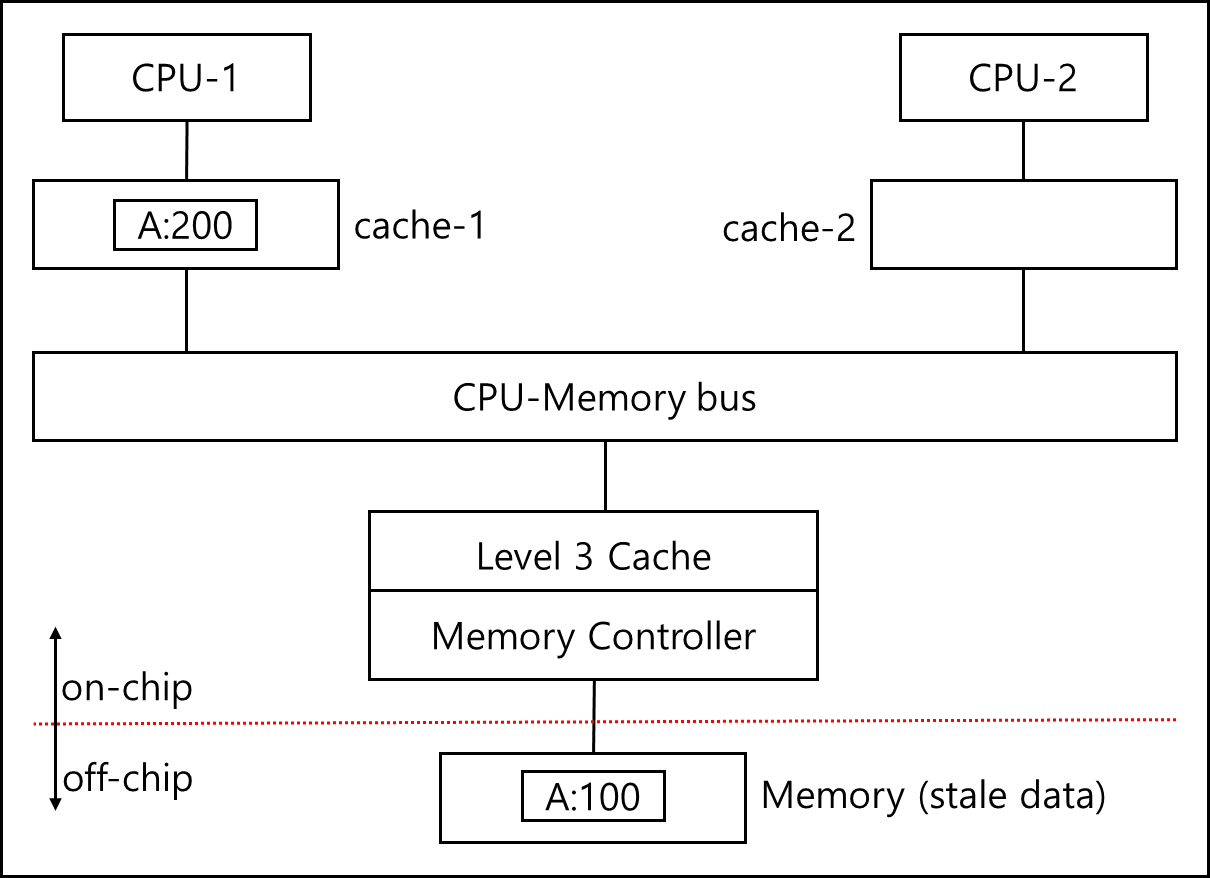
만약, cache1과 l3에 붙어있는 Memory Controller에 요청이 모두 모두 도착한다면 L3에 해당 데이터가 없다면, 메모리 컨트롤러를 통해 Memory로 데이터를 요청할 준비를 하게된다. L2 까지는 on-chip이기 때문에 매우 속도가 빠른 반면, Memory는 off-chip이기 때문에 성능이 매우 느리다. 따라서 메모리 컨트롤러에서 준비하는 도중에 cache1에서 데이터를 전달하게 되고, 이 신호를 메모리 컨트롤러에서 수신하게 되면 메모리에 요청하려 했던 것을 취소하면 된다.
그 외 방식
위에서 언급한 방식 외 MESIF 방식과 MEOSI 방식이 있다.
MESIF
Intel에서 많이 사용하는 방법으로 기본적인 MESI 방식에서 F 상태가 추가된 방법이다. F 상태는 Forward의 약자로, 공유된 캐시 라인을 여러 코어가 갖고 있어도 오직 한 캐시만 응답자로 지정해 중복 응답을 막고, 공유 데이터를 메모리보다 더 빠르게 다른 캐시에서 가져오도록 하는 방식이다.
MEOSI
AMD64 아키텍처에서 사용하는 방식으로 기본적으로 MESI 상태에서 O 상태가 추가된 방법이다. O 상태는 Owned의 약자로, 한 캐시가 해당 라인의 소유권을 유지한 채 다른 sharer들이 함께 복사본을 가질 수 있게 하며, 이 점이 수정된 블록을 메모리에 먼저 되돌리지 않고도 공유하게 해서 coherence traffic를 줄이게 하는 방식이다.
※ 한번 더 확인해야함
2) Directory based
a. Scalable Approach : Directories (Standford)
스탠포드에서 만든 방식이며, 교수님이 이 방식에 대해서 설명하실 때 실제로 이 방식이 제품화된 것은 보신적이 없다고 했다.
여러가지 이유가 있을 수 있다고 하셨는데, 일단은 느리기 때문이 아닌가 싶다.(쓰기에 대해서 메모리에 갔다오긴 해야하니)
컨셉 자체는 매우 간단하다, 어떤 캐시가 어떤 데이터를 갖고 있는지 중앙화된 무언가가 있는 것인데, 이는 메인 메모리에서 갖고 있는 형태이다.
각 데이터 블록 옆에 상태 비트와 어떤 cpu가 갖고 있는지 bit로 표현되는 값과 id를 표기하는 비트가 달려있다. 상태 비트는 2비트이고 어떤 CPU가 갖고 있는지 표현되는 비트인 Directory 비트는 cpu가 10개라면 10bit이다, ID를 표기하는 비트 역시 Directory 비트와 동일하다.
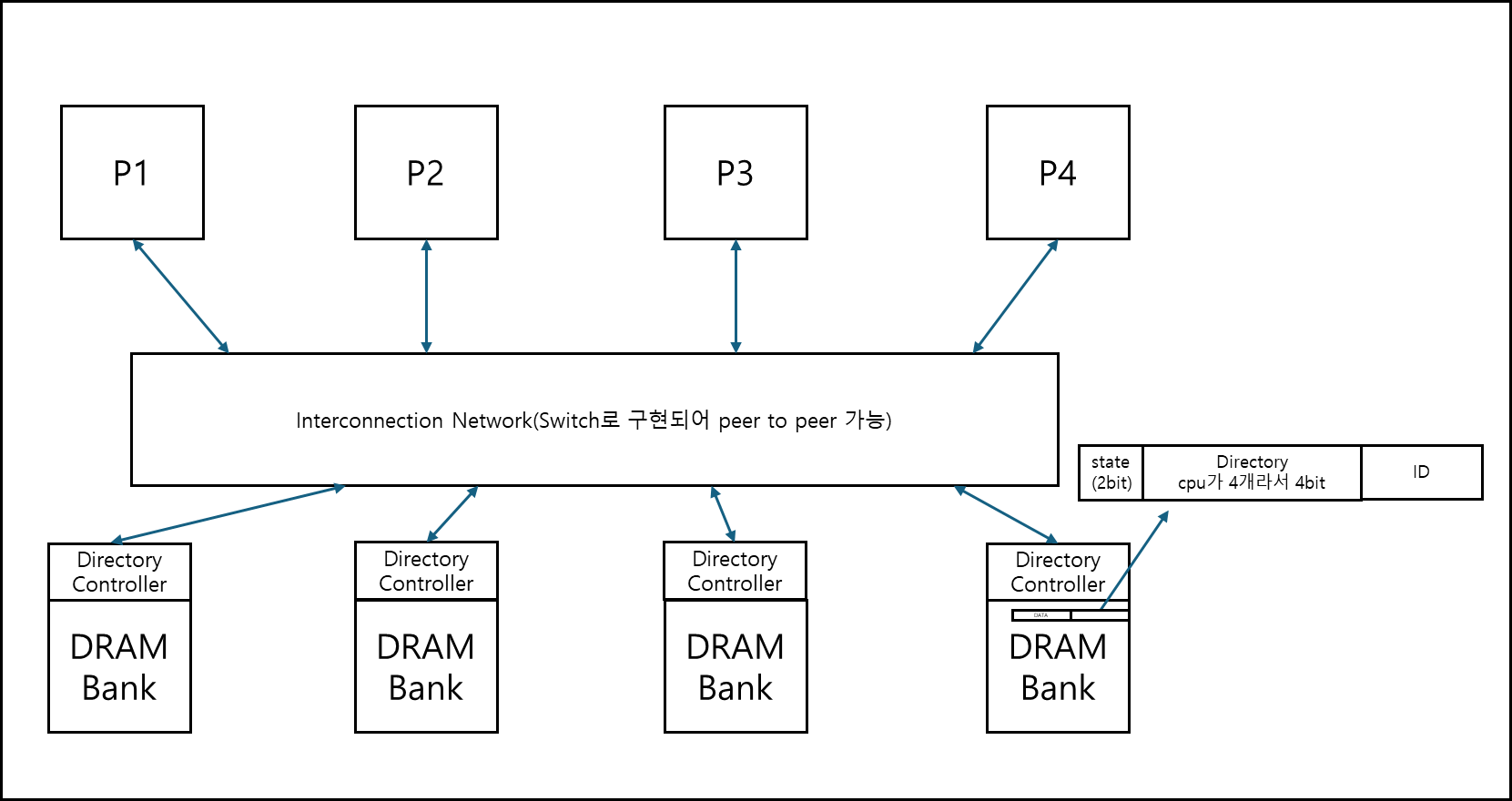
위와 같이 운용하기 위해서는 Cache와 메인메모리에 있는 Directory 부분 둘다 4개의 state를 가져야한다.
ㄱ. 캐시 상태
- C-invalid (= Nothing): 사용 불가, 쓸데없는 데이터가 담긴 상태다.
– C-shared (= Sh): MSI에서 Shared와 동일하다.
– C-modified (= Ex): MSI에서 Modified와 동일하다.
– transient (= Pending): 데이터를 캐시까지 전달 중이거나 요청한 데이터를 대기중인 상태이다.
ㄴ. 디렉토리 상태
– R(dir): 해당 데이터는 캐시에서 읽기만 했다, 다수일수도있고 한개 일수도 있으며 변경되지 않았다.
– W(id): 특정 캐시가 데이터를 쓰고 있다. id 값을 이용하면 어떤 캐시인지 알 수 있다.
– TR(dir): 디렉토리에서 대상 캐시에 대해서 Invalidation을 보냈고 그에 대한 확인을 기다리고 있는 상태이다.
– TW(id): 디렉토리에서 대상 캐시를 최신화하기 위해 데이터를 전달하고 있는 중이다.
5. 병렬 프로세스의 성능을 떨어뜨리는 요인
1) False sharing
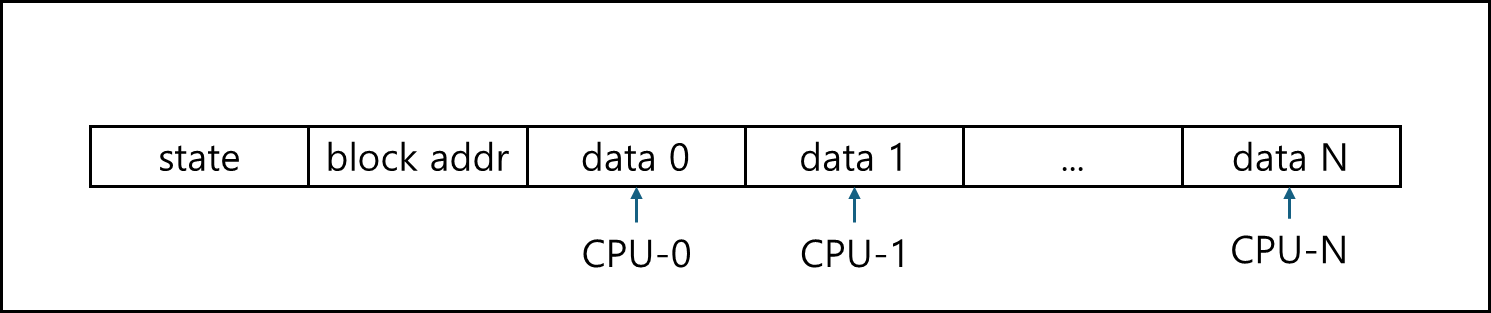
위와 같이 같은 캐시는 사용하나 실제 사용하는 데이터는 다른 블록에 위치 할때, 가짜 공유라고 한다.
이는 실질적으로 데이터 공유를 하지도 않는데도 불구하고 단일 CPU로 돌릴때보다 더 성능이 떨어질 수 있다.
이런 경우 캐시 placement를 조정할 필요가 있다.
※ 추가 업데이트 및 검증 예정이고, 올라간 부분도 아직 완벽하지 않으니 참고만 바란다.
참고자료
- Computer Organization and Design-The hardware/software interface, 5th edition, Patterson, Hennessy, Elsevier
- 서강대학교 이혁준 교수님 강의자료 - 고급 컴퓨터 구조
- 서강대학교 박성용 교수님 강의자료 - 병렬 분산 컴퓨팅
- Introduction to Intel® Architecture, The Basics
- WIKIPEDIA - MOESI protocol