MongoDB Index
인덱스 지정
DB의 스키마 구조를 설계하고 DB를 운영하는데 있어서 빠질 수 없는게 바로 인덱스 설정이다. MongoDB라고 해서 이게 크게 다르지 않는데, 이러한 인덱스 설정을 어떤 기준으로 하면 좋고 어떻게 하는지 세부적으로 알아보도록 하겠다.
Index의 구조
기본적으로 MongoDB의 Index는 B-tree를 이용해서 구성된다. 이는 이진트리에서 파생된 자료구조로 자식 노드를 두 개씩만 가질 수 있는 이진트리와는 달리 B-tree는 2개 이상의 자식 노드를 가질 수 있으며 노드 내의 데이터가 1개 이상이다.
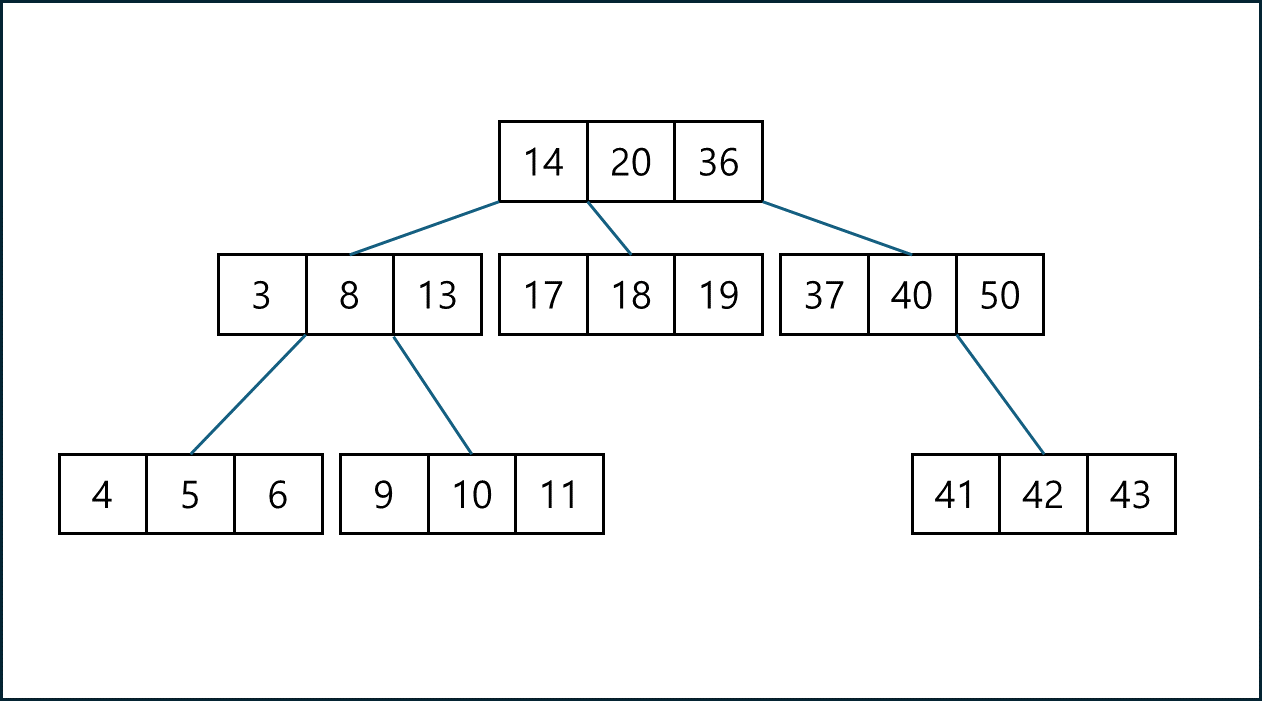
이러한 인덱스가 B-tree로 구성되어있기 때문에 우리는 Index를 두 가지로 지정할 수 있다.
1
2
3
// DB의 inventory collection의 budget 속성에 대해 오름차순과 내림차순 index
db.inventory.createIndex({'budget':1})
db.inventory.createIndex({'budget':-1})
MongoDB에서 지원하는 인덱스 종류
크게 두 개로 나뉜다. 단일 필드 인덱스와 복합 필드 인덱스가 그것인데 index는 기본적으로 한 쿼리에 한 index만 유효하며 두 개의 index 가 필요하다면 복합 index를 사용해야한다.
단일 필드 인덱스 (Single Field Index)
말 그대로 단일 필드에 대해서 인덱스를 거는 것이다. user라는 collection에서 score에 대해 오름차순으로 인덱스를 걸때 방법은 아래와 같다.
1
db.user.createIndex({score:1})
한 개의 속성에 대해서 Index를 걸며 find시 인덱스가 걸려있는 속성을 포함해서 걸어야 성능의 이득을 볼 수 있다.
인덱스 자체에서 오름차순이냐 내림차순이냐를 설정할 수 있지만 단일 필드 인덱스에서는 크게 상관이 없다. 어차피 동일하게 접근하기에 성능은 좋게 나온다.
다중 필드 인덱스 (Multikey Index)
고정된 배열 값에 대해 인덱스를 지정하는 방식을 말한다.
1
2
3
4
5
6
// document 구조가 이러할때
{
table : [{a:1},{a:2},{a:3}]
}
// 이런식으로 인덱스를 건다
db.user.createIndex({"table.a":1})
배열로 이루어진 어떤 값에 대해서 인덱스를 거는 것으로 elemMatch와 같이 특정 속성 배열에서의 빠른 검색이 필요 할때 좀더 나은 성능을 제공한다.
복합 필드 인덱스 (Compound key Index)
단일 속성이 아닌 여러 속성에 대해서 인덱스를 거는 것이다. 위와 동일하게 user라는 collection에서 인덱스를 걸건데 score는 오름차순으로 name 값에 대해서는 내림차순으로 설정한다고 해보자, 그럴때 방법은 아래와 같다.
1
db.user.createIndex({score:1,name:-1})
복합 필드 인덱스는 단일 필드 인덱스와는 다르게 고려해야할 사항이 좀 있는데 세부적인 내용은 아래와 같다.
1. sort 연산 시 인덱스 순서를 고려하여 생성하자.
아래의 인덱스 명령어는 동일한 결과를 도출할까?
1
2
db.user.createIndex({score:1,name:-1})
db.user.createIndex({name:-1,score:1})
언뜻보면 동일한 결과일 것 같지만 사실은 전혀 다른 인덱스이다. 검색할 때 역시 다른 인덱스로 처리되므로 주의해야한다.
2. 단일 필드 인덱스와 다르게 복합 필드 인덱스는 정렬 방향을 고려하자.
아래와 같이 인덱스를 생성했다고 생각해보자
1
db.user.createIndex({score:1,name:-1})
이러한 경우는 빠른 검색을 지원한다.
1
2
db.user.find({}).sort({score:1,name:-1})
db.user.find({}).sort({score:-1,name:1})
원래 걸었던 인덱스대로 조회하거나 완전 반대인 경우 인덱스를 사용해서 조회해서 성능이 보장된다 하지만 아래의 경우는 안된다
1
2
db.user.find({}).sort({score:-1,name:-1})
db.user.find({}).sort({score:1,name:1})
이렇게 인덱스는 미리 설정해둔 대로만 걸리기에 설정할시에 위 사항을 고려하는게 좋다.
3. Index prefixes
인덱스를 이용할 때 왼쪽 인덱스부터 적용되는 부분 인덱스를 Index Prefixes라고 한다. 예를 들어 아래와 같이 Index가 설정되었다고 가정해보자
1
db.user.createIndex({name:-1,score:1,number:1})
이런 경우 아래의 query는 index의 영향을 받는다
1
2
3
db.user.find({}).sort({name:-1})
db.user.find({}).sort({name:-1,score:1})
db.user.find({}).sort({name:-1,score:1,number:1})
이는 아까 말했다시피 왼쪽 인덱스부터 적용되기 때문이다. 그렇기 때문에 아래와 같은 쿼리는 index의 영향을 받지 않는다.
1
2
3
4
db.user.find({}).sort({number:1})
db.user.find({}).sort({score:1})
db.user.find({}).sort({score:1,number:1})
db.user.find({}).sort({name:-1,number:1})
그렇기 때문에 필수로 필드가 존재하는 순서대로 인덱스를 걸어야 성능에 대한 제대로 된 효과를 볼 수 있으며 만약에 인덱스가 걸려있음에도 인덱스를 타지 않게끔 쿼리를 쓴다면 성능에 되려 악영향을 미친다.
4. sort 연산은 non-prefix를 지원한다.
원래는 쿼리를 인덱스 건 왼쪽 필드 순서대로 요청해야하지만 sort 연산이 추가될경우 특정 상황에서 non-prefix를 지원한다. 아래와 같이 인덱스를 걸었다고 가정해보자
1
db.data.createIndex({a:1, b: 1, c: 1, d: 1 })
이런 경우 prefix의 정의에 맞지 않아도 find안의 값이 equilty에 대한 내용이라면 다음의 쿼리에 대해서는 인덱스의 영향을 받는다.
1
2
3
db.data.find({a:1}).sort({b: 1, c: 1, d: 1 })
db.data.find({b:1,a: 1}).sort({c: 1})
db.data.find({a:1,b:{"$gte":1}}).sort({b:1})
5. Index Intersection
인덱스 교차라는 것으로 인덱스가 교차해서 자동으로 적용되는 것을 뜻한다. 아래와 같이 두 개의 단일 필드 인덱스가 있다고 가정해보자
1
2
{ a: 1 }
{ b: 1 }
이런 경우 order라는 collection에서 아래의 쿼리를 요청시 인덱스의 영향을 받는다.
1
db.orders.find( { b: "1", a: { $gte: 15 } } )
각각 단일 필드 인덱스라서 영향을 받지 않는게 일반적이지만 이런 경우에는 인덱스 교차가 일어나기 때문에 빠른 성능을 제공한다.
느린 쿼리 탐색
Index를 설정한 건 좋다. 하지만 우리가 만든 쿼리가 미리 구성해둔 Index를 통해 요청되는지는 어떻게 알 수 있을까? 가장 좋은건 MongoDB에서 제공하는 COMPASS를 이용해서 분석하는게 가장 좋다. 특정 쿼리를 요청했을 때 MongoDB에서는 쿼리 응답시간이 느릴 경우 해당 쿼리를 기재해둔다. 이러한 쿼리 응답시간을 바탕으로 어떤 쿼리가 느린지 분석이 가능하다. (물론 쿼리 응답시간이 포함된 로그를 불러와서 파싱해서 별도로 분석할 수도 있다) 기본값으로 100ms 넘어가면 SLOW QUERY로 설정되어 찍히지만 별도의 명령어를 통해 이 설정을 바꿀 수도 있다.
1
2
3
4
5
db.runCommand({
profile: 0,
slowms: 200
})
// 200ms를 slow query로 처리하는 명령어
물론 이러한 느린 쿼리만 기재하는 것이 아닌 전체 쿼리에 대한 로그도 남길 수 있는데 그러면 성능이 느려진다. (ReplicaSet에서는 이러한 log 기능이 자동으로 설정되어 대부분의 log가 oplog로 남는다)
이러한 쿼리 로그로 찾을 수도 있지만 실 서비스에서 이렇게 찾게 되면 서비스 품질이 좋지 못하다. 가장 좋은 것은 서비스를 제공하기 전에 해당 쿼리에 대한 검증을 마치는게 가장 좋다. 그럴때 쓰면 좋은게 query explain 기능이다.
가령 DATA DB의 todo_lists collection에 “USER_ID”가 “test”인 값을 찾는다고 해보자 그러면 mongosh 명렁어로 다음과 같이 될것이다.
1
2
use DATA
db.todo_lists.find({CREATED_DATE:{"$gte":ISODate("2023-08-08T12:45:31.135Z")}})
그런데 이 collection에 복합 필드 인덱스를 걸어두었지만 해당 쿼리에 대해서도 제대로 작동하는지 궁금하다. 그럴때는 이런식으로 뒤에 덧 붙인다.
1
2
use DATA
db.todo_lists.find({CREATED_DATE:{"$gte":ISODate("2023-08-08T12:45:31.135Z")}}).explain()
그러면 쿼리에 대한 세부 설명이 나온다. 단순한 find 명령어의 경우 크게 볼것은 없지만 aggregation이나 복잡한 쿼리의 경우 explain기능을 사용하면 제대로 인덱스를 사용해서 찾기를 하는지 성능은 어떤지 살펴볼 수 있어서 매우 좋다.
만약에 해당 쿼리가 인덱스가 추가되어있지 않다면 다음과 같이 표기될 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
{
"explainVersion" : "1",
"queryPlanner" : {
"namespace" : "DATA.todo_lists",
"indexFilterSet" : false,
"parsedQuery" : {
"CREATED_DATE" : {
"$gte" : ISODate("2023-08-08T12:45:31.135Z")
}
},
"queryHash" : "48DC72E5",
"planCacheKey" : "98831128",
"maxIndexedOrSolutionsReached" : false,
"maxIndexedAndSolutionsReached" : false,
"maxScansToExplodeReached" : false,
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"CREATED_DATE" : {
"$gte" : ISODate("2023-08-08T12:45:31.135Z")
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"command" : {
"find" : "todo_lists",
"filter" : {
"CREATED_DATE" : {
"$gte" : ISODate("2023-08-08T12:45:31.135Z")
}
},
"$db" : "DATA"
},
"serverInfo" : {
"host" : "<HOST 이름>",
"port" : <사용 포트>,
"version" : "<버전>",
"gitVersion" : "<GIT VERSION>"
},
"serverParameters" : {
"internalQueryFacetBufferSizeBytes" : 104857600,
"internalQueryFacetMaxOutputDocSizeBytes" : 104857600,
"internalLookupStageIntermediateDocumentMaxSizeBytes" : 104857600,
"internalDocumentSourceGroupMaxMemoryBytes" : 104857600,
"internalQueryMaxBlockingSortMemoryUsageBytes" : 104857600,
"internalQueryProhibitBlockingMergeOnMongoS" : 0,
"internalQueryMaxAddToSetBytes" : 104857600,
"internalDocumentSourceSetWindowFieldsMaxMemoryBytes" : 104857600
},
"ok" : 1
}
다음 내용에 대해서 차근차근 해설해보자면 다음과 같다.
- explainVersion은 출력 버전이다.
- queryPlanner는 쿼리 최적화 프로그램에서 선택한 계획에 대해서 자세하게 나타낸다. namespace는 대상 db와 collection
parsedQuery는 내가 입력한 쿼리가 어떻게 해석되었는지 이것저것 다 지나치고 당장 확인 할 것은 winningPlan인데 stage를 보면 COLLSCAN이라고 되어있다. 이것은 Collection을 전체 확인했다는 것으로 인덱스가 사용되지 않고 검색되었기에 매우 비효율적임을 알수 있다.
다음 쿼리가 비효율적임을 알았으니 우리는 어떻게 해야할까? 바로 인덱스를 걸어줘야한다. 다음 명령어로 인덱스를 걸어줘보겠다.
1
db.todo_lists.createIndex({"CREATED_DATE":1})
CREATED_DATE에 대해서 오름차순으로 인덱스를 설정해둔 뒤 동일한 QUERY에 explain을 걸어보겠다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
{
"explainVersion" : "1",
"queryPlanner" : {
"namespace" : "DATA.todo_lists",
"indexFilterSet" : false,
"parsedQuery" : {
"CREATED_DATE" : {
"$gte" : ISODate("2023-08-08T12:45:31.135Z")
}
},
"queryHash" : "48DC72E5",
"planCacheKey" : "12099F37",
"maxIndexedOrSolutionsReached" : false,
"maxIndexedAndSolutionsReached" : false,
"maxScansToExplodeReached" : false,
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"CREATED_DATE" : 1
},
"indexName" : "CREATED_DATE_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"CREATED_DATE" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"CREATED_DATE" : [
"[new Date(1691498731135), new Date(9223372036854775807)]"
]
}
}
},
"rejectedPlans" : [ ]
},
"command" : {
"find" : "todo_lists",
"filter" : {
"CREATED_DATE" : {
"$gte" : ISODate("2023-08-08T12:45:31.135Z")
}
},
"$db" : "DATA"
},
"serverInfo" : {
"host" : "<HOST 이름>",
"port" : <사용 포트>,
"version" : "<버전>",
"gitVersion" : "<GIT VERSION>"
},
"serverParameters" : {
"internalQueryFacetBufferSizeBytes" : 104857600,
"internalQueryFacetMaxOutputDocSizeBytes" : 104857600,
"internalLookupStageIntermediateDocumentMaxSizeBytes" : 104857600,
"internalDocumentSourceGroupMaxMemoryBytes" : 104857600,
"internalQueryMaxBlockingSortMemoryUsageBytes" : 104857600,
"internalQueryProhibitBlockingMergeOnMongoS" : 0,
"internalQueryMaxAddToSetBytes" : 104857600,
"internalDocumentSourceSetWindowFieldsMaxMemoryBytes" : 104857600
},
"ok" : 1
}
이전에 stage에 COLLSCAN이라고 되어잇던 것이 IXSCAN으로 되어있는걸 볼 수 있다. 이는 인덱스를 이용하여 검색하였다는 뜻으로 제대로 인덱스가 적용되었음을 알 수 있다.
해당 COLLECTION에 총 데이터량이 N이라고 할 때 COLLSCAN일 경우 O(N)만큼 탐색을 해야한다. 하지만 인덱스를 거칠 경우 B-TREE를 거쳐서 탐색이 이루어지기 때문에 O(logN)만큼의 탐색이 이루어진다. (B-TREE와 이진트리는 시간 복잡도는 동일하나 랜덤엑세스의 횟수 차이로 인해 B-TREE가 조금 더 빠르다) 100개의 데이터를 검색한다고 할때 100번 보는 것보다는 7번 보는게 더 빠르게 찾을 수 있는것이니 추가적인 설명은 필요없으리라 생각한다.