하드웨어 구조 - SSD
SSD
1. 구조
기계적인 장치로 데이터를 읽고 쓰게 만들어진게 HDD라면 SSD는 전기적인 장치로 데이터를 읽고 쓰게 만들어졌다.
SSD의 구조는 아래와 같다.
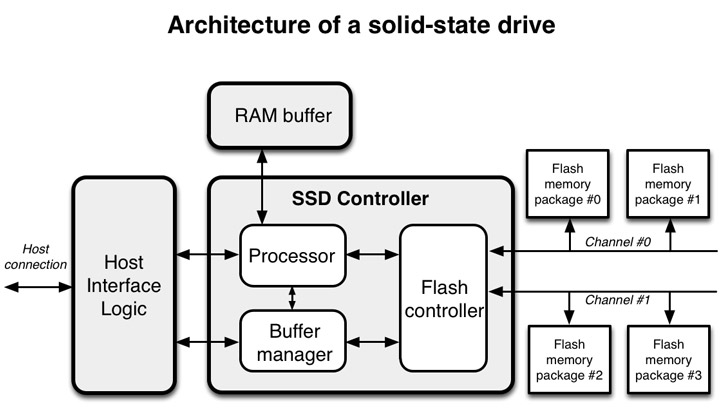
출처 : https://codecapsule.com/wp-content/uploads/2014/02/ssd-architecture.jpg
사용자의 요청이 Host Interface를 통해서 들어오게 된다. 여기서 말하는 Host Interface는 현재 기준 SATA 혹은 PCle타입이다. 이러한 타입으로 연결되어 들어오는 데이터는 프로세서의 명령을 받아 플래시 컨트롤러로 이동되게 되어 각 플래시 메모리 패키지에 쓰여지거나 혹은 플래시 메모리 패키지에서 읽어온 데이터를 다시 반출하기도 한다. 이 과정에서 SSD에 자체적으로 달린 DRAM(위 그림에서는 RAM Buffer)은 캐싱 역할을 해서 데이터를 더욱 빨리 읽어오는 역할을 하거나 혹은 맵핑 정보를 저정하는데 쓰인다. 이 DRAM 사이즈도 막 정해지는 것이 아니다. 아래에서 좀 더 세부적으로 설명할 것이다.
2. 데이터 저장 방식
앞서 HDD에서 CHS 방식의 주소 지정 대신 LBA 방식으로 상대적인 섹터의 위치를 표기하는 방식으로 데이터의 위치를 표기한다고 했는데, SSD의 경우 HDD를 대체하기 위해서 나왔고, 그 때문에 SSD도 LBA 방식의 데이터 접근법을 지원한다. (그래서 SSD도 블록 장치이다, 블록 단위 읽기 쓰기를 지원하기 때문이다)
그렇다고 SSD가 HDD처럼 여러개의 플래터(Platter)로 이루어져있다는 뜻은 아니다. 최근에 나온 대부분의 플래시 메모리는 NOR 방식이 아닌 NAND 방식의 플래시 메모리로 이루어져있는데 가장 작은 단위는 셀(Cell)이라고 하며 이 셀은 페이지(Page)로 묶여있으며 이 페이지는 블록(Block)으로 묶여 있다. 대략 128 ~ 256개의 페이지 단위로 블록을 이루며 블록(Block)은 다시 플레인(Plane)으로 묶여 있다.
여기서 말하는 가장 단위인 셀의 구조는 아래와 같다.
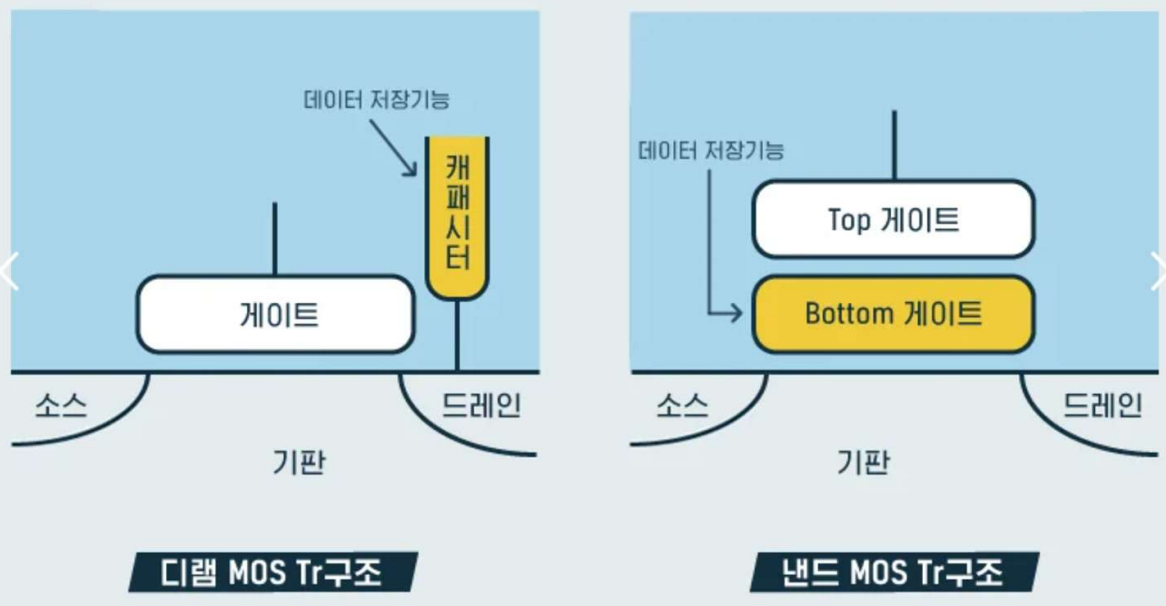
DRAM은 캐시피터가 전자를 가지며 데이터를 저장하고 있지만 NAND SSD의 경우 플로팅 게이트라고 불리는 Bottom GATE가 전자를 가지며 데이터를 저장했었다.
하지만 이것도 옛날 말이다. 요즘에는 Charge Trap Flash로 바뀌었으며 이는 나이트라이드라는 부도체에 전자를 담아서 데이터를 저장하고 있다.
전체 구조는 플로팅 게이트 셀과 크게 다르지 않다. 플로팅 게이트 대신 부도체(Trap SiN)에 Control Gate (Top Gate)에
전압을 걸면 전하들이 부도체에 갇히게 된다. 이 일련의 한 개의 구조를 셀이라고 한다.
이 셀에 대해서 3가지 정도로 데이터를 구분할 수 있는데, 50% 가령 전자가 찼을때 0, 미만일때 1로 표기하는 Single-level cell부터 2bit 표기가 가능한 MLC, 3bit 표기가 가능한 TLC, 4bit 표기가 가능한 QLC로 나뉜다.
각각 소자에 대한 특성은 아래와 같다.
- 내구성(내결함성) : SLC > MLC > TLC > QLC
- 데이터 집적도(용량) : QLC > TLC > MLC > SLC
- 접근 속도 : SLC > MLC > TLC > QLC
내구성에 대해서는 아래에 추가적으로 서술할 예정이니 넘어가고, 데이터 집적도의 경우에는 당연하다고 볼 수 있다.
한 셀에 한 개의 bit보다 다수의 bit를 넣을 수 있다면 당연히 최대 용량은 커진다.
접근 속도 또한 연관되어있는데 셀 안에 전자가 50% 이상인지 미만인지 알아보는게, 25% 이하인지, 50% 이하인지 같이 세부적으로 알아보는 것보단 훨씬 쉬울 것이다. 때문에 접근 속도에 대해서 SLC가 가장 빠른건 당연하다.
4. Read & Write & Erase
SSD의 데이터 소자의 단위는 셀이지만 읽고 쓰기의 가장 작은 단위는 페이지(Page)이다. 셀들이 모여 Page를 이루며, Page가 몇 개의 bit로 이루어져있는지는 설계에 따라 다르다.
(25년도 기준, 일반적으로 16KB 단위로 쓰는 것 같긴하다)
쓰기와 읽기는 페이지 단위로 가능하지만 삭제는 블록(Block) 단위로만 삭제될 수 있다. 이는 셀 소자의 특성에 기인하는 것인데, 1으로 세팅하는 것에 대해서는 각 셀에 회로에 전압을 걸어주면 되지만
0로 세팅하는 것은 블록 단위의 셀에 붙어있는 기판에 전압을 걸어줘야하기 때문이다.
쓰는 것을 Program 지우는 것을 Erase라고 하며 쓰고 지우는 것을 PE Cycle 이라고 하며
몇번 쓰고 지울 수 있는지는 이 PE Cycle 가능 횟수로 나타낸다.
일반적으로 SLC는 10만 PE Cycle, MLC는 1만 PE Cycle이면 해당 셀의 데이터를 신뢰할 수 없다, 즉 더 이상 사용할 수 없다고 판단한다 그렇다면 MLC 셀들로 이루어진 SSD가 있는데 특정 셀만 1만번 쓰고 지우고를 반복하면 어떻게 될까?
해당 셀에 대해서 신뢰할수 없어졌으니 SSD 전체를 쓰지 못하게 된 것과 마찬가지이다.
그렇기 때문에 Wear Leveling 이라는 기술을 사용하는데 이는 그 다음 항목에서 자세히 서술 하겠다.
예를 들어 어떤 블록이 있고 이 블록은 0번부터 15번까지 총 16개의 페이지로 이루어져있다고 해보자.
1개의 페이지만 사용중인데, 이 페이지에 대해서 수정할 일이 생겼다. 그렇다면 15개의 안쓴 페이지까지 모두 초기화시켜버리고 블록 단위로 다시 적어야할까?
이 문제를 해결하기 위해서 가장 단순히 생각하자면 그냥 SSD에 포함된 DRAM에서 해당 페이지를 유지하며 쓰고 있다가 이후 Flash로 내리는 방법이 있다.
그냥 들어도 알겠지만 이 경우 예상치 못한 system crash에 매우 취약하다. SSD에 전원이 끊기면 DRAM의 데이터가 날아가버려 데이터 손실이 있기 때문이다.
개발자들은 위와 같은 System crash에 덜 취약하고 효율적인 방식으로 이런 문제를 해결하기 위해 FTL이라는 구조를 차용했다.
5. FTL(Flash Translation Layer)
1) 개요
Flash 전송 계측이라고 해석할 수 있다. OS에서 말하는 가상메모리와 비슷한 형태로 실제 스토리지와 가상 스토리지를 분리해서 운용한다고 생각하면 된다. 이는 SSD 컨트롤러 내부에 위치하고 있으며 HDD와 인터페이스를 맞춰주는 LBA(logical Block Address)를 물리적 주소(Physical Block Address)로 바꿔주는 역할도 한다.
FTL의 내부에서는 STL(Sector Translation Layer), BML(Block Management Layer), LLD(Low Level Driver)로 나뉘며 STL은 SECTOR주소를 물리주소로 바꿔주는 것, BML은 블록단위로 이루어진 플래시 메모리의 불량 관리를 담당한다. 또 LLD의 경우 실질적인 플래시 메모리를 사용하기 위한 드라이버라고 생각하면 된다.
2) FTL의 동작 원리
FTL에 대해 서술하기에 앞서 페이지 단위로 쓰고, Block 단위로 지우는 특성 때문에 Page는 총 3가지 상태로 운용된다.
이와 같은 상태는 out-of-band 영역에 64바이트로 된 영역에 staus를 기록한다.
Valid
사용 중인 페이지이다. 유효한 값이 들어있다.Invalid
사용 중이지 않은 페이지이며, 초기화 되어있지 않기 때문에 한번 지우고 써야한다.Free
사용 중이지 않은 페이지이며 지울 필요 없이 바로 사용이 가능하다.
위와 같은 상태를 관리하기 위해 처음 나온게 페이지 단위로 Mapping Table을 구성하는 것이다.
이 Mapping Table은 기본적으로 SSD에 내장된 DRAM에 올라가지만 전원이 꺼져버리면 싹 날아가므로 동일한 내용을 내부의 Flash Memory에 저장해두고, 전원이 켜지면 해당 내용을 Memory에 올린다.
Page 단위로 Mapping Table을 유지하는 것에 대해서 여러가지 문제점으로 인해 여러 방법들이 논의되어있다.
이에 대한 내용은 아래에 추가적으로 서술할 것이고, 지금은 일단 Page 단위의 Mapping Table로 FTL의 동작 원리에 대해서 설명하도록 하겠다.
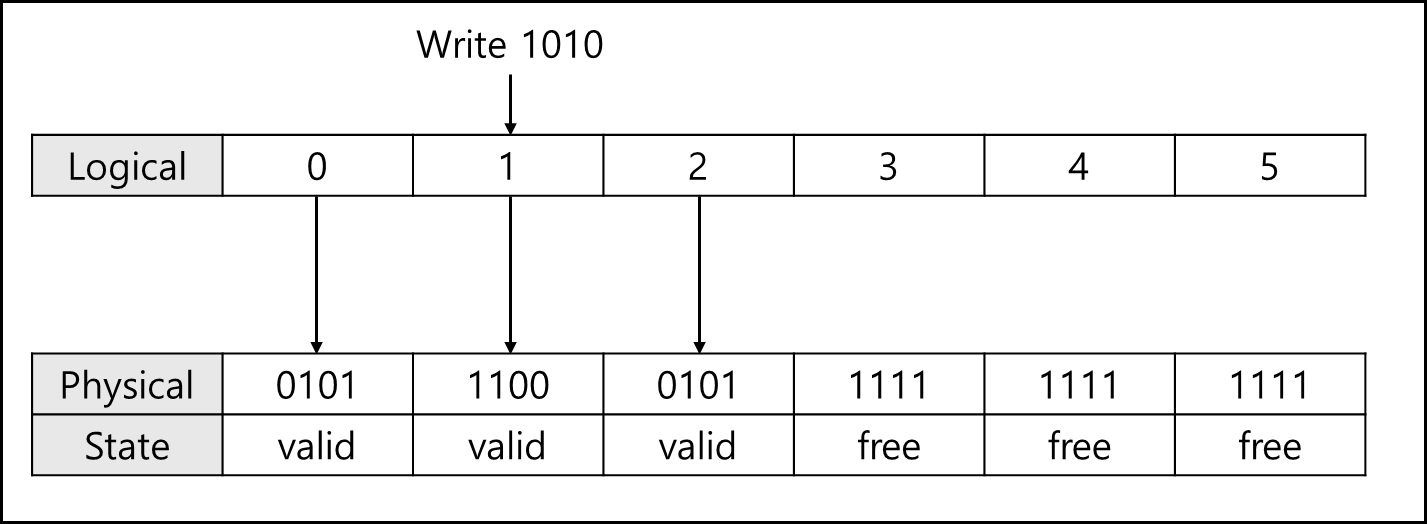
위와 같이 Local page와 Physical page가 별도로 구성되어있고, Mapping 되어있다고 할 때 Logical Block 1번을 1010으로 수정한다고 해보자. 이 경우 페이지의 데이터를 지우기 위해서는 한 블록 전체를 초기화해야한다.
굉장히 비효율적이다. 따라서 해당 블록에 비어있는(free)인 Page에 1010을 써버리고 포인터를 바꿔버린뒤 원래 page는 invalid 처리 해버린다.
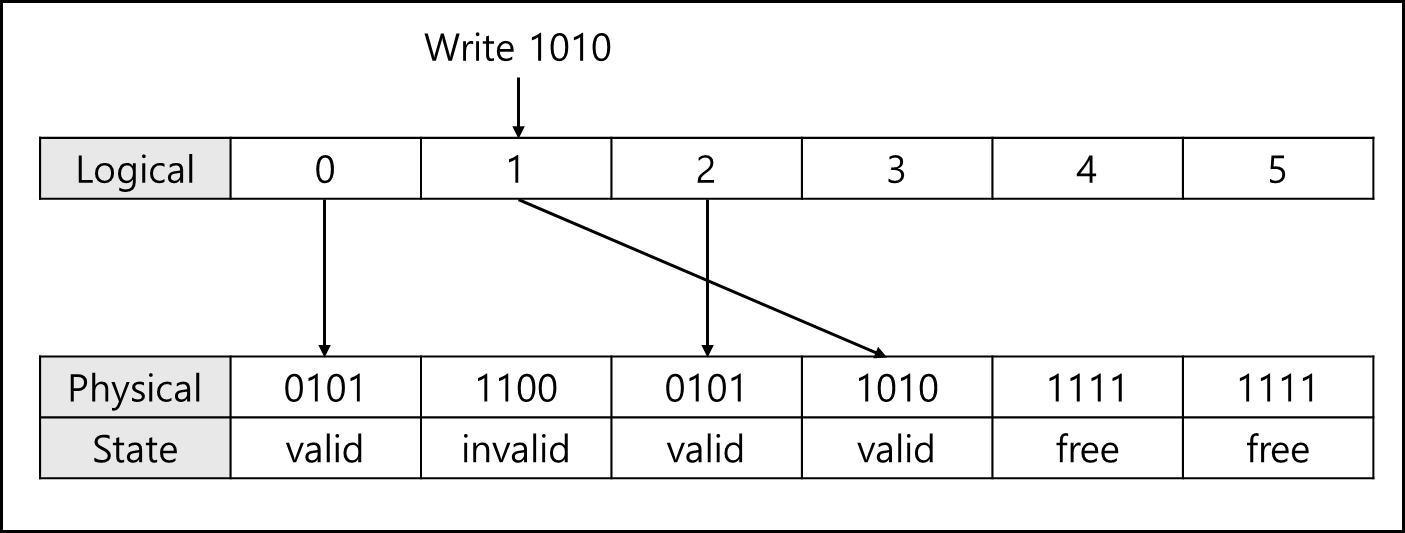
데이터 업데이트간 생긴 invalid page 같은 경우에는 별도의 처리방식이 있는데 이는 아래에서 좀 더 자세히 설명하겠다.
위에서 Wear leveling에 대한 설명을 잠깐 했는데, 사실 이 Logical page과 Physical page에 Mapping 할 대상을 찾을 때 가장 덜 쓴 Physical Page를 지정하면 사실상 그게 Wear Leveling이 되며 이 역시 자체적으로 목록을 갖고 있다.
3) Garbage Collection
Invalid한 page를 초기화하기 위한 나머지 Valid한 Data를 어떻게 옮겨서 원래 블록을 초기화하면 좋은지에 대한 방법으로 Garbage Collection 이라고 부른다. 기본적인 방식은 이러하다.
- Invalid page가 많은 Block을 찾는다.
- Block에서 valid한 page를 찾는다.
- Valid한 page를 쓸 수 있는 Block(free page가 많은 block)에 복사한다.
- 원래 Block은 초기화 해버린다.
대충 그림으로 나타내면 아래와 같다.
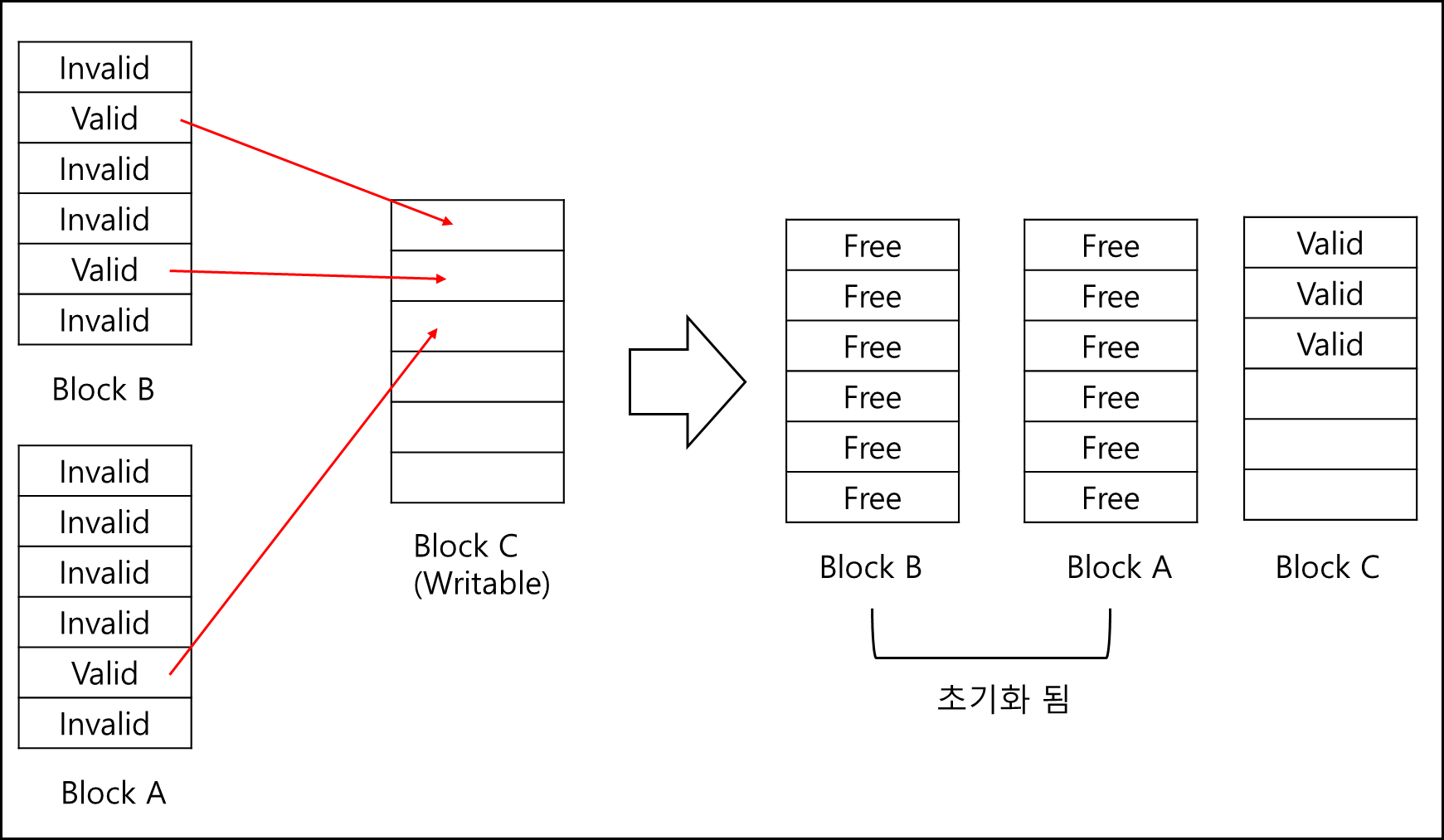
이렇게 작업되는건 SSD Device내에서 자체적으로 실행되며 이를 TRIM이라고 한다.
4) Logical과 Phyical간 Mapping Table 방식의 종류
위에서 Page 단위로 Mapping 테이블을 하는것 외의 방법이 있다고 했는데 일단 현재는 크게는 네 개로 나뉜다.
a. Page Level Mapping
페이지 단위로 매핑을 하는 것이다. 물리적으로 SSD를 일정 단위의 페이지로 나누고, 가상 페이지의 주소와 물리 페이지의 주소를
Mapping 해두는 것이다. (OS에서 가상 메모리와 비슷한 구조라고 생각하면 된다)
가령 1TB의 SSD가 있다고 가정해보자 16KB 크기의 page를 갖고 있다고 할때 Page 정보를 모두 담기 위해서 필요한 용량은 얼마일까? 주소 공간이 기본적으로 32bit 라고 가정한다면 아래의 식으로 구할 수 있다.
- 1TB = $ 2^{40} $
- 16KB = $ 2^{14} $
주소 공간이 32bit이니 아래와 같이 계산된다.
\[2^{26} \times 2^{2} = 256MB\]만약에 SSD 크기가 2TB, 4TB가 되면 여기에 2배, 또 2배가 되니까 512MB, 1GB 이런식으로 필요한 DRAM 크기가 순식간에 뛴다. 메모리를 너무 많이 먹는다. SSD 용량이 커질수록 그에 수반되는 DRAM Buffer 역시 매우 커져야함을 알 수 있다. 이 문제로 인해 아예 Mapping을 Block 단위로 하는게 어떤가 하는 방식도 있다.
b. Block Level Mapping
말 그대로 블록 단위로 매핑을 하는 방식이다.
이러한 블록 단위 매핑 방식의 경우 실질적인 Offset을 같이 기록하는 것이다. 이게 무슨 말이냐면 Page 매핑 방식은 해당 Page 자체를 Mapping 하기 때문에 쓰는 위치가 자유로운 반면에 Block Mapping 방식은 데이터를 쓰기 위해서는 해당 Block의 해당 Page Offset을 같이 기재하며 그 offset대로 쓰기를 해야하기 때문에 유동적이지 않고 고정되어있다는 뜻이다. 이렇게 되면 Wear Leveling이나 병렬적으로 쓰기나 읽기가 힘들어질수도 있어서 이는 좀 비효율적이라고 할 수 있다.
물론 메모리 테이블 크기로는 매우 효율적이다. 이전 사례와 같이 1TB의 SSD가 있다고 할때 Block 크기는 32MB이고 이 Block은 16KB page가 2048개 들어있다 생각해보자. 그러면 아래와 같이 필요한 DRAM의 크기를 구할 수 있다.
- 1TB = $ 2^{40} $
- 32MB = $ 2^{25} $
주소 공간이 32bit이니 아래와 같이 계산된다.
\[2^{15} \times 2^{2} = 128KB\]필요한 메모리가 매우 줄었음을 알 수 있지만 이보다 작은 데이터를 쓸 경우에도 블록 단위로 통째로 업데이트해야하기 때문에 매우 불필요한 행동이라 볼 수 있다.
또한 Block Level Mapping의 경우 기본적으로 offset이 고정되어있다.
c. Hybrid Mapping
Hybrid Mapping은 Block Mapping 방식과 Page Mapping 방식을 같이 쓰는 방식이다.
DRAM 영역을 Data 블록과 Log 블록으로 분리한 뒤 Data 블록은 Block Mapping 방식으로, Log 블록은 Page Mapping으로 운영하는 것이다.
이에 대해서는 여러가지 방식이 있는데 병합 방식이나 Page와 Block 개수 비율을 조절한다. 이중에 BAST(Block-level Associative Sector Translation) 방식은 page와 block 방식을 1대1로 두는 것으로 데이터 블록과 로그 블록이 1대 1로 대응된다.
기본적인 방식은 아래와 같다. 쓰기시에 Data block에 대상 Page가 비어있다면 그냥 Data block에 쓰기를 한다. 하지만 이미 Data block의 대상 Page에 값이 있다면 Data block의 대상 Page를 Invalid 처리해버리고 Log Block의 Page에 기재를 하게 되는데 만약 이후 업데이트를 해야하는 값이 Log Page에 있을 경우 이전에 Log Block에 쓰여진 Page를 Invalid 처리해버린다. 이후 모든 page conflict에 대한 수정 값들은 Log Block에 fully-associative하게 기재하되 이 Log Block이 꽉 차게된다면 Garbage Collection을 통해 merge를 하게 된다.
d. Page Mapping plus caching
이 방식은 ASPLOS 2009에 올라온 “DFTL: a flash translation layer employing demand-based selective caching of page-level address mappings” 논문 내용이다.
요지를 기본적으로 자주 사용하는 매핑 정보만 DRAM에 캐싱하고 나머지 내용은 Flash 메모리에 보관하는 내용이다.
전체 Table을 Flash 메모리가 갖고 있고, caching하듯 자주 쓰는 것은 DRAM에 적재한다.
이 방법에 대해서 아래와 같은 장점이 있다고 한다.
- Selective Caching : 자주 사용하는 매핑 정보만 DRAM에 유지하여 메모리 사용 절감
- On-Demand Loading : 필요한 매핑만 불러오기 때문에 효율적인 메모리 관리 가능
- Page Mapping 유지 : 페이지 매핑 기반이므로 랜덤 쓰기 성능이 뛰어남
- Garbage Collection 최적화 : 불필요한 블록 병합(Block Merge) 최소화
기본적으로 지역성이 높은 데이터라는걸 가정했을 때 가장 효과적인 방식이다. cache miss나 page fault의 문제점을 그대로 갖고 있다고 볼 수 있다.
※ 추가 업데이트 및 검증 예정
참고 문헌
- codecapsule - Coding for SSDs – Part 1: Introduction and Table of Contents
- 카카오 테크 - 개발자를 위한 SSD (Coding for SSD)
- 서강대학교 김영재 교수님 강의 자료 - 고급 데이터 베이스
- [반도체 특강] 디램(DRAM)과 낸드플래시(NAND Flash)의 차이
- [전문가 인사이트] D램과 낸드플래시의 동향과 전망 - 낸드플래시편 (2/2)
- 나의 메모리는 SLC, MLC, TLC? 메모리의 종류 알아보기
- Gupta, Aayush, Youngjae, Kim, and Bhuvan, Urgaonkar. “DFTL: a flash translation layer employing demand-based selective caching of page-level address mappings”.SIGPLAN Not. 44, no.3 (2009): 229–240.