GPU 프로그래밍 - CUDA 기초 문법
CUDA Programming 문법
1. 개요
NVIDIA GPU를 이용하여 프로그래밍을 하려면 기본적으로 CUDA(Compute Unified Device Architecture) 프로그래밍에 대해서 알아야한다.
프로그래밍을 하기 위해서는 프로세서 구조를 어느정도 알아야하는데, 이전까지 포스팅은 GPU의 구조에 대한 설명이었다.
이번 포스팅은 CUDA 프로그래밍에 대한 기본적인 내용을 알아보겠다.
2. 주요 단어들
CUDA 프로그래밍간에 사용하는 단어는 일반 CPU 프로그래밍과 살짝 다르다.
이 부분에 대해서는 미리 좀 알아두면 좋다.
1) Host and Device
Host란 기본적으로 CPU를 말하며, Device는 GPU를 말한다.
이는 메모리를 이야기할 때도 마찬가지인데 Host Memory는 메인보드에 연결된 RAM을 말하고, Device Memory는 GPU에 달린 VRAM을 말한다.
2) Kernel
OS 제일 아래에서 돌아가는 그 Kernel이 아니다.
GPU에서 돌아가는 프로그램을 Kernel이라고 하는데, 아마 GPU와 가장 맞 닿아있는 프로그램이라서 그런게 아닌가 싶다.
3. CUDA C++ Language Extensions
원래 C++에는 포함되어있지 않으나 CUDA용 컴파일러인 nvcc에서 사용하는 식별자와 함수들을 말한다.
기존 C++ 코드들은 원래 C++ 컴파일러를 통해 처리되지만 이 확장들은 NVCC가 처리하게된다. CUDA 코드가 포함된 파일은 확장자가 .cu여야한다.
1) 확장 식별자
__global__
Device에서 돌아가는 프로그램, 즉 Kernel 이라는 뜻이다.
Host에서 호출할수 있는 함수이다. void 타입의 리턴 값을 가지며 class의 멤버가 될 수 없다. 기본적으로 비동기 함수이므로 CPU와 동기화하고 싶다면 별도의 명령어가 필요하다.__device__
Device에서 돌아가는 프로그램이나, Device에서만 호출이 가능하다.__global__과__device__는 병행해서 사용할 수 없다.__host__
host에서 돌아가는 프로그램이다, host에서만 호출 할 수 있다.__device__와__host__값을 같이 사용할 수 있다.
2) 차원 및 인덱스에 대한 내장 변수
a. 설명
아래 변수는 device에서 구동되는 코드에서만 유효하다.
gridDimgrid가 몇 개의 Threadblock으로 이루어져있는지에 대한 값이다.
몇 차원으로 구성했는지에 따라 x,y,z로 호출 가능하다.blockDimblock이 몇 개의 thread로 이루어져있는지에 대한 값이다.
몇 차원으로 구성했는지에 따라 x,y,z로 호출 가능하다.blockIdx
grid에서 해당 block의 Index를 반환한다.
몇 차원으로 구성했는지에 따라 x,y,z로 호출 가능하다.threadIdxblock에서 해당 thread의 Index를 반환한다.
몇 차원으로 구성했는지에 따라 x,y,z로 호출 가능하다.warpSize
고정적으로 32를 반환한다. 차후에 WarpSize가 변경된다면 32가 아닌 다른 값이 반환 될 수 있다.
그리드에서 몇 번째 thread인지 알아내는 법
- 1차원일때
1
blockDim.x * blockIdx.x + threadIdx.x
- 2차원일때
1
gridDim.x * blockDim.x *(blockDim.y * blockIdx.y+threadIdx.y) + blockDim.x * blockIdx.x + threadIdx.x
b. 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
// device에서 구동되는 함수
__global__ void kernel() {
// 전역에서 현재 Thread가 몇번째인지
int globalThreadId = blockIdx.x * blockDim.x + threadIdx.x;
// 블록에서 몇번째 Warp인지
int warpIdInBlock = threadIdx.x / warpSize;
// 각각의 값에 대해서 출력
printf("GridDim.x: %d, BlockDim.x: %d, BlockIdx.x: %d, ThreadIdx.x: %d, GlobalThreadId: %d, WarpSize: %d, WarpIdInBlock: %d\n",
gridDim.x, blockDim.x, blockIdx.x, threadIdx.x, globalThreadId, warpSize, warpIdInBlock);
}
int main() {
// 블록당 32개의 스레드, 2개의 블록
int threadsPerBlock = 32;
int numBlocks = 2;
// GPU 커널 실행
kernel<<<numBlocks, threadsPerBlock>>>();
// 디바이스에서 작업이 끝날때까지 대기 시킴
cudaDeviceSynchronize();
return 0;
}
3) 에러 핸들링
일반적으로 CUDA에서 사용하는 API의 에러 코드 반환 형태는 아래와 같다.
1
2
3
4
5
enum cudaError_t{
cudaSuccess,
cudaErrorInvalidValue,
...
}
위 타입을 보면 알겠지만 0을 반환시 문제없이 작동한 것이고 그 외의 번호를 반환한다면 그에 맞는 에러가 일어나서 해당 에러 코드를 반환한 것이다.
이를 직접 매핑해서 확인하기는 귀찮으니 아래와 같은 에러 처리 함수를 지원한다.
a. cudaGetLastError
함수 타입을 아래와 같다.
1
cudaError_t cudaGetLastError(void)
런타임간에 마지막 에러를 반환한다.
b. cudaGetErrorName
함수 타입을 아래와 같다.
1
const char* cudaGetErrorName(cudaError_t error)
enum으로 된 에러 코드를 받아서 어떤 에러인지 반환한다.
c. cudaGetErrorString
함수 타입을 아래와 같다.
1
const char* cudaGetErrorString(cudaError_t error)
error code를 받아서 해당 에러에 대한 설명을 반환한다.
위와 같은 에러 처리 함수 들이 있는데 일일이 설정하기 귀찮으니 아래와 같이 에러 처리 매크로를 만들어서 사용하면 편하다
1
2
3
4
5
6
7
8
9
10
11
#define CHECK_CUDA(call)
do {
cudaError_t status_ = call;
if (status_ != cudaSuccess) {
fprintf(stderr, “CUDA error (%s:%d): %s:%s\n”,
__FILE__, __LINE__,
cudaGetErrorName(status_),
cudaGetErrorString(status_));
exit(EXIT_FAILURE);
}
} while (0)
위와 같이 매크로를 설정해두면 아래와 같이 사용하기만 하면 된다.
1
CHECK_CUDA(cudaMalloc((**void)&A,size));
4) 메모리 관리
a. 메모리 할당
일반 C++에서 메모리를 사용하려면 별도의 선언이 필요하다.
변수나 함수 같이 컴파일러가 알아서 스택에 메모리를 잡아주는 경우도 있고, Malloc과 같은 함수로 사용자가 명시적으로 heap 영역에 메모리를 잡아줘야하는 경우도 있다.
CUDA에서도 마찬가지이다. 기본적으로 GPU는 자체적으로 RAM(이하 VRAM)을 가지고 있는데, 이 영역을 사용하려면 VRAM에서 할당받아야한다.
VRAM을 할당 받는 함수에 대한 명세는 아래와 같다.
1
cudaError_t cudaMalloc(void** devPtr, size_t size)
위 코드도 위에서 설명한 CHECK_CUDA 매크로와 함께 쓰면 어떤 에러가 발생했을시에 트래킹하기 쉽다.
첫번째 인자인 devPtr은 할당 받은 VRAM에 엑세스할 수 있는 포인터 변수를 넣으면되고, 두번째 인자인 size는 얼마나 할당 받아야하는지 바이트 단위로 기재해주면 된다. 가령 float 타입의 포인터 변수 A에 30개의 float 만큼 VRAM을 할당받아야한다면 아래와 같이 쓰면 된다.
1
cudaMalloc((void**)&A,sizeof(float)*30);
메모리의 어느 위치를 쓸지 미리 정해둘수도 있다. 아래의 식별자를 사용하면 된다.
__host__: host memory에 위치하는 메모리이다. malloc을 통해 동적으로 할당 받을 수 있다.__device__: GPU에 달린 VRAM에 위치하는 메모리이다. cudaMalloc을 통해 동적으로 할당 받을 수 있다.__constant__: GPU에 달린 VRAM에 위치하는 메모리이다. 동적으로 할당 받지는 못하며, 상수를 담을때 사용한다.
아래는 선언 예시이다.
1
2
3
4
5
6
7
8
9
10
11
__host__ float A[128];
__device__ float B[128];
__constant__ float C[128];
__global__ void kernel(...) {
float c = B[0] + C[1];
}
void function(...) {
float d = A[0];
}
b. 메모리 해제
메모리를 할당하여 사용했으면 메모리 할당을 해제해주어야한다.
메모리 할당을 해제해주는 함수의 명세는 아래와 같다.
1
cudaError_t cudaFree(void *devPtr)
역시 이 과정에서 CHECK_CUDA 매크로를 같이 사용하면 문제 발생시 트래킹하기 좋다. 위에서 할당한 A 포인터에 대해서 할당을 해제해주고 싶다면 아래와 같이 사용하면 된다.
1
cudaFree(A);
c. 메모리 복사
일반적으로 어떤 계산을 할 때 HOST 메모리에서 데이터를 가져와서 VRAM에 복사한뒤에 뭔가 계산을 한다.
이때 필요한 것이 메모리 복사를 하는 코드인데, 이 메모리 복사에 대해서는 좀 알아야할 부분이 있다.
HOST 메모리에서 VRAM으로 데이터를 옮길 때 HOST 메모리에서 바로 VRAM으로 이동하는게 아니라는 점이다.
HOST 메모리는 Pageable Memory와 Pinned Memory로 나뉜다. Pageable Memory는 OS에서 말하는 페이징 가능한 메모리라고 생각하면 된다. 언제든 페이징에 의해 disk로 쫒겨날 수 있는 메모리이다. Pinned 메모리는 고정되어있는 메모리로 페이징으로 인해 쫒겨나지 않는 메모리이다.
일반적으로 대부분의 데이터는 Pageable 메모리에 있다. 따라서 이 데이터는 Pinned Memory로 옮겨진 뒤에 VRAM으로 이동한다.
이 때문에 아예 Pinned 메모리를 잡아서 거기에 데이터를 넣는게 아니면 VRAM으로 데이터를 옮기는 건 시간비용적으로 꽤나 비싼 행동이다.
메모리 복사의 원리에 대해서 알았다면 어떻게 사용하는지에 대한 것을 알아볼 차례이다.
메모리 복사 함수의 원형은 아래와 같다.
1
cudaError_t cudaMemcpy(void* dst, void* src, size_t size, cudaMemcpyKind kind)
뭔가 복잡한데, 별거 없다. dst는 목적지, src는 출발지, size는 얼마나 복사할지, kind는 어디서 어떻게 복사할지이다.
아래와 같이 사용할 수 있다.
1
2
3
4
5
6
7
float * CPU_A = malloc(sizeof(float) * 1024);
float * GPU_A;
cudaMalloc((void**)&GPU_A,sizeof(float)*1024);
//CPU_A에게 할당된 HOST 메모리에 데이터를 채워넣음
cudaMemcpy(GPU_A,CPU_A,sizeof(float)*1024,cudaMemcpyHostToDevice);
위 코드에서 CPU_A에 할당된 1024 * float 크기의 메모리를 동일한 크기로 할당된 GPU_A 포인터에 그대로 복사한 것이다.
끝에 cudaMemcpyHostToDevice 부분은 해당 메모리를 어디서 어디로 복사할 것이냐에 대한 내용인데 세부적인건 아래와 같다.
- cudaMemcpyHostToHost : HOST 메모리에서 HOST 메모리로 이동
- cudaMemcpyHostToDevice : HOST 메모리에서 DEVICE 메모리로 이동
- cudaMemcpyDeviceToHost : DEVICE 메모리에서 HOST 메모리로 이동
- cudaMemcpyDeviceToDevice : DEVICE 메모리에서 DEVICE 메모리로 이동
- cudaMemcpyDefault : 포인터를 보고 방향을 자동으로 추론한다.
d. pinned 메모리 관리
HOST에서 DEVICE로 데이터를 보낼때나 혹은 정반대의 경우 Pinned Memory를 거쳐서 복사된다고 했다.
그렇다면 Pinned 메모리 영역을 임의로 잡아줄순 없을까?
당연히 가능하다. 이 역시 cuda에서 지원을 하며, 아래의 함수를 사용하면 해당 메모리는 Pinned 메모리가 된다.
1
cudaMallocHost(void **ptr, size_t size);
위 함수를 사용하면 host에서 메모리를 할당 받을때 해당 메모리를 할당받음과 동시에 pinned 메모리로 설정한다.
때문에 위 함수로 할당받은 메모리를 다시 반환하기 위해서는 그냥 free나 delete 함수를 사용하면 안되고 아래의 함수를 사용하여 해제해야한다.
1
cudaFreeHost(void *ptr);
위와 같이 바로 pinned 메모리로 바꿀 수 있는 함수도 있고, 플래그에 따라 다른 기능을 제공하는 함수도 있다.
1
cudaHostRegister(void *ptr, size_t size, unsigned int flags);
인자중에 ptr은 할당 받을 변수, size는 크기, 플래그는 아래의 값을 따른다.
cudaHostRegisterDefault: 기존 호스트 메모리를 Pinned 메모리로 등록하여 호스트와 장치 간 전송 속도를 향상시킨다. 이 플래그에는 특별한 동작이 추가되지 않는다.
cudaHostRegisterMapped: 기존 호스트 메모리를 등록하고 장치의 주소 공간에 매핑한다. cudaHostAllocMapped과 비슷하게 이 플래그는 GPU가 호스트 메모리에 직접 액세스할 수 있는 zero-copy 메모리 액세스를 허용한다
cudaHostRegisterPortable: 시스템의 여러 GPU가 호스트 메모리에 액세스할 수 있도록 등록한다. 다중 GPU 설정에서 데이터를 복제하지 않고 메모리를 공유하는 데 유용하다.
cudaHostRegisterIoMemory: GPU와 I/O 장치 간의 DMA(Direct Memory Access) 전송과 같은 GPU 작업에 사용할 I/O 메모리를 등록한다. 네트워크 카드와 같이 I/O 하드웨어와 직접 인터페이스하는 애플리케이션에 유용하다.
cudaHostRegisterReadOnly: GPU 관점에서 호스트 메모리를 읽기 전용으로 등록한다. 이는 GPU 커널이 중요한 데이터를 수정하는 것을 방지할 때 유용할 수 있다.
위 함수는 아래의 함수로 해제를 해야한다.
1
cudaHostUnregister(void *ptr);
5) Device 관리
어떤 GPU를 사용하는지 정보가 필요할 때가 있다. 특히 응용부분에서는 GPU의 종류와 성능에 따라 가변적으로 처리해야할 부분이 있기 때문에 정보를 얻을 수 있어야한다.
또한 GPU는 다수를 달 수 있는데 이를 CUDA에서 제어하기 위한 정보로써 이를 제공하고 처리할 수 있게 해준다.
현재 사용가능한 GPU의 개수를 반환하는 함수이다.
1
cudaError_t cudaGetDeviceCount(int *count)
정수형 포인터를 반환하면 해당 포인터에 GPU의 개수를 반환한다.
GPU가 4개가 달려있다고 하면 0~3번까지의 번호를 부여받는다. 이 번호는 각각의 GPU를 구분하는 식별자가 되며 아래의 함수에 device 인자에 넣어주면 해당 GPU에 대한 정보를 받을 수 있다.
1
cudaError_t cudaGetDeviceProperties(cudaDeviceProp *prop, int device)
cudaDeviceProp는 구조체인데, 해당 함수의 인자로 넣어주면 아래와 같은 정보들을 포함해서 반환해준다.
| 구조체 멤버 | 타입 | 설명 |
| name | char* | 아스키 문자로 이루어진 기기 이름 |
| multiProcessorCount | int | SM의 개수 |
| maxThreadsPerBlock | int | 블록 당 최대 스레드 개수 |
| totalGlobalMem | size_t | 기기에서 사용가능한 글로벌 메모리의 바이트수 |
| sharedMemPerBlock | size_t | 블록당 사용가능한 Shared 메모리의 바이트수 |
1
2
3
4
5
6
다수의 GPU가 연결되어있을 때 어떤 GPU를 사용해서 코드를 실행할지 정할 수도 있다.
아래는 현재 사용중인 GPU의 번호를 반환하는 함수이다.
```cuda
cudaError_t cudaGetDevice(int *device)
아래는 GPU 번호를 이용하여 해당 GPU를 사용할 수 있게 지정하는 함수이다.
1
cudaError_t cudaSetDevice(int device)
GPU에서 커널이 끝날때까지 기다리는 함수도 있다.
1
cudaError_t cudaDeviceSynchronize(void)
6) Stream 관리
Stream 관리에 대해서 알기 위해서는 일단 Stream이 뭔지 알아야한다.
Stream은 기본적으로 Device에서 요청한 일을 말한다. 일의 흐름을 처리하는 큐라고 생가갛면 편할 것 같다.
기본적으로 GPU는 다수의 stream을 운용할 수 있으며 별다른 명시가 없으면 기본 Stream인 0번 Stream을 사용한다.
위에서 언급한 작업들도 별도의 Stream에 대한 명시가 없었기 때문에 기본 Stream인 0번 Stream을 사용했다.
host에서 해당 stream으로 일을 밀어넣으면 cuda runtime에서는 해당 일을 땡겨와서 실행시켜준다.
기본적으로 동일 Stream에 있는 일을 순차적으로 실행되지만 다른 Stream에 있는 일의 경우에는 서로 순차적이지 않을 수 있으며 이를 위해 별도의 동기화 처리가 필요하다.
일단 Stream을 다루는 함수들에 대해 알아보자.
a. 함수의 종류
- Stream 생성을 위한 함수
1
cudaError_t cudaStreamCreate(cudaStream_t* pstream)
stream을 담을 수 있는 변수를 선언해주고 해당 함수의 인자로 넘겨주면 인자로 넘겨준 변수를 통해 Stream을 제어할 수 있다.
- 대상 stream에 들어있는 모든 Task가 완료될때까지 HOST가 기다리는 함수
1
cudaError_t cudaStreamSynchronize(cudaStream_t pstream)
- 대상 stream안에 모든 Task가 완료되었는지 확인하는 함수
1
cudaError_t cudaStreamQuery(cudaStream_t pstream)
0(cudaSuccess)이 반환되면 모두 완료된거고 34(cudaErrorNotReady)가 반환되면 아직 덜된 것이다.
- 대상 stream을 없애는 함수
1
cudaError_t cudaStreamDestroy(cudaStream_t pstream)
b. Stream을 사용하는 방법
사실 위에서 언급했던 함수들은 모두 Stream부분을 입력하지 않으면 Default Stream을 사용하게 되어있기 때문에 명시적으로 선언하지 않았다. 따라서 특정 Stream을 사용하고 싶다면 함수에 특정 Stream을 명시해주면 된다.
다만 이럴때는 별도의 Async가 붙은 비동기 함수를 사용해주어야한다.
이전에 언급했던 GPU 함수(cudaMemcpy 같은)는 원래는 각 GPU 함수간에 동기적으로 작동하나 뒤에 Async가 붙은 함수들은 동기적인 작동을 보장하지 않으며 이를 위해서는 별도의 스트림을 지정해주어야한다.
Async 함수도 동일한 Stream내에 속하게 되면 해당 함수간에는 동기적으로 작동한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int test = 2;
int *d_test;
cudaStream_t s; // 스트림 담아줄 변수 생성
cudaStreamCreate(&s); // 스트림 s 생성
cudaMalloc(&d_test, sizeof(int)); // d_test에 VRAM int만큼 할당
// HOST RAM의 a에서 VRAM d_a로 int 크기만큼 데이터를 이동, s 스트림 사용
cudaMemcpyAsync(d_test, &test, sizeof(int), cudaMemcpyHostToDevice, s)
// d_test를 인자로 받고, threadblock 1개 thread 1개, 공유 메모리 0bytes에 stream s를 사용하는 test 커널
test_kernel<<<1, 1, 0, s>>>(d_test);
// 후략
7) Event 관리
Event는 Stream에서 가벼운 연산 같은 것이다. 서로 다른 Stream을 동기화할때도 사용하며 커널 실행시간을 구할때도 요긴하게 사용한다.
a. 함수
- 이벤트를 만드는 함수
1
cudaError_t cudaEventCreate(cudaEvent_t *event)
- 이벤트를 기록하는 함수
1
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream=0)
- 두 개의 이벤트간의 시간을 반환하는 함수
1
cudaError_t cudaEventElapsedTime(float *ms, cudaEvent_t start, cudaEvent_t end)
- 이벤트를 삭제하는 함수
1
cudaError_t cudaEventDestroy(cudaEvent_t event)
b. Stream과 Event를 같이 연동하는 법
아래와 같은 함수가 있다.
1
cudaStreamWaitEvent(stream, event);
이 함수는 해당 event가 발생하기 전까지 인자로 넘겨준 stream을 기다리게 하는 함수이다. 사용예시는 아래와 같다.
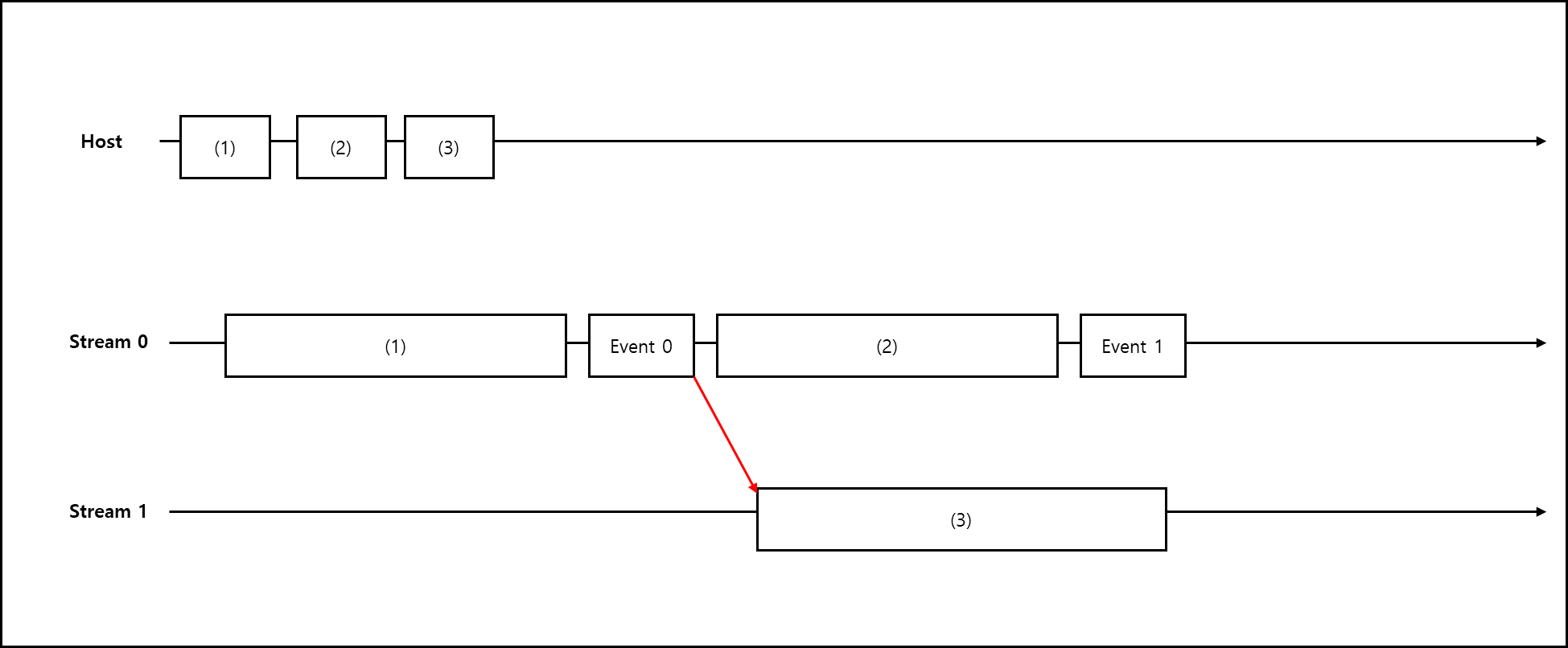
Stream 1과 2가 있다고 해보자. Stream 1의 어떤 작업이 종료된 뒤에 Stream 2를 실행하고 싶다.
그럴 경우에 Stream 1이 종료되는 시점에 Event를 걸어주고 해당 Event까지 Stream2를 대기하게 하면 된다.
아래와 같이 예를 들어보자.
1
2
3
4
5
6
cudaMemcpyAsync(..., cudaMemcpyHostToDevice, stream0); // (1)
cudaEventRecord(event0, stream0);
stream1_kernel<<<..., 0, stream0>>>(...); // (2)
cudaEventRecord(event1, stream0);
cudaStreamWaitEvent(stream1, event0);
cudaMemcpyAsync(..., cudaMemcpyDeviceToHost, stream1); // (3)
Stream 1에서 어떤 값을 HOST에서 DEVICE로 전달했다 — (1) 이후 stream 0의 작업이 완료되면 event0을 기재한다. stream 0에서 stream1_kernel을 실행하고 — (2) 이후에 stream 0의 작업이 완료되면 event1를 기재한다. 이후에 나오는 cudaStreamWaitEvent에서는 stream1와 event0이 기재되어있는데 이는 stream1은 event0이 기재될때까지 대기라하는 뜻이다. 이후 event0이 기재되면 stream 1이 실행되어
이후 stream1에서 어떤 값을 DEVICE에서 HOST로 복사시킨다. — (3)
위 코드를 그림으로 나타내면 아래와 같다.
참고문헌
- 서강대학교 임인성 교수님 - 기초 GPU 프로그래밍 수업 자료
- NVIDIA - NVIDIA ADA GPU ARCHITECTURE
- NVIDIA 공식 문서 - CUDA TOOLKIT DOCUMENTATION