GPU 프로그래밍 - CUDA 용어 및 구조
CUDA
1. 종류
일반적인 용도의 병렬 컴퓨팅을 위한 프로그램을 할 수 있는 모델이라고 생각하면 된다.
소위 말하는 CUDA에는 사실 두 가지 종류가 있다.
Driver library
- NVIDIA 드라이버를 설치하면 자동으로 설치된다.
- 저수준의 CUDA 프로그래밍을 목적으로 한다
- 지원하는 API이름은 CUDA Driver API이다.
- 라이브러리 명
(static) cuda.lib이나 libcuda.a
(dynamic) cuda.dll이나 libcuda.so - 헤더파일은 cuda.h
Runtime library
- NVIDIA CUDA Toolkit 설치시 설치된다.
- 고수준의 CUDA 프로그래밍을 목적으로 한다.
- 지원하는 API이름은 CUDA Runtime API이다.
- 라이브러리 명
(static) cudart.lib 이나 libcudart.a
(dynamic) cudart.dll 이나 libcudart.so - 헤더파일은 cuda_runtime.h
2. 용어들
1) Kernel
GPU에서 구동될 수 있는 프로그램을 말한다.
2) Thread
한 개의 코어가 하는 각각의 작업 하나하나를 말한다.
a. Thread ID
전체의 Thread 리스트 중에서의 구분자를 말한다. 일반적으로 배열 번호이다.
b. Thread Index
Thread block(아래에 서술)안의 몇 번째 Thread인지 구분할 수 있는 번호이다.
3) Thread block
Thread의 묶음을 말한다. 몇 개의 Thread를 1 Thread block으로 쓸지는 그때그때 다르다. 이후 언급할 warp의 집합 역시 Thread Block으로 볼수 있다. Thread Block은 Warp의 집합을 이루어져있고, Warp는 32개의 스레드로 이루어져있기 때문에 Thread Block은 32의 배수로 지정하는게 좋다. (32의 배수가 아니라면 효율이 떨어진다.)
Thread Block의 최대 Thread 개수의 제한은 1024이니, 최대 32개의 Warp를 지정할 수 있다( $32 \times 32 = 1024$ )
1) Thread block dimesion
Thread block이 몇 개의 Thread로 이루어져있는지를 말한다.
4) Grid
Thread block들의 묶음이다.
1) Grid Dimension
Grid가 몇 개의 Thread block으로 이루어져있는지 말한다.
5) Warp
Thread block에서 동일한 크기로 나뉜 조각을 말하며 CUDA에서는 32 Threads로 지정되어있다.
GPU에서는 이 Warp를 기준으로 처리한다.
3. 구조
아래는 Geforce 3000번대인 ADA AD102 GPU의 구조이다.
칩셋 종류마다 어느정도 차이는 있지만 각각의 컴포넌트의 역할이 바뀌진 않는다.
1) GPC
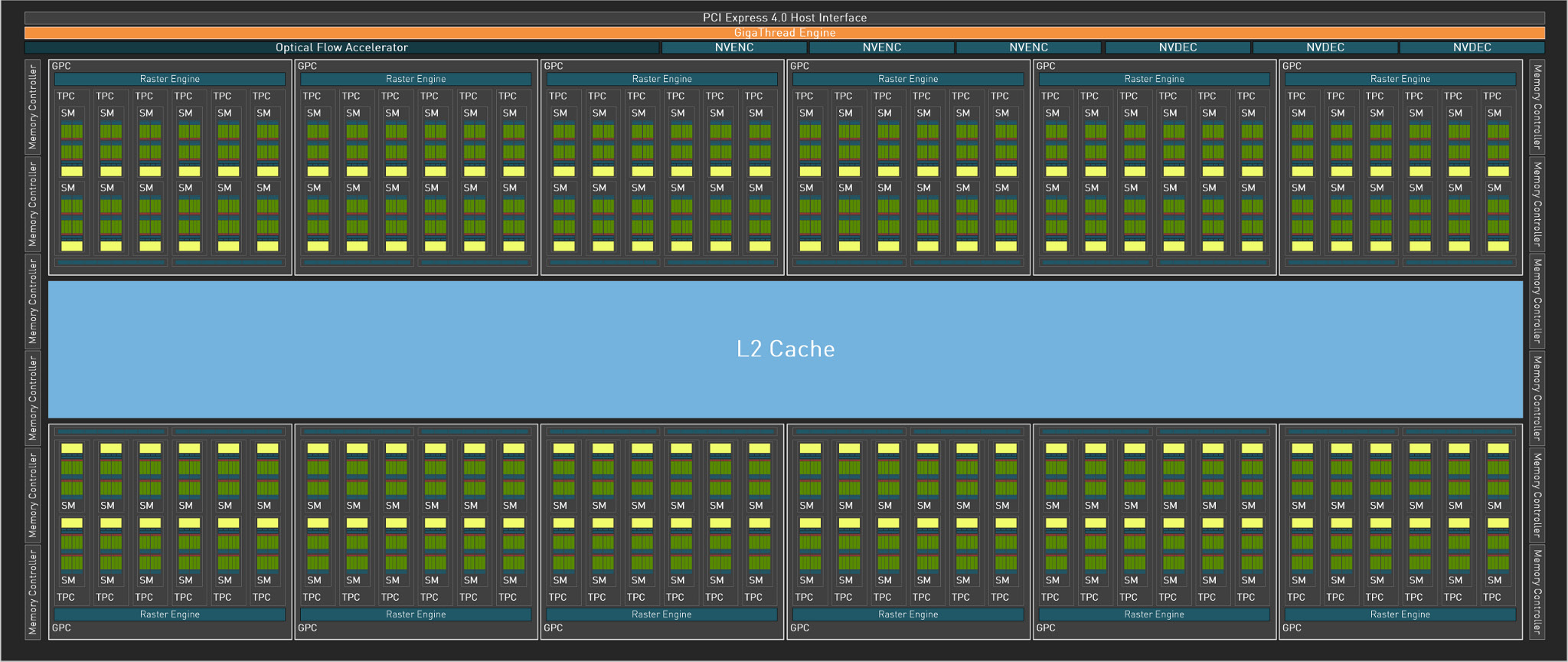
그래픽 카드의 chip을 보면 GPCs(Graphics Processing Clusters)라는 것으로 이루어져있다. 여기서는 12개의 GPC로 이루어져있으며 그 외에 Optical Flow Accelerator나 NVENC 같은 부속 부품으로 이루어져있고 6개의 GPC 쌍의 중간에는 L2 Cache가 자리하고 있다.
이 GPC의 내부는 아래와 같다.
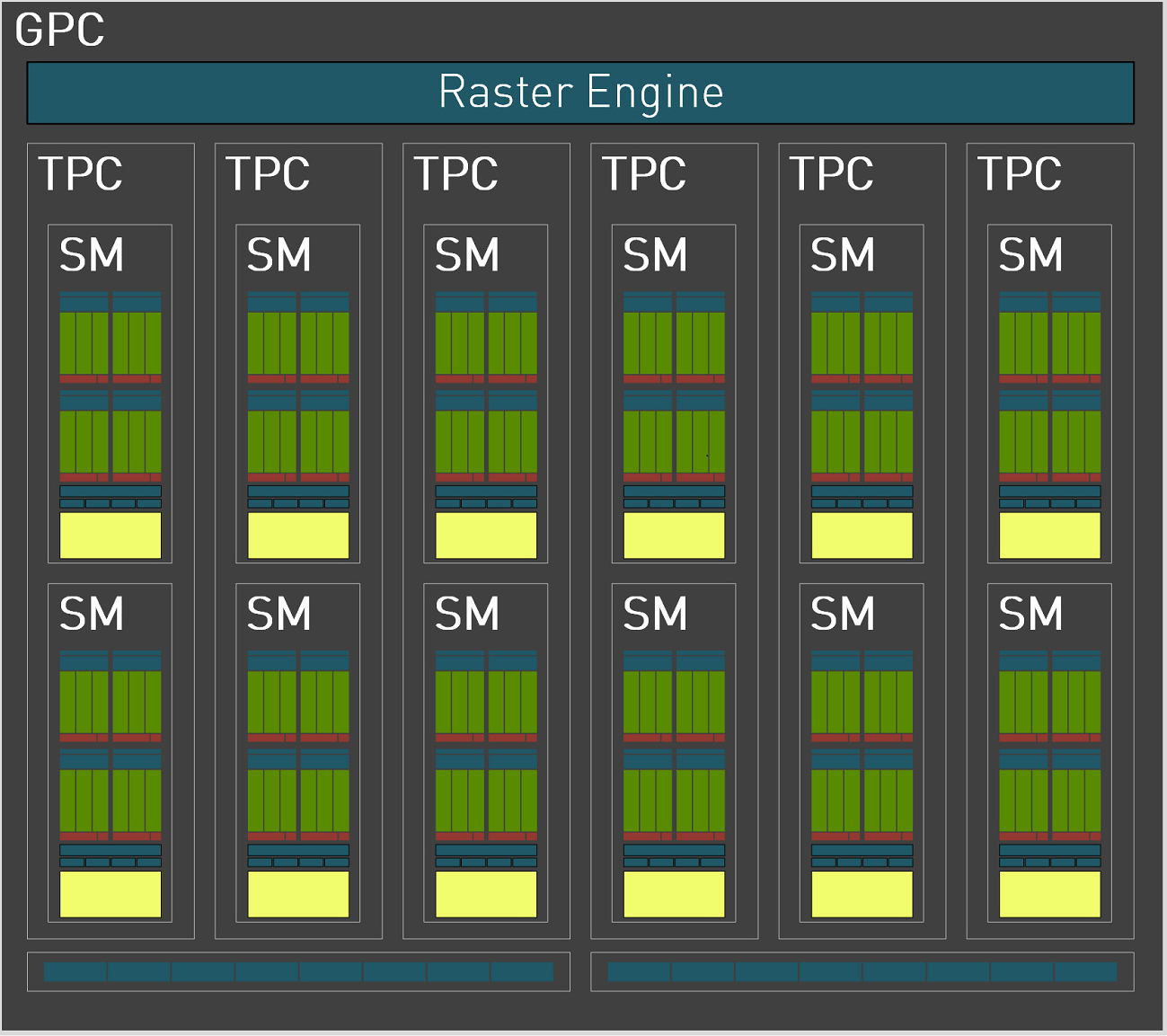
GPC 마다 1개의 Raster Engine이 있고 6개의 TPC(Texture Processing Cluster)가 있으며 2개의 Raster Operations(ROPs, 가장 GPC 가장 아래에 8개씩 두 개의 파란색) 이 있다. 그리고 TPC는 2개의 SM과 1개의 PolyMorph Engine으로 이루어져있다.
2) SM
SM의 구조는 아래와 같다.
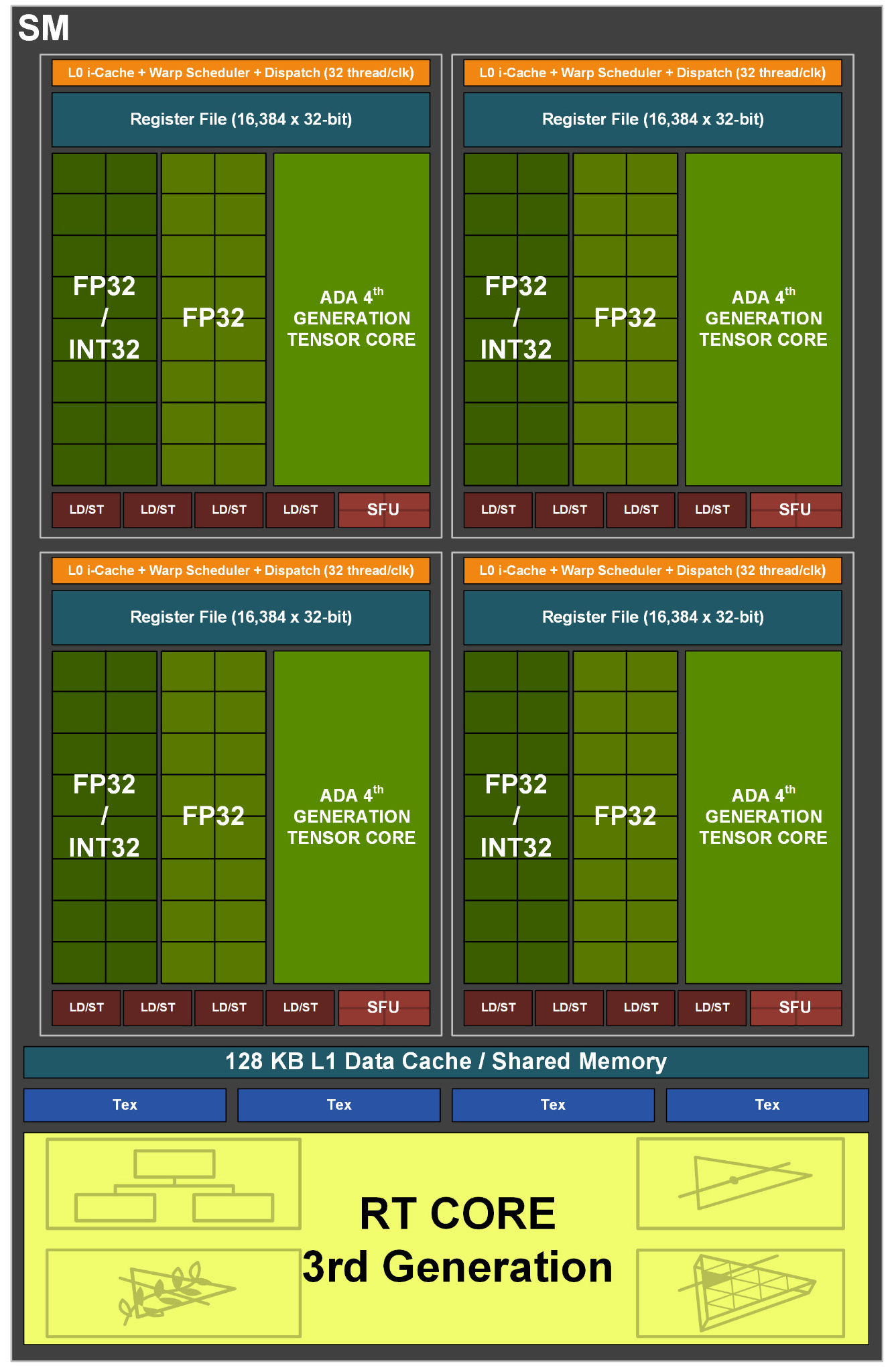
SM당 포함하고 있는 것은 아래와 같다.
- 4개의 프로세싱 블록
- 128KB 크기의 L1 Data Cache이자 공유 메모리
- 4개의 Texture Unit
- 2개의 FP64 Unit
여기서 FP64 unit이라는건 부동 소수점 연산을 할 수 있는 유닛인데 64bit 크기의 부동소수점을 연산할 수 있는 회로라고 생각하면 된다.
3) Processing Block
각 프로세싱 블록은 아래와 같은 유닛들을 포함하고 있다.
- FP32 or INT32 (32bit 부동소수점연산 혹은 32bit 정수연산)이 가능한 16개의 코어
- FP32 연산만 가능한 16개의 코어
- L0 명령어 캐시
- 1개의 Warp 스케줄러, 1개의 디스패치 유닛
- 1개의 64KB 레지스터 파일
- 1개의 SFU(Special Function Unit) : 삼각함수 같은 특수 함수 연산을 위한 유닛
- 4개의 로드/스토어 유닛
- 1개의 ADA 4세대 텐서코어
프로세싱 블럭마다 총 32개의 CUDA 코어가 있기에 한번에 처리하는 단위(Warp)가 32개의 스레드인것이며 최근에야 추가된 특수한 경우를 제외하고는 각 프로세싱 블럭에서 연산하는 것의 동기화를 할 수 없다.
4. GPU가 Thread를 처리하는 방법
1) 기본적인 처리법
위에서 언급했듯이 SM마다 총 4개의 프로세싱 블록이 있다.
이 프로세싱 블록은 Warp라는 단위로 구동된다. 한 개의 프로세싱 블록 마다 하나의 warp가 돌아가는 것이다.
이는 warp가 32개의 thread로 이루어진 것과도 연관이 있다.
각 Thread는 32개의 FP32 코어 혹은 16개의 FP32, 16개의 IN32 코어를 포함하고 있다.
한 사이클마다 32개의 부동소수점 연산 혹은 16개의 부동소수점, 16개의 정수 연산을 할 수 있다는 소리다.
Thread Block 단위로 SM에 배정이 되며 Warp는 프로세싱 블럭에서 독립적으로 구동된다.
Warp에 대한 스케줄링은 프로세싱 블록 내부에 있는 Warp Scheduler 가 담당하며 SM당 최대 Warp의 개수는 별도로 정의된 바에 따른다.
기본적으로 Thread Block을 GPU에게 맡기려면 각 블럭당 필요한 L1 캐시 크기와 Register 개수가 확보가 되어야 배정할 수 있다.
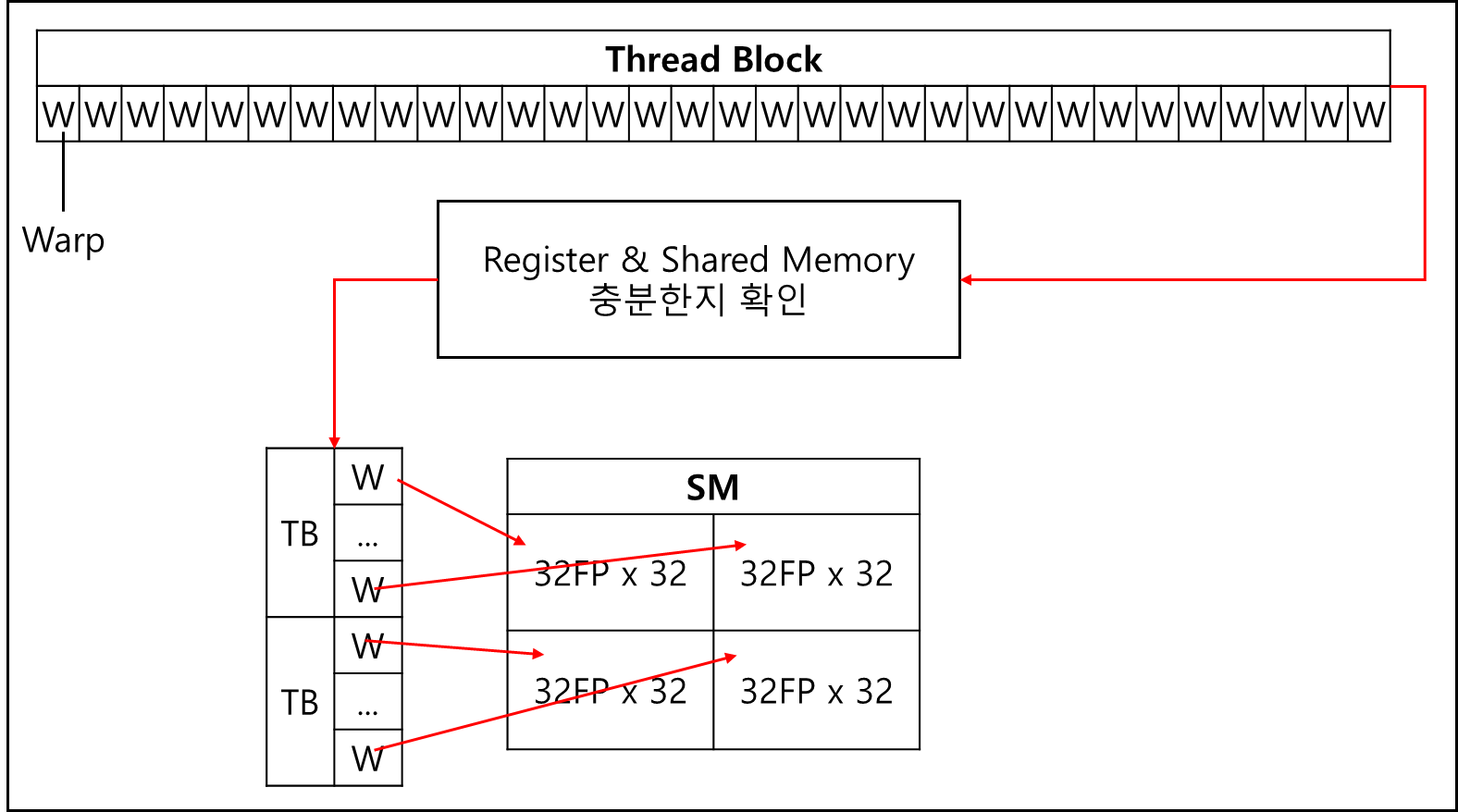
물론 모든 데이터를 L1 캐시에 다 넣을 수 없기 때문에 스레드 구동간에 필연적으로 VRAM에 엑세스를 해야하는데, 그렇게되면 GPU 수백 사이클을 허비해야한다. 이는 사용률에 안 좋은 영향을 미치기 때문에 CPU에서 하듯이 GPU도 구동되고 있는 Thread를 교체한다.
단, 이때 구동되고 있던 정보들은 Register에 고스란히 보관되었다가 필요한 데이터를 VRAM에서 갖고오게 된다면 그때 다시 전환되는데 일반적인 OS의 Context switching에 비해 시간이 월등히 적게 드므로 “Zero cost context switching” 이라고 한다.
위와 같이 Context Switching에 드는 비용이 극단적으로 적기 때문에 한 SM당 최대한 많은 수의 Warp를 배정하는게 좋다.
이는 cache miss에 따른 memory latency를 context switching을 통해서 숨길 수 있기 때문이다. 이를 latency-hiding이라고 한다.
SM당 최대 Warp 수가 정해져있는데 Compute Capability 별로 다르다. 만약 최대치를 48이라 할 경우 이 중에서 16개의 Warp만 지정해두었다고해보자 그러면 12/48 만큼 Warp가 SM에서 구동되고 있는 것인데, 이를 Warp Occupancy라고 하며 일반적으로 높을 수록 좋으나 너무 높다면 여유 Register와 여유 L1 / Shared cache가 생길때까지 프로세스 블럭에 Warp가 배정이 안되므로 되려 성능은 떨어질 수 있다.
따라서 뭐든 적절한 수준의 크기 조정이 필요하며 대부분 최고 성능일때 Warp Occupancy는 약 70 ~ 80% 정도라고 한다.
※ 참고1 - Warp Occupancy 산출 공식
\(The number of concurrently active warps / The number of maximum possible warps\)
최대 가능한 Warp 수 분의 동시에 구동중인 Warp 수이다.
※ 참고2 - 2차원 이상에서의 처리 방식
CUDA에서는 Block과 Thread를 2차원이상으로 지정할 수 있다. 그렇다면 이 경우 어떻게 실행될까?
이런 경우 x값을 기준으로(row-major) 실행이 된다.
이래의 예시를 보자.
Q) Kernel에서 그리드 내의 Thread block의 개수가 x=8, y=8이고 한 스레드 블록내의 Thread의 개수가 x=4,y=8 일때 전체 스레드의 갯수를 구하고 1432번째로 실행되는 스레드의 Thread block의 x,y값과 ThreadIdx의 x,y 값을 구하라.
A) 그림을 전체 구조를 나타내면 아래와 같다.
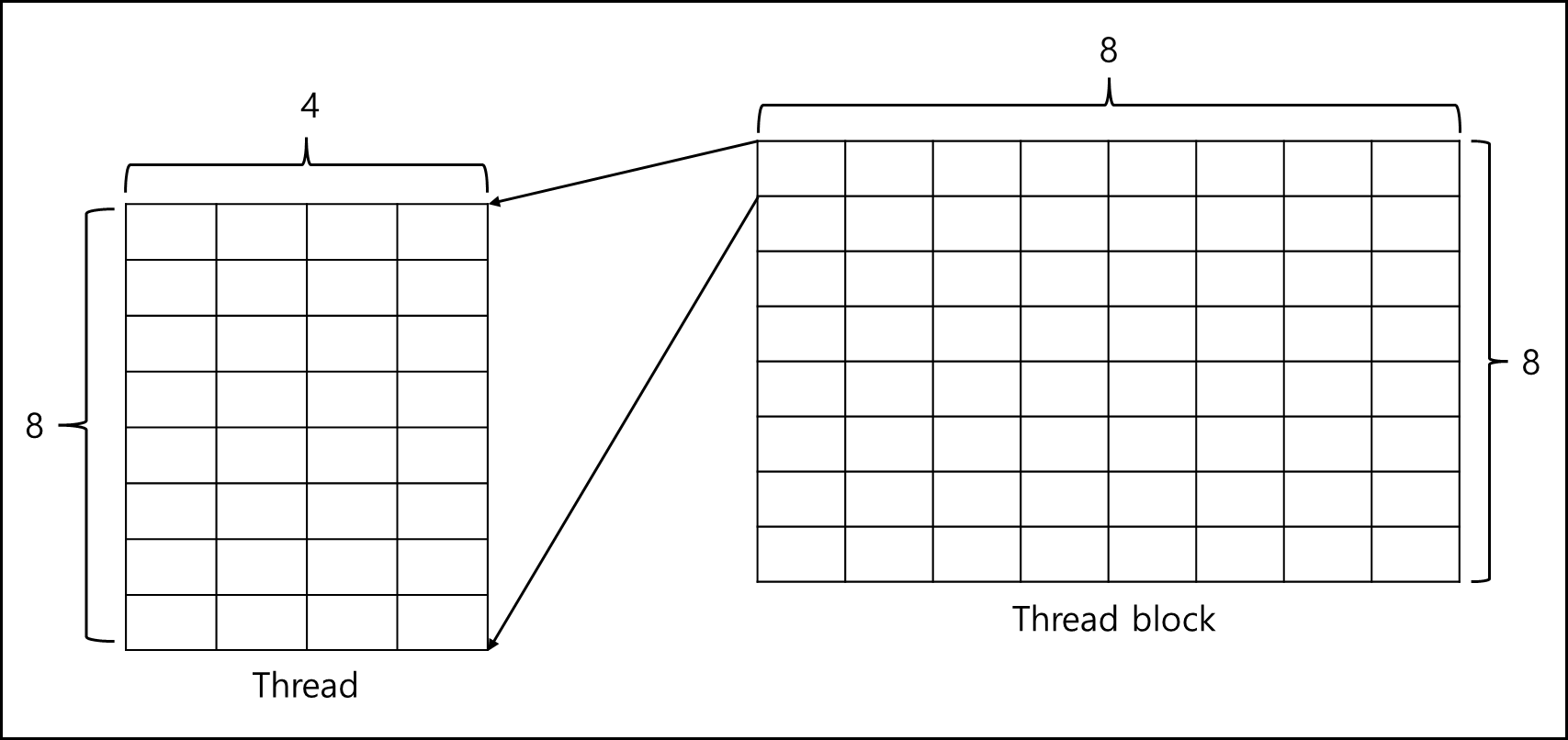
한 블록당 Thread 개수
\(8 \times 4 = 32\)한 그리드당 Thread block의 개수
\(8 \times 8 = 64\)커널 전체의 Thread 개수
\(64 \times 32 = 2048\)1432번째 실행되는 스레드의 위치
row-major 순으로 실행되니 아래와 같은 순서이다.
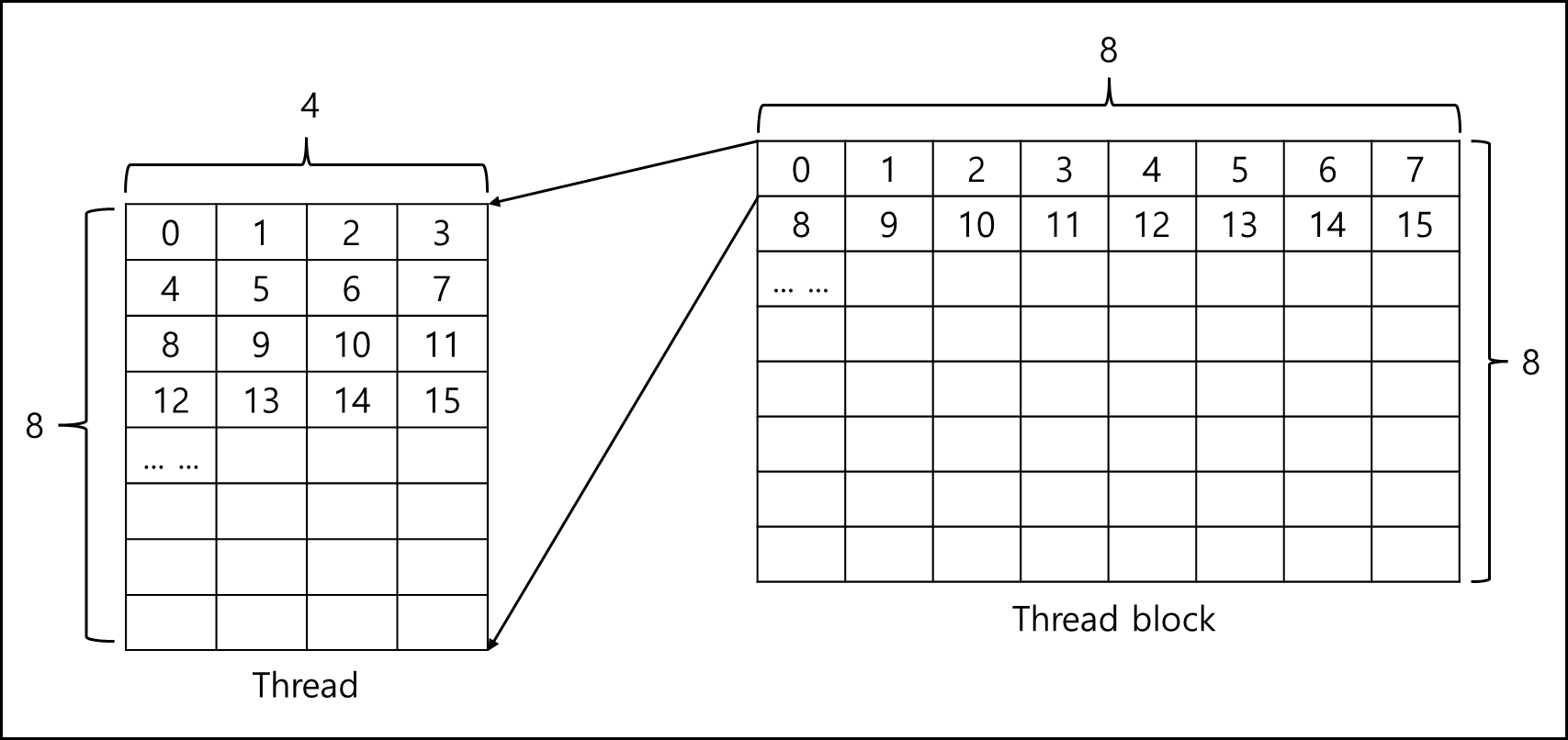
1번 스레드 블럭 -> 1번 스레드 블럭 안에 1번 ~ 32번 스레드 -> 2번 스레드 블럭 순이다.
따라서 1432번째라면 45번째 스레드 블록이다.
(1432 / 32 = 44.xx)
이 45번째 블록은 x 차원 수인 8로 나눌 경우 몫으로 5, 나머지가 5가 남는데, 이를 통해 x 값은 5, y값은 5라는 것을 알 수 있다.
나머지 24 thread는 해당 스레드 블록내에서 x값으로 3, y값으로 5이다 (index가 0으로 시작, 4x6=24) 그러므로 1432번째로 실행되는 스레드의 좌표는 아래와 같다.
blockIdx.x= 5 blockIdx.y= 5
threadIdx.x= 3 threadIdx.y= 5
2) 분기문 처리법
만약 GPU 연산에서 분기문이 생긴다면 어떻게 되는가?
전체적인 부분은 같으나, 세부적인 부분이 volta 버전 이전과 이후로 나뉜다.
아래의 코드를 보자.
1
2
3
4
5
6
7
void main() {
if(threadIdx.x < 3){
A;
} else {
B;
}
C;
위와 같이 한 개의 Thread에서 분기문이 생긴다면 해당 분기에 속하지 않는 Thread는 일시적으로 inactive화 된다.
그림을 표현하면 아래와 같다.
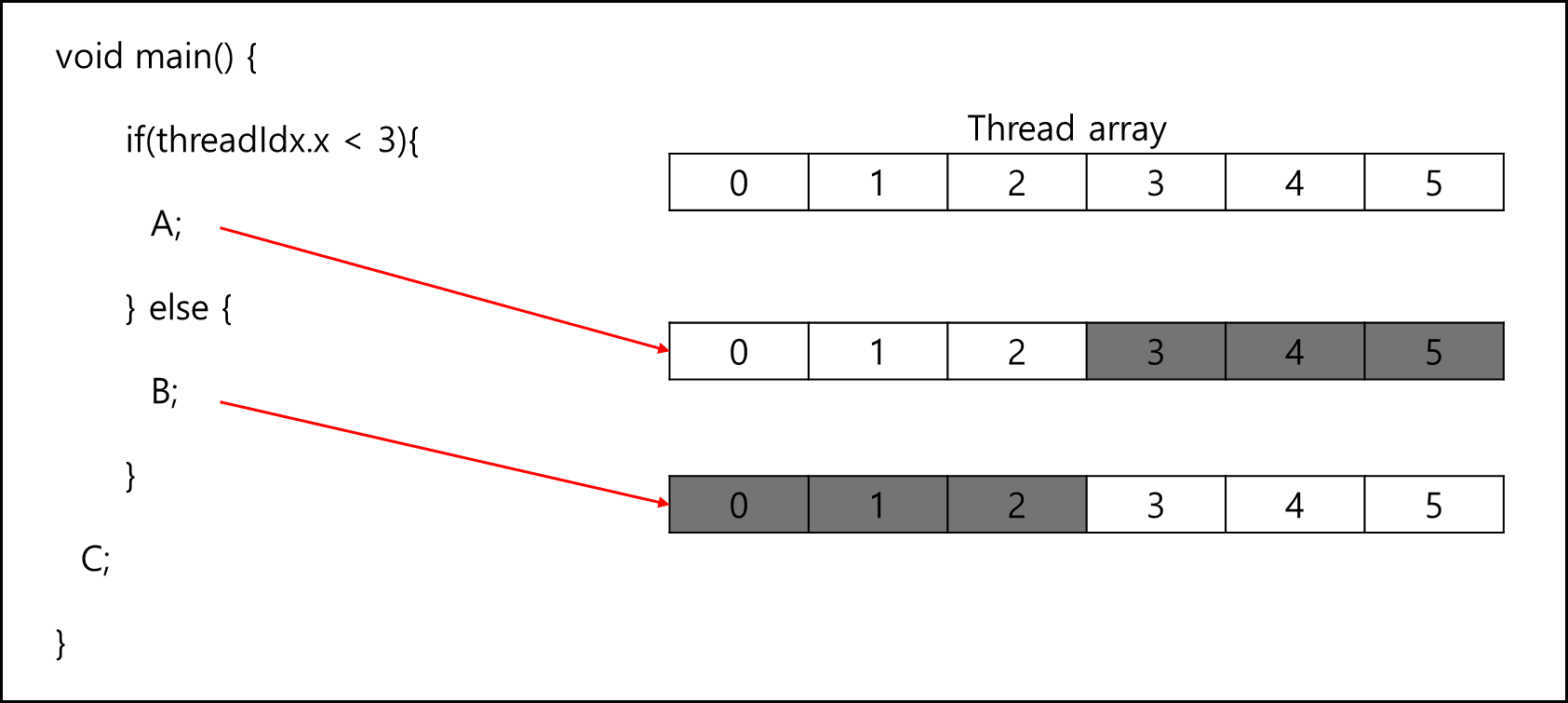
그냥 CPU에서 돌아가는 Single Thread 프로그램이라면 둘 중 하나만 실행되겠지만 GPU의 경우 모두 실행하되 해당 되지 않는 Thread는 inactive로 변경하여 처리해버린다. 요컨대 분기문이 많아진다면 GPU 사용률이 낮아지는 것이다. 때문에 GPU 프로그램을 코딩할때는 이런 것까지 고려해서 짜야한다.
이후에 volta 전과 이후의 차이에 대한 문제가 생기는데, volta 이전에는 warp의 각 Thread가 각 컨택스트에 대한 PC(Program Counter)와 Stack을 갖고 있지 않고 Warp 단위로 갖고있었지만 volta 버전 이후로는 각 Thread가 PC와 Stack을 가지게 되었기 때문에 추가적인 동기화를 해줄 필요가 생겼다. 아래의 코드를 보자.
1
2
3
4
5
6
7
8
9
void main() {
if(threadIdx.x < 3){
A;
B;
} else {
C;
D;
}
E;
위 코드에 따라 volta 버전 이전과 이후에 대해서 그려보도록 하겠다.
volta 이전
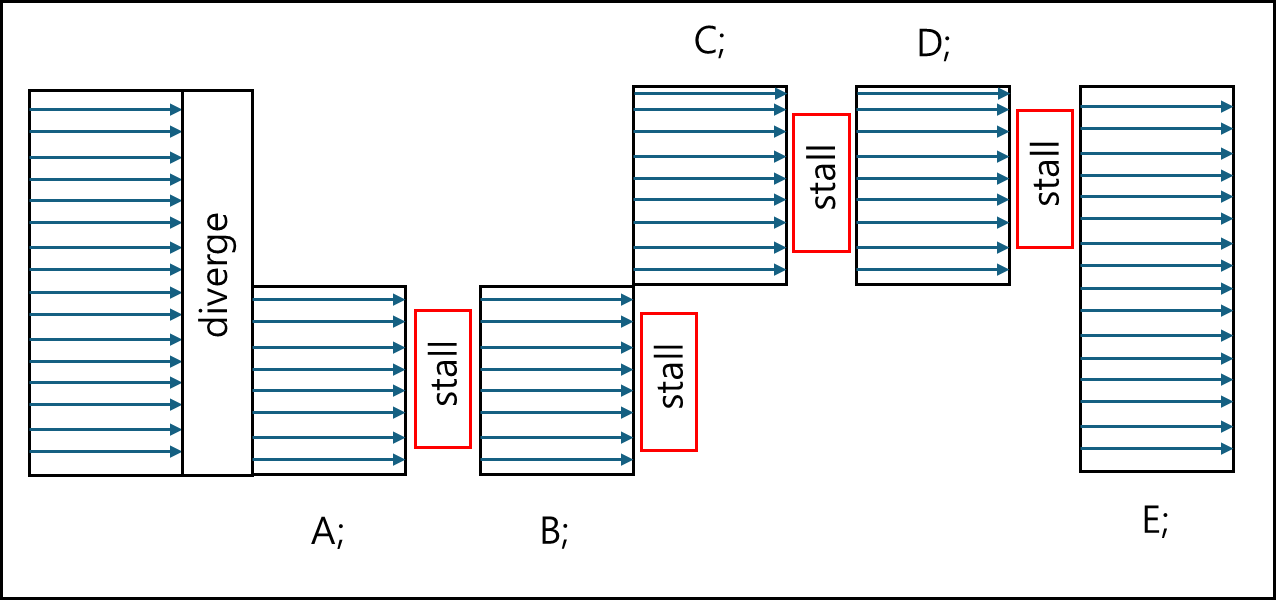
volta 이후
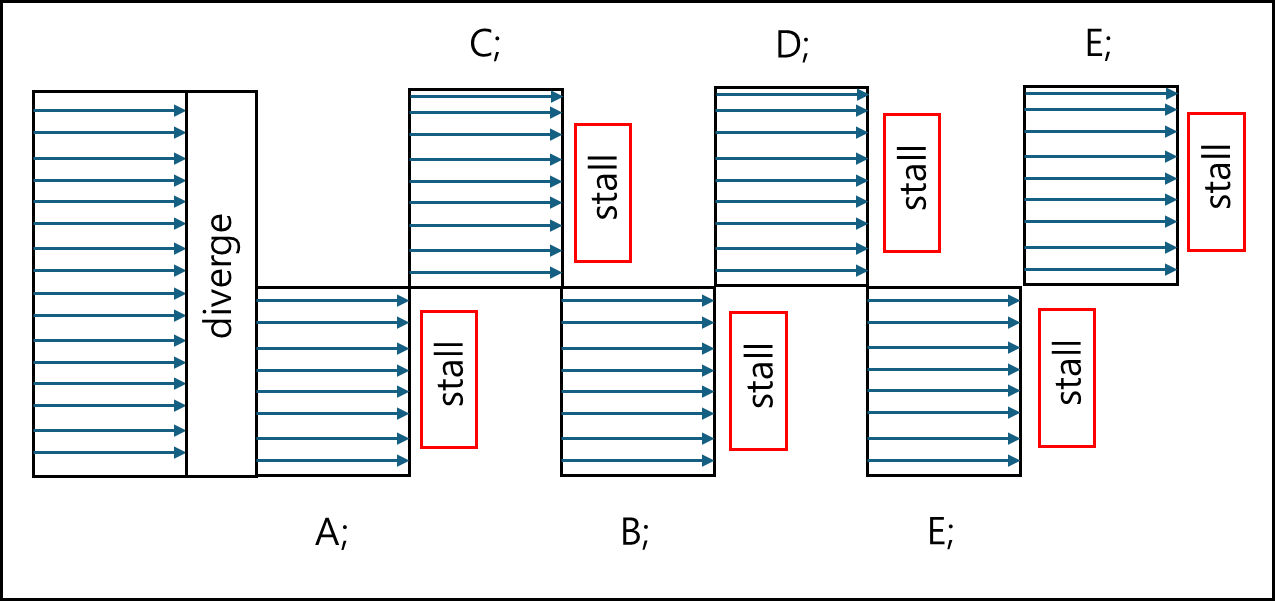
차이점이 보이는가? 이전에야 PC를 공유했으니 자동으로 Sync가 맞춰졌지만 Volta 아후에는 각 Thread가 PC를 가지게 되었기 때문에 각각 별도로 구동되어서 추가적인 Sync를 맞춰줄 필요가 생겼다.
volta 이전이라면 E가 동시에 작동되니 문제가 없지만 volta 이후라면 E의 실행에 문제가 생긴다.
특히 E이 A,B 혹은 C,D에서 한 작업과 의존성이 있다고 한다면 별도로 sync를 맞춰줄 필요가 있다. 이를 위해 명령어가 생겼으며 명령어를 이용하여 Sync를 맞춰주어야한다.
1
__syncwarp();
위 명령어는 warp안에 Thread가 해당 함수의 지점까지 모두 완료되는것을 기다리라는 명령어이다.
1
__syncthreads();
위 명령어는 Thread Block 안의 모든 Thread가 해당 함수의 지점까지 모두 완료되는 것을 기다리라는 명령어이다.
당연하지만 __syncwarp() 함수는 __synctrheads() 함수보다 비용이 적다.
때문에 어지간하면 __syncwarp() 함수로 동기화를 맞춰줘야할 것이다.
※ Thread가 inactive 되는 조건 3가지
1. 한 Warp에서 다른 Thread에 비해 일찍 완료된 경우
기본적으로 Thread는 모두 독립적으로 구동된다. 한 Warp에서도 각 Thread의 진행 상황은 다르게 구동될 수 있다.
프로세싱 블럭에서는 Warp 단위로 구동되기 때문에 Warp내의 작업을 다 한 Thread의 경우 Inactive한 상태가 된다.
2. 분기문으로 갈라질 경우
위에서 언급했듯이 분기문의 경우 해당 Thread를 Inactive로 두고 각 분기문을 실행한다.
3. Thread Block을 Warp의 배수(32의 배수)로 구성하지 않았을 경우
이런 경우는 사실 피해야하는 경우이다.
Thread block은 Warp 단위로 쪼개져서 프로세싱 블럭에 할당되는데 Warp가 32개의 단위인 만큼 만약 32개의 배수가 아닌 가령 33개인 경우 32를 제한 나머지 1개가 별도의 Warp로 잡혀서 돌아가기 때문이다.
이는 GPU 사용률을 최대로 높혀야 효율적인 방면에선 매우 좋지 못한 일이다.
※ 내용 업데이트 및 추가적인 검증 예정
참고문헌
- 서강대학교 임인성 교수님 - 기초 GPU 프로그래밍 수업 자료
- NVIDIA - NVIDIA ADA GPU ARCHITECTURE