GPU 프로그래밍 - CUDA Memory Management
CUDA Memory Management
1. CUDA 메모리 구조
CUDA 메모리는 데이터의 대역폭과 지연 시간(Latency)의 격차를 줄이기 위해 계층적 구조를 가진다. 크게 On-chip 메모리와 Off-chip 메모리로 나눈다.+
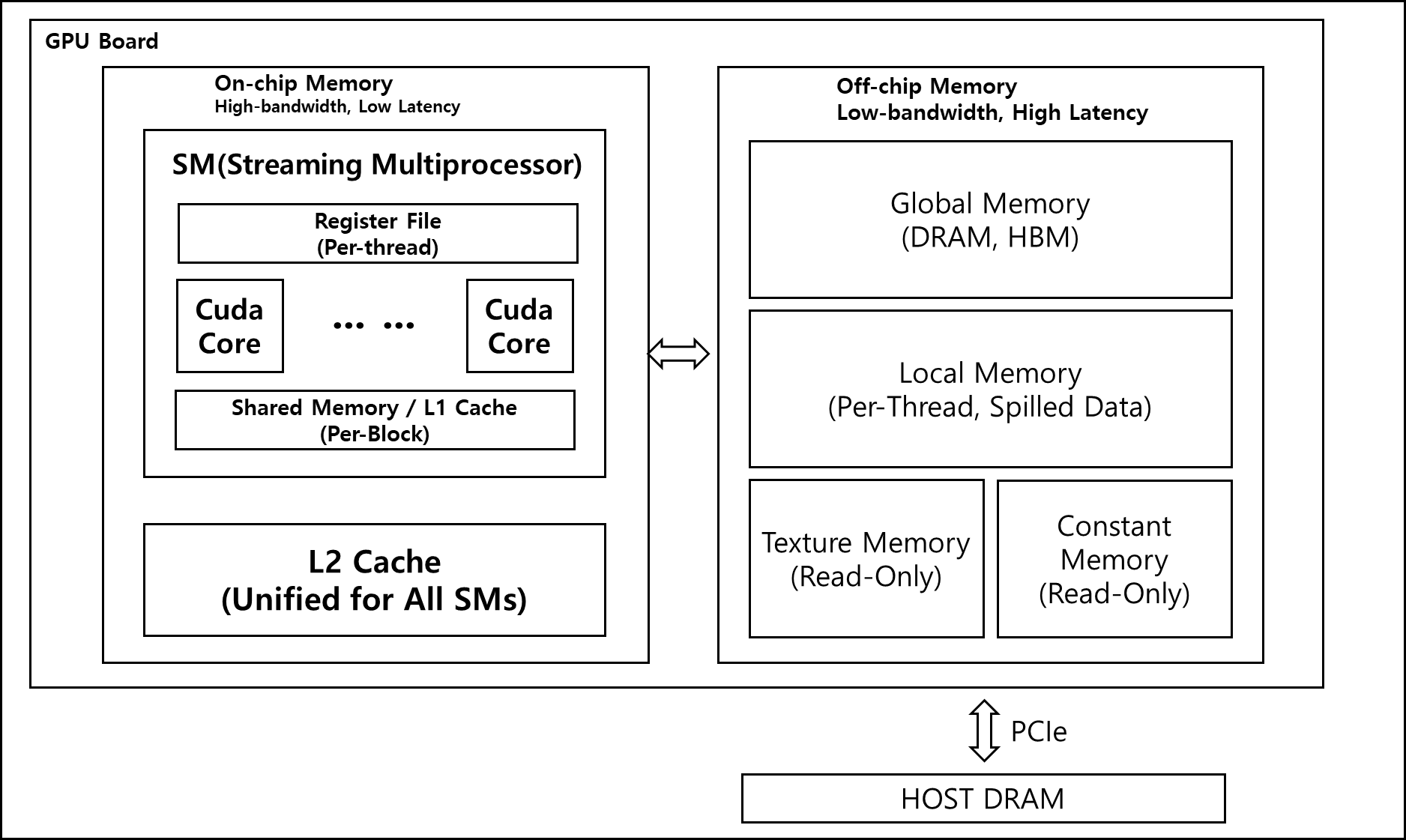
1) On-chip 메모리
레지스터, 공유 메모리(Shared Memory), L1/L2 캐시 등이 포함되며 대역폭이 매우 높고 지연 시간이 짧다.
2) Off-chip 메모리
전역 메모리(Global Memory), 로컬 메모리(Local Memory), 상수(Constant, 읽기 전용) 및 텍스처(Texture, 읽기 전용) 메모리가 포함되며 용량은 크지만 지연 시간이 길다.
2. Register
On-chip 메모리이며 가장 빠르다. 그리고 각 스레드마다 독립적으로 할당되는 저장 공간이다. 주로 자동 변수(스레드가 자신만 별도로 쓰는 변수), 스칼라 변수들을 저장하며, 스레드 블록 내의 스레드 수와 스레드당 레지스터 사용량은 GPU의 점유율(Occupancy)을 결정하는 중요한 요소이다.
3. Local Memory
Off-chip 메모리이며 실제로는 전역 메모리와 동일한 저장 공간을 사용한다. 이름은 로컬이지만 물리적으로는 On-chip이 아니기 때문에 전역 메모리만큼 느리다. 레지스터 공간이 부족하여 변수가 밀려날 때(Spilling) 또는 스레드 전용의 큰 배열을 저장할 때 사용되며, 데이터의 유효 범위(Scope)는 해당 스레드로 한정된다.
4. Shared Memory
On-chip 메모리이며 스레드 블록 내의 모든 스레드가 공유할 수 있는 빠르고 명시적인 관리형 캐시이다. 전역 메모리보다 훨씬 빠르며 자주 접근하는 데이터의 복사본을 저장하거나, 같은 블록 내의 스레드들끼리 데이터를 교환할 때 사용한다. 기본적으로 L1 캐시를 같이 공유하는데, Shared Memory로 잡는 만큼 L1 캐시의 크기가 줄어든다.
일반적으로 아래의 용도로 많이 사용된다.
- 전역 메모리에 접근해야 하는 매우 자주 사용되는 데이터(예: 카운터 배열)를 저장하는 장소.
- 전역 메모리(프로그램 관리 캐시)에 저장될 데이터를 여러 번 접근해야 하는 경우, 해당 데이터의 빠른 미러링(예: 입력 데이터의 일부).
- SM 내 코어들이 데이터를 빠르게 공유하는 방법.
5. Global Memory
Off-chip 메모리이며 흔히들 GPU DRAM이나 혹은 HBM인 경우도 있다. 가장 크고 지연 시간이 길며, 모든 그리드와 스레드가 접근할 수 있는 가장 일반적인 메모리로 대부분 VRAM이라고 하면 이 Global Memory를 말한다. cudaMalloc과 cudaFree를 통해 동적으로 할당 및 해제하며, 데이터 접근은 L2 캐시를 거쳐 이루어진다.
6. Bank conflict
공유 메모리는 보통 32개의 뱅크(Bank)로 나뉘어 관리된다(아키텍처 마다 다르지만 대체로 그렇다). 그런데 한 워프(32스레드) 내의 여러 스레드가 동일한 뱅크의 서로 다른 주소에 동시에 접근하려 할 때 발생하는 문제가 바로 Bank conflict이다. 접근 요청이 직렬화(Serialization)되어 메모리 성능이 급격히 저하되는 것이다.

Bank에서 데이터를 가져오는데 1 cycle이 걸린다고 하면 동일한 Bank에서 순차적으로 데이터를 N개 가져오려면 N cycle이 걸린다.
즉, 직렬화된 만큼 가져오는 시간이 느려지는 것이다.
※ Bank와 align의 관계
흔히들 CPU를 이용해서 코딩할 때도 구조체를 잡으면 큰 것 기준으로 align이 맞춰지게 된다.
가령 int, char, int가 혼재된 방식으로 구조체를 선언하면 align으로 인해 크기가 12bytes가 되는데 이러한 이유는 host memory의 bank 구조로 인해 발생한다.
CPU 프로그래밍에서도 한 BANK에 대해서 4 바이트 또는 8 바이트 단위의 WORD 단위로 가져오게 되는데 4 바이트의 배수 단위로 저장되어있지 않다면 데이터를 가져올 때 동일 BANK에 데이터가 모두 저장되어있어서 병렬로 불러 올 수 있게 아닌 BANK에서 순차적으로 불러오게 될 수 있어 성능이 떨어진다.
1) 해결 방식 1 - Padding 추가
패딩(Padding)은 데이터 배열의 행(Row) 사이에 의미 없는 더미 요소(extra elements)를 추가하여 메모리 접근 간격(Stride)을 변경하는 방식이다.
Bank-conflict가 발생하는 코드가 아래와 같다고 하면
1
2
3
4
5
6
7
#define TILE_DIM 32
__shared__ float tile[TILE_DIM][TILE_DIM];
int lane = threadIdx.x;
int fixed_col = 0;
float val = tile[lane][fixed_col];
이를 Padding 추가로 해결한 코드는 아래와 같다.
1
2
3
4
5
6
7
#define TILE_DIM 32
__shared__ float tile[TILE_DIM][TILE_DIM + 1];
int lane = threadIdx.x;
int fixed_col = 0;
float val = tile[lane][fixed_col];
row부분에 1을 더해서 1칸을 더해줌으로써 원래는 Bank 개수만큼의 공간이 할당이되어 conflict가 날 상황을 피하게 되었다 그림으로 보면 아래와 같다.
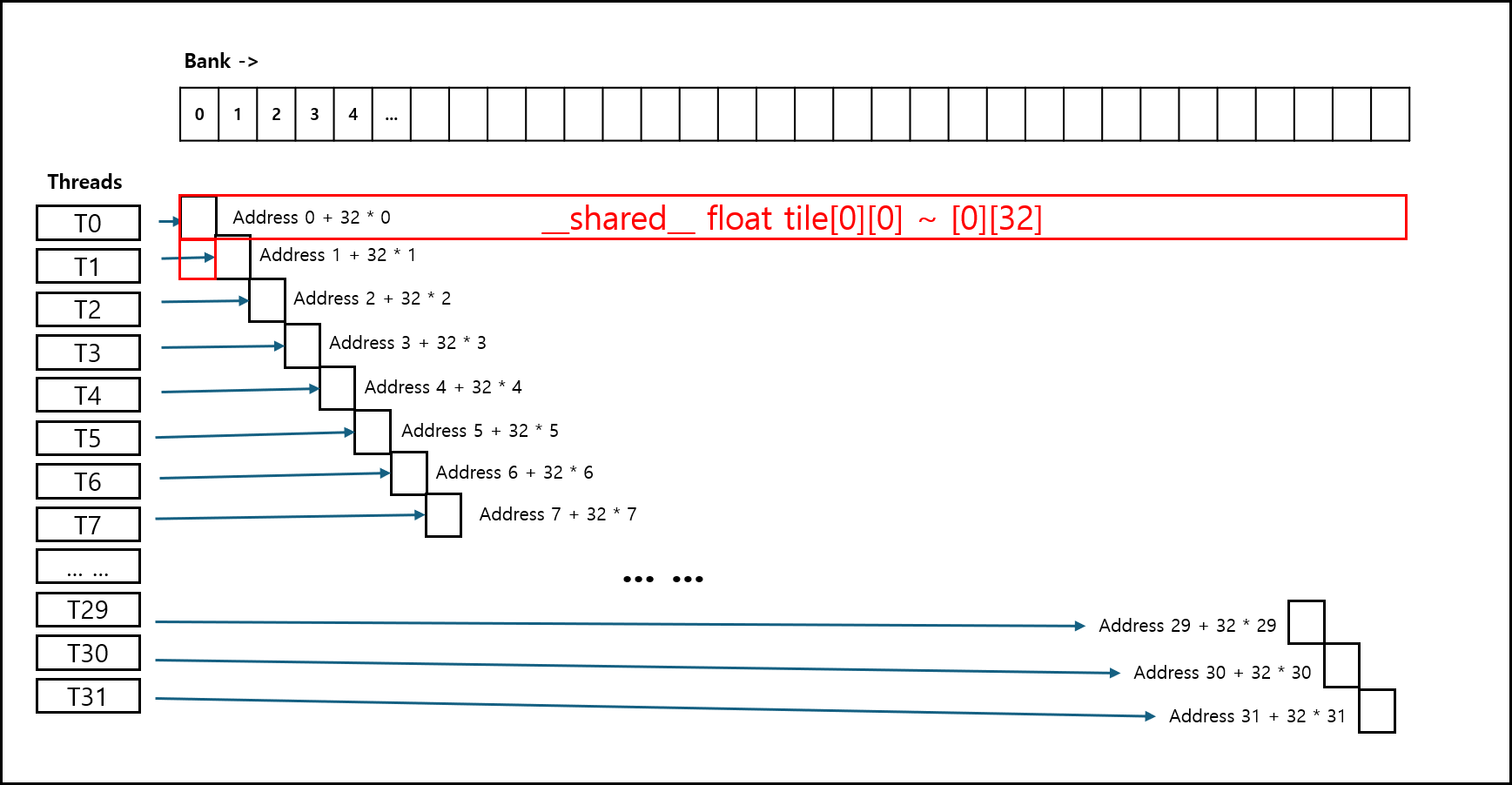
데이터를 담는 틀을 비트는 방식이라고 생각하면 된다.
2) 해결 방식 2 - Re-order
리오더(Reorder)는 데이터의 물리적 구조를 바꾸는 대신, 스레드가 메모리에 접근하는 순서나 인덱스 매핑 방식을 변경하여 컨플릭트를 피하는 방식이다.
원래 conflict 나는 코드는 Padding과 같은 걸 썼을 때 Re-order 방식으로 피하는 법은 아래와 같다.
A. 행렬 전치
1
2
3
4
5
int lane = threadIdx.x;
int fixed_row = 0;
// 아예 행렬을 전치하여 접근
float val = tile[fixed_row][lane];
원래 행 단위로 접근하던 것을 열단위로 접근하도록 변경했다.
이렇게 하려면 원 데이터 자체도 전치되어 들어가 있어야 이전 코드와 동일하게 구동한다.
B. Index 비틀기
1
2
3
4
5
6
7
int row = threadIdx.x;
int col = fixed_col;
int phys_col = (col + row) & (TILE_DIM - 1);
// 저장시에도 phys_col이 반영되어있어야함.
float val = tile[row][phys_col];
Index를 구할 때 별도의 수식을 통해 Bank Conflict가 일어나지 않게끔 별도로 수식을 정의하여 사용한다.
당연하지만 데이터를 넣을때도 해당 수식으로 Index를 구하여 넣어야 동일한 결과가 나온다.
3) 해결 방식 3 - BroadCasting
브로드캐스트는 뱅크 컨플릭트의 예외 상황으로, 워프 내의 모든 스레드가 정확히 동일한 주소(동일한 32비트 워드 내)를 읽으려고 할 때 발생한다. 하드웨어가 해당 요청을 감지하면, 요청된 주소의 데이터를 워프 내의 모든 스레드에 동시에 전달한다. 이 작업은 단일 브로드캐스트 트랜잭션으로 처리되기 때문에 뱅크 컨플릭트가 발생하지 않으며, 매우 효율적이고 빠르다
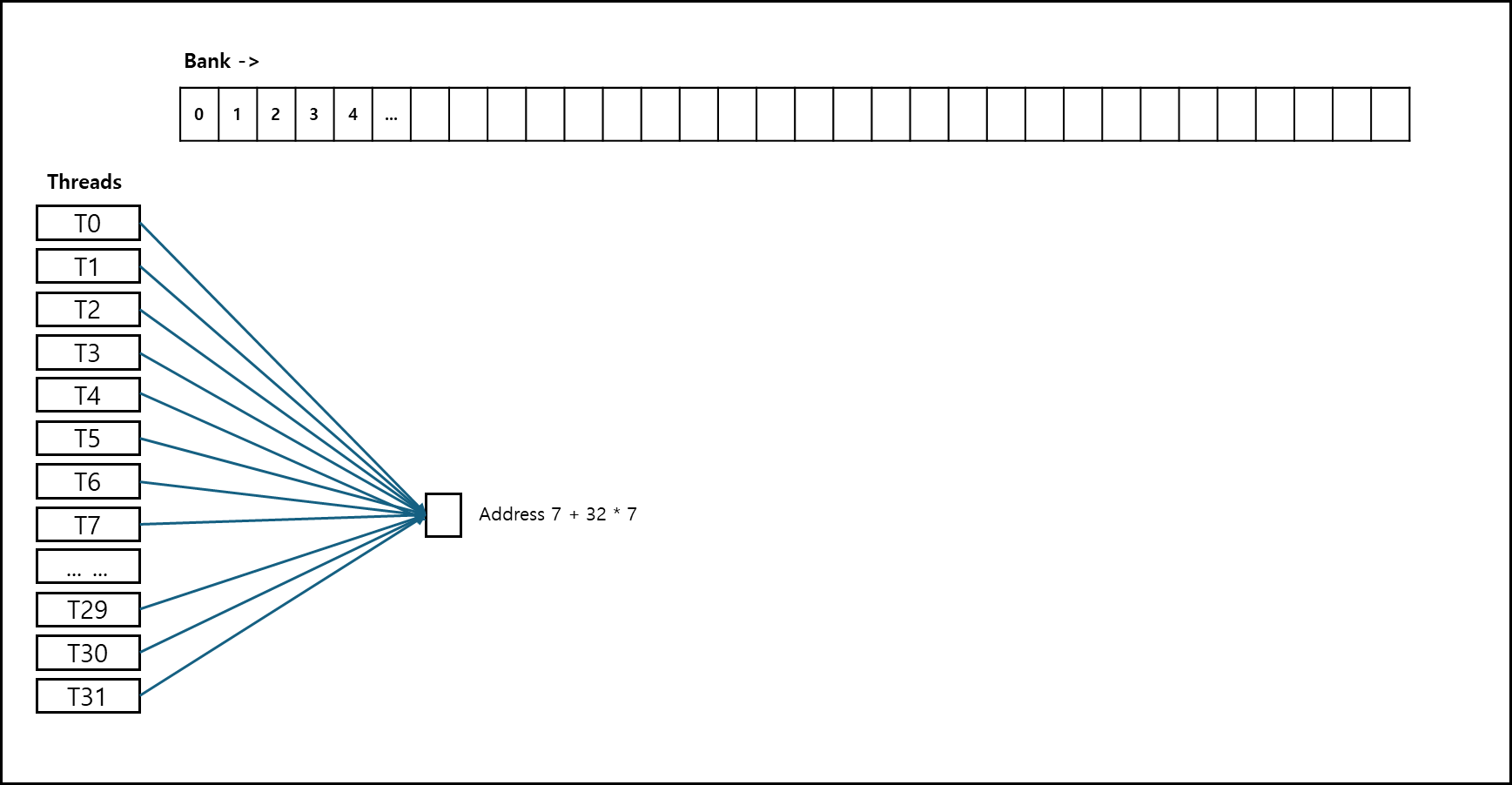
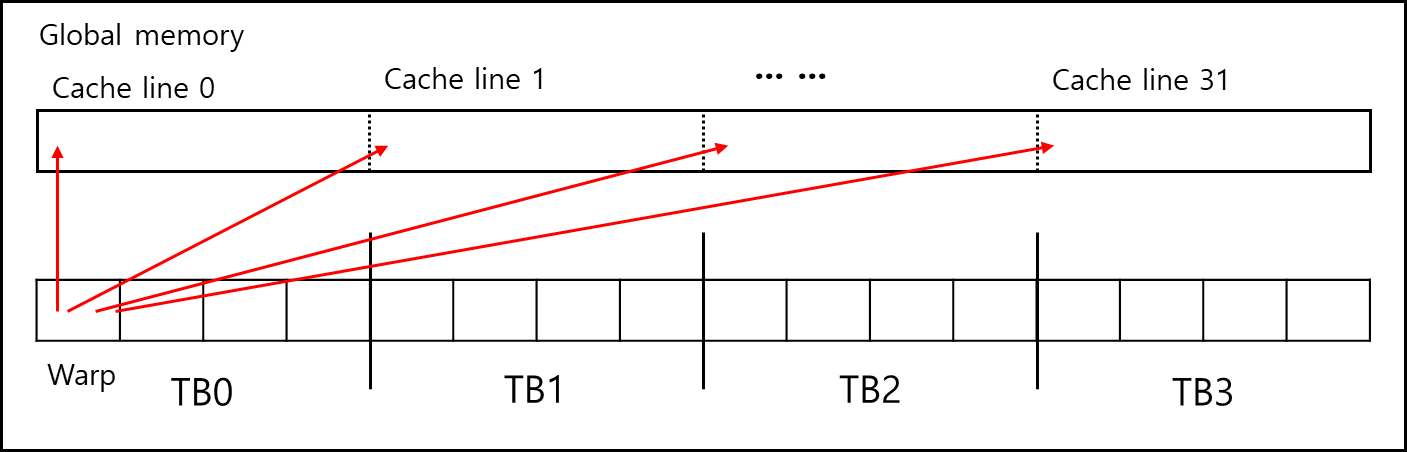
7. Memory Coalesced Access
워프 내의 연속된 스레드들이 연속적인 GLOBAL 메모리 주소에 접근할 때, 이를 하나의 메모리 트랜잭션으로 합쳐서 처리하는 최적화 기법이다. 불필요한 메모리 트랜잭션 횟수를 최소화하여 전역 메모리 대역폭을 극대화한다.
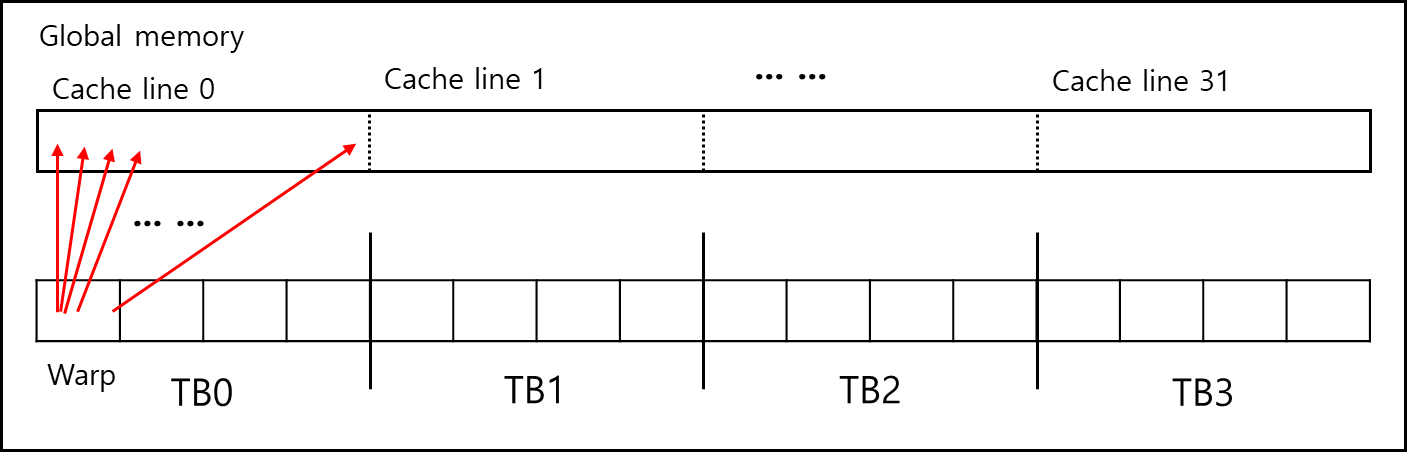
반대로 스레드들이 흩어진 주소에 접근(Non-coalesced)하면 최대 32번의 트랜잭션이 발생할 수 있다.
8. Zero-copy Memory (Mapped Memory)
원래라면 GPU에서 연산을 할때 HOST MEMORY에서 GPU RAM을 데이터를 복사해와서 연산해야하지만, Zero-copy Memory 기술을 사용하면 Host의 메모리의 Pinned Memory(Paging되지 않는 메모리)를 GPU가 직접 참조 할 수 있게 매핑된다. (CPU 메모리를 GPU 메모리 주소로 Mapping 해주기 때문)
Host 메모리에서 가져온 데이터는 L2 캐시에 저장되지 않는 것으로 보인다. (참고 - nvidia 포럼 - Zero Copy performance problem )
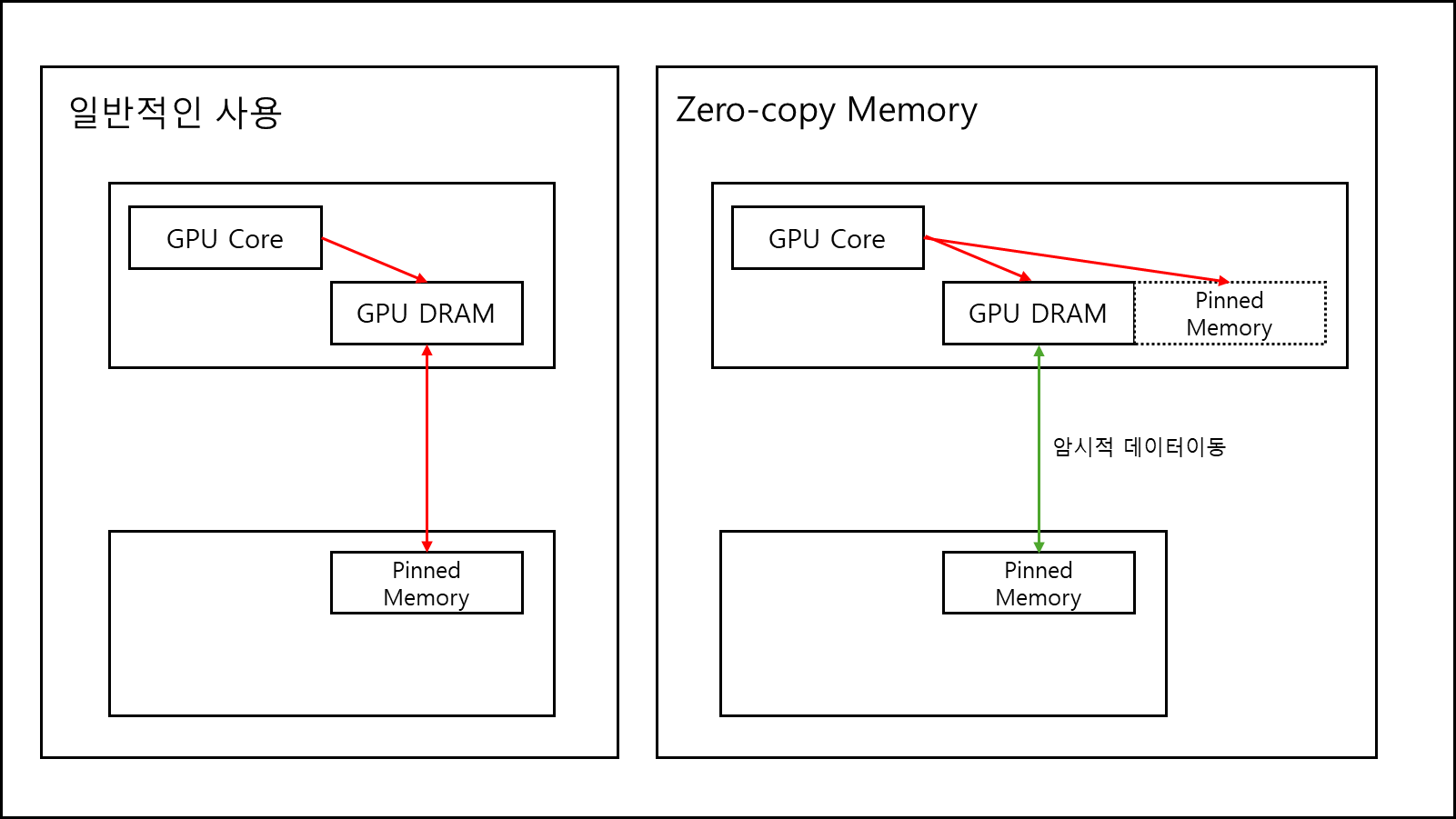
명시적인 데이터 복사라던지 GPU RAM이 부족할때 Host memory를 가져다 쓸수있는 장점이 있지만, 결국에는 PCIe 버스를 통해 데이터를 가져오게 되므로 속도는 여전히 느리며, 사실상 개발자의 편의성을 위해서 있는 기술이라고 생각하면 된다.
※ 사용 방법
HOST 영역에 Pinned Memory 영역을 잡아주는 함수인 cudaHostAlloc()를 사용하되 flag로 cudaHostAllocMapped를 넣어준다.
int형으로 길이 4의 배열을 Mapped Memory로 사용하겠다고 할 때 아래와 같이 쓸 수 있다.
1
2
3
4
5
6
7
8
9
10
// ... 생략
int len = 4;
int * arr_h;
int * arr_d;
cudaError err;
cudaSetDeviceFlags(cudaDeviceMapHost); // 64bit linux에서는 항상 on 되어있어서 안 넣어도 됨
cudaHostAlloc((void**)&arr_h,len*sizeof(int),cudaHostAllocMapped);
err = cudaHostGetDevicePointer((void**)&arr_d,arr_h,0); // host에 할당된 메모리 주소를 device로 가져옴
kernel_something<<1,len>> (arr_d,len);
// ... 생략
커널에 인자로 넘겨주면서 해당 영역을 GPU 커널에서 사용할 수 있다.
9. Unified Virtual Address
CPU와 모든 GPU가 하나의 통합된 가상 주소 공간을 공유하는 기술이다. 포인터 값이 시스템 전체에서 고유해지므로, 런타임이 포인터만 보고 데이터가 호스트에 있는지 어느 GPU에 있는지 자동으로 판단할 수 있다.
10. Unified Memory
CPU와 GPU가 동일한 포인터를 사용하여 접근할 수 있는 관리형 공유 메모리이다. Unified Virtual Address를 기반으로 만들어진 기술로 cudaMallocManaged로 할당하며, 시스템이 데이터가 필요한 시점에 호스트와 디바이스 사이에서 메모리 페이지를 자동으로 이동(On-demand migration)시킨다. 개발자가 명시적으로 cudaMemcpy를 호출할 필요가 없어 프로그래밍 모델이 매우 단순해지며 효율적인 메모리 활용이 가능하다.
※ Unified Memory 사용 방식
Unified memory가 아니라면 CPU와 GPU에 각각 별도의 데이터를 할당해주어야한다.
명시적으로 이동시켜야하니 당연하다면 당연한 것인데, Unified Memory의 경우 이러한 명시적인 이동이 없기 때문에 코드가 좀 더 간결하다.
아래의 코드는 A,B라는 크기 32의 INT 배열 둘을 더해서 C 배열에 넣는 코드로 Unified Memory 방식을 사용하지 않은 CUDA 코드이다.
편의상 예외처리 코드나 상태 체크 코드, 헤더는 제외했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
// ... 헤더 및 vectorAdd 커널 코드 생략
int main() {
int * h_A = (int*)malloc(4 * sizeof(int));
int * h_B = (int*)malloc(4 * sizeof(int));
int * h_C = (int*)malloc(4 * sizeof(int));
// host memory 배열 초기화 코드 생략
int * d_A = NULL;
int * d_B = NULL;
int * d_C = NULL;
// GPU에 메모리 할당
cudaMalloc((void**)&d_A, 4 * sizeof(int))
cudaMalloc((void**)&d_B, 4 * sizeof(int))
cudaMalloc((void**)&d_C, 4 * sizeof(int))
// host에서 GPU 데이터 이관
cudaMemcpy(d_A, h_A, 4 * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, 4 * sizeof(int), cudaMemcpyHostToDevice);
// GPU에서 연산
vectorAdd << < 1, 4 >> > (d_A, d_B, d_C, 4);
// GPU에서 CPU로 결과 이관
cudaMemcpy(h_C, d_C, 4 * sizeof(int), cudaMemcpyDeviceToHost);
// .. 나머지 생략
}
위 코드를 Unified Memory를 사용하는 코드로 바꾸면 아래와 같이 변경된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// ... 헤더 및 vectorAdd 커널 코드 생략
int main() {
int * A = NULL;
int * B = NULL;
int * C = NULL;
// A,B,C 배열 초기화 코드 생략
// GPU에 메모리 할당
cudaMallocManaged((void**)&A, 4 * sizeof(int))
cudaMallocManaged((void**)&B, 4 * sizeof(int))
cudaMallocManaged((void**)&C, 4 * sizeof(int))
// GPU에서 연산
vectorAdd << < 1, 4 >> > (A, B, C, 4);
// .. 나머지 생략
}
위에서 이전 코드와 비교해보면 알겠지만 HOST 메모리 따로 GPU 메모리 따로 할당을 요청하는 부분이 사라지고 cudaMallocManaged로 통합되었다.
이후 GPU와 CPU로 데이터 이동은 드라이버에서 자동으로 해주기 때문에 신경쓸거 없이 바로 변수를 Kernel로 넘겨서 연산하면 된다.
※ Managed Flag
cudaMallocManaged 함수의 경우 인자를 포인터 변수와 size 마지막으로 Flag를 받는다.
이 Flag 종류는 아래와 같다.
- cudaMemAttachGlobal : 대상 Managed된 메모리는 모든 커널에서 접근 가능하다.
- cudaMemAttachHost : 대상 Managed된 메모리는 할당을 요청한 커널에서만 접근 가능하다.
이 Flag는 생략 가능하며 생략시 기본값으로 cudaMemAttachGlobal 로 지정된다.
참고자료
- 서강대학교 박성용 교수님 강의자료 - 병렬 분산 컴퓨팅
- nvidia 포럼 - Zero-copy: is cudaSetDeviceFlags(cudaDeviceMapHost) actually needed?
- nvidia 포럼 - Zero Copy performance problem
원문 참고자료들
- Peter S. Pacheco, An Introduction to Parallel Programming, Elsevier Inc. (Morgan Kaufmann), 2011, ISBN 978-0-12-374260-5
- Gerassimos Barlas, Multicore and GPU Programming – An Integrated Approach, Elsevier Inc. (Morgan Kaufmann), 2015, ISBN 978-0-12-417137-4.