GPU 프로그래밍 - Global Memory Coalescing
Global Memory Coalescing 예제분석
1. 개요
아래의 예제는 행렬 A,B,C가 있을때 A의 i번째 값 제곱 더하기 B의 i번째 값 제곱 더하기 1을 해서 C의 i번째 값으로 나누는 연산이다. 어떻게 구현하는지에 따라 속도가 달라지며, 이는 Global Memory에 어떻게 엑세스하고 어떻게 캐싱되는지에 대한 내용이다. 오늘은 CPU로 구동되는 코드 1개와 GPU로 구동되는 코드 3개를 종류에 따라 분석해보겠다.
2. 예제에 대한 분석
1) CPU 예제 분석
아래 코드는 CPU로 구동되는 코드이다.
1
2
3
4
5
void combine_three_arrays_CPU(const float* A, const float * B, const float* C, float* D, int n) {s
for(int i=0;i<N;i++){
D[i] = C[i]/(A[i]*A[i]+B[i]*B[i]+1.0f);
}
}
위에서 설명했듯이 A,B,C float 배열의 i번째 값을 갖고와서 A배열값과 B배열값은 제곱해서 더하고 1을 더한 뒤 C 배열값으로 나누어 D배열에 넣는 것이다.
위 코드는 잘 짜여진 코드인가? 조금 생각해볼 필요가 있다.
물론 GPU 코드와 비교하기 위해 있는 코드긴 하지만 조금 생각해볼 여지는 있다. 기본적으로 위 코드의 loop안에 있는D[i] = C[i]/(A[i]*A[i]+B[i]*B[i]+1.0f);이 코드는 float으로 계산된다. 또한 A,B,C,D의 각 블록 단위로 캐싱되어 구동된다. 따라서 캐시 미스는 그렇게 많지 않을 것이다. (캐시사이즈가 충분하다는 가정하에)
추가적으로 Non-blocking 캐시를 사용한다면 latency hiding까지 노려볼 수 있을 것이다.
위 코드를 더 최적화하기 위해서는 Loop unrolling 으로 구동 CPU 타입에 맞게 loop를 해제하는 정도까지는 가능할 것 같다.
2) GPU_0 예제 분석
1
2
3
4
__global__ void combine_three_ary_GPU_0(const float* A, const float* B,const float* C, float* D){
int i = blockDim.x * blockIdx.x + threadIdx.x;
D[i] = C[i] / (A[i] * A[i] + B[i] * B[i] + 1.0f);
}
심플한 방식이다. CPU 코드를 진짜 GPU로 그대로 옮겨온 것으로 그리드에 대한 스레드 전역 ID를 가져와서 A,B,C에 대해서 계산한다음에 D에 넣는 방식이다.
위와 같은 코드라면 아래와 같이 메모리에 엑세스 한다.
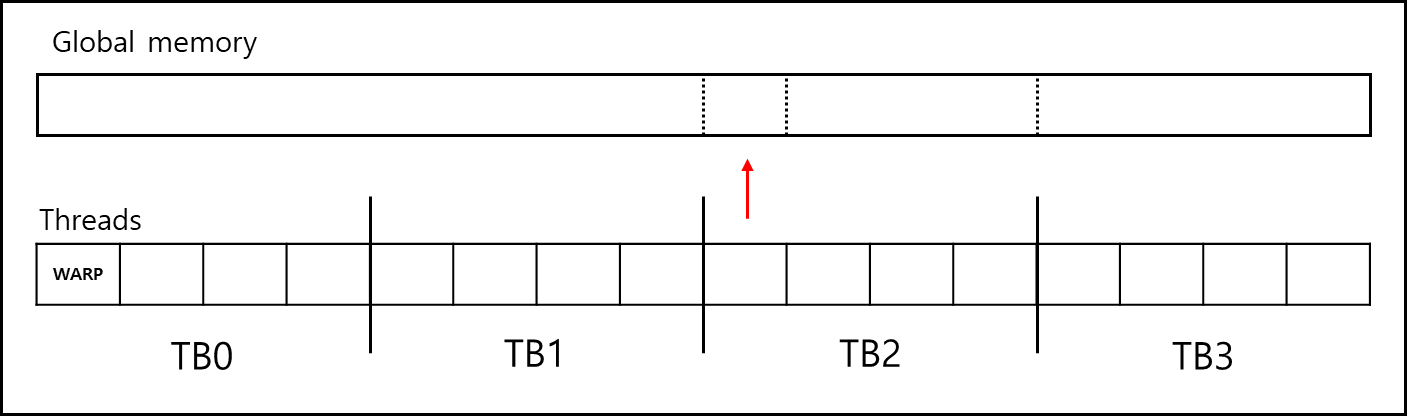
Thread block이 있고 Global memory가 있다면 thread의 순서대로 global memory에 Mapping 된다.
이는 블럭 단위로 갖고오는 캐시 특성상 좋은 접근 패턴이다.
3) GPU_1 예제 분석
1
2
3
4
__global__ void combine_three_ary_GPU_1(const float* A, const float* B,const float* C, float* D){
int i = threadIdx.x * girdDim.x + blockIdx.x;
D[i] = C[i] / (A[i] * A[i] + B[i] * B[i] + 1.0f);
}
코드를 보면 GPU_0에서는 GRID에 대한 전역 Index를 썼었다면 GPU_1에서는 아래와 같은 메모리 엑세스 패턴을 가진다.
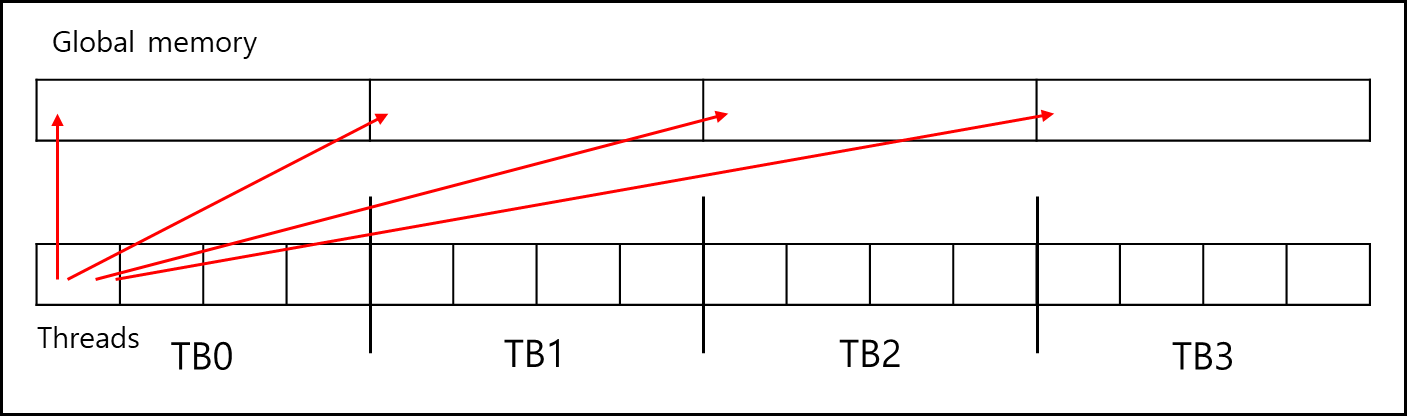
각 스레드는 Global Memory를 스레드 블록 사이즈로 나누었을때 각 블록의 index 번째의 값을 가져와서 계산한다.
이러한 경우 Globacl Memory에서 캐시사이즈대로 갖고와도 계속해서 캐시 미스와 캐시 replacement가 일어나므로 효율적이지 않다.
4) GPU_2 예제 분석
1
2
3
4
5
6
__global__ void combine_three_ary_GPU_2(const float* A, const float* B,const float* C, float* D, int image_width){
int column = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int i = row * image_width + column;
D[i] = C[i] / (A[i] * A[i] + B[i] * B[i] + 1.0f);
}
2차원으로 생각해서 계산하는 방식이다. 결론적으로 일차원 배열에서 계산하는 것은 같으나, Thread와 Thread block을 2차원으로 구성해서 구동하는 것인데 이 역시 GPU_0와 같이 캐시 배치와 지역성을 잘 살릴 수 있는 코드기에 성능은 꽤 빠르다.
3. 성능 평가
결론적으로 GPU_2 >= GPU_0 > GPU_1 순으로 성능이 좋으며, 이는 메모리 엑세스 패턴으로 인해 생기는 차이이다.
※ 내용 업데이트 및 추가적인 검증 예정
참고문헌
- 서강대학교 임인성 교수님 - 기초 GPU 프로그래밍 수업 자료
- NVIDIA - NVIDIA ADA GPU ARCHITECTURE