GPU 프로그래밍 - 텐서코어
텐서 코어(Tensor Core)
1. 개요
행렬연산에 특화되어있는 Nvidia에서 만든 코어이다. 기본적으로 이 텐서 코어는 D = A * B + C 와 같은 형태의 연산에 특화되어있는 코어이다.
딥러닝 연산의 대부분이 가중치와 편향 계산인 만큼 텐서코어의 이와 같은 특성은 AI에 특화되어있다고 볼 수 있다.
2. 구조
1) 지원하는 자료형
텐서코어에서는 IEEE 754에서 정의한 공식적인 자료형 외에 Nvidia에서 자체적으로 만든 자료형도 지원을 한다.
아래는 Ampere 버전의 NVIDIA GPU에서 텐서코어에서 지원하는 자료형에 종류에 대해 간략하게 설명해둔 표이다.
| Format | Total bits | Sign Bits | Exponents Bits | 비고 |
| BF16(Brain Float 16) | 16 | 1 | 8 | Ampere 추가 |
| FP16 | 16 | 1 | 5 | |
| TF32(Tensor Float 32) | 19(Effectively 32) | 1 | 8 | Ampere 추가 |
| FP64 | 64 | 11 | 52 | Ampere 추가 |
| INT8 | 8 | - | - | Turing에서 추가 |
| INT4 | 4 | - | - | Turing에서 추가 |
| BINARY | 1 | - | - | Turing에서 추가 |
2) 지원하는 연산 형태
a. 연산 기본구조
기본적으로 총 4개의 2차원 행렬이 등장한다.
\[D = A \times B + C\]라고 한다면 각각 Matrix A, Matrix B, Accumulator C, Accumulator D라고 하자. 연산은 아래와 같은 형태로 이루어진다.
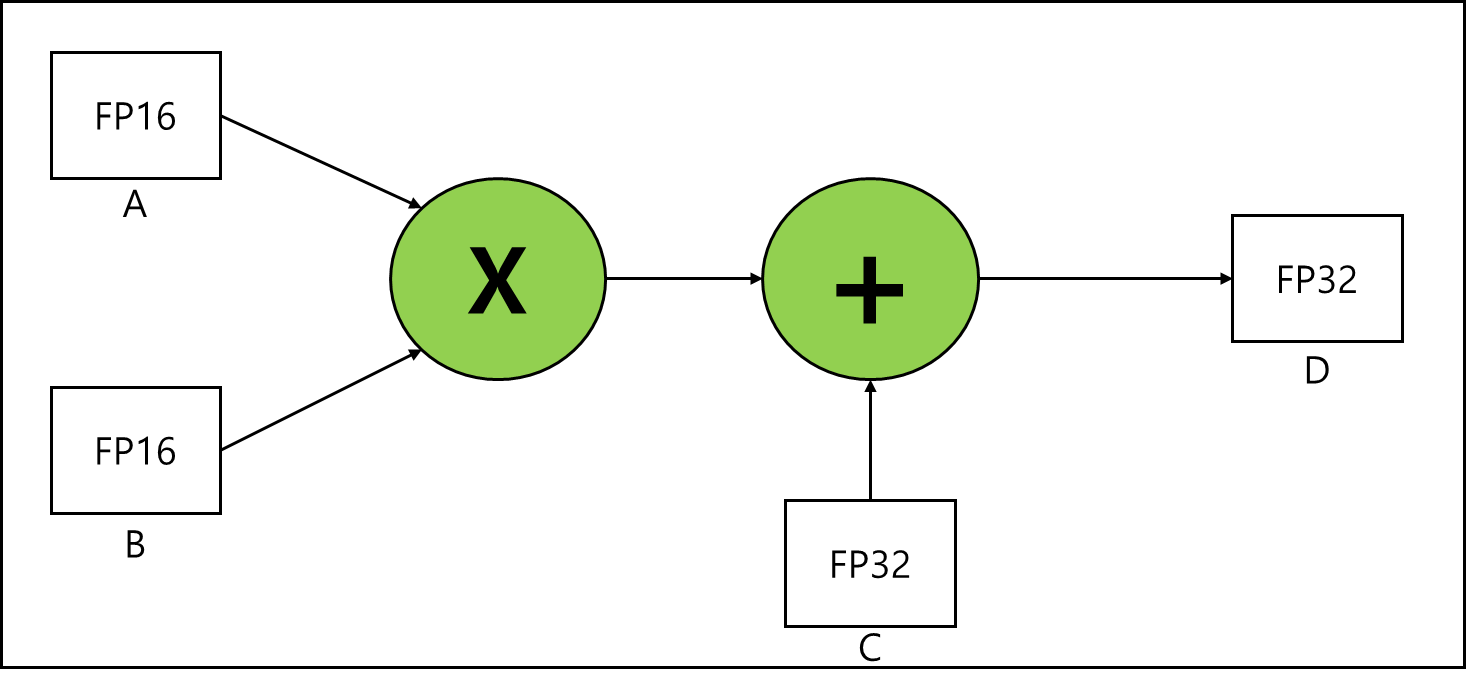
위 경우는 곱셈 연산에 Input 되는 FP16이 A,B이고 이후 덧셈 연산에서의 INPUT으로 들어오는 FP32가 C 결과값으로 출력되는게 FP32가 D이다라고 생각하면 된다. A와 B 그리고 C 연산과정에서 확장되어 FP32가 되는 것이다. 이렇게 연산 과정에서 Precision이 변경되는 연산 종류를 많이 지원한다.
b. 연산 종류
A 행렬을 m x k , B 행렬을 k x n, C와 D를 m x n이라고 할때 Ampere 이전 Volta에서는 클럭당 4x4x4 행렬 연산을 지원했지만 Ampere에서는 클럭당 8x4x8 행렬 연산을 지원한다.
아래는 연산 형태에 따른 속도(Trillions of Operations Per Second)이다.
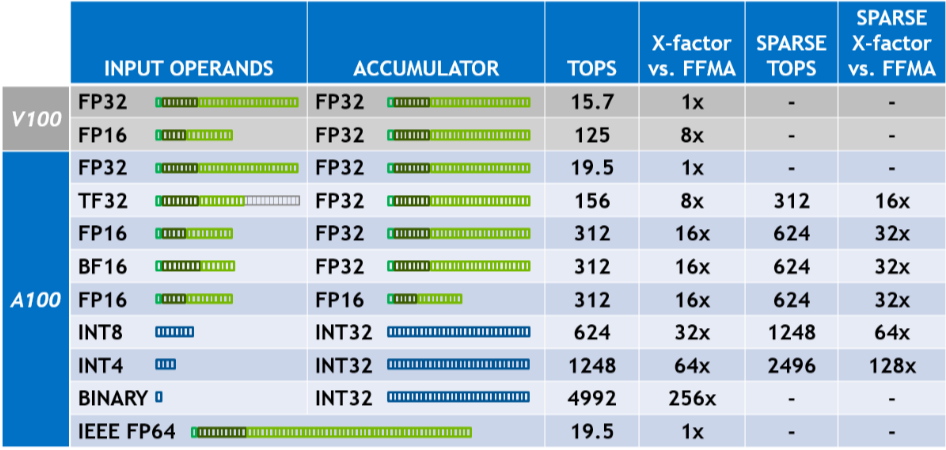
아래의 A100이 Ampere 세대이며, rtx와 같은 보급형 계통에서는 tensor 코어의 개수가 다르므로 TOPS가 다르지만 참고 정도는 하기에 괜찮다.
희소 행렬의 경우 2배정도의 속도 향상을 제공하는데 아마 연산 인자로 0이 들어오게 되면 해당 부분의 연산을 넘어가버리고 0으로 반환하는 형태의 회로가 있는 것으로 추정된다.
3. 텐서코어 연산 예시
아래는 텐서코어로 연산하는 코드 예시이다.
A와 B를 곱해서 C로 넣는 일을 하며 A는 MK, B는 KN, C는 MN 행렬이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
// file: tensorcore_wmma_example.cu
#include <iostream>
#include <mma.h>
#include <cuda.h>
using namespace nvcuda;
// 행렬 크기 정의 (각 블록이 처리할 tile 크기)
const int M = 16;
const int N = 16;
const int K = 16;
// CUDA 커널: 한 워프(warp)가 M×K × K×N 행렬 곱 (C = A×B) 수행
__global__ void wmma_gemm(const half* A, const half* B, float* C) {
// WMMA fragment 선언
wmma::fragment<wmma::matrix_a, M, N, K, half, wmma::row_major> a_frag;
wmma::fragment<wmma::matrix_b, M, N, K, half, wmma::col_major> b_frag;
wmma::fragment<wmma::accumulator, M, N, K, float> c_frag;
// C fragment 초기화 (0으로)
wmma::fill_fragment(c_frag, 0.0f);
// A, B 데이터를 WMMA fragment에 로드
const half* tile_ptr_A = A + blockIdx.x * M * K;
const half* tile_ptr_B = B + blockIdx.y * K * N;
wmma::load_matrix_sync(a_frag, tile_ptr_A, K);
wmma::load_matrix_sync(b_frag, tile_ptr_B, N);
// Tensor Core 연산 수행
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
// 결과 C fragment를 전역 메모리에 저장
float* tile_ptr_C = C + (blockIdx.x * N + blockIdx.y) * M;
wmma::store_matrix_sync(tile_ptr_C, c_frag, N, wmma::mem_row_major);
}
int main() {
// 호스트 메모리 할당
size_t bytes_A = M * K * sizeof(half);
size_t bytes_B = K * N * sizeof(half);
size_t bytes_C = M * N * sizeof(float);
half *h_A = (half*)malloc(bytes_A);
half *h_B = (half*)malloc(bytes_B);
float *h_C = (float*)malloc(bytes_C);
// 입력 행렬을 예시 값으로 채움
for (int i = 0; i < M*K; i++) h_A[i] = __float2half(1.0f);
for (int i = 0; i < K*N; i++) h_B[i] = __float2half(2.0f);
// 디바이스 메모리 할당
half *d_A, *d_B;
float *d_C;
cudaMalloc(&d_A, bytes_A);
cudaMalloc(&d_B, bytes_B);
cudaMalloc(&d_C, bytes_C);
// 데이터 복사
cudaMemcpy(d_A, h_A, bytes_A, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, bytes_B, cudaMemcpyHostToDevice);
cudaMemset(d_C, 0, bytes_C);
// 그리드/블록 설정: 각 블록을 하나의 tile에 매핑, warp 하나로 충분
dim3 gridDim(1, 1);
dim3 blockDim(32, 1); // warp 크기
wmma_gemm<<<gridDim, blockDim>>>(d_A, d_B, d_C);
cudaDeviceSynchronize();
// 결과 가져오기
cudaMemcpy(h_C, d_C, bytes_C, cudaMemcpyDeviceToHost);
// 확인: 모든 값이 16 (1×2 summed 16번) 인지 출력
bool ok = true;
for (int i = 0; i < M*N; i++) {
if (fabs(h_C[i] - 32.0f) > 1e-3) {
ok = false; break;
}
}
std::cout << "Result is " << (ok ? "correct" : "incorrect") << std::endl;
// 메모리 해제
free(h_A);
free(h_B);
free(h_C);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return 0;
}
※ 추가 업데이트 및 검증 예정
참고문헌
- 서강대학교 임인성 교수님 - 기초 GPU 프로그래밍 수업 자료
- NVIDIA - NVIDIA ADA GPU ARCHITECTURE
- NVIDIA - ampere architecture White paper