병렬분산컴퓨팅 - MPI
병렬 분산 컴퓨팅 - MPI
원래는 분산 메모리 프로그래밍 관련 내용인데 이쪽에서 가장 유명한 라이브러리가 MPI라서 MPI 관련으로 포스팅을 하겠다.
1. 개요
이전에 포스팅 했던 OpenMP는 Shared memory programming 이었다.
하지만 이번에 포스팅할 내용은 Distributed memory programming 이다.
여기서 말하는 Distributed memory system이란 아래와 같다.
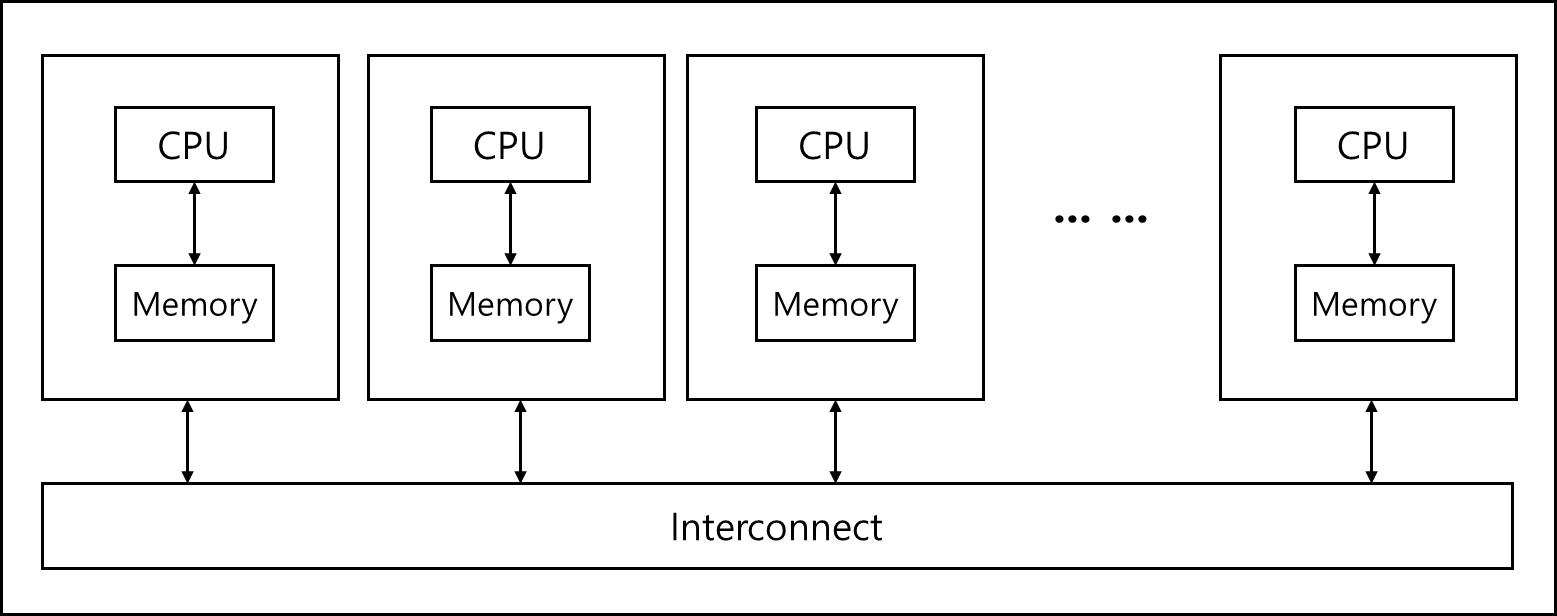
각 CPU에 Memory가 달린 상태에서 만약 어떤 CPU에서 다른 CPU에 달린 Memory로 엑세스하고 싶을 경우 Interconnect를 통해서 요청해서 가져와야하는 구조이다.
물론 위와 같은 구조에서 각 Node안에서도 Multi-thread를 이용해서 병렬화가 가능하다. 따라서 아래와 같은 구조로 구동되기도한다.
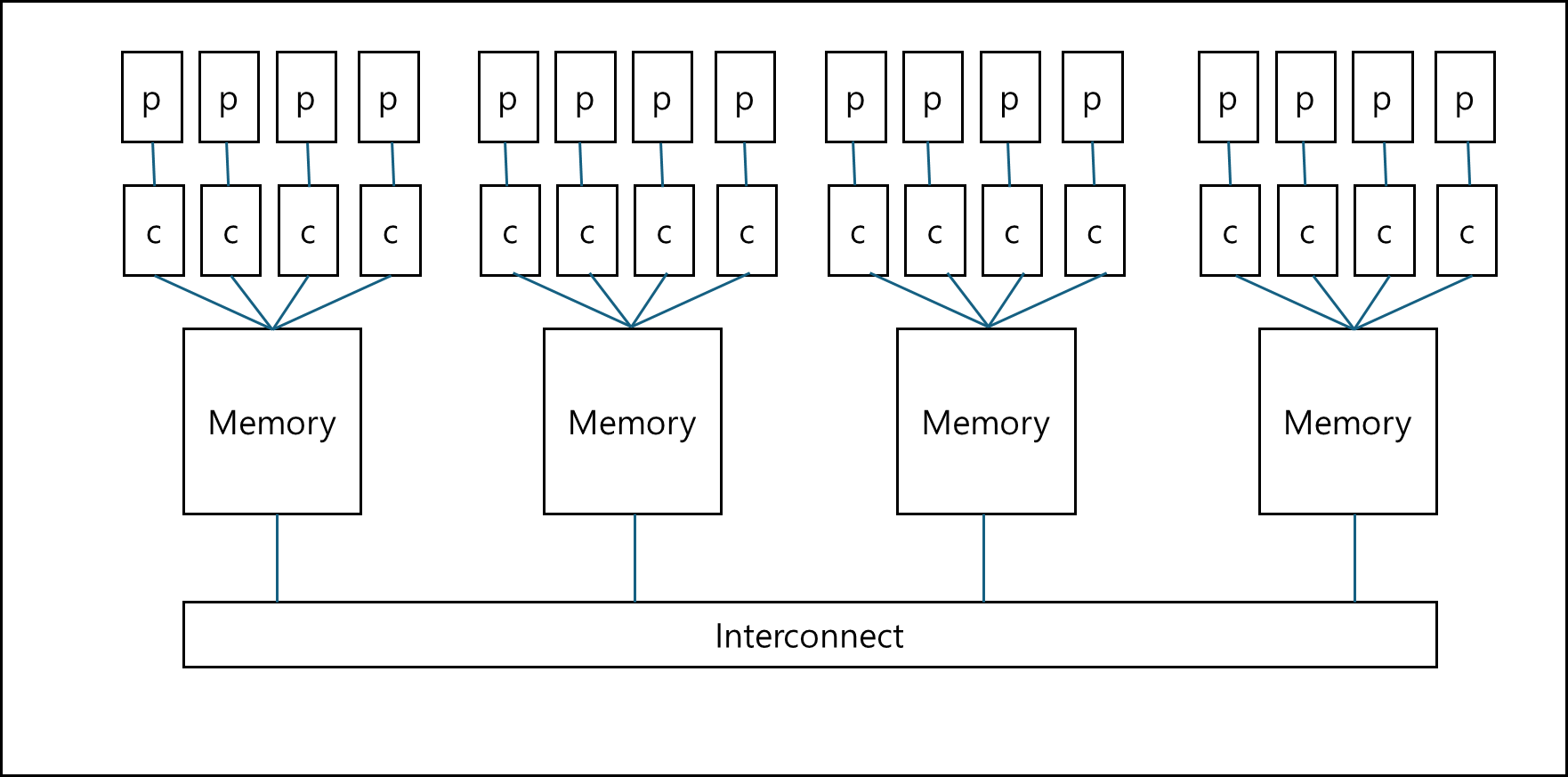
위와 같은 구조는 MPI와 OpenMP를 같이 쓰는 구조로, 여기에 GPU까지 포함되기도한다.
2. MPI 기본 문법
기본적으로 MPI는 API 스펙이다. 해당 스펙대로 구현한게 MPI 라이브러리이며,LAM/MPI나 OpenMPI등 여러 종류가 있다. 기본적으로 이기종 클러스터에 대해 지원하며, 2013년 부터는 GPU도 지원하기 시작했다.
1) Initialize
먼저 OpenMPI를 기준으로 설명하자면 사용하기 위해 아래의 코드로 시작해야한다.
1
2
3
4
5
6
#include<mpi.h>
int main(){
MPI_Init(&argc, &argv);
MPI_Finalize();
}
Init과 Fianlize 중앙의 영역에 MPI 코드를 써야한다.
2) Basic function
a. MPI_INIT
1
MPI_INIT(int *argc, char ***argv)
MPI 계산을 초기화한다.
b. MPI_FINALIZE
1
MPI_FINALIZE()
MPI 계산을 종료한다.
c. MPI_COMM_SIZE
1
MPI_COMM_SIZE(MPI_Comm comm, int *size)
- MPI_Comm comm : 커뮤니케이터 핸들러이다. 그룹에 대한 context이며 모든 프로세스는 기본적으로 MPI_COMM_WORLD에 포함되어있다.
- int * size : 그룹내 프로세스 개수를 반환한다.
d. MPI_COMM_RANK
1
MPI_COMM_RANK(MPI_Comm comm, int *rank)
- MPI_Comm comm : 커뮤니케이터 핸들러이다. 그룹에 대한 context이며 모든 프로세스는 기본적으로 MPI_COMM_WORLD에 포함되어있다.
- int * rank : 양의 정수의 유일한 값으로 프로세스의 ID 같은 것이다.
e. MPI_Send
다른 Node로 데이터를 보내는 Send 함수이다.
1
int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm);
- buf : 보낼 버퍼의 주소이다.
- count : 메세지 안에 아이템 개수이다.
- datatype : data의 타입이다.
- dest : 메세지를 받을 프로세스의 RANK값 즉, ID 값이다.
- tag : 메세지 종류이다. 사용자가 정의해서 사용할 수 있다.
- comm : 이전에 SIZE나 RANK에서도 봤듯이 통신에 참여하는 그룹 같은걸로 생각하면 편하다. 기본값은
MPI_COMM_WORLD이다.
f. MPI_Recv
다른 Node에서 데이터를 받는 Receive 함수이다.
1
int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
- *buf : 메세지를 전달 받을 버퍼 주소이다.
- count : 버퍼 크기이다.
- datatype : 받을 데이터의 데이터 타입이다.
- source : 지정하면 해당 source에 해당하는 데이터만 받을 수 있다, 만약 제한을 두고 싶지 않다면
MPI_ANY_SOURCE로 지정하면 된다. - tag : 지정하면 해당 tag의 데이터만 받을 수 있다, 만약 제한을 두고 싶지 않다면
MPI_ANY_TAG로 지정하면 된다. - comm : 이전에 SIZE나 RANK에서도 봤듯이 통신에 참여하는 그룹 같은걸로 생각하면 편하다. 기본값은
MPI_COMM_WORLD이다. - *status : Send 함수와는 다르게 Recive는 해당 status 객체로 완료 여부 등을 판단할 수 있다. 세부 구조는 아래에 서술되어있다.
1
2
3
4
5
6
7
8
typedef struct ompi_status_public_t MPI_Status;
struct ompi_status_public_t {
int MPI_SOURCE;
int MPI_TAG;
int MPI_ERROR;
int _count;
int _cancelled;
}
- MPI_SOURCE : source에 해당 하는 프로세스의 rank값, 즉 ID 값이다.
- MPI_TAG : source의 tag 값이다.
- MPI_ERROR : 0이 아니라면 에러가 났음을 알리는 값이다.
- _count : 메세지의 크기이다. 위의 세 값들은 직접 엑세스가 가능하지만 이 값은
MPI_Get_Count()함수로 가져와야한다. - _cancelled : 함수가 통신 요청을 취소시 성공적으로 취소되었다면 0이 아닌 값으로 세팅된다. 이 값이 0아닌 값일시 위의 모든 값들을 유효하지 않다.
3. Hello word example
1
2
3
4
5
6
7
8
9
10
11
#include<mpi.h>
#include<stdio.h>
int main(int argc, char **argv) {
int rank, num, i;
MPI_Init (&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &rum);
printf("Hello from process %i of %i /n",rank,num);
MPI_Finalize();
return 0;
}
위의 코드는 연결된 서버 그룹내에 전체에 프로세스 중에 몇번째 프로세스로 작업해서 반환하는지 출력하는 코드이다.
실행하려면 아래의 코드를 linux에서 입력한다.
1
mpicc hello.c -o hello
1
gcc hello.c -o hello -I /usr/include/mpi -1mpi
4. Hostfile
위 예시에서 실행하는 코드는 기본적으로 Master node가 제어하고, slave node로 작업을 뿌려서 처리하는 방식이다.
때문에 slave node와 ssh와 같은 방식으로 연결할 필요가 있는데, 이를 실행할때마다 입력하면 귀찮기 짝이 없다.
때문에 hostfile이라는 파일을 만들어 인자로 넘겨주면, 그 파일에 적힌 서버로 요청을 해준다.
hostfil은 아래와 같은 구조이다.
1
2
3
192.168.0.5
192.168.0.7
192.168.0.100
위와 같이 IP 형태일 수도 있고, 혹은 아래와 같이 DNS 형태일 수도 있다.
1
2
3
test1.example.com
test2.example.com
test3.example.com
뒤에 아무런 지시자도 안넣으면 ROUND ROBIN 방식으로 하나씩 프로세스를 할당하게 된다. 에를 들어 DNS Hostfile을 예시로 든다면 test1, test2, test3 가 순차적으로 프로세스를 하나씩 할당받게 되는 것이다. 그리고 이렇게 만들어진 hostfile mpirun을 통해서 아래와 같이 실행할 수 있다.
1
mpirun -np 8 -hostfile hosts ./hello
5. Slot Modifer
각 slave node들이 다수의 코어를 가지고 있는데, 프로세스를 하나씩만 할당하는건 비효율적일 수 있다.
때문에 MPI에서는 Slot modifer라는 걸 지원한다.
slot modifier는 간단하게 말해서 각 node에 몇 개씩 프로세스를 할당할 거냐는 일종의 지시자이다.
앞서 hostfile에서는 아무런 지시자도 없었는데, 이는 default로 할당하려는 프로세스를 1개만 쓰겠다는 뜻이다.
test1에 프로세스 2개, test2에 프로세스 3개, test3에 프로세스 4개를 할당하고 싶다면 아래와 같이 입력하면 된다.
1
2
3
test1.example.com slots=2
test2.example.com slots=3
test3.example.com slots=4
실행은 동일하게 실행하면 된다.
6. Program Structure
1) SPMD
한 개의 명령어를 다수의 데이터로 처리하는 프로그램 구조이다. 아래와 같이 정의할 코드를 짤 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main(int argc, char **argv){
MPI_Init(&argc,&argv);
int rank, num, i;
MPI_Comm_rnak(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &num);
if(rank=0) {
char mess[] = "Hello world";
int len = strlen(mess)+1;
for(i=1;i<num;i++)
MPI_Send(mess,len,MPI_CHAR, i,MESSTAG,MPI_COMM_WORLD);
}
else{
char mess[MAXLEN];
MPI_Status status;
MPI_Recv (mess, MAXLEN, MPI_CHAR, 0 MESSTAG, MPI_COMM_WORLD, &status);
printf("%i received %s\n",rank,mess);
}
MPI_Finlize();
}
Master node를 하나 두고, 나머지로 하여금 메시지 수신자를 구동하게 하는 코드이다.
2) MPMD
구동하는 컴퓨터의 OS가 다를 수 있다. 이를 위해서 각기 다른 파일을 실행 시킬 수 있다.
이를 위해서 appfile을 만들어야한다. 아래는 appfile인 appconf의 예시이다.
1
2
-host 192.168.0.2 -np 8 myapp.solaris
-host 192.168.0.5 -np 2 myapp.linux
위의 host도 hostfile을 사용할 수 있다. 실행은 아래와 같다.
1
mpirun -app appconf
6. Point to point communication
앞서 설명했던 Send 함수와 Recv 함수로 어느정도 거리가 있는 두 Node 간에 통신이 있었다고 해보자.
그러면 아래와 같은 Data flow가 일어난다.
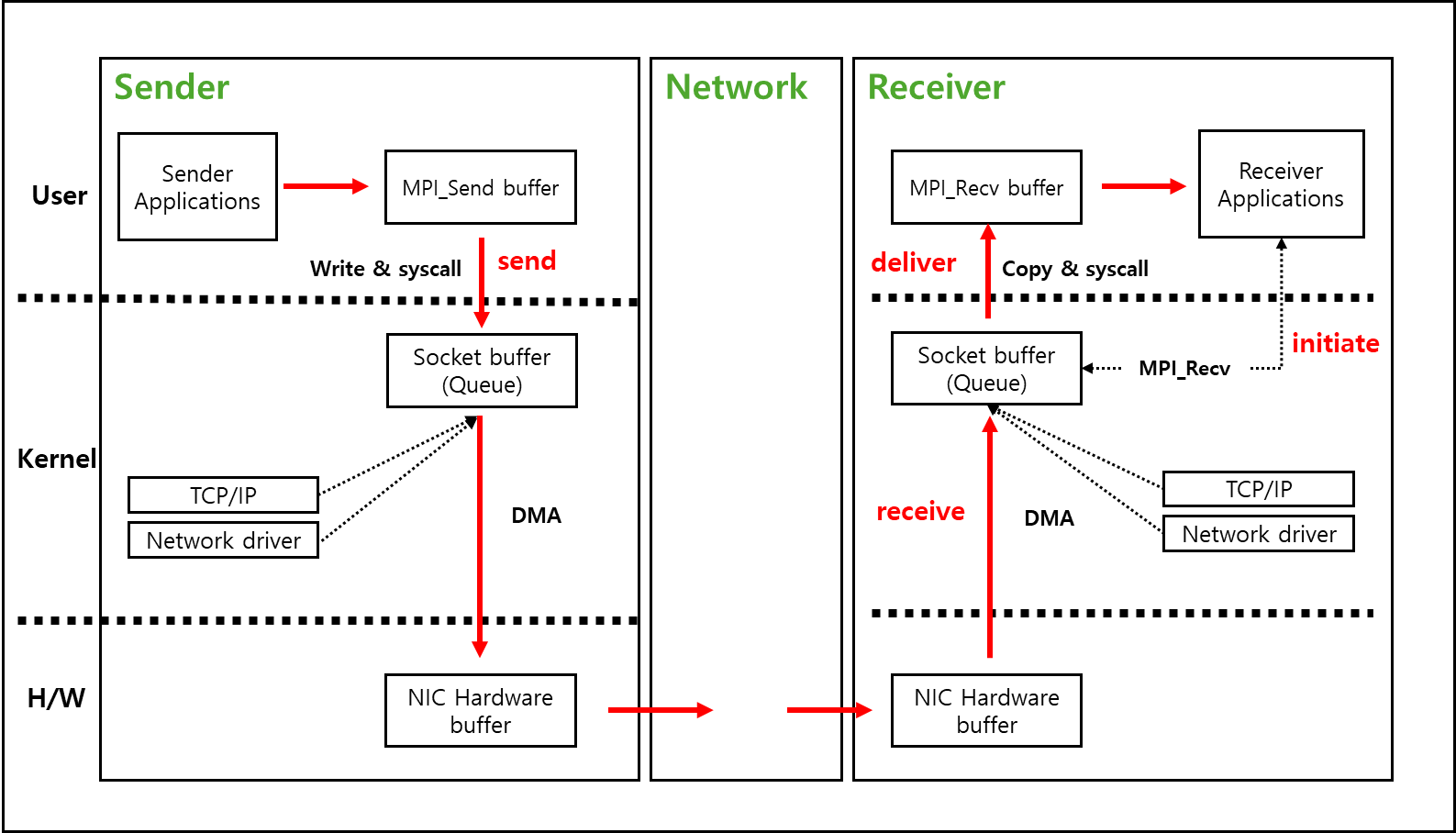
만약에 어떤 Node에서 다른 Node로 메세지를 보낸다고 할 때 어디까지 데이터가 전송되었을 때 전송되었다고 볼 수 있을까?
여러가지 정의가 있을 수 있겠지만 적어도 MPI에서는 빨간 색으로 표시된 send, receive, deliver는 아래의 정의에 따른다.
- send : user buffer에서 socket buffer로 데이터가 write 된 경우
- receive : 받는 Node에서 kernel의 socket buffer까지 데이터가 도착한 경우 receive
- deliver : user 영역의 buffer에 데이터가 도착한 경우 deliver
1) Block & Non-block
Send 함수와 Recv에 대해서 좀 더 자세히 알려면 Block과 Non-block에 대해서 알아야한다.
- blocking send는 메세지가
send가 되기전에 return이 되지 않는(locally blocking) 경우를 말한다. - blocking receive는 메세지가
receive나deliver되기 전에는 return 하지 않는 것을 말한다.
여기서 Non-blocking send/receive는 위에 설명한 것과 반대이다. 이게 무슨 소리냐 싶을 것이다.
아래의 예시를 보면 이해가 편하다. 아래의 예시를 보자.
2) 예시 : Process P, Process Q
Process P, Process Q가 있다. P는 sender고 Q는 receiver이다.
아래의 코드를 보자.
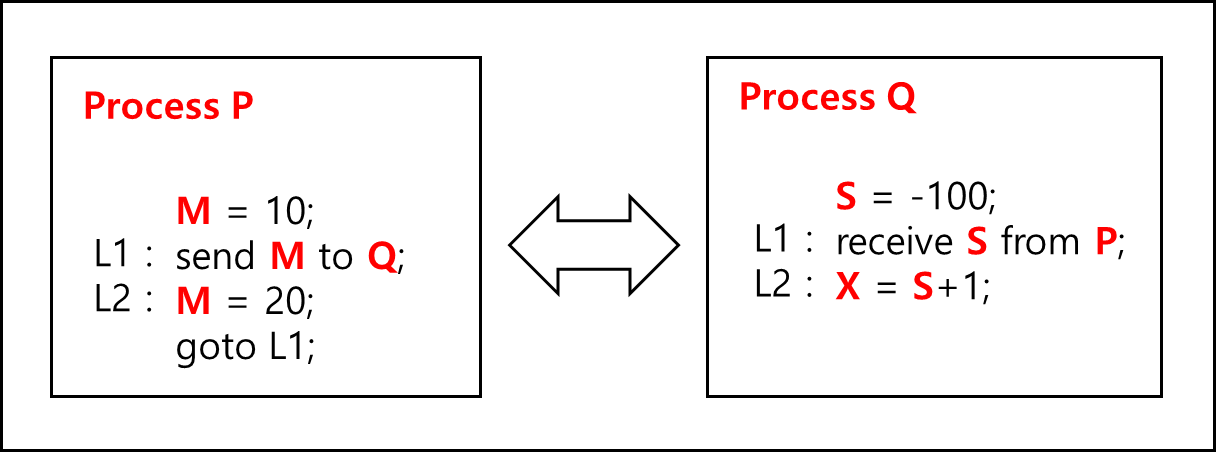
만약에 Blocking send와 Blocking receive를 사용 했을 경우 X 값은 11만 가능하다.
이는 Process P에서 buffer M 값을 Process Q로 보냈을 때, 해당 Node의 Socket buffer에 write 되고나서야 M=20; 코드가 실행되고 Process Q에서는 받은 값을 S에 넣어서 1을 더한 뒤 X에 넣는데, L1 위치의 코드도 S에 어떤값을 받지 않는다면 L2에 넘어가지 않기 때문에 11이 보장된다.
하지만 만약에 Non-Blocking send와 receive라면 어떨까? 이 경우 가능한 X의 값은 11, 21, -99이다. Blocking send/receive와 같이 구동되면 11이 반환 될 것이고, M=20으로 변경되는 시점에 Q로 전송된다면 21이 될것이며, receive 쪽에서 어떤 것도 받지 않았는데, 넘어가버리면 -99이다.
3) Communication Mode에 따른 함수의 종류
Communication Mode는 Send시 어떻게 보낼 것인가에 대한 프로토콜이라고 생각하면 된다.
총 4가지가 있으며 각 Mode에 대해 Block과 Non-block으로 나뉜다. 아래의 표를 보자.
| Communication Mode | Blocking Routines | Non-Blocking Routines |
| Standard Send | MPI_Send | MPI_Isend |
| Synchronous Send | MPI_Ssend | MPI_Issend |
| Ready Send | MPI_Rsend | MPI_Irsend |
| Buffered Send | MPI_Bsend | MPI_Ibsend |
| Receive | MPI_Recv | MPI_Irecv |
Basic function 파트에서 설명했던 Send와 Recv는 사실 Standard mode에서의 Send와 blocking Receive에서의 Receive 함수였으며 Receive의 경우 별도의 모드는 없고 Blocking인지 Non-blocking에 따라 차이만 있다.
a. Standard Send/Receive (Blocking 기준 설명)
여기서 설명하는 Standard Mode의 Send는 OpenMPI 기준이다. 다른 라이브러리의 경우 구현이 다를 수 있다.
OpenMPI에서 Standard 모드는 메세지의 길이에 따라 방식이 변한다. 모드 전환을 정하는 기준인 메시지 길이는 사용자가 정의하는 값이다.
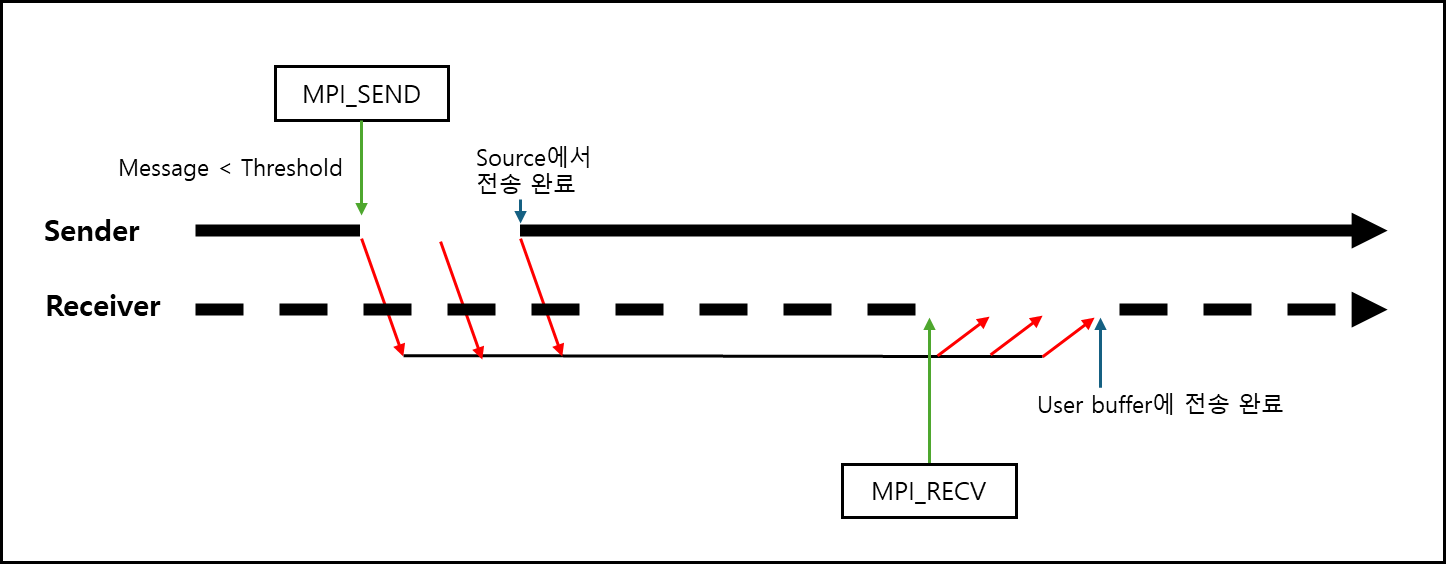
ⓐ 메세지가 짧을 경우 (<Threshold)
Eager protocol이라고 부르며, Receive하는 쪽의 Buffer 사이즈는 고려하지 않고 그냥 보내는것이다.
별도의 동기화 과정을 거치지 않기 때문에 동기화 오버헤드가 없다.
하지만 확장성에 대해서는 떨어진다. 아무래도 Receiver의 buffer를 고려하지 않기 때문이다. 이를 eagar protocol이라고 한다.
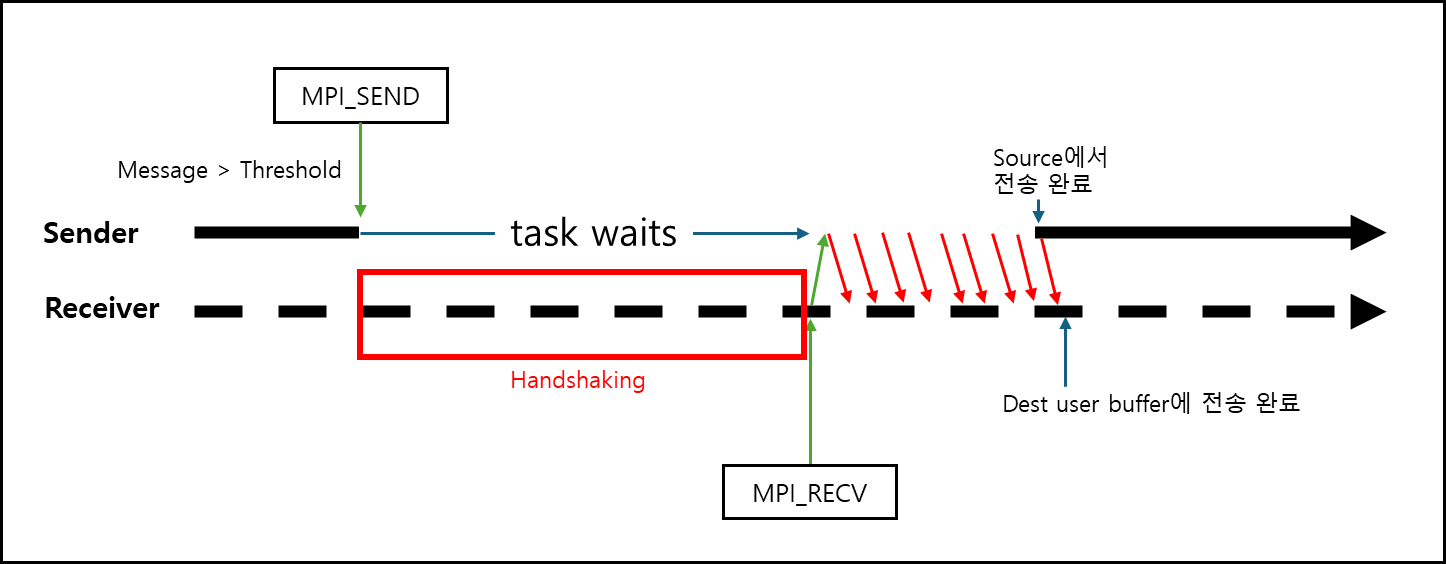
ⓑ 메세지가 길 경우 (>=Threshold)
보내기전에 Receiver한테 buffer가 충분한지 확인한다. handshaking 과정으로 확인하여 버퍼가 준비되면 전송하는 방식이다.
매우 안전하나 handshaking 과정에서 Overhead가 발생한다.
이를 rendezvous protocol이라고 한다.
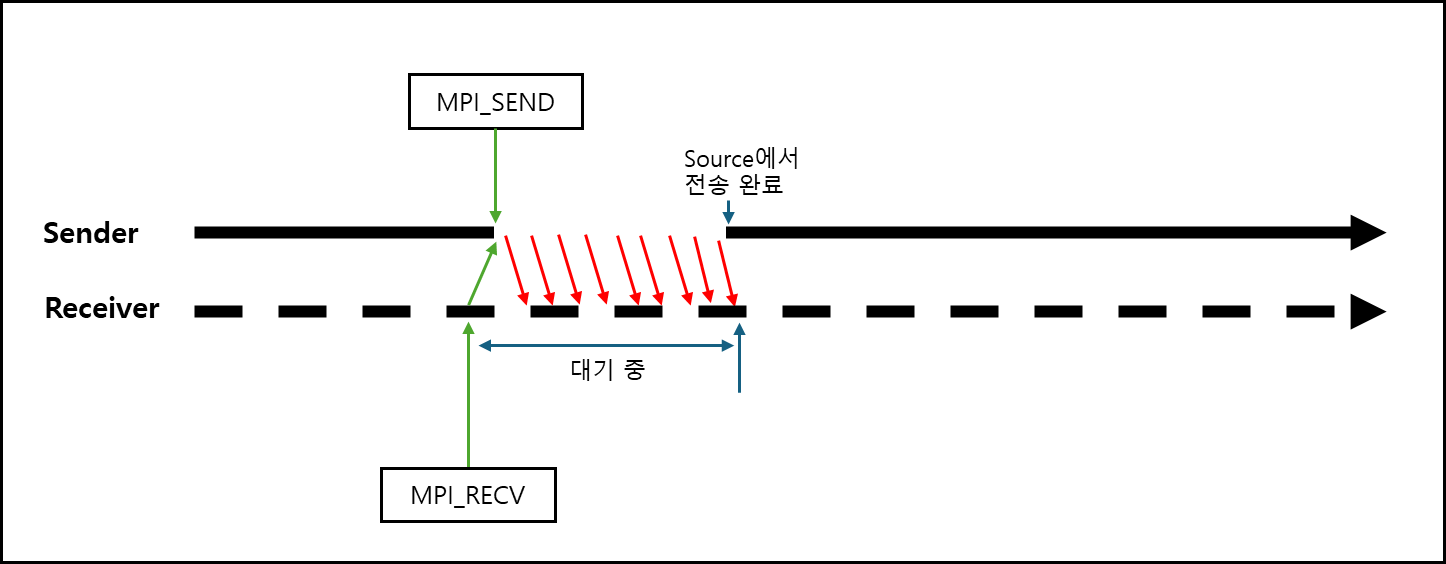
b. Synchronous Send/Receive (Blocking 기준 설명)
OpenMPI에서 Standard mode의 long message일때(rendezvous protocol)와 동일한 방식인데, 좀 더 명시적으로 쓰고 싶을 때 쓰면 된다.
c. Ready Send/Receive (Blocking 기준 설명)
이미 Receiver가 initiated 되어있을 때 전송했을 때만 성공 처리되므로 Receiver가 준비되어있을때만 보내는 것과 비슷한 방식이다.
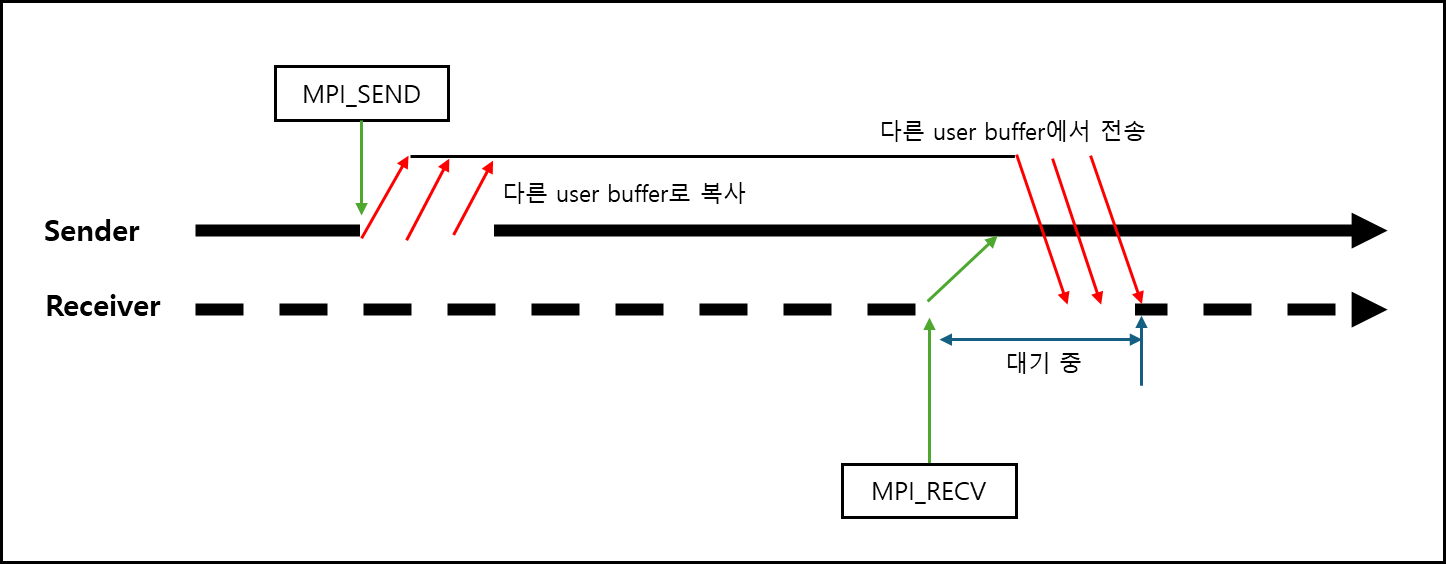
d. Buffered Send/Receive (Blocking 기준 설명)
다른 사용자 버퍼에 복사해두고 해당 버퍼에서 socket buffer로 보내서 전송시킨다음에 Sender의 프로세스는 계속 작업하는 방식이다.
동기화 오버헤드가 없으나 별도의 추가 복사가 있기 때문에 데이터가 너무 크다면 위험할 수 있다.
※ Non-blocking 설명이 없는 이유
위의 설명에서 blocking으로 기다리는 부분만 빼면 나머지는 각 모드에서 Non-blocking 방식과 동일하다.
※ Non-blocking 이 있는 이유
간단히 말해서 전송과 계산을 Overlap하여 전체적인 지연시간을 줄이기 위해서이다.
CUDA 스트림 Overlapping 이랑 비슷한 것이라고 생각하면 편하다.
※ 상태 제어
Non-blocking 함수의 경우 도착이 보장 되지 않는데 뭐 어떻게 처리하냐는 건지 물어 볼 수 있다. 여기서 Non-block send 함수의 경우에는 끝에 MPI_Request라는 구조체로 req라는 이름의 포인터 변수를 갖고 있다. 이를 아래의 함수에 인자로 넣고 사용하면 된다.
MPI_Wait
해당 작업이 완료될까지 기다리는 함수이다. 아래와 같이 사용한다. (Blocking)
1
int MPI_Test(MPI_Request *req, MPI_Status *st)
Non-blocking send 함수에서 받은 req 핸들러를 인자로 넘기고 MPI_Status라는 구조체의 *st에 들어간 값을 읽는다.
MPI_Test
해당 작업이 완료되었는지 확인만하고 넘어간다. (Non-blocking)
1
int MPI_Test(MPI_Request *req, int *flag,MPI_Status *st)
Non-blocking send 함수에서 받은 req 핸들러를 인자로 넘기고 MPI_Status라는 구조체의 *st에 들어간 값을 읽는다. 완료시에 flag는 0이 아닌 값으로 반환받는다.
7. Collective communication
2개 이상의 노드가 통신에 참여하는 작업으로, MPI에서는 이러한 작업을 함수로써 지원하며 함수는 내부적으로 최적화되어있다.
크게 나누면 아래의 세가지로 분류된다.
- Synchronization (Barrier)
- Data movement (Broadcast / Scatter / Gather)
- Reduction
1) Barrier 와 Broadcast
a. Barrier
다른 프로세스들이 모두 도착할때까지 기다리게하는 함수이다. cuda에서 사용하는 동기화함수 같은 것이다.
1
MPI_Barrier(MPI_Comm comm)
- comm : 커뮤니케이터 핸들러이다. 그룹에 대한 context이며 모든 프로세스는 기본적으로 MPI_COMM_WORLD에 포함되어있다.
b. Broadcast
한 개의 프로세스가 나머지 전체 프로세스로 내용을 뿌리는 함수이다. 보내는 프로세스와 받는 프로세스는 동일한 함수를 쓴다.
1
2
int MPI_Bcast(void *inbuf, int incnt, MPI_Datatype intype,
int root, MPI_Comm comm)
- *inbuf : 보내는 프로세스의 경우 보낼 데이터가 포함된 buffer 주소, 받는 프로세스의 경우 받을 buffer 주소이다.
- incnt : 보낼/받을 데이터의 개수이다.
- intype : 보낼/받을 데이터의 타입이다.
- root : 어떤 프로세스가 보낼 프로세스인지 정하는 값이다. rank값을 넣으면 rank값을 가진 프로세스가 보낼 프로세스가 된다.
- comm : 커뮤니케이터 핸들러이다. 그룹에 대한 context이며 모든 프로세스는 기본적으로 MPI_COMM_WORLD에 포함되어있다.
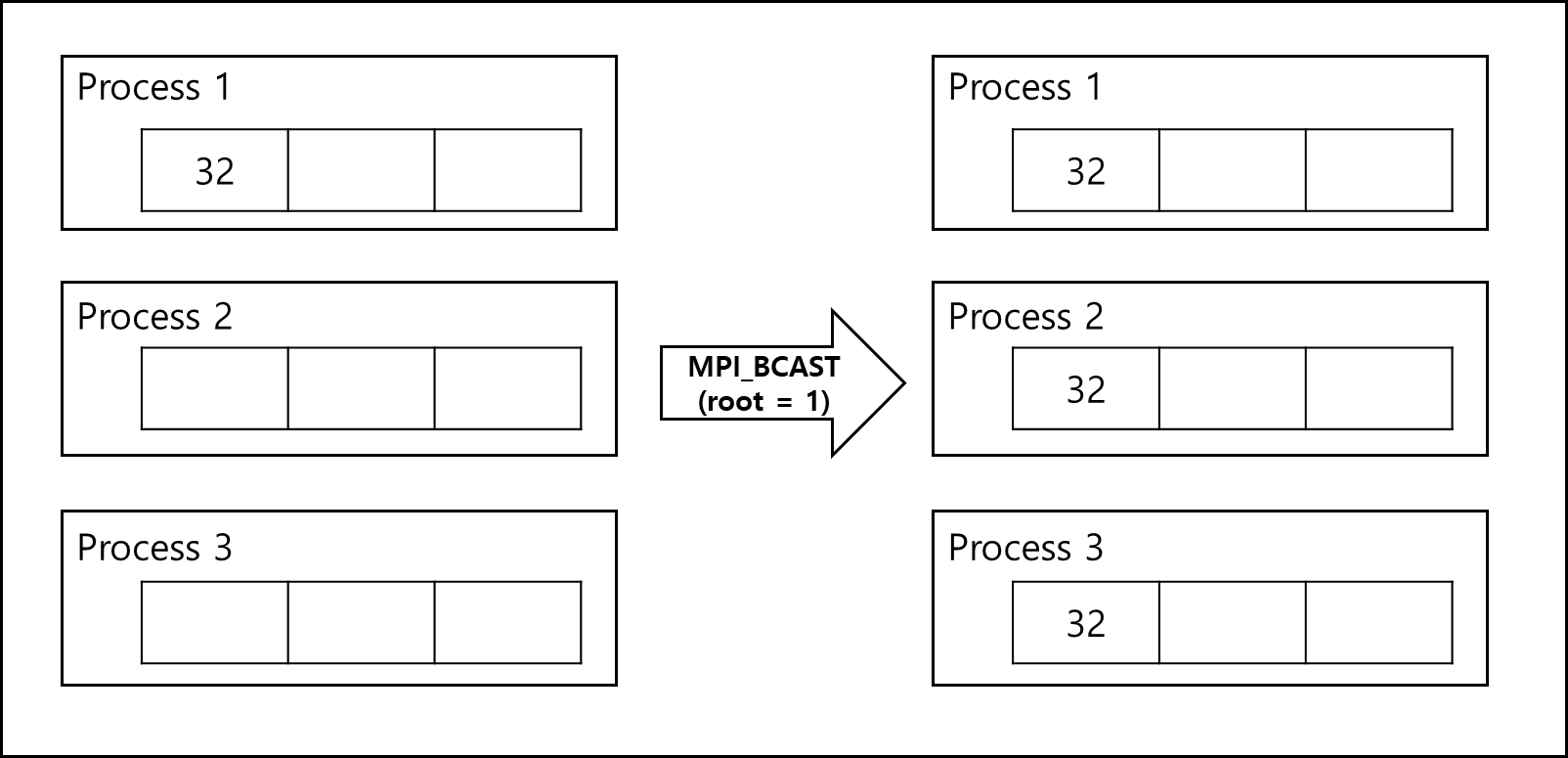
2) Gatter and Scatter
a. Gather
다수의 프로세스에 퍼져있는 데이터를 한 프로세스의 버퍼로 모으는 함수이다.
1
2
3
int MPI_Gather(const void *sndbuf, int sndncnt, MPI_Datatype sndtype,
void *recvbuf, int recvcnt, MPI_Datatype recvtype, int root,
MPI_Comm comm)
- *sndbuf : 데이터를 보낼 buffer 주소이다.
- sndncnt : 보낼 데이터의 개수이다.
- sndtype : 보낼 데이터의 타입이다.
- *recvbuf : 데이터를 받을 buffer 주소이다.
- recvcnt : 받을 데이터의 개수이다. sndncnt와 같다.
- recvtype : 받을 데이터의 타입이다. sndtype과 같다.
- root : 어떤 프로세스가 보낼 프로세스인지 정하는 값이다. rank값을 넣으면 rank값을 가진 프로세스가 보낼 프로세스가 된다.
- comm : 커뮤니케이터 핸들러이다. 그룹에 대한 context이며 모든 프로세스는 기본적으로 MPI_COMM_WORLD에 포함되어있다.
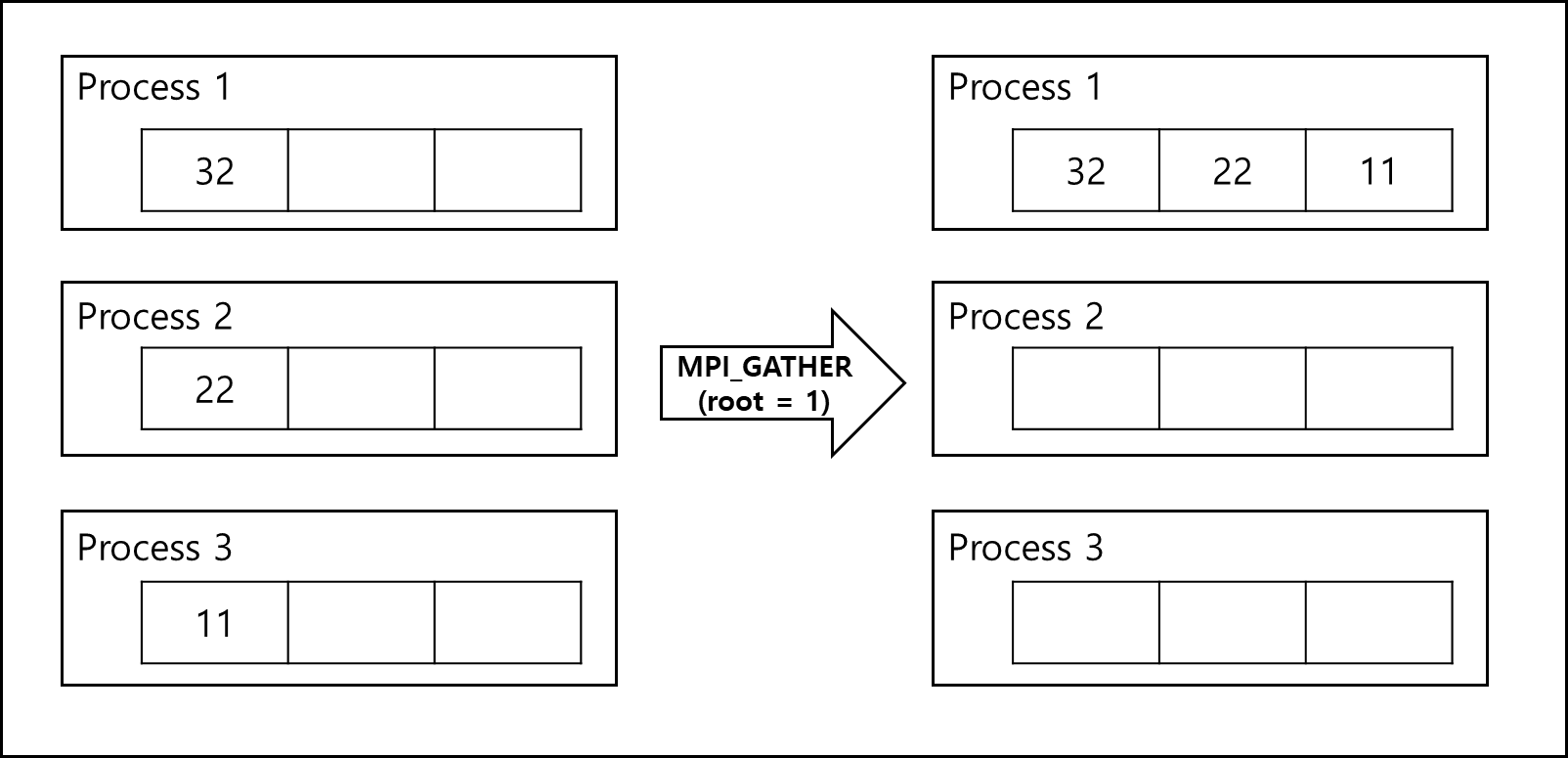
b. Scatter
한 개의 프로세스가 가지고 있는 다수의 데이터를 다수의 프로세스로 뿌리는 함수이다.
1
2
3
int MPI_Scatter(const void *sndbuf, int sndncnt, MPI_Datatype sndtype,
void *recvbuf, int recvcnt, MPI_Datatype recvtype, int root,
MPI_Comm comm)
- *sndbuf : 데이터를 보낼 buffer 주소이다.
- sndncnt : 보낼 데이터의 개수이다.
- sndtype : 보낼 데이터의 타입이다.
- *recvbuf : 데이터를 받을 buffer 주소이다.
- recvcnt : 받을 데이터의 개수이다. sndncnt와 같다.
- recvtype : 받을 데이터의 타입이다. sndtype과 같다.
- root : 어떤 프로세스가 보낼 프로세스인지 정하는 값이다. rank값을 넣으면 rank값을 가진 프로세스가 보낼 프로세스가 된다.
- comm : 커뮤니케이터 핸들러이다. 그룹에 대한 context이며 모든 프로세스는 기본적으로 MPI_COMM_WORLD에 포함되어있다.
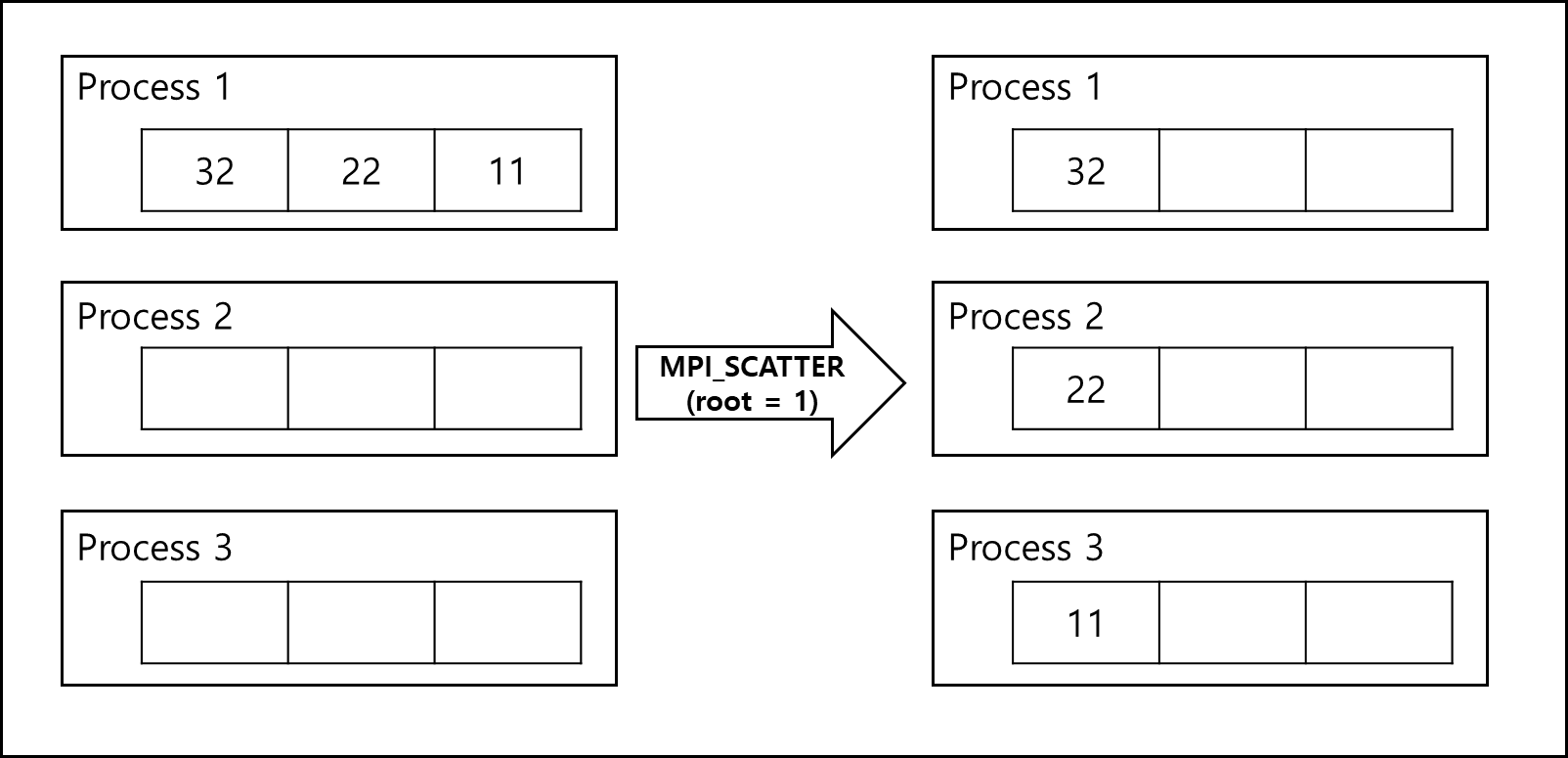
3) Reduction
말 그대로 다수의 프로세스에서 값을 받아와서 한 개의 프로세스에 해당 연산을 해서 저장하는 함수이다.
OpenMP에서 Reduction과 비슷하다.
1
2
3
int MPI_Reduce(const void *inbuf, void *outbuf, int cnt,
MPI_Datatype type, MPI_Op op, int root,
MPI_Comm comm)
- *inbuf : 처리할 데이터가 저장될 buffer 주소이다.
- *outbuf : 처리된 데이터가 저장될 buffer 주소이다.
- cnt : 보낼 데이터의 개수이다.
- type : 보낼 데이터의 타입이다.
- op : 연산자이다. 연산자에 대한 세부 내용은 별도의 표로 서술하겠다.
- root : 어떤 프로세스가 보낼 프로세스인지 정하는 값이다. rank값을 넣으면 rank값을 가진 프로세스가 보낼 프로세스가 된다.
- comm : 커뮤니케이터 핸들러이다. 그룹에 대한 context이며 모든 프로세스는 기본적으로 MPI_COMM_WORLD에 포함되어있다.
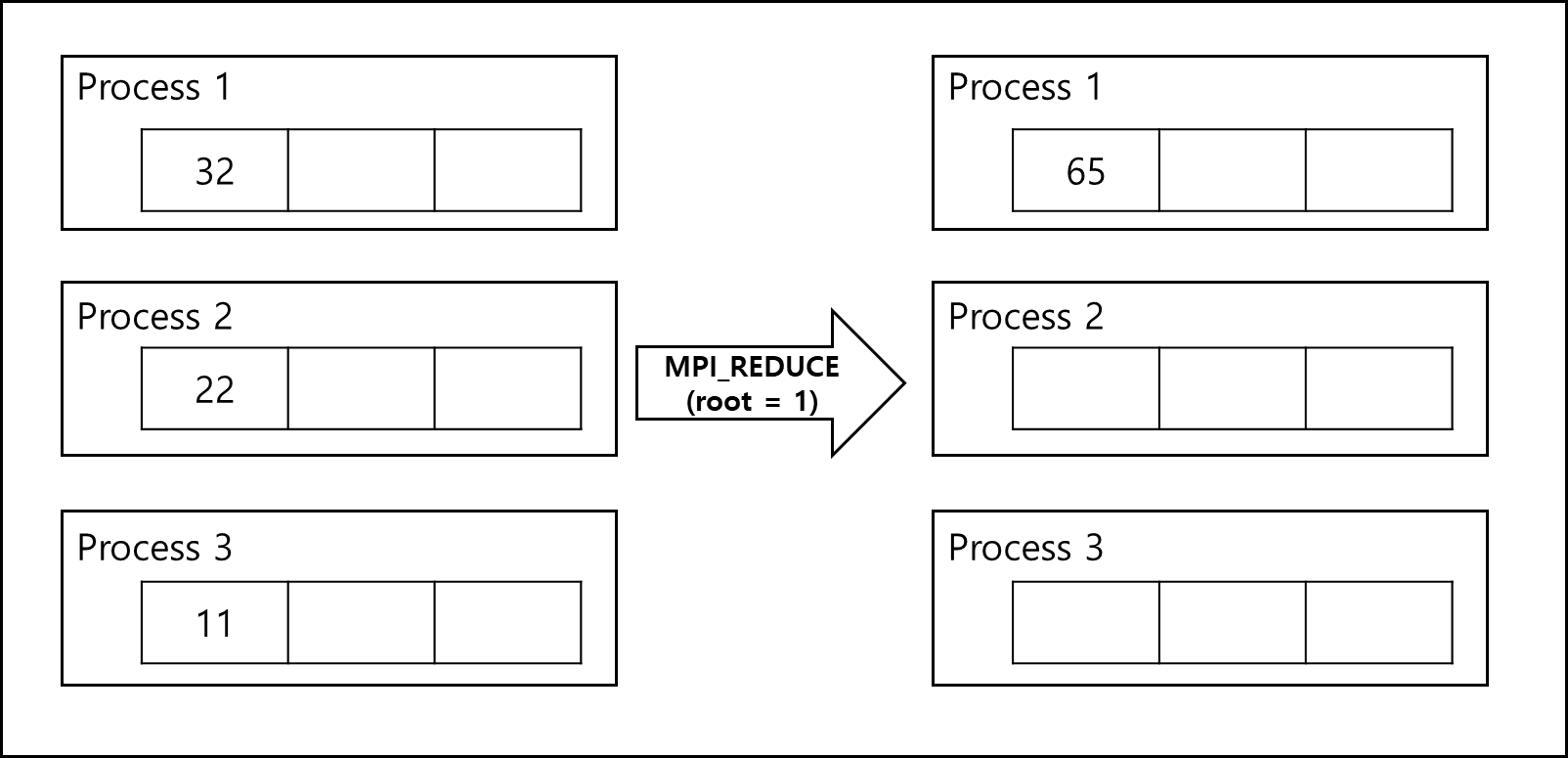
| Operation | 뜻 |
| MPI_MAX | 최대값 |
| MPI_MIN | 최소값 |
| MPI_SUM | 합 |
| MPI_PROD | 곱 |
| MPI_LAND | 논리 AND |
| MPI_BAND | 비트 AND |
| MPI_LOR | 논리 OR |
| MPI_BOR | 비트 OR |
| MPI_LXOR | 논리 XOR |
| MPI_BXOR | 비트 XOR |
| MPI_MAXLOC | 최대값과 위치 |
| MPI_MINLOC | 최소값과 위치 |
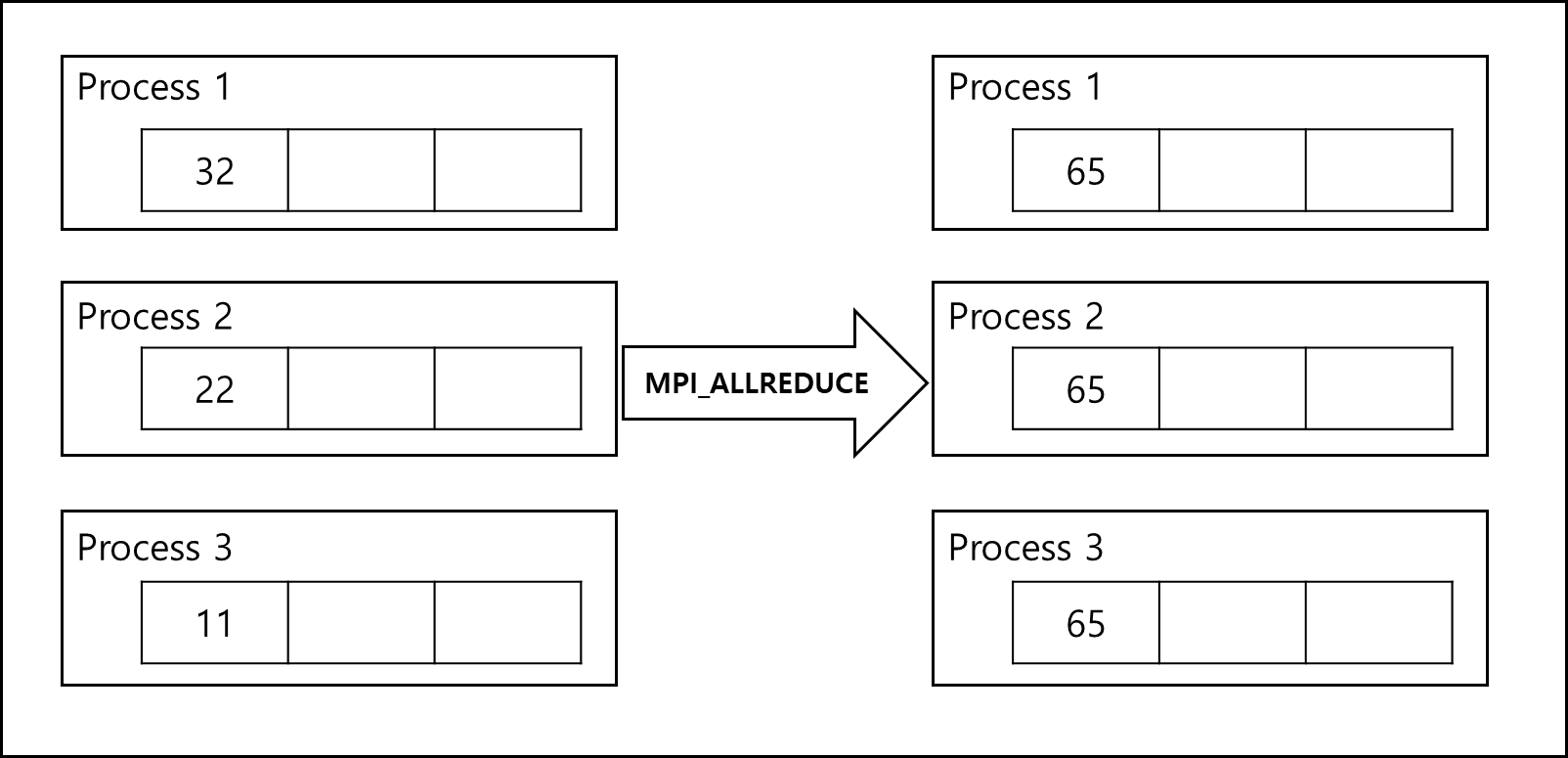
만약 모든 프로세스에 연산 결과를 저장하고 싶다면 MPI_ALLREDUCE 함수를 사용하면 된다.
1
2
int MPI_Allreduce(const void *inbuf, void *outbuf, int cnt,
MPI_Datatype type, MPI_Op op, MPI_Comm comm)
root가 없는 것외에는 함수 명세는 동일하며 연산 결과는 모든 프로세스에 저장된다.
4) MPI Collective의 통신 구현
a. Broadcast의 구현
Broadcast는 기본적으로 Tree Structured Communication 구조를 따른다.
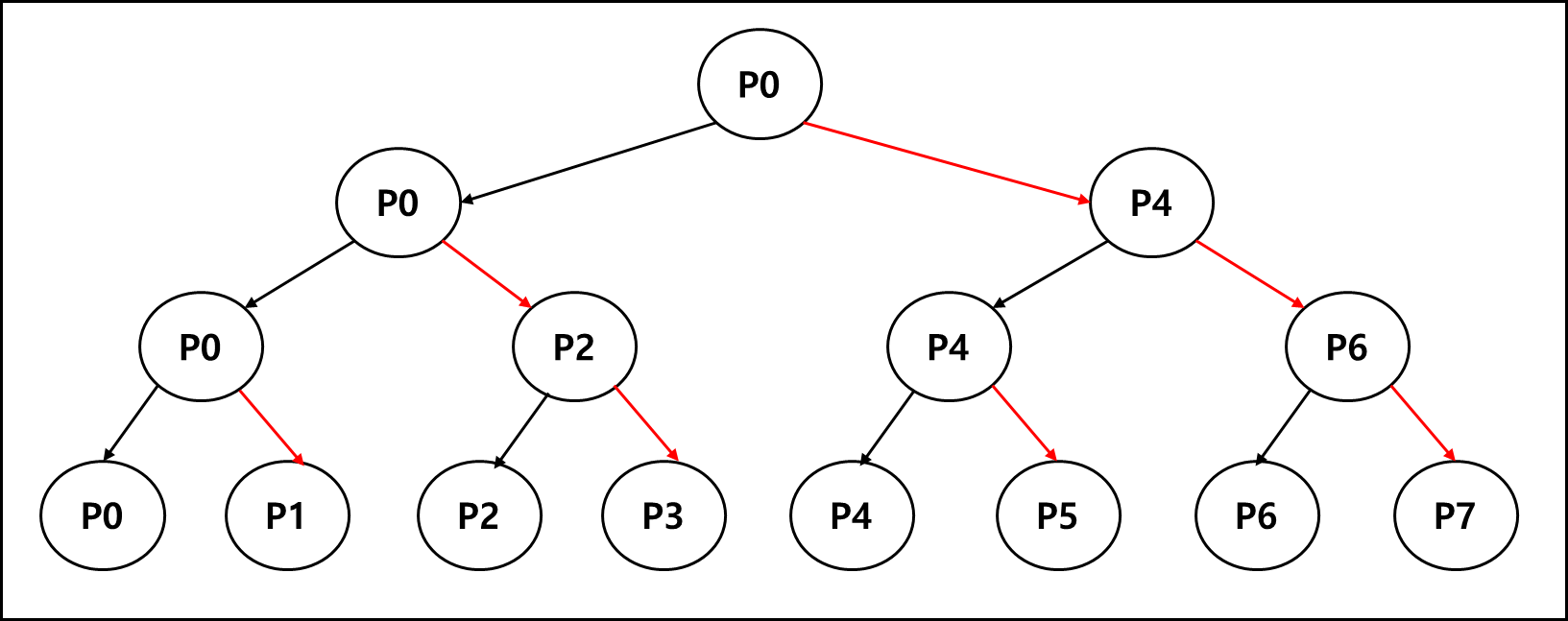
만약에 p개의 프로세스가 있다면 전체로 Broadcast되는데 $log_{2}P$ 스테이지가 필요하다.
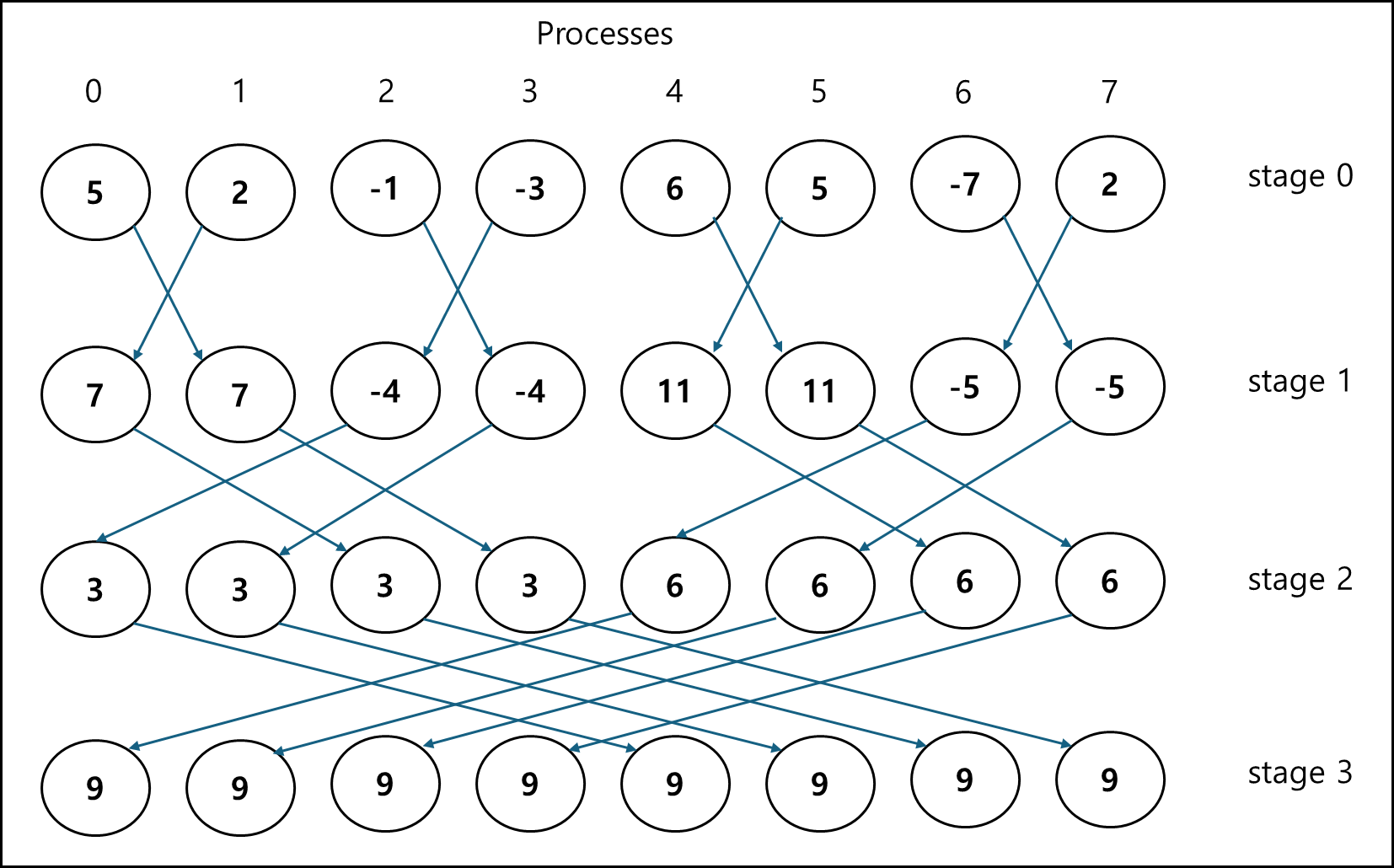
b. Reduction의 구현
한 개의 프로세스에만 연산 결과가 저장되는 것이 아닌 전체 프로세스에 저장 결과가 저장되는 Reduction의 경우 Butterfly structured global sum 구조이다.
5) Scatter와 Gather, Broadcast의 종류
위에서 언급한 방식은 기본적인 Scatter와 Gather의 방식이다.
동일한 크기의 데이터를 나머지 프로세스들에게 1개씩 전달하거나 받는 방식이었다면 크기를 지정해서 잘라주거나 혹은 전체가 전체에게 지정된 크기 만큼 주거나 받는 것도 가능하다.
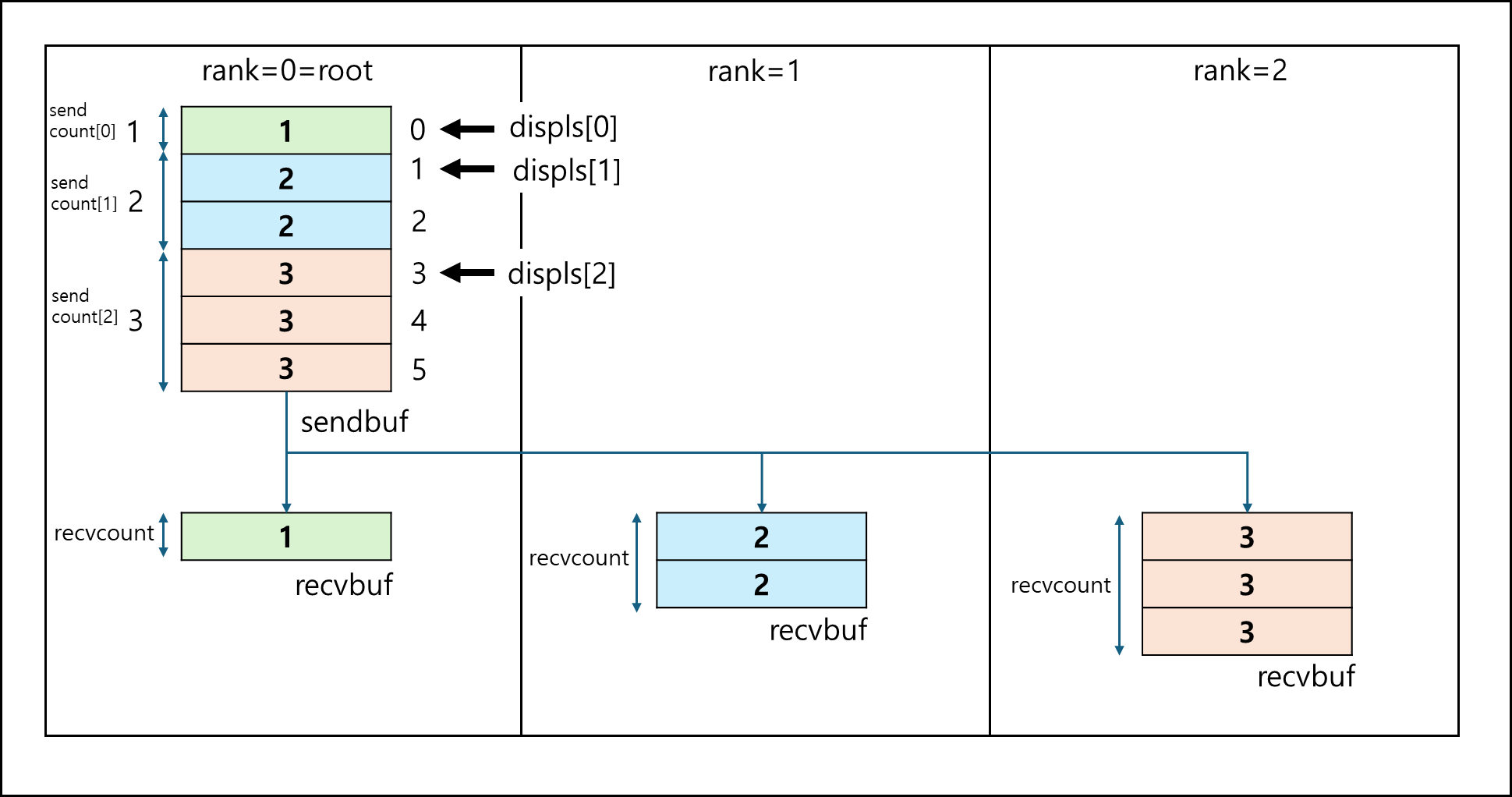
a. MPI_Scatterv
기본적인 Scatter 함수와 모두 동일한 크기로 잘라서 뿌리는게 아닌, array로 각 프로세스에 몇 개씩 잘라서 뿌릴지 정할 수 있다.
1
2
int MPI_Scatterv(const void *sndbuf, int *sndncnt,int *displs, MPI_Datatype sndtype,
void *recvbuf, int recvcnt, MPI_Datatype recvtype, int root, MPI_Comm comm)
다른 인자는 다 동일하나 *sendcnts, *displs가 다르다.
- *sendcnts : 각 프로세스에 보낼 데이터의 count 배열이다.
- *displs : 보내는 데이터 버퍼의 어디에 위치할지 정하는 인덱스 배열이다.
만약 *sendcnts = [1,2,3], *displs = [0,1,3] 이라면 아래의 그림과 같이 분배된다.
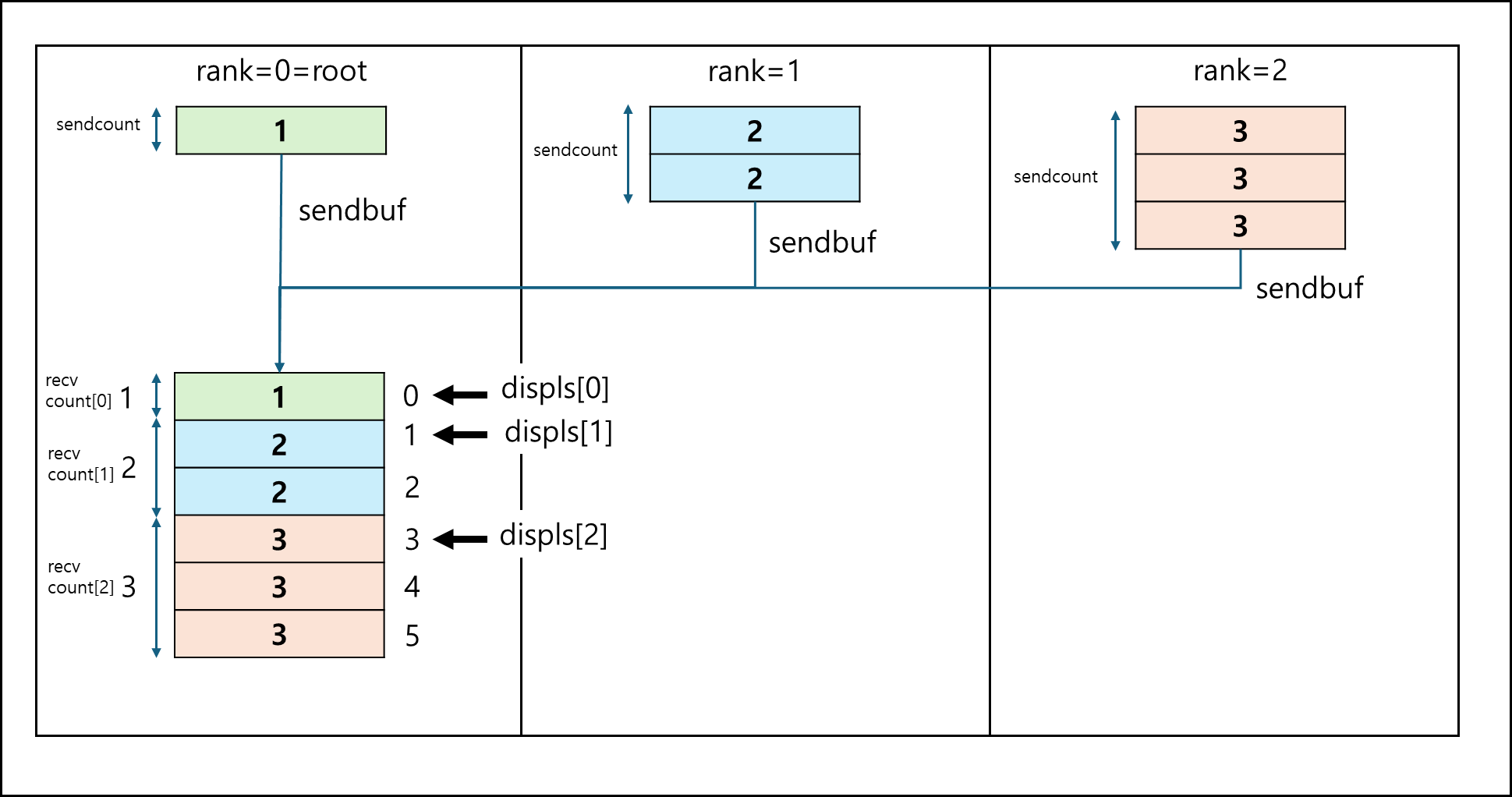
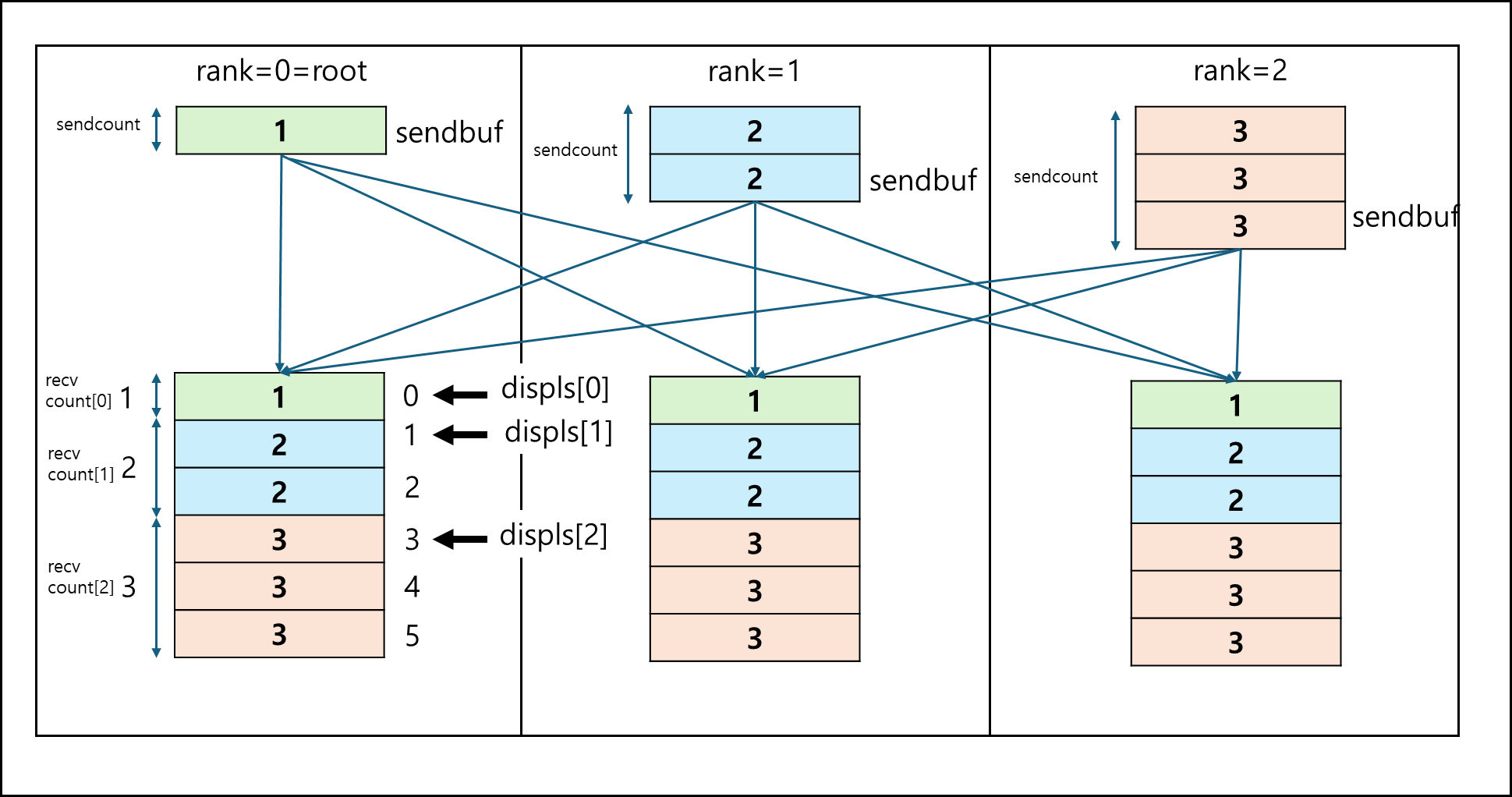
b. MPI_Gatherv
기본적인 Gather 함수와 동일하지만 1개씩 받는게 아닌, array로 각 프로세스에서 몇 개씩 받을지 정할 수 있다.
1
2
3
int MPI_Gatherv(const void *sndbuf, int sndncnt, MPI_Datatype sndtype,
void *recvbuf, int *recvcnts,int *displs, MPI_Datatype recvtype, int root,
MPI_Comm comm)
다른 인자는 다 동일하나 *recvcnts, *displs가 다르다.
- *recvcnts : 각 프로세스에서 받을 데이터의 count 배열이다.
- *displs : 받는 데이터 버퍼의 어디에 위치할지 정하는 인덱스 배열이다.
만약 *recvcnts = [1,2,3], *displs = [0,1,3] 이라면 아래의 그림과 같이 분배된다.
c. MPI_Alltoall
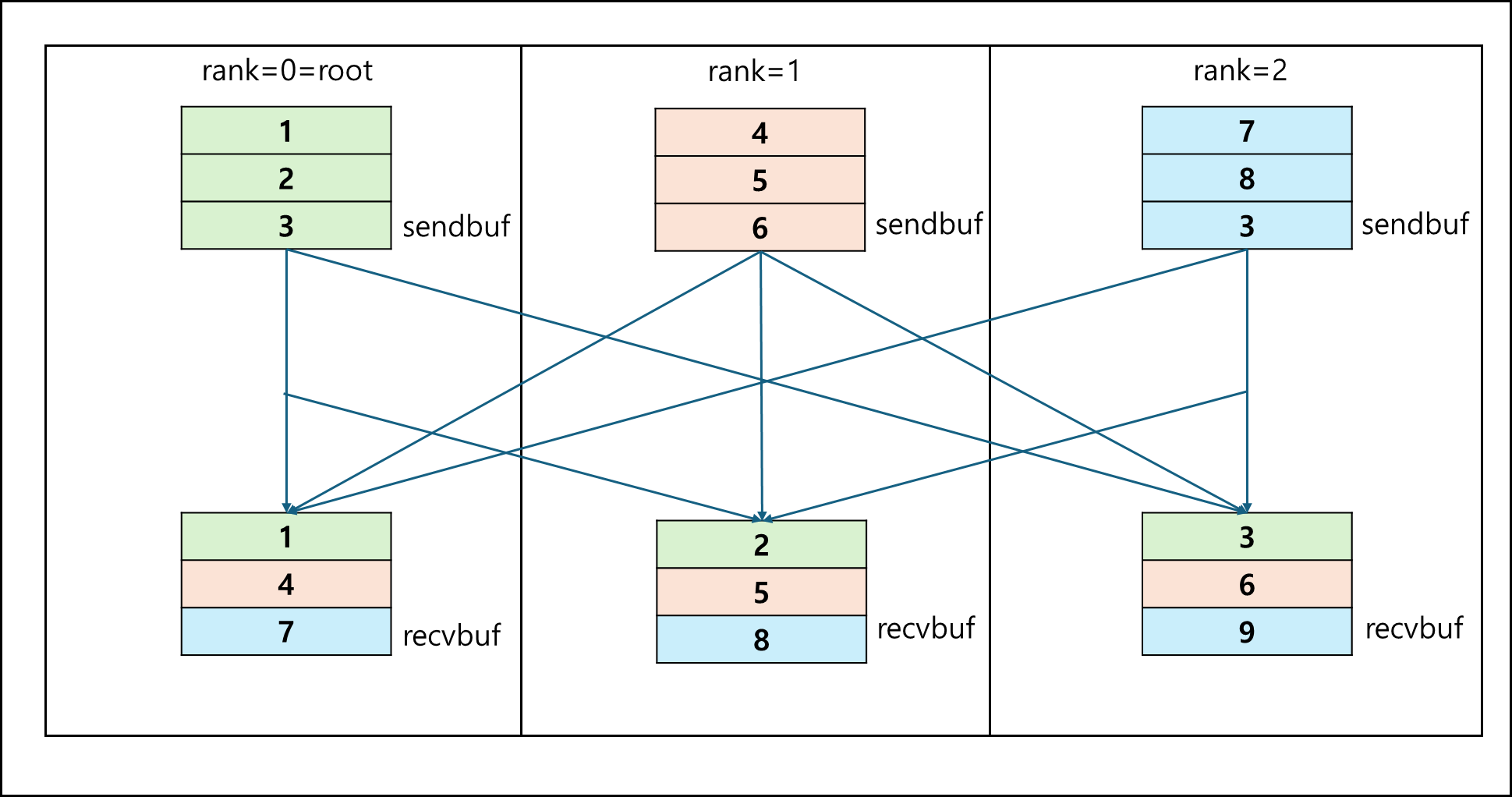
Broadcast 함수가 프로세스 한개가 나머지 프로세스들에게 모두 뿌리는 함수라면 MPI_Alltoall은 모든 프로세스가 모든 프로세스에게 동일한 크기의 데이터를 뿌리는 함수이다.
1
2
int MPI_Alltoall(const void *sndbuf, int sndncnt, MPI_Datatype sndtype,
void *recvbuf, int recvcnt, MPI_Datatype recvtype, int root, MPI_Comm comm)
인자의 사용방식은 다른 함수들과 같으며
만약 sendcnts = 1 이라면 아래의 그림과 같이 분배된다.
d. MPI_Alltoallv
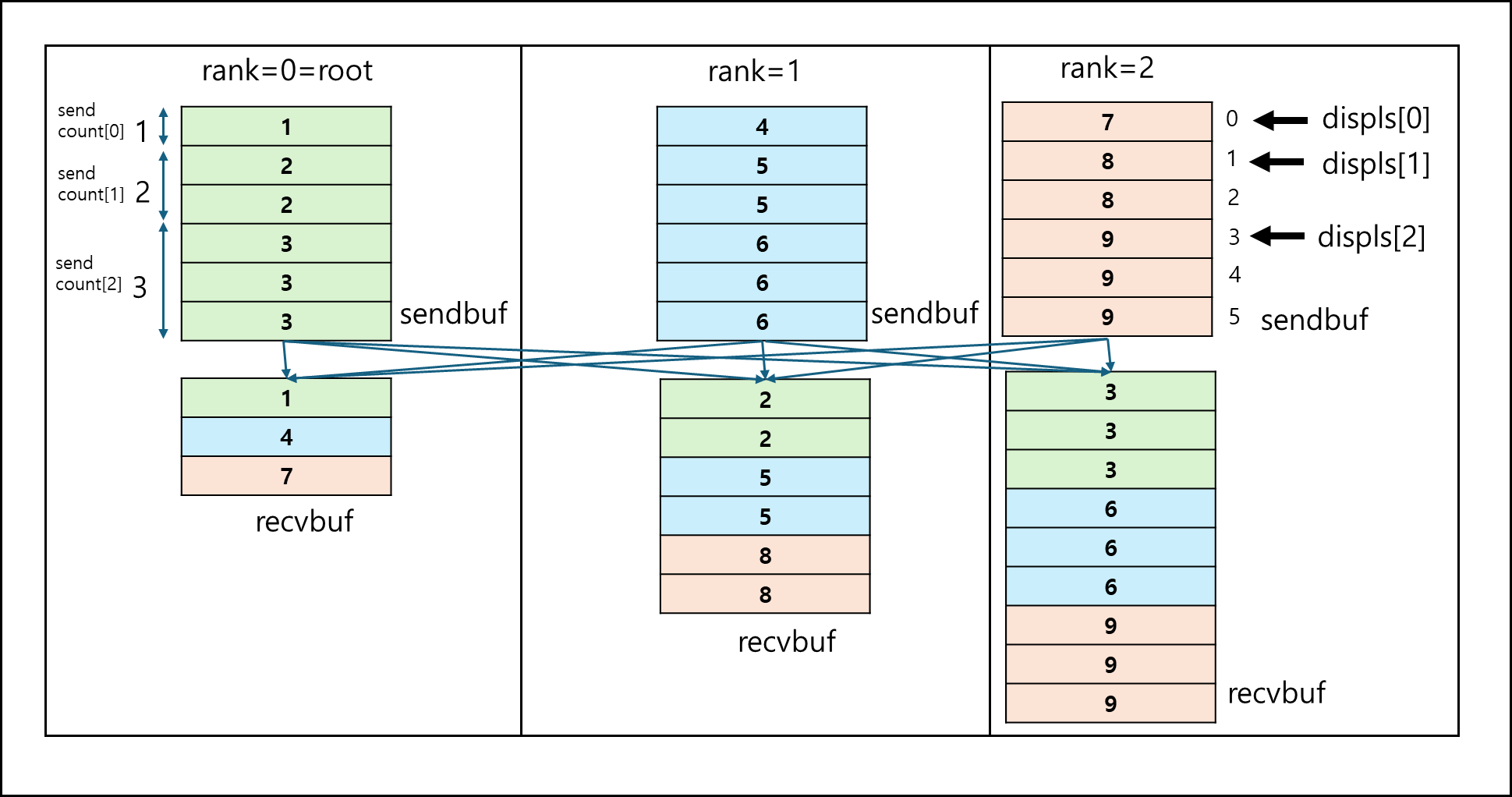
Broadcast 함수가 프로세스 한개가 나머지 프로세스들에게 모두 뿌리는 함수라면 MPI_Alltoall은 모든 프로세스가 모든 프로세스에게 다른 크기의 데이터를 뿌리는 함수이다.
1
2
int MPI_Alltoallv(const void *sndbuf, int *sndncnt, int *sdispls, MPI_Datatype sndtype,
void *recvbuf, int recvcnt, int *rdispls, MPI_Datatype recvtype, int root, MPI_Comm comm)
다른 것들은 알고 있을거라 생각하며 sdispls와 rdispls만 살펴보겠다.
- *sdispls : 보낼 데이터 버퍼의 보낼 데이터 Index
- *rdispls : 받을 데이터 버퍼의 데이터 받을 Index
만약 *sendcnts = [1,2,3], *sdispls = [0,1,3], *recvcnts = [1,2,3]이고 프로세스는 총 3개이며, 프로세스 0,1,2일때 *rdispls가 순서대로 [0,1,2],[0,2,4],[0,3,6]일때 아래의 그림과 같이 분배된다.
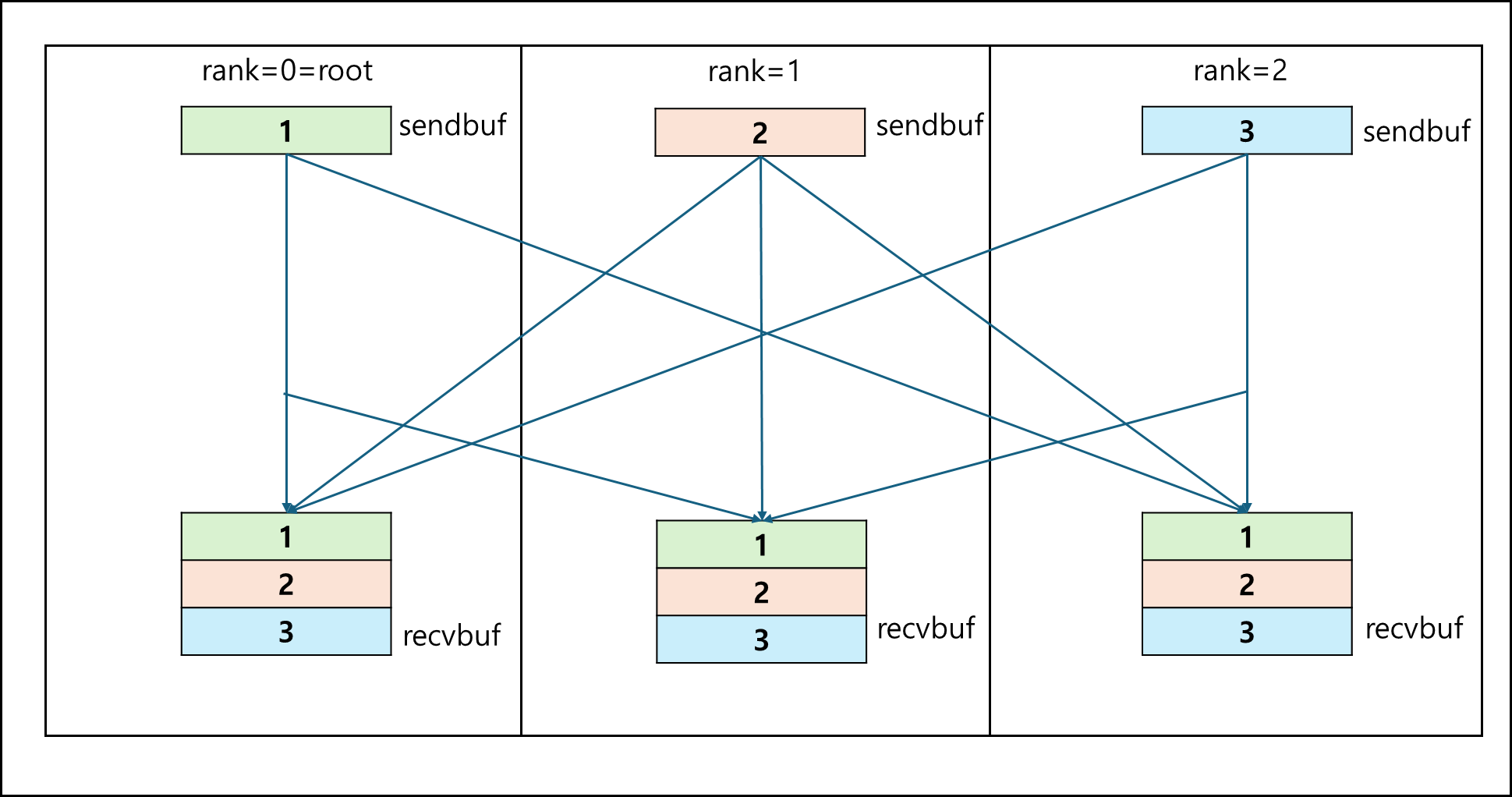
e. MPI_Allgather
모든 프로세스에서 동일한 크기만큼 데이터를 복사해서 모든 프로세스에 받아오는 함수이다.
1
2
int MPI_Allgather(const void *sndbuf, int sndncnt, MPI_Datatype sndtype,
void *recvbuf, int recvcnt, MPI_Datatype recvtype, int root, MPI_Comm comm)
만약 sendcnts가 1이고 프로세스가 3이면 아래와 같다.
f. MPI_Allgatherv
모든 프로세스에서 각기 다른 크기만큼 데이터를 복사해서 모든 프로세스에 받아오는 함수이다.
1
2
int MPI_Allgatherv(const void *sndbuf, int sndncnt, MPI_Datatype sndtype,
void *recvbuf, int *recvcnt, int *displs, MPI_Datatype recvtype, int root, MPI_Comm comm)
만약 *recvcnts = [1,2,3], *displs = [0,1,3] 이라면 아래의 그림과 같이 분배된다.
8. MPI Derived datatypes
기본적으로 MPI에서는 별도의 자체 기본 데이터 타입을 제공한다.
| MPI DATA TYPE | C DATA TYPE |
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
C 계통 언어에서 구조체 지원을 하듯, MPI에서도 Basic type을 조합해서 만든 Derived datatype을 지원한다.
하지만 이쯤되서 드는 의문이 있다. 그냥 어차피 C 언어계통에서 쓰는 데이터 타입을 그대로 쓰면 되는거 아닌가라는 의문이다.
굳이 MPI에서 이런 파생 타입을 지원해줄 필요가 있을까? 그럴 필요가 있다.
1) Derived data type이 있어야하는 이유
a. 현실 세계에서 데이터가 단순히 인접한 블록형태로 존재하는 경우가 드물기에 처리할 수 있어야한다.
비연속적 데이터 처리
실제 데이터는 메모리에 연속적으로 존재하지 않는 경우가 많다. ex) 2D 행렬에서 특정 서브 블록만 추출하거나 열(column) 단위로 데이터를 보낼 때
때문에 이를 연속적으로 보낼 수 있게 작업해주어야한다.혼합 데이터 타입 전송
정수형 헤더와 실수형 데이터가 섞인 구조체(struct)와 같이 서로 다른 타입들은 패딩을 포함할 수 있다.
이러한 패딩까지 감안해서 보낼 수 있게 처리해주어야한다.
b. 데이터 전송시 숨겨진 비용이 있다.
높은 cpu 오버헤드
메모리에서 메모리 복사시 cpu 사이클 낭비가 있다.메모리 대역폭 경합
메모리 버스의 압력이 높아진다(read + write)지연시간이 증가함
실제 데이터를 네트워크로 전송하기 전에 보낼 데이터에 대해서 packing하는 것은 지연시간을 증가시킨다.
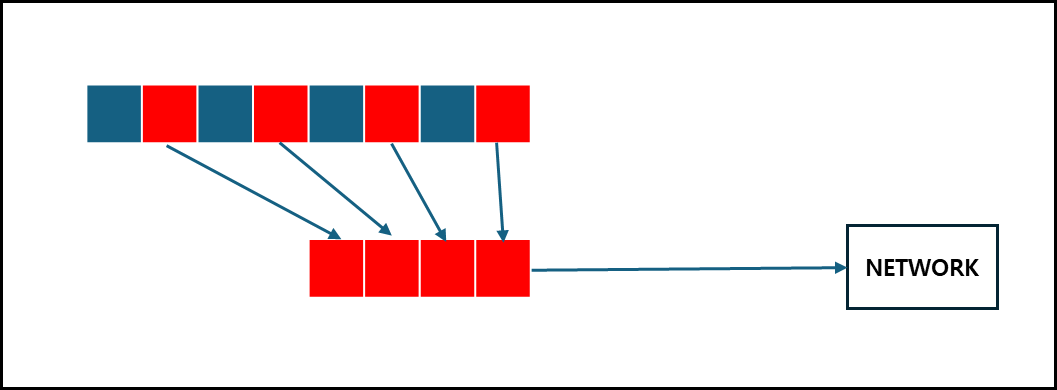
c. 다른 환경에서의 이식성을 보장해주어야한다.
다른 환경에서는 흔히들 사용하는 데이터 타입의 크기가 다를 수 있으며, 메모리에 적재되는 방식 역시 다르다.
- Datatypes
아래는 운영체제 종류에 따른 타입들 용량이다.
| Data type / OS type | 32bits (Win32,Unix,Linux,Mac) | 64bits(Win64) | 64bits(Unix, Linux, Mac) |
| char | 8bits(1byte) | 8bits(1byte) | 8bits(1byte) |
| short | 16bits(2bytes) | 16bits(2bytes) | 16bits(2bytes) |
| int | 32bits(4bytes) | 32bits(4bytes) | 32bits(4bytes) |
| long | 32bits(4bytes) | 32bits(4bytes) | 64bits(8bytes) |
| pointer | 32bits(4bytes) | 64bits(8bytes) | 64bits(8bytes) |
| float | 32bits(4bytes) | 32bits(4bytes) | 32bits(4bytes) |
| double | 64bits(8bytes) | 64bits(8bytes) | 64bits(8bytes) |
long과 pointer의 경우 크기가 모두 다른 것을 확인할 수 있다. 이러한 차이를 제대로 처리해주지 않으면 다른 시스템에서
제대로 된 작동을 보장 할 수 없다.
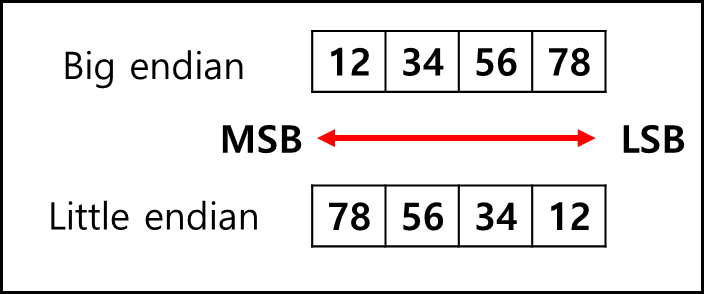
- Big endian vs Little endian
여러 바이트로 이루어진 값을 메모리나 전송 구간에 어떤 순서로 배치하느냐를 뜻하는 바이트 순서(byte order) 개념을 엔디안이라고 하는데
걸리버 여행기에서 유래된 단어이다. 메모리에 적재되는 순서의 경우에는 CPU 아키텍처에 따라 달라지면 Intel 류는 주로 little endain으로 적재되며 네트워크 전송은 주로 Big endian으로 이루어진다.
만약 HEX값으로 0x12345678이라고 했을 때 각각의 경우에 대해서 메모리에 적재되는 형태는 아래와 같다.
2) Derived data type을 지원하는 함수
위와 같은 이유로 아예 MPI에서 제공하는 함수가 있는데 이 함수를 사용하면 MPI 라이브러리는 이를 가지고 TYPE MAP을 만들어준다.
이 함수는 MPI Datatype constructor 라고 불리며 아래와 같은 종류가 있다.
a. Structured (Regular)
정해진 패턴이나 고정된 사이즈에서 각 원소들을 가져오는 경우 사용하는 함수들이다.
ⓐ MPI_Type_contiguous
사용하는 방식은 아래와 같다.
1
MPI_Type_contiguous(int count, MPI_Datatype oldtype, MPI_Datatype *newtype);
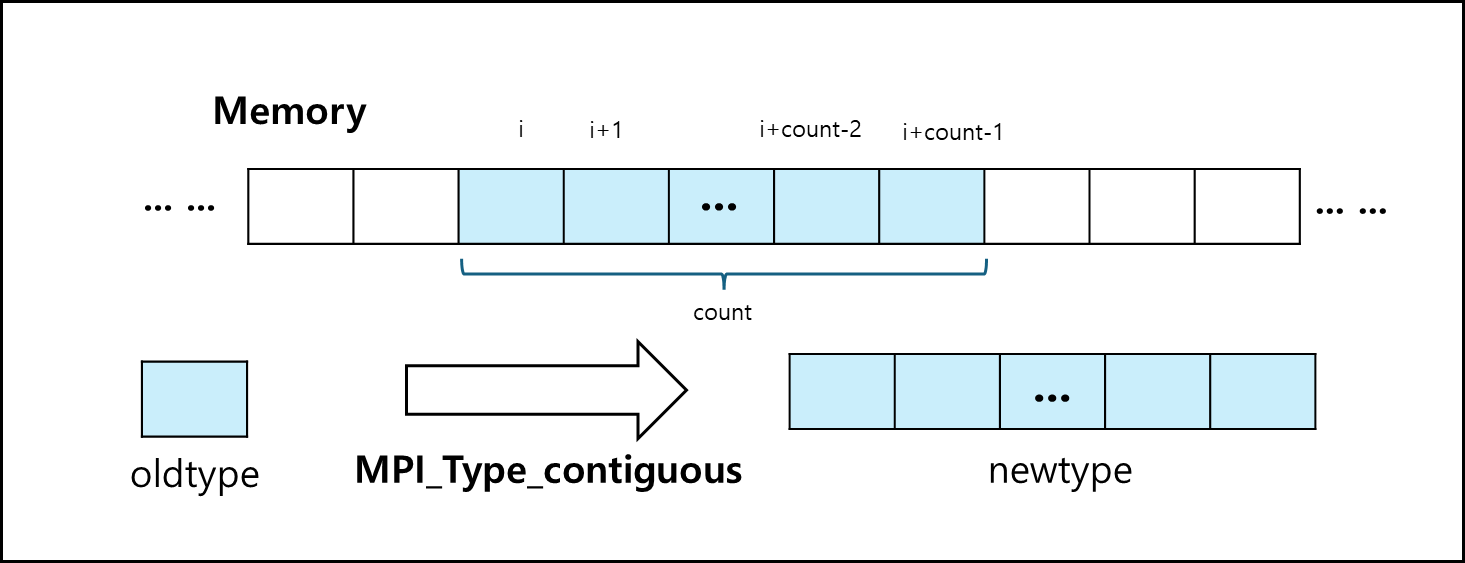
- count : oldtype에 대한 개수이다.
- oldtype : 원래 데이터의 type이다.
- newtype : 새로 만들어진 datatype에 대한 변수이다.
ⓑ MPI_Type_vector
사용하는 방식은 아래와 같다.
1
MPI_Type_vector(int count,int blocklength,int stride, MPI_Datatype oldtype, MPI_Datatype *newtype);
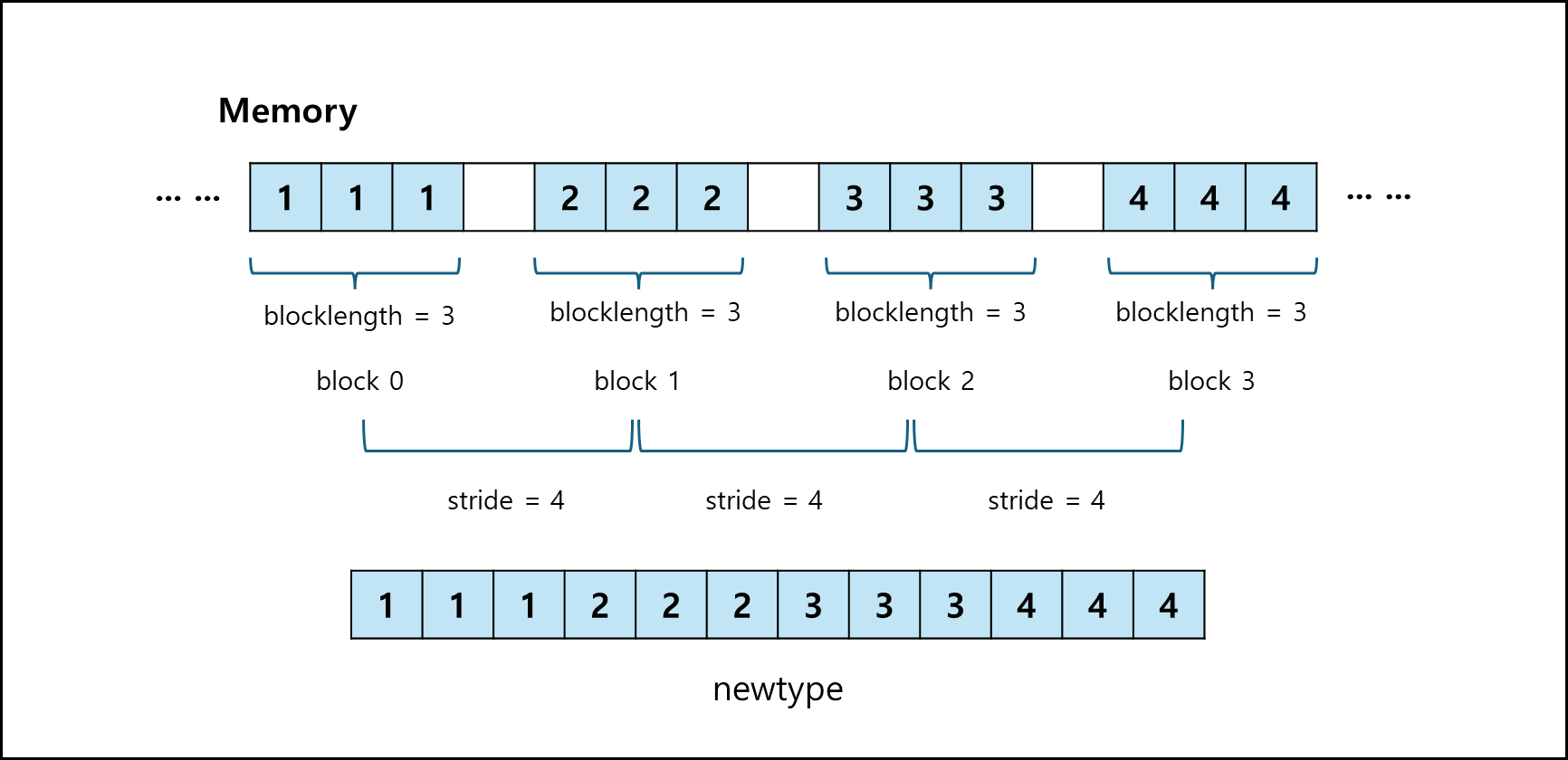
- count : block의 개수가 몇 개인지? 위 예시의 경우 4
- blocklength : 각 block의 길이가 어느정도인지? 위 예시의 경우 3
- stride : 각 블록의 시작점이 얼마나 떨어져있는지? 위 예시의 경우 4
- oldtype : 원래 데이터의 type이다.
- newtype : 새로 만들어진 datatype에 대한 변수이다.
b. Unstructured (Irregular)
타입이 섞였거나 임의의 offset에서 각 원소들을 가져올 경우 사용하는 함수이다. C언어에서 이야기하는 구조체 같이 복잡한 타입을 보낼때 사용한다.
ⓐ MPI_Type_create_struct
사용하는 방식은 아래와 같다.
1
MPI_Type_create_struct(int count,int blocklength[],MPI_Aint displacements[], MPI_Datatype type[], MPI_Datatype *newtype);
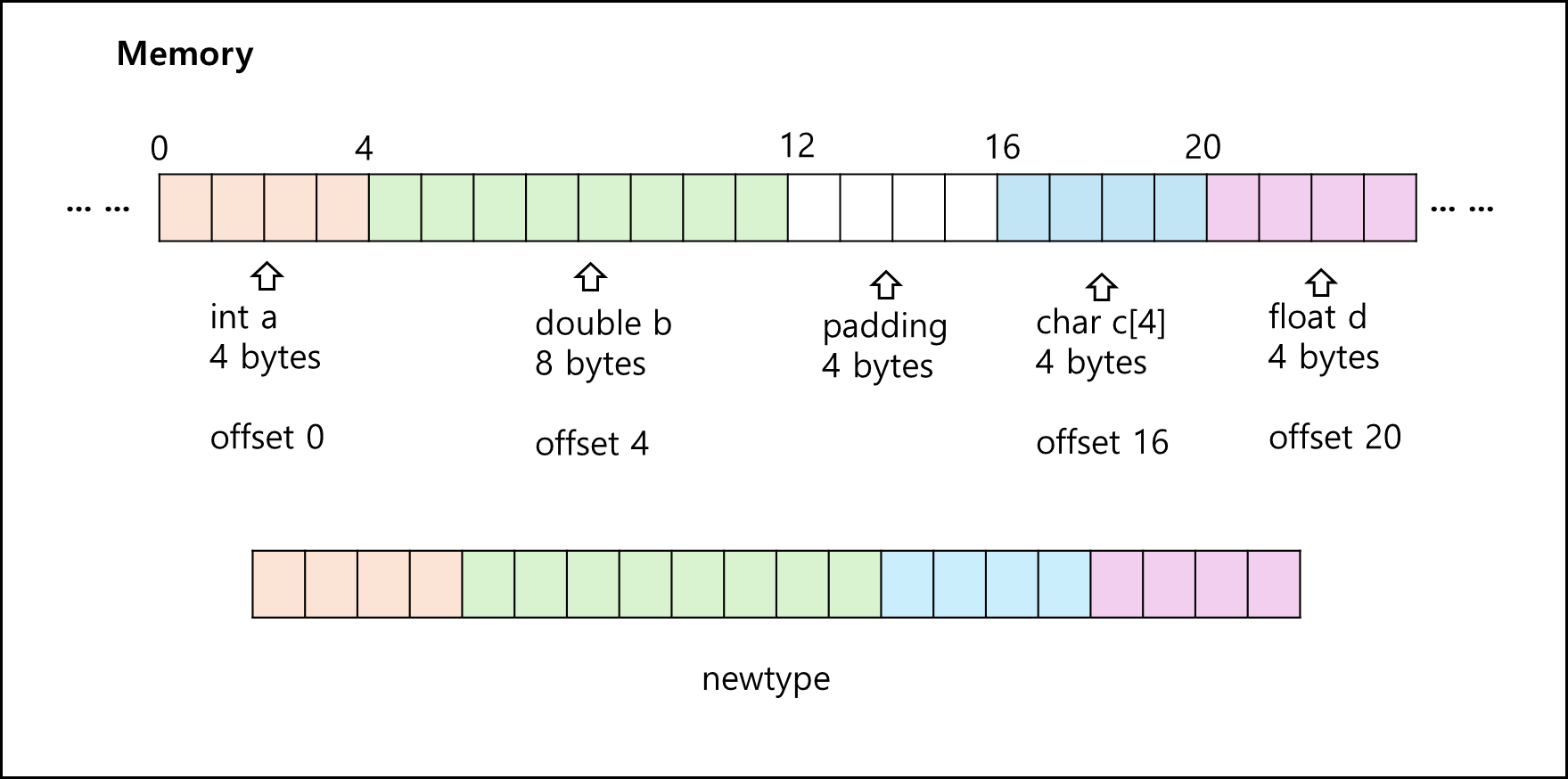
- count : 총 block의 개수이다. 위의 예시의 경우에는 int a, double b, char c[4], float d니까 4이다.
- blocklength[] : 각 block의 길이이다. 위 예시를 볼때 c의 경우 크기 4의 char 배열이므로 4이고 나머지는 1이니까. [1,1,4,1] 이다.
- displacements[] : 각 block의 시작 위치이다. 위 예시를 볼때 각 block의 시작 offset을 기재하면 [0,4,16,20]이다.
- type[] : 각 block의 type이다. MPI에서 제공하는 타입으로 기재해야하며 위 예시를 볼때 [MPI_INT, MPI_DOUBLE,MPI_CHAR,MPI_FLOAT] 이다.
- newtype : 새로 만들어진 datatype에 대한 변수이다.
※ 각 offset을 구하는 방법
그냥 C에서 구하듯이 sizeof로 구해버리면 위에서 언급했듯이 다른 OS나 아키텍처의 경우 달라질 수 있기 때문에 unsafe하며, 구조체 역시 정의한 순서대로 컴파일러가 컴파일하지 않고 순서를 바꿀수 있다. 따라서 아래의 함수를 써야한다.
- MPI_Get_address 아래의 명세를 따르는 함수이다.
1
int MPI_Get_address(const void* location, MPI_Aint* address)
구조체의 각 데이터 타입이 어디 offset인지 구하는 함수이다. 아래와 같이 사용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
struct Pixel{
int x;
int y;
unsigned char RGB[3];
}
// 그외 코드
struct Pixel sample;
// 그외 코드
MPI_Aint displ[3], off, base; //각 구조체 원소의 시작점을 구해야함
displ[0] = 0;
MPI_Get_address &(Sample.x), &base); // x는 무조건 앞에서 시작
MPI_Get_address &(Sample.y), &off); // off로 y 위치를 구함
displ[1] = off - base; // off에서 base를 빼서 두번째 원소의 상대적 위치를 기재
MPI_Get_address &(Sample.RGB[0]), &off);
displ[2] = off - base; // off에서 base를 빼서 세번째 원소의 상대적 위치를 기재
// 그외 코드
ⓑ MPI_Type_indexed
아래의 명세를 따르는 함수이다.
1
2
3
int MPI_Type_indexed(int count, const int array_of_blocklengths[],
const int array_of_displacements[], MPI_Datatype oldtype,
MPI_Datatype *newtype)
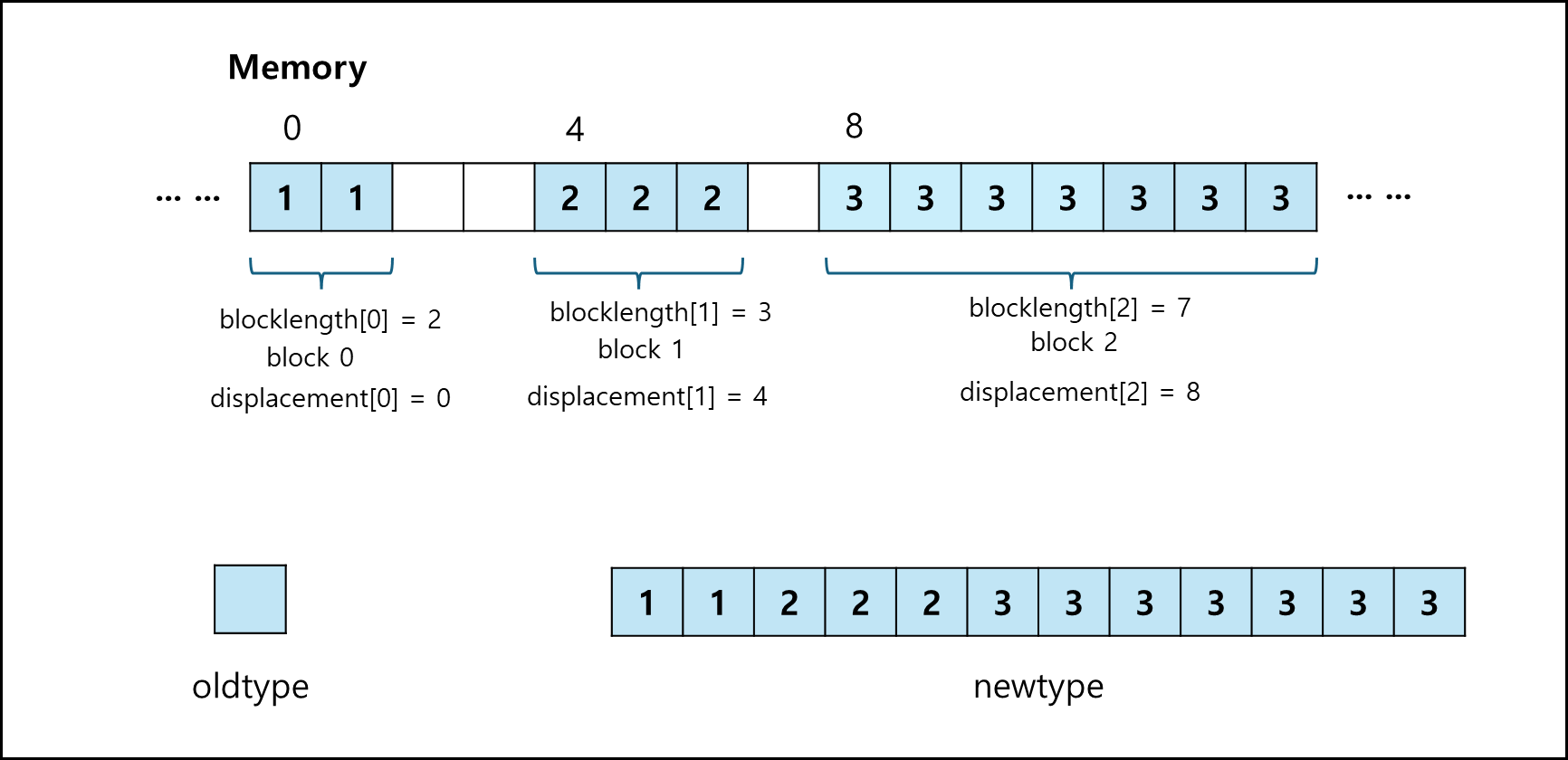
- count : 총 block의 개수이다. 위의 예시의 경우에는 총 3이다.
- blocklength[] : 각 block의 길이이다. 위 예시를 볼때 [2,3,7] 이다.
- displacements[] : 각 block의 시작 위치이다. 다만 MPI_Type_create_struct 함수는 바이트 offset인 반면, MPI_Type_indexed 함수는 배열로 쳤을 때 몇번째냐를 적어야한다. 위 예시를 볼때 각 block의 시작 index를 기재하면 [0,4,8]이다.
- oldtype : 각 block의 oldtype이다. MPI에서 제공하는 타입으로 기재해야하며 MPI_Type_create_struct 함수와는 다르게 모두 동일한 타입이어야한다.
- newtype : 새로 만들어진 datatype에 대한 변수이다.
ⓒ MPI_Pack & MPI_Unpack
ㄱ. MPI_Pack
어떤 구조체를 Packing해서 보낼 수 있는 타입으로 바꾸는 함수이다.
1
int MPI_Pack(void *inbuf, int incount, MPI_Datatype datatype, void *outbuf, int outcount, int *position, MPI_Comm comm);
- *inbuf : 바이트 배열에 저장할 데이터의 주소
- incount : 바이트 배열에 저장될 데이터의 개수
- datatype : inbuf의 데이터 타입
- *outbuf : 바이트 배열의 주소
- outcount : outbuf의 바이트 크기
- *position : outbuf에서 첫 번째 사용 가능한 여유 공간의 위치
- comm : 커뮤니케이터 핸들러이다. 그룹에 대한 context이며 모든 프로세스는 기본적으로 MPI_COMM_WORLD에 포함되어있다.
ㄴ. MPI_Unpacking
받은 데이터를 구조체로 파싱하여 사용할 수 있는 함수이다.
1
int MPI_Unpack(void *inbuf, int insize,int *position,void *outbuf, int outcount, MPI_Datatype datatype, MPI_Comm comm);
- *inbuf :바이트 배열에 읽어올 데이터의 주소
- insize : inbuf의 바이트 크기
- *position : inbuf에서 읽어올 주소.
- *outbuf : unpack된 데이터가 들어갈 버퍼 주소
- outcount : unpack할 아이템의 개수
- datatype : oubuf의 데이터 타입
- comm : 커뮤니케이터 핸들러이다. 그룹에 대한 context이며 모든 프로세스는 기본적으로 MPI_COMM_WORLD에 포함되어있다.
ㄷ. 예시
그냥 설명만 들으면 이해하기 어려우니 예시를 들어서 설명하도록 하겠다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 대상 구조체
struct Pixel {
int x;
int y;
unsigned char RGB[3];
}
unsigned char *buffer = new unsigned char[100];
if (rank == 0)// 전송
{
//...
struct Pixel test;
int position = 0;
MPI_Pack(&(test.x), 1, MPI_INT, buffer, 100, &position, MPI_COMM_WORLD);
MPI_Pack(&(test.y), 1, MPI_INT, buffer, 100, &position, MPI_COMM_WORLD);
MPI_Pack(test.RGB, 3, MPI_UNSIGNED_CHAR, buffer, 100, &position, MPI_COMM_WORLD);
MPI_Send(buffer,position, MPI_UNSIGNED_CHAR,1,0, MPI_COMM_WORLD);
//...
}
else {// 수신
//...
struct Pixel test;
int position = 0;
MPI_RECV (buffer, 100, MPI_UNSIGNED_CHAR, 0,0,MPI_COMM_WORLD, &status);
MPI_Unpack(buffer, 100, &position, &(test.x), 1, MPI_INT, MPI_COMM_WORLD);
MPI_Unpack(buffer, 100, &position, &(test.y), 1, MPI_INT, MPI_COMM_WORLD);
MPI_Unpack(buffer, 100, &position, test.RGB, 3, MPI_UNSIGNED_CHAR, MPI_COMM_WORLD);
//...
}
Sender에서 Pixel 구조체로 만들어진 test 변수의 x,y,RGB를 Packing해서 바이트 배열로 보내고
Receiver에서 Pixel 구조체로 test 변수를 선언하여 받은 바이트 배열을 해당 변수의 x,y,RGB에 각각 파싱하여 넣는 구조이다.
※ Derived Datatypes vs Pack/Unpack
Derived Datatypes을 만드는 것과 Pack/Unpack의 차이는 아래와 같다.
- Pack/Unpack 구조가 코딩하기 쉽다.
- Pack/Unpack는 데이터 복사 오버헤드가 있다.
- Derived Datatypes은 복잡한 데이터 타입을 정의하는데 좀 더 유연하다.
- Derived Datatypes 이미 만들어진 데이터 타입을 재 사용할 때 용이하다.
※ 새로운 데이터 타입 완료 처리 함수
ⓐ MPI_Type_commit
새로 만들어진 데이터 타입을 확정짓는 함수이다. 해당 함수를 호출하지 않으며 MPI가 해당 데이터 타입에 대한 메타데이터를 읽어올 수 없다.
1
int MPI_Type_commit(MPI_Datatype *newtype);
ⓑ MPI_Type_free
새로 만들어진 데이터 타입을 없애서 메모리 누수를 막는 함수이다.
1
int MPI_Type_free(MPI_Datatype *newtype);
2) Derived data type을 전송하는 방식
Derived data type을 이용하여 전송할때는 아래와 같은 절차를 거친다.
- Type map을 빌드한다. (MPI Datatype constructor)
- 데이터 타입을 commit하고 send 한다.
여기까지는 사용자가 할 일이고, 그 다음부터는 MPI 라이브러리가 알아서 처리하는 부분이다.
Gather (Sender)
typemap을 이용해서 메모리에서 데이터를 복사해서 packing해서 바이트 배열로 만든다.타입 변환
다른 이종 노드를 고려해서 Endian 변환이나 Padding, align을 맞춰서 보내준다.Scatter (Receiver)
받은 바이트 배열을 unpack해서 typemap에 따라 다시 메모리에 적절하게 복사한다.
메모리에서 각각의 데이터를 가져와서 Packing 후 보내는 방식은 아래의 세가지가 있다.
a. Legacy CPU Packing
각각 대상 블록 메모리 위치에서 복사하여 Pack buffer에 기재한 뒤에 Pack buffer에서 Socket Buffer로 복사하는 방식이다. 대상 블록 메모리에서 복사하는 경우 CPU가 SIMD 명령어(e.g., AVX-512) 하면 한번에 처리되기도 한다. 만약에 Pack buffer로 한번에 복사가 된다면, Socket buffer로 복사 하는 1번을 더해서 메모리 복사는 2번 일어난다.
b. OS Vectorized I/O (writev)
POSICS API 중에 writev라는 함수로 구현된 방식으로 각각 대상 블록 메모리 위치와 크기를 배열로 넘기면 해당 Memory에서 Kernel이 바이트레벨로 직접 Socket buffer로 복사하는 방식이다.
이 경우 Pack buffer에 복사하지 않고 바로 socket buffer에 복사하기 때문에 메모리 복사는 한번이다.
이렇게 들으면 Legacy CPU Packing 보다 더 빠를 것 같지만 배열의 크기가 커지거나 복잡해지면 되려 느려지는 문제가 있다.
c. Modern HCA SGL (Zero-copy)
하드웨어가 사용자 메모리 공간에서 데이터를 직접 읽어오는 ‘Direct DMA Read’ 방식을 사용한다. 이를 위해서는 각 SGE(Scatter/Gather Element)는 데이터가 저장된 가상 주소(addr), 데이터의 길이(length), 그리고 RDMA 전송을 위해 등록된 메모리를 식별하는 로컬 키(lkey) 정보가 있어야한다.
OS 커널을 우회하고 컨택스트 스위치나 복사가 없다. 때문에 메모리 복사는 0회이다.
물론 위 방식을 사용하려면 하드웨어에서 해당 기능을 지원해주어야한다.
위 세가지 방식 중에 MPI는 런타임에 동적으로 네트워크 상태나 Data layout에 따라 동적으로 정한다.
9. 성능 평가
1) 성능 평가시 사용하는 함수
성능 평가할 때는 일반적으로 시간을 잰다. MPI에서 제공하는 아래의 함수를 사용할 수 있다.
1
2
3
4
5
6
7
8
//...
double start, finish;
double elapsedTime;
start = MPI_Wtime();
// 실행하려는 코드
finish = MPI_Wtime();
elapsedTime = finish - start // 실행 시간 (초)
꼭 MPI에서 제공하는 함수를 쓰지 않아도 된다.
timer.h에 포함된 아래의 함수를 쓸 수도 있다.
1
2
3
4
5
double start,finish,elapsed;
GET_TIME(start);
// 실행 코드
GET_TIME(finish);
elapsed = finish - start; // 실행 시간 (초)
GET_TIME 은 timer.h에 정의된 매크로 함수로 gettimeofday라는 함수를 이용해서 반환하는 값을 이용하여 초로 변환해서 반환해준다.
2) 확장성
- 프로그램의 확장성은 문제 크기를 늘릴 때 프로세스 수가 증가해도 효율성이 떨어지지 않는 비율을 말한다.
- 문제 크기를 늘리지 않고도 일정한 효율성을 유지할 수 있는 프로그램은 확장성이 강하다고 한다. (strongly scalable)
- 문제 크기가 프로세스 수와 같은 비율로 증가할 때에도 일정한 효율성을 유지할 수 있는 프로그램은 확장성이 약하다고 한다. (weakly scalable)
참고자료
- 서강대학교 박성용 교수님 강의자료 - 병렬 분산 컴퓨팅
- Wikipedia - Endianness
원문 참고자료들
- Peter S. Pacheco, An Introduction to Parallel Programming, Elsevier Inc. (Morgan Kaufmann), 2011, ISBN 978-0-12-374260-5
- Gerassimos Barlas, Multicore and GPU Programming – An Integrated Approach, Elsevier Inc. (Morgan Kaufmann), 2015, ISBN 978-0-12-417137-4.
- G. Coulouria, J. Dollimore, T. Kindberg, and G. Blair, Distributed Systems: Concepts and Design, 5 th Edition, Pearson, 2012, ISBN 978-0-273-76059-7
- M. van Steen and A. S. Tanenbaum, Distributed Systems, 3 rd Edition, 2017
- Martin Kleppmann, Designing Data-Intensive Applications, 1 st Edition, O’Reilly Media, 2017, ISBN 978-1491903070 (또는 2nd Edition in February 2026)