ESPN
텍사스 대학교 사람들이 쓴 논문이다. 제목부터 ESPN이라는 미국 사람 아니면 알아듣지 못할 드립을 던져놓고(ESPN은 미국 연예 및 스포츠 채널이름이다) 시작하는 이 논문은 멀티 벡터 검색에 대한 논문이다.
1. 배경지식과 문제 정의
최신 신경망 IR 시스템은 fine-tuning된 LLM을 활용하여 텍스트 문서를 dense vector 또는 임베딩으로 인코딩하여 텍스트의 본질을 효과적으로 찾아낸다. 임베딩 기반 검색 환경에서 단일 벡터 시스템은 각 텍스트 문서를 단일 dense vector 내에 캡슐화하여 검색 프로세스를 간소화하는데, 이러한 패러다임을 발전시켜 ColBERT와 같은 late interaction 모델은 토큰의 세분성으로 문서를 인코딩하여 멀티 벡터 행렬 표현을 생성한다.
Late interaction 모델은 관련성 모델링을 토큰 수준 계산으로 분해하여 단일 dot product 내에서 복잡한 쿼리-문서 관계를 인코딩해야 하는 정보 병목 현상을 우회합니다. 그러나 검색 인덱스에 대한 메모리 및 스토리지 요구 사항은 여러 배수만큼 증가한다. 예를 들어, ColBERTv1의 인덱스 크기는 BM25와 같은 기존 lexical 검색기의 인덱스 크기보다 210배 더 크다.
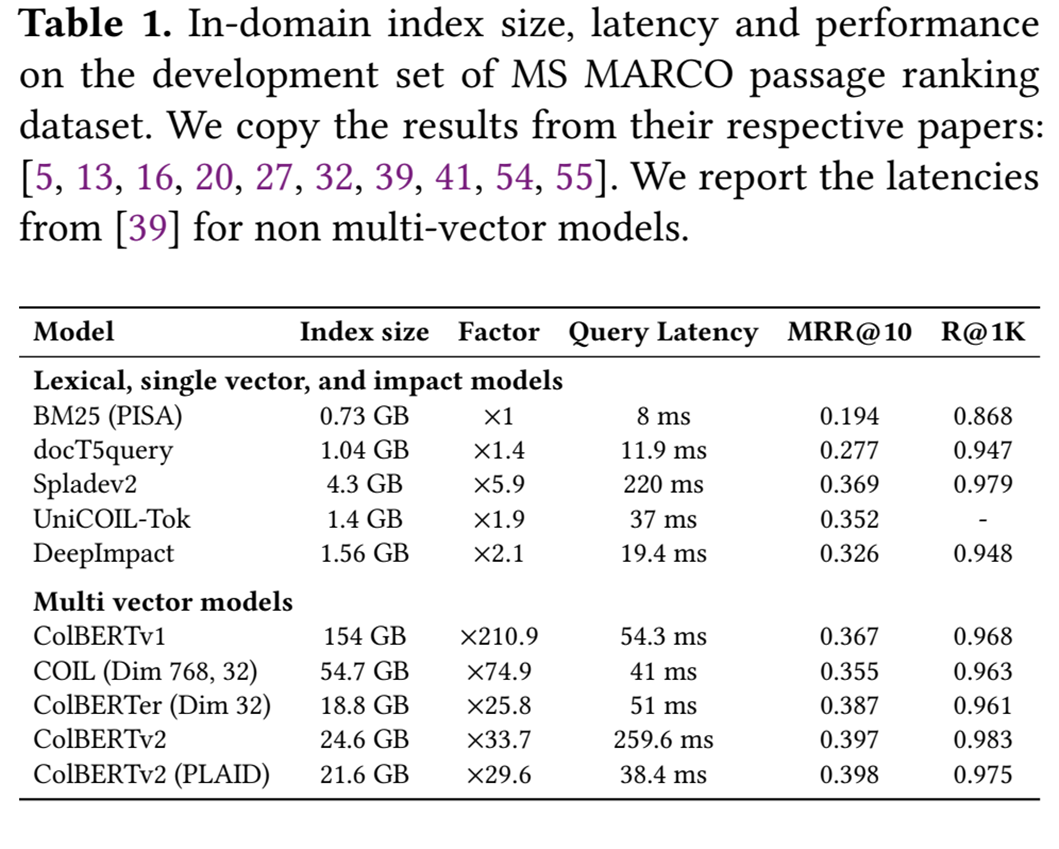
이렇게 Index 크기가 크면 시스템 메모리에도 올라가지 않으며 Swap이나 mmap을 이용하여 사용해도 아래와 같이 높은 지연시간이 나타난다.
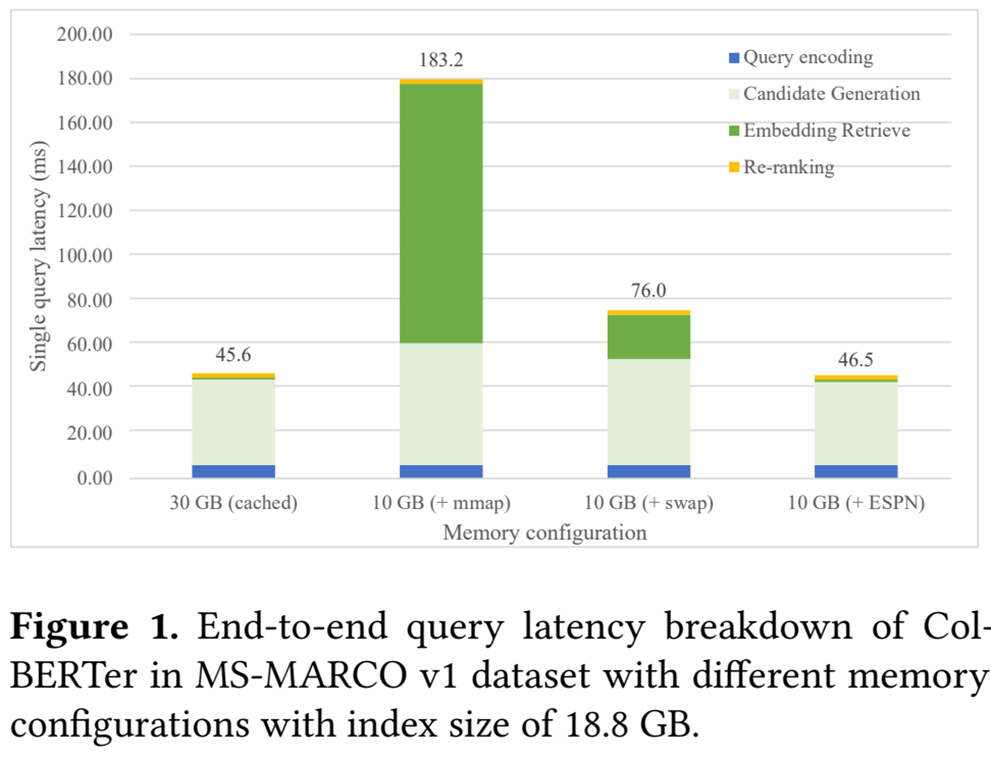
따라서 논문 저자들이 시스템 메모리가 부족하여 구동을 못하고 혹은 OS에서 지원하는 Swap 기능을 써서 구동한다고 하더라도 느려지는 문제를 해결하기 위해 ESPN(Embedding from Storage Pipelined Network) 이라는 솔루션을 제안했다.
2. 솔루션 구현
1) 개요
큰 그림은 아래와 같다.
- 미세 조정된 LLM을 사용하여 문서를 사전에 Single Vector(CLS)와 Multi Vector(BOW)화
- Multi Vector Embedding은 SSD에 적재
- Multi Vector Embedding의 시작 위치 및 길이 등 메타데이터와 Single Vector Embedding은 Host Memory에 적재
입력된 Query를 미세조정된 LLM을 통해 Single Vector와 Multi Vector로 변환
Single Vector를 이용하여 ANN Search(IVF)를 통해 유사 최근접 이웃 후보군 탐색
탐색 과정에서 순위 높은 δ개의 후보군을 GPU Direct Storage를 이용하여 SSD에서 GPU RAM으로 불러옴
GPU RAM에 적재된 δ개의 후보군을 MaxSim 연산을 통해 조기 Re-ranking을 진행
ANN 완료 후 GPU로 Prefech 단계에서 놓쳤던 문서들을 다시 GDS로 불러와 Maxim 연산 후 최종 Re-ranking
- 재정렬된 문서 반환
하나 하나 세부적으로 살펴보도록 하겠다.
2) Approximate Nearest Neighbor (ANN) Prefetching
ANN 검색 과정에서 쿼리와 가장 가까운 δ개의 클러스터를 탐색한 후 Access 가능성이 있는 문서 ID의 근사 목록 L을 생성 L의 상위 K개 문서의 ID에 해당하는 임베딩을 GDS를 사용하여 미리 Prefetch하여 VRAM에 적재 ANN이 나머지 λ개의 클러스터를 추가로 탑색하여 Recall을 개선하는 동안 Overlap되어 Latency hiding 효과가 있음 이러한 Prefetch 예산은 ANN 검색 차이로 정의되며 아래의 식과 같다.

Prefetching 지연시간이 발생하지 않는 임계값은 아래와 같습니다. 여기서 $BW_{SSD}$는 SSD의 대역폭이다.
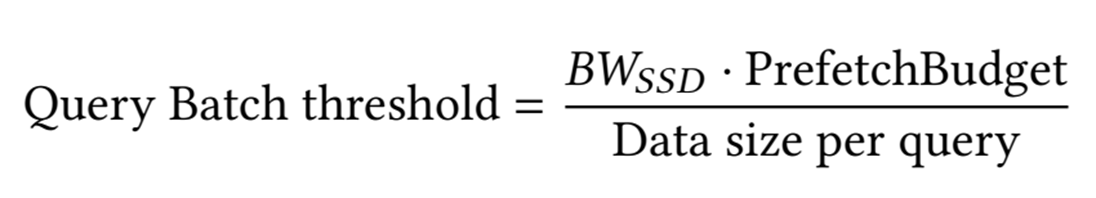
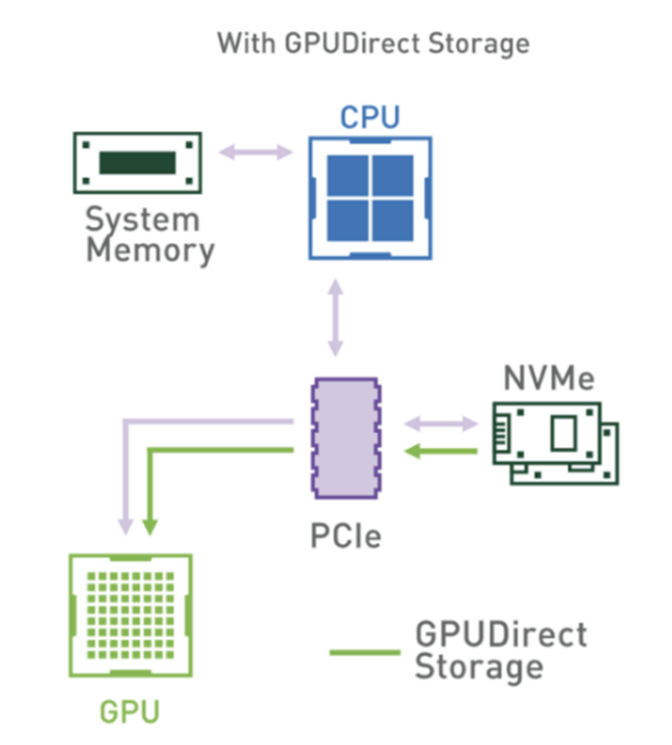
3) Embedding offload and GPUDirect Storage
Reranking에 필요한 데이터는 모두 NVMe SSD에 있기 때문에 GPU Direct Storage(이하 GDS)를 이용하여 데이터를 가져온다.
4) CUDA 메모리 관리 커널
GDS로 가져오는 데이터는 연속된 블록의 형태이다. 따라서 이를 문서단위로 나누어주어야하는데 하나 하나 cudaMemcpy를 통해서 옮기면 시간이 너무 많이 걸린다. 따라서 그에 맞는 최적의 메모리 관리 커널을 만들어서 커널로 하여금 GPU RAM Buffer를 생성하게 함으로써 효율을 높였다고 한다.
근데 코드를 살펴보면 그냥 Matrix를 잘 잘라둔 것에 가깝다.
5) Early Re-ranking 및 점수 통합
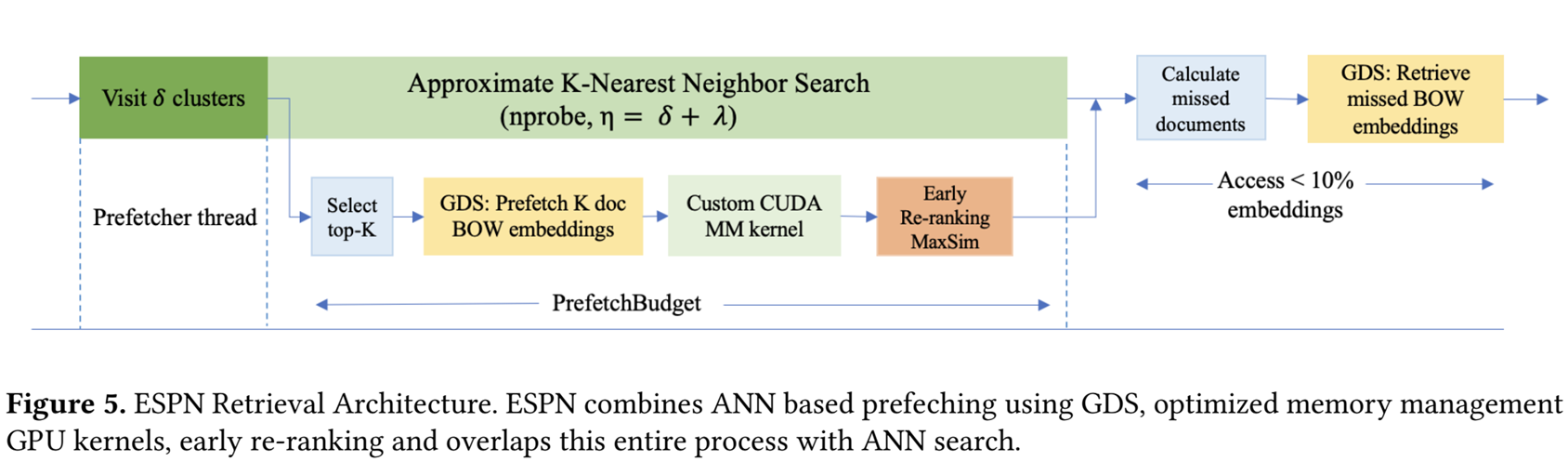
앞서 개요에서 설명 했듯이 1차 ANN 후보 수집기에서 Prefetcher가 대략적인 후보 목록을 가져오기 때문에 약간의 관련 없는 임베딩을 검색할수 있다. 때문에 전체 계산량이 약간 증가할 수 있다. 하지만 ANN 검색이 CPU에서 수행된다는 점을 감안할 때, GPU를 활용하여 조기 재정렬을 수행하면 동시 계산 증가로 인한 추가 지연 시간이 발생하지 않는다. (CPU 계산과 GPU 계산이 Overlap 됨)
쿼리 배치 임계값 미만으로 작동할 때 조기 재정렬은 ANN 검색결과와 겹칠 수도 있으며 쿼리의 중요한 경로에서 MaxSim 작업량을 줄여 쿼리 지연 시간을 더욱 줄일 수 있기 때문에 매우 효과적이며, 이후 Prefetcher가 초기에 선택하지는 않았지만 1차 ANN 후보수집기가 최종 선택한 작업을 다시 GDS로 GPU RAM에 보내고 Rerank한뒤 병합하여 최종 Rerank 결과를 산출 한다.
6) 대역폭 효율적인 부분 재순위화(Partial Re-ranking)
첫 번째 후보 생성기의 성능이 좋아졌기 때문에 이미 관련성 높은 후보들은 목록의 상단에 위치하게 된다. 따라서 첫 후보 생성기가 반환한 전체 후보 목록중에 가장 상위 랭크된 소수의 문서에 대해서만 비용이 많이 드는 MaxSim 연산을 적용하여 BOW Embedding을 가져오고 실제 점수를 계산한다. 나머지는 첫 단계 후보 생성기가 부여한 점수(또는 다른 간소화된 점수)를 사용해도 된다.
무슨 말도 안되는 소리인가 할 수도 있는데 실제로 그렇다. 아래의 그래프를 보자.
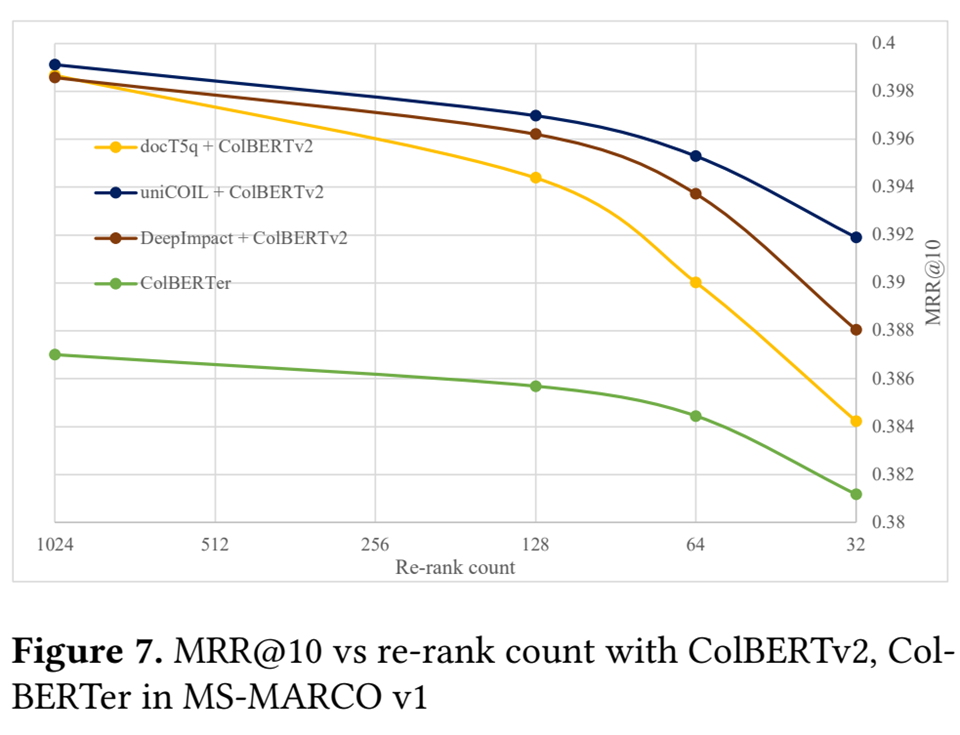
Colberter의 경우 1000개 중에 64개만 뽑아도 0.3~ 0.7%의 정확률 하락밖에 일어나지 않는다.
1000개중에 64개 또는 128개만 뽑을 경우, 질의당 SSD에서 GPU로 전송해야 하는 BOW 임베딩 데이터의 양이 8배에서 16배까지 감소하기 때문에 대역폭에 효과적인데 ESPN은 이러한 대역폭 효율적인 부분 재순위화를 통해 정확도 하락은 약간 감수하며 대역폭을 확 줄인다.
3. 실험 및 평가
1) 실험 환경
A. Hardware
CPU : Intel Xeon W2255 CPU HOST RAM : 256(GB) DDR4 SWAP : 32 GB GPU : NVIDIA A5000 GPU GPU RAM : 24GB(GDDR6) STORAGE : Samsung PM983 SSD (PCie 3.0)
B. Dataset
- MS-MARCO-v1 : ivfflat(4.3 GB) -> HOST RAM에 적재
- MS-MARCO-v2 : ivfpq (7.5 GB, m=128, nbits =8) -> HOST RAM에 적재
- 16.8 GB, 255.4 GB Embedding Table -> NVMe SSD에 적재
2) Prefetcher Results
3) End-to-End Exact Retrieval Solutions
4) Scaling ESPN to Large Query Batch Sizes
5) Bandwidth Efficient Partial Re-ranking Solution
6) conclusion
추가 업데이트 예정
참고문헌
- Shrestha, Susav, Narasimha, Reddy, and Zongwang, Li. “ESPN: Memory-Efficient Multi-vector Information Retrieval.” . In Proceedings of the 2024 ACM SIGPLAN International Symposium on Memory Management (pp. 95–107). Association for Computing Machinery, 2024.