컴퓨터 구조 - CPU 구조 - Cache 기초
Cache
1. 개요
캐시(Cache)란 CPU 연산에 비해 상대적으로 느린 메모리 접근 속도를 커버하기 위해 만든 임시 저장장소이다.
기본적으로 지역성에 근거하여 빨라질 것이라는 기대아래 설계된 것으로, 실제로 Cache 덕분에 성능은 급격하게 올라갔다.
※ 지역성이란?
기본적으로 공간 지역성(Spatial Locality), 시간 지역성(Temporal Locality)으로 나뉜다.
공간 지역성은 비슷한 주소 공간에 있을 경우 참조될 가능성이 높다는 것이고 시간 지역성은 최근에 참조된 것이 직후에 참조될 가능성이 높다는 것이다.
2. 캐시의 전체적인 구조
기본적으로 캐시뿐만 아니라 모든 메모리는 계층 구조로 되어있다.
아래의 그림을 보자
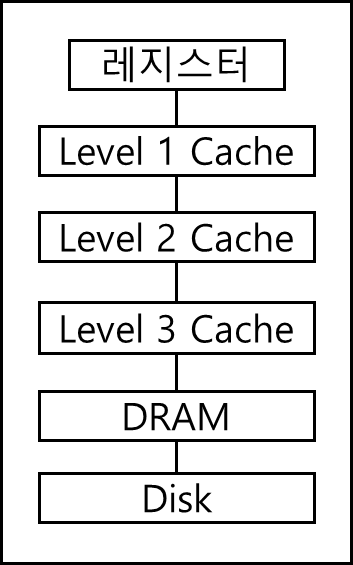
아래 표는 위 그림의 구조에 접근 시간, 용량, 그리고 관리 주체에 대한 표이다.
| Memory Type | Access Time | Capacity | Managed by |
| Register | 1 cycle | ~500B | Software/Compiler |
| Level 1 Cache | 1~3 cycles | ~64KB | Hardware |
| Level 2 Cache | 5~10 cycles | 1~10MB | Hardware |
| Level 3 Cache | 14~80 cycles | 11~50MB | Hardware |
| DRAM | ~ 100 cycles | ~16GB | Software/OS |
| Disk | 10^6 ~ 10^7 cycles | TB이상 | Software/OS |
범위가 완전히 맞지는 않으니 참고만 하길 바란다. 아무튼 표를 보면 레지스터 뿐만아니라, Level1 Cache, Level2 Cache, DRAM, DISK 순으로 빠르고 작은것에서 느리고 큰것으로 내려가는 것을 볼 수 있다.
3. hit 방식에 따른 구조
1) Direct-mapped
아래의 그림을 보자.
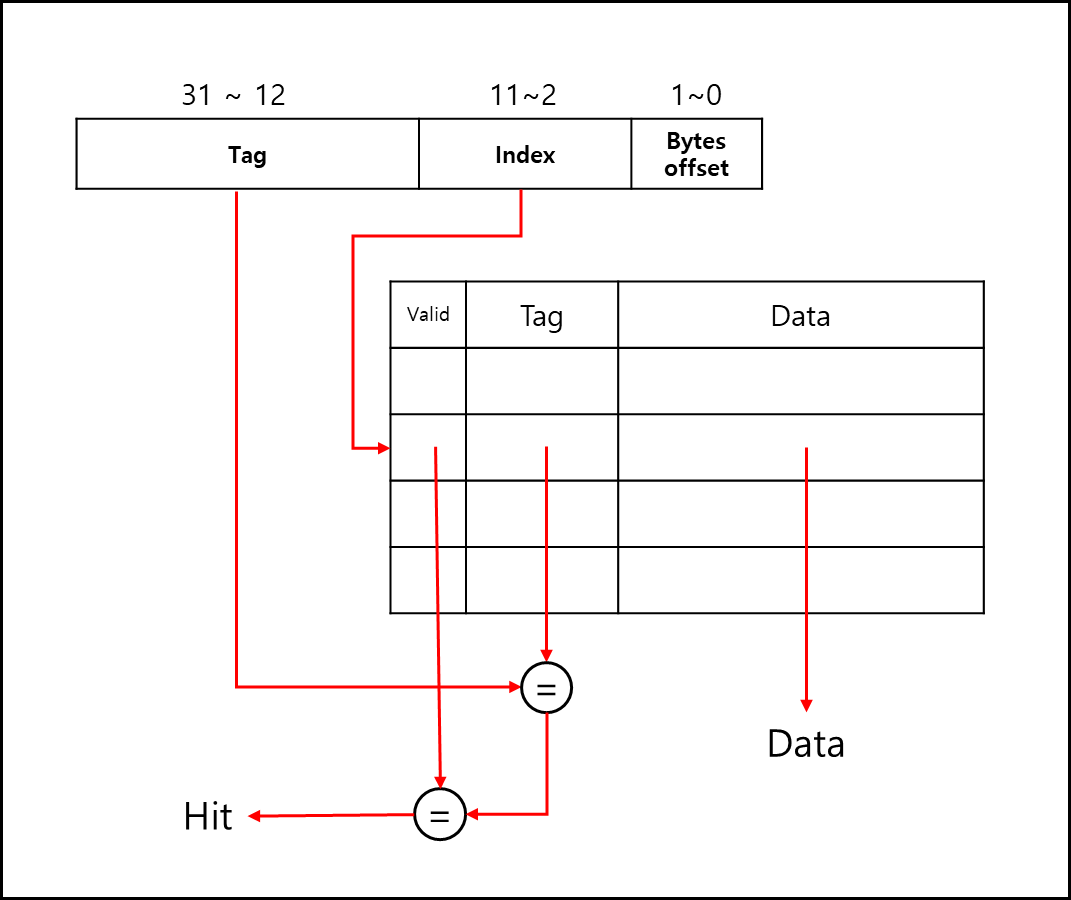
주소는 Tag와 Index로 분할되고, byte offset은 몇 비트 아키텍처냐에 따라 달라진다. 일단 32bit 기준이라면 2비트는 offset으로 두고 index를 기준으로 찾고, 찾은게 맞는지 Tag로 검색하는 방식이다.
cache 테이블이 있고, index로 주소의 Index 영역을 사용한다.
이후 Tag로 값을 확인한다.
가장 기초적인 방식이다. 하지만 여러 문제점이 있다.
각 index에 대해서 하나밖에 연결이 안되니까 conflict 율이 높다.
이는 곧 cache miss로 이어지기 때문에 별로 좋지 않다.
2) Fully associative
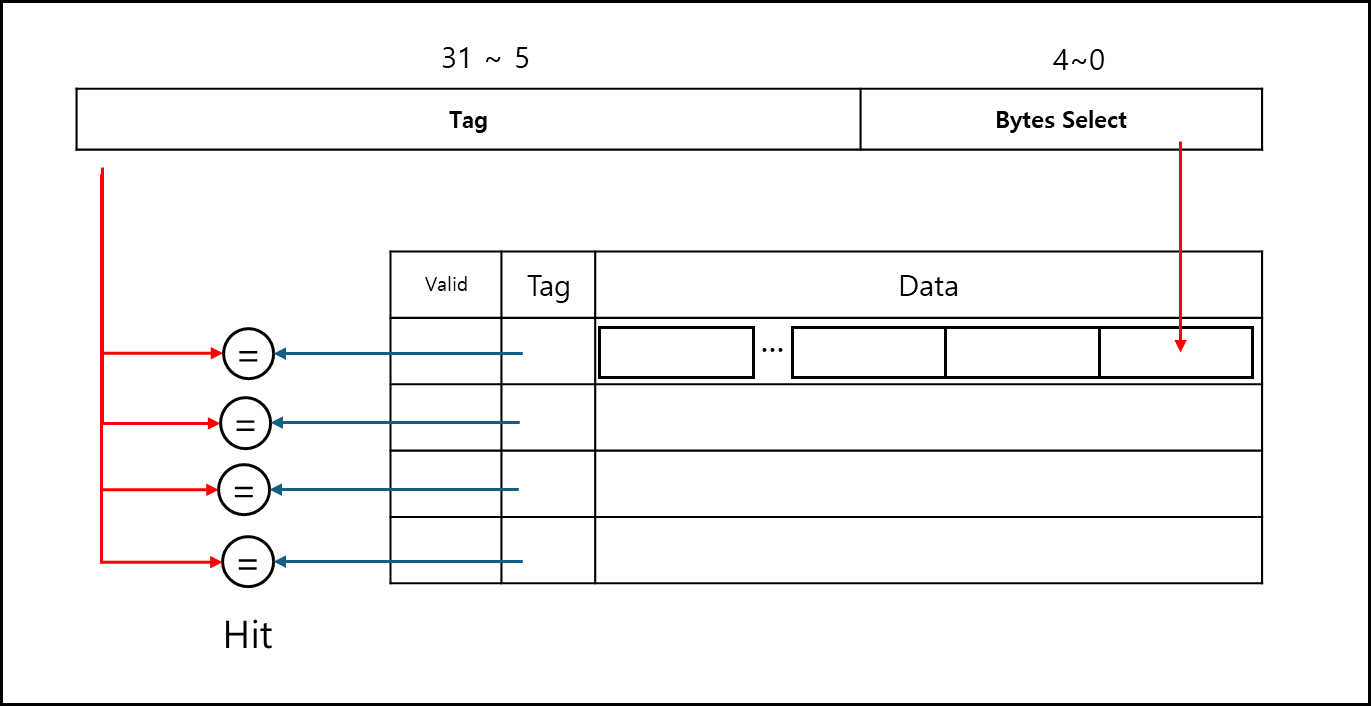
아예 빈자리가 있으면 넣을 수 있게 만든 캐시 방식이다.
캐시를 읽어들일때마다 전체를 다 체크하기 때문에 느리고 이런 구조는 CAM(Content Addressable Memory)를 써야하는데 이게 비싸고 복잡하다.
3) Set associative
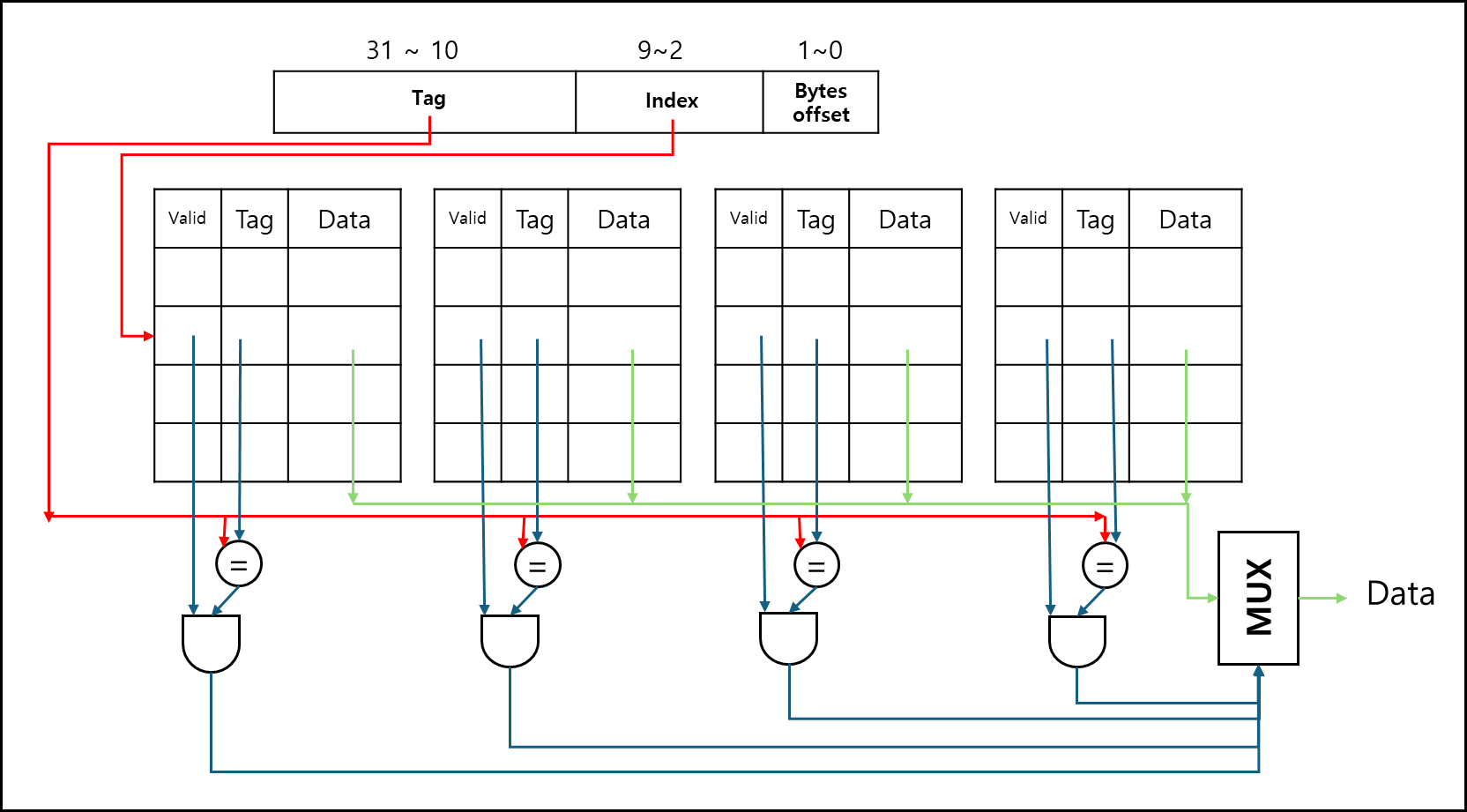
위와 같이 각 Index별로 몇 가지를 두는 것이다. 이렇게 되면 Direct Mapped cache에 비해 conflict도 적어지고 conflict가 적어지니 hit 율도 많이 올라간다.
4. 메모리 동기화에 따른 구조
연산 이후에 어떤 값을 메모리에 기재해야할 때 어떻게 할 것인가에 대한 내용이다.
해당 값이 캐시에 있다면 어떻게 할 것이며, 캐시에 없다면 어떻게 할 것인지 여러가지 방법이 있다.
아래의 표를 보자.
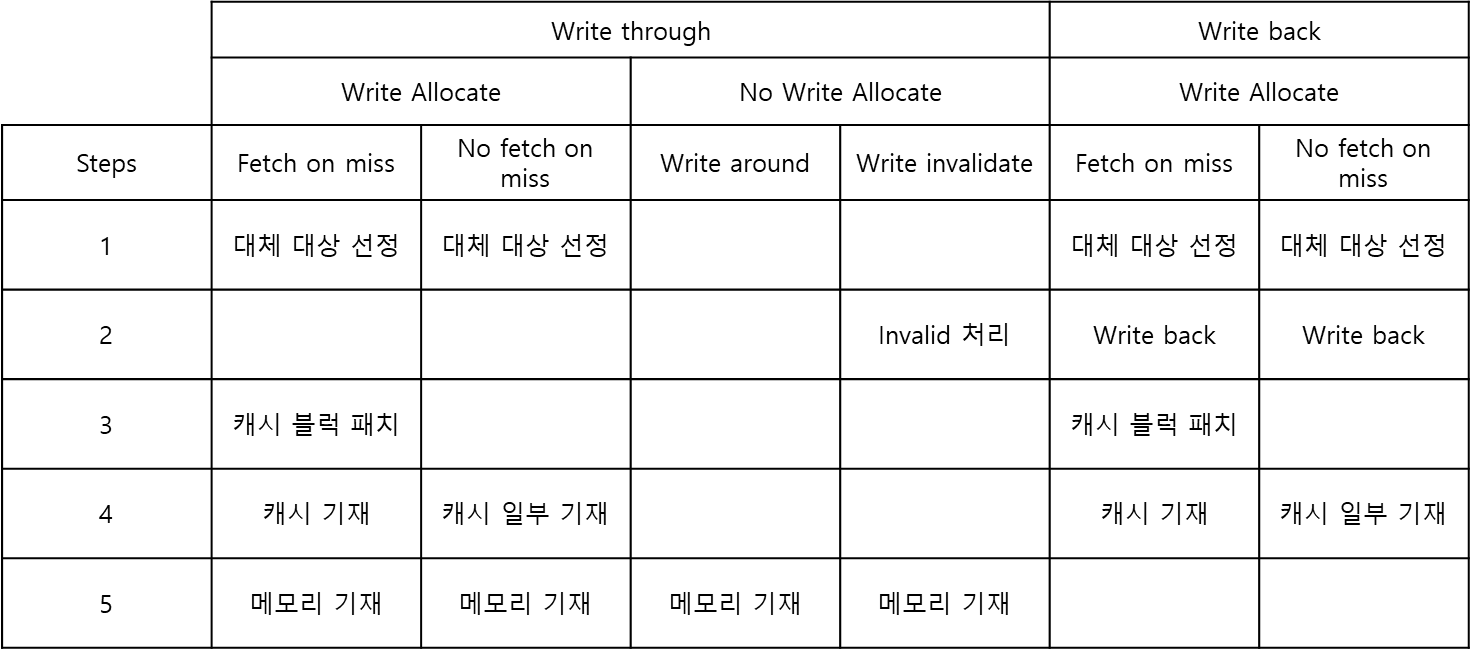
위의 표를 보자 Write through와 Write back이 가장 큰 카테고리에서 시작한다.
Write through는 해당 값이 캐시에 있을 때 Cache와 메모리에 둘다 기재하는 방식이고 Write back은 Cache에만 기재하는 방식이다. Write back으로 처리한 Cache data는 차후 Replacement가 될 때 그 값을 메모리에 기재하고 Cache에서 제거한다.
Write through와 Write back의 경우 하위에 Write allocate와 No write allocate 항목이 있는것을 볼 수 있는데 이는 cache miss가 났을 때 정책이다.
쓸때 cache miss가 났을 때 Write allocate는 Memory에서 cache로 갖고 와서 쓰는 것이고 (굳이 cache로 갖고 오는 이유는 Locality에 따른 cache hit로 성능 향상을 기대 할 수 있기 때문이다) No write allocate는 Memory에서 Cache로 갖고 오지 않는 것이다.
fetch on miss는 전체 블록을 갖고 와서 쓰는 것이고, no fetch on miss는 전체 블록이 아닌 일부만 적는 것이다. write around는 메모리에 바로 기재하는 것이고, Write invalidate는 캐시에 해당 값이 있을 경우 해당 cache 블록을 invalid로 바꾸어 다음에 읽을 때 새로 갖고오게끔 하는 것이다.
※ 참고
교수님께서 말씀하시길 아래의 경우는 일반적이지 않고, 특수한 캐시 구조라고 하셨다.
- Write through - Write allocate - No fetch on miss
- No write through - No write allocate - Write invalidate
- Write back - Write allocate - No fetch on miss
5. Replacement Policy
캐시가 전체 데이터를 담을 수 없기 때문에 필연적으로 캐시의 데이터를 제거하고 대체하는 작업이 수반되어야한다.
이 과정에서 어떤 데이터를 제거하고 새 데이터로 대체할 것인가에 대한 정책이 필요한데, 이게 바로 Cache Replacement Policy이다.
종류에는 아래와 같은 것들이 있다.
- Least Recently Used(LRU)
- Least Frequently Used(LFU)
- Not Most Recently Used(NMRU)
- Non Recently Used(NRU)
- First In First Out(FIFO)
보면 알겠지만 기본적으로 LRU에서, 나머지는 LRU 비슷한 것들이라고 볼 수 있다.
※ 참고
Direct-Mapped Cache는 Replacemen Policy가 필요없다. Index가 정해져있기 때문이다.
Set Associative Cache의 경우 동일한 index에 n개의 (n-way일때) 캐시 중에서 대체 대상을 골라야하기 때문에 정책이 필요하며
Fully Associative Cache는 index외에 전체에 대해서 고르는 것이므로 정책이 필요하다.
참고자료
- Intel 아이스레이크 스펙
- Computer Organization and Design-The hardware/software interface, 5th edition, Patterson, Hennessy, Elsevier
- 서강대학교 이혁준 교수님 강의자료 - 고급 컴퓨터 구조