NSDI 24' - Fast Vector Query Processing for Large Datasets Beyond GPU Memory with Reordered Pipelining
Fast Vector Query Processing for Large Datasets Beyond GPU Memory with Reordered Pipelining
24년 NSDI에 발표된 논문이다. 베이징 대학교에서 발표했으며, Vector DB에서 GPU 사용을 어떻게 하면 효율적으로 할 수 있는지에 대한 내용으로 아주 큰 Dataset을 대상으로 IVF(Inverted File) 방식의 인덱스를 차용한 GPU 메모리 매니저를 포함한 시스템이며 Offline에서 Index build하고 Online에서 서비스는 제공하는 방식이다. Faiss를 기반으로 통합되었으며 이를 사용해 볼 수 있게 github에 관련 코드도 있다.
1. 개요
Deep Learning과 RAG 기술 발달로 인해 Vector DB의 수요가 증가하고 있다.
수요가 증가함에 따라 성능에 대한 수요와 Dataset의 증가는 같이 이뤄졌는데, 그 과정에서 GPU가 Vector DB에 도입되는 것은 너무 자연스러운 현상이라고 말한다.
하지만 GPU RAM은 한정되어있기 때문에 HOST RAM으로 확장하여 같이 지원할 수 있게끔 많은 연구가 이뤄지고 있다고 한다. 이 과정에서 가장 먼저 생각할 수 있는 것은 Dataset을 GPU RAM 사이즈만큼 나누어서 Rotate 방식으로 구동하는 것인데, 이는 GPU의 활용률이 낮고, GPU Unified Memory라는 솔루션이 있는데 이는 Vector Data에 대해 고려하지 못하기 때문에 다수의 GPU Page fault를 발생시켜서 성능 저하를 초래한다고 한다.
위와 같은 문제로 인해 베이징대 연구원들은 GPU RAM의 크기를 벗어난 사이즈의 Dataset을 지원하고 GPU Unified Memory나 Dataset을 나누어서 Rotate하는 방식보다 훨씬 GPU를 잘 사용할 수 있는 솔루션인 RUMMY를 제안했다.
RUMMY의 큰 구조는 아래와 같다.
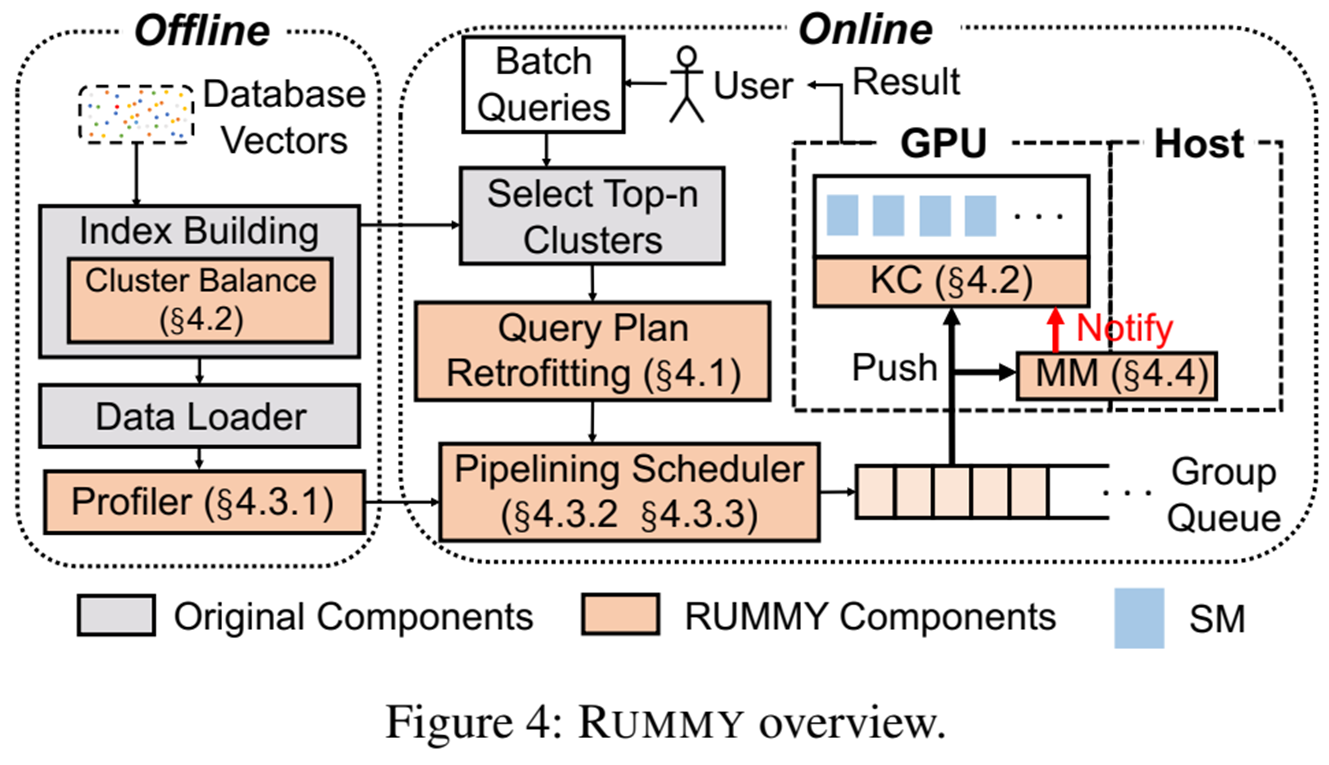
먼저 offline에서 Index를 빌드한다. IVF 방식이기 때문에 K-means를 통해 클러스터를 생성(이때 만들어진 클러스터를 원시 클러스터라고 하겠다)하고 해당 클러스터들을 다시 균등하게 쪼개는 클러스터 Balance 과정을 거친다. 이후에 해당 클러스터(이를 균등 클러스터라고 하겠다)들은 Profiler들을 통해 GPU 전송시간과 GPU 연산 시간을 측정하여 차후에 있을 Online에서 Query 요청하는데 필요한 Metric을 제공한다음에 Host Memory에 적재된다.
이후 실제 서비스를 제공하는 Online 과정에선 사용자가 Query를 입력하면 이를 Batch로 처리하는데 일반 IVF 방식과 같이 클러스터들의 중심점과 Query의 거리를 계산해서 가장 가까운것 K개를 뽑아서 연산할만한 원시 클러스터들을 선정한 뒤 해당 원시 클러스터들이 나뉜 균등 클러스터를 최적의 그룹단위로 묶고 전송 순서를 변경하여 전송하여 클러스터 연산 중(Overlap)에 데이터 전송이 일어나게끔 하고 GPU의 프로세싱 유닛인 SM이 충분히 활용되지 못한다면 해당 균등 클러스터 역시 나누어서 구동함으로써 GPU의 사용률을 높이는 방식이다.
2. RUMMY의 구조
1) Index build
a. IVF Index build
기본적인 K-means를 통해서 클러스터링(이렇게 만들어진 클러스터를 원시 클러스터라고 한다)하고 이를 이용하여 IVF를 만든다.
각 클러스터는 Centroid를 가지고 있으며 이는 나중에 Query와 비교하여 어떤 클러스터를 탐색 대상으로 삼을지 선정하는데 사용된다.
b. Cluster balance
원시 클러스터를 균등한 크기가 되도록 나눈다. 이때 나누어진 클러스터는 별도의 Centroid를 갖지 않고 원시 클러스터의 하위 클러스터로 존재한다. 이렇게 균등하게 나눠진 클러스터를 균등 클러스터라고 할때, 균등 클러스터로 만드는 이유는 차후 연산의 효율성을 위해서이다.
원시 클러스터를 균등 클러스터로 나누는 방식은 간단하다.
가장 작은 원시 클러스터의 크기를 p라고 하고, 이를 기준으로 클러스터를 나눈 뒤에 나눠진 전체 클러스터의 표준편차를 계산하여 목표 표준편차까지 도달하지 않았다면 p를 반으로 나눈 값으로 다시 클러스터들을 나눈다. 이런 방식으로 목표 표준 편차까지 도달할때까지 나누는 것이다.
ex) 100, 150, 200
- p = 100
- 100 => 100
- 150 => 100, 50
- 200 => 100, 100
- p = 50
- 100 => 50, 50
- 100, 50 => 50, 50, 50
- 100, 100 => 50, 50, 50, 50
차후 이 균등 클러스터들은 한번에 전송하고 처리하는 단위인 Group으로 묶이게 되는데 이 Grouping 과정은 런타임 과정에서 동적으로 일어나게 된다.
c. Profiler
온라인(런타임)에서 개별 그룹의 전송 시간과 계산 시간을 정확하게 예측할 수 있도록 모델을 오프라인에서 미리 구축하는 것이다.
이렇게 구축된 정보는 차후 클러스터 전송 계획 수립 간에 사용된다.
- Transmission Profiler 클러스터들이 전송될때 시간이 얼마나 걸릴지 측정하는 모델이다.
a : 전파시간, 실제 얼마나 걸리는지 측정
b : API 호출 오버헤드, 실제 얼마나 걸리는지 측정
ρ : 클러스터 크기
m : 균형 잡힌 클러스터 수
- Computation Profiler 클러스터가 연산될때 시간이 얼마나 걸릴지 측정하는 모델이다.
여기서 p는 클러스터 크기이며 그룹Gi에 포함된 균형 잡힌 클러스터의 개수를 나타내는 값으로 사실상 몇개의 클러스터를 처리하느냐에 대한 값이다.
d. Dataset store
처리된 균형잡힌 클러스터들은 모두 Host Memory에 저장되며 저장된 클러스터들은 OS가 해당 위치를 Disk로 SWAP하는 것을 막기 위해서 모두 page-locked로 지정된다. 이는 GPU가 해당 메모리에 더 높은 대역폭으로 접근 가능하게 처리할 수 있게 해준다.
2) Search Process
a. 원시 클러스터 선정
입력 받은 쿼리들은 일종의 배치로 처리한다고 생각할 수 있는데 이 Batch 사이즈는 임의로 지정할 수 있다.
입력 받은 쿼리들에 대해 사전에 build된 IVF에서 상위 n개의 가장 가까운 Cluster Centroid들의 거리를 구하여서 대상 원시 클러스터를 선정한다.
b. Cluster based retrofitting
초기 쿼리 계획에서 발생하는 중복 데이터(클러스터) 전송을 완전히 제거하는 것으로 아래의 그림을 보자.
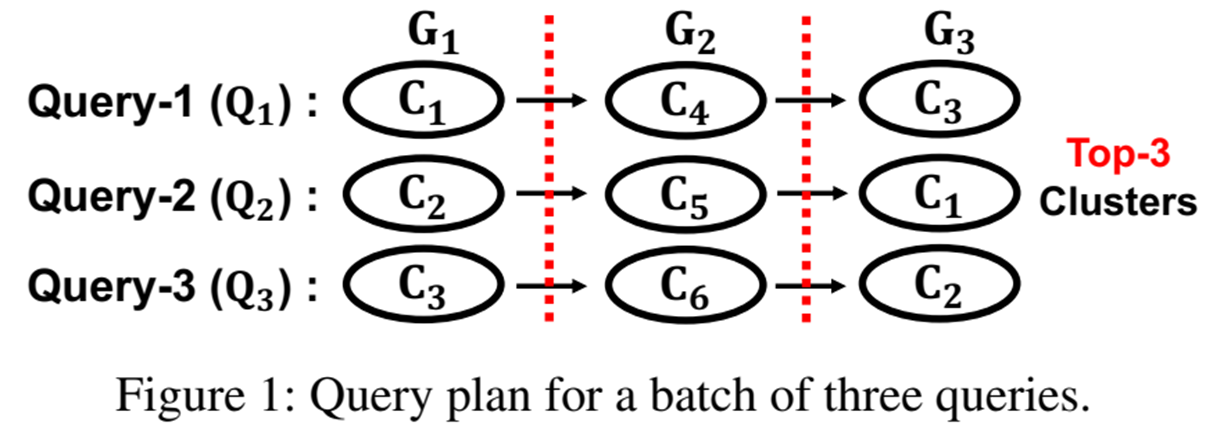
원래 쿼리들인 Q1, Q2, Q3가 다음과 같은 원시 클러스터를 요한다고 하자. 그러면 각각 다른 쿼리에서 동일한 클러스터를 요하는 경우가 있음에도 불구하고 GPU RAM의 한계로 인해 다시 전송해야할 수가 있다. (GPU RAM 부족으로 인해 이전에 사용하던 클러스터는 GPU RAM에서 제거해야하므로)
하지만 아래의 그림 a와 같이 클러스터가 올라온 김에 다수 쿼리를 처리할 수 있게 끔 순서를 바꿔줄 수 있다.
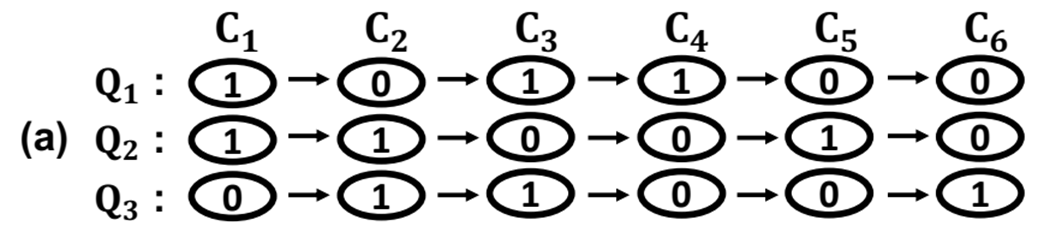
위와 같이 순서를 변경하면 C1,C2,C3에 대해서 중복 전송을 제거할 수 있다.
만약 앞서한 작업으로 인해 이미 GPU RAM에 C5,C6가 있다면 아래와 같이 C5와 C6를 앞으로 당겨서 추가 전송을 제거 할 수도 있다.
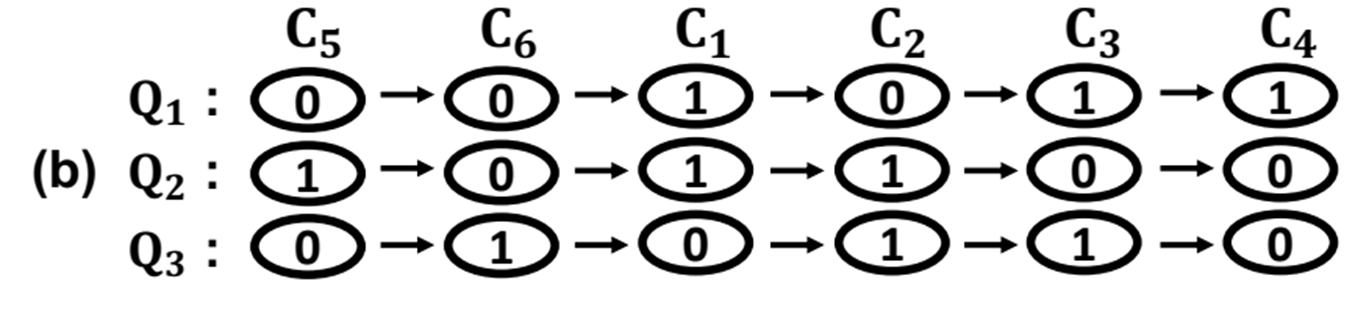
이렇게 원시 클러스터의 전송 순서를 바꾸어서 중복 전송을 제거할 수 있다.
c. Pipelining scheduler
앞서 균등 클러스터들은 다시 Grouping 되어 전송과 연산의 최소 단위가 된다고 했다.
이 경우 Group은 동적으로 일어나게 되는데, 이 과정에서 어떻게 그룹화 할지가 중요하다.
이 RUMMY의 목적은 전송간에 연산이 일어나게 하여 latency를 최대한 줄이고 GPU 활용률을 최대한 높이는데 있다. 따라서 이 Grouping도 너무 작게 Group으로 잡으면 전송 및 계산 그룹 간 동기화 오버헤드 증가하고, 너무 크게 Group을 잡으면 Overlapping이 일어나지 않는다.
Overlapping이란 아래와 같은 상황이다.

PCIe에 있는게 전송중인 그룹이고, GPU에 있는게 연산중인 그룹이라고 해보자.
위와 같이 전송과 연산이 동시에 일어나는데 이 과정이 겹치게 되면 가장 빠른 결과를 낼 것이다.
CPU에서 파이프라이닝을 하는 것과 같은 것이다.
따라서 이러한 Overlap이 많이 일어날 수록 성능은 좋아질 것이기 때문에 Grouping의 적절한 균형점을 찾는게 중요하며, 이것을 RUMMY는 해준다.
Grouping된 균등 클러스터 역시 스케줄링이 필요한데, 아래의 그림을 보자.
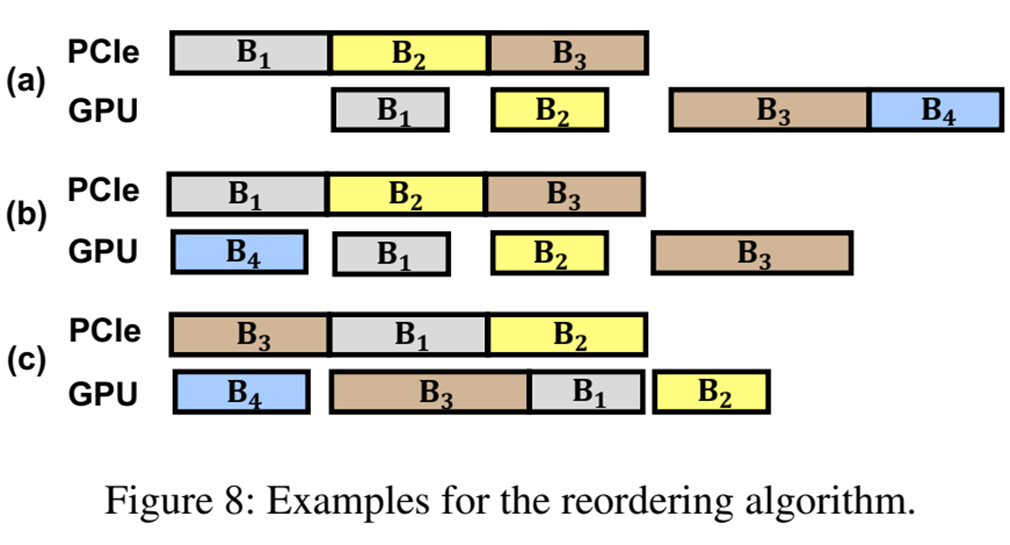
그림 (a)의 B1~4들이 각각 그룹이라고 했을 때 B4은 이미 GPU RAM에 있다고 가정해보자.
아무리 균등화된 클러스터라지만 완전히 같진 않을 것다. 때문에 B1,2,3,4는 연산시간이 모두 다른것을 볼 수 있다.
이 과정에서 가장 최적의 Overlap을 찾는것은 매우 어렵다고 논문에서 말하고, 때문에 2가지 통찰을 이용하여 문제를 해결했다고 했다.
- 이미 GPU RAM에 올라와 있는 클러스터 먼저 사용할 것
- 연산시간이 긴 클러스터를 먼저 전송할 것
위 두 가지 정책을 따르면 Overlap이 증가함을 알 수 있다.
간단한 예시로 그림 (b)는 이미 B4가 GPU RAM에 있는 상태이니 전송이 필요없고, 그 과정에서 Overlap이 발생하고, 그림 (c)는 B3가 연산 시간이 가장 길기 때문에 먼저 전송하여 처리함으로써 다른 B1과 B2의 전송시간간에 Overlap 되는 것을 볼 수 있다.
이렇게 스케줄링까지 완료된 그룹은 Global Group Queue에 포함되어 대기하게 된다.
d. GPU Runtime
Global Group Queue에서 GPU로 올라오는 것 역시 RUMMY가 총괄한다. 정확하게는 kernel controller(이하 KC)와 GPU Memory Manager(이하 MM)이 해당 시스템의 요체이다.
둘다 구동 자체는 HOST RAM에서 구동되지만 서로 맡은 역할이 다르다.
MM은 Host 메모리에서 GPU 메모리로의 데이터 전송을 관리하고 GPU 메모리내의 클러스터 할당, 페이지 교체 정책등을 담당한다. 자체적으로 관리하는 로컬 그룹 큐가 비게 되면 글로벌 그룹 큐에서 그룹을 로컬 큐에서 가져오며 로컬 그룹 큐에 그룹이 있따면 이를 GPU 메모리로 전송하고 전송이 완료되면 KC에 이를 알린다.
KC는 GPU 커널의 실행을 제어하고 관리하며 GPU의 SM 활용률을 모니터링하고 동적 커널 패딩(아래 서술)에 대해 결정하며 CUDA 커널을 실행시키는 역할을 한다. MM에서 그룹 전송이 완료되었다는 알림을 받으면 KC는 전송된 그룹에 대한 계산 작업을 자신의 로컬 그룹 큐에 추가하여 실행한다.
※ GPU RAM 교체 정책
기본적으로 GPU RAM에는 균형 클러스터 단위로 메모리가 할당된다(이는 OS의 페이징과 비슷하므로 편의상 페이지라고 하겠다)
GPU RAM이 꽉 차면 원래 있던 Page들 중에 제거할 Page를 골라야하는데, 이 과정에서 필요한게 교체정책이다.
RUMMY에서는 GPU 페이지 교체간에 Miss 율을 최소화하기 위해서 배치내와 배치간 작업을 모두 고려한다.
배치 내 고려
RUMMY는 현재 처리 중인 배치에 대한 MM의 로컬 그룹 큐(local group queue)를 미리 살펴본다. 현재 GPU 메모리에 존재하면서도 이 배치 내에서 미래에 다시 필요할 것으로 예상되는 클러스터들을 식별한 뒤 식별된 클러스터들은 고정(pinned) 상태가 되어 GPU 메모리가 가득 차더라도 이 배치 내에서는 절대 제거되지 않는다.배치 간 고려
RUMMY는 각 클러스터가 참조된 횟수(referred count)를 기록한다. 실질적으로 해당 클러스터로 몇번 연산되었느냐를 말하는 것이다. GPU 메모리가 가득 차서 클러스터를 제거해야 할 때, RUMMY는 고정되지 않은(not pinned) 클러스터 중에서 참조 횟수가 가장 적은 클러스터(smallest counter)를 제거하는데 이는 LFU(Least Frequently Used) 정책과 유사하다.
d. Dynamic Kernel Padding
균등한 클러스터로 인해 GPU의 시간적 저활용은 해결했다(아래 그림 참조) 볼 수 있지만
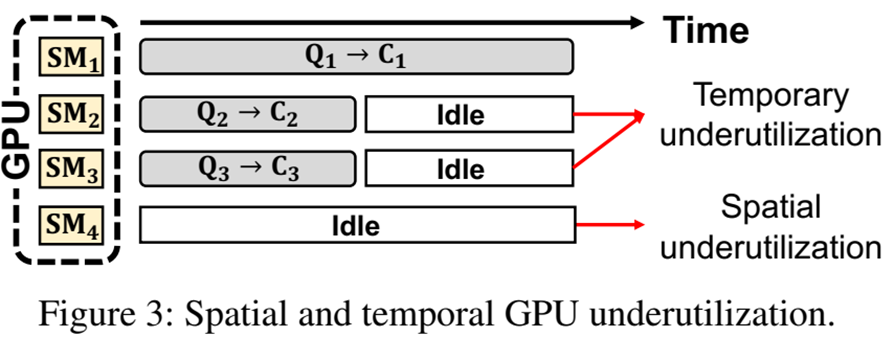
위와 같이 아예 SM이 비는 공간적 저활용은 어떻게 해결 할 수 있을까?
SM이 충분히 포화되지 못한다고 판단될 경우 GPU에서 균등 클러스터를 다시 나누어서 각 SM에 맡기게된다 이를 동적 커널 패딩이라고 부르며 균등 클러스터를 잘라서 각각 SM에 맡김으로써 SM의 활용율을 최대로 높인다. (그림 아래 참조)
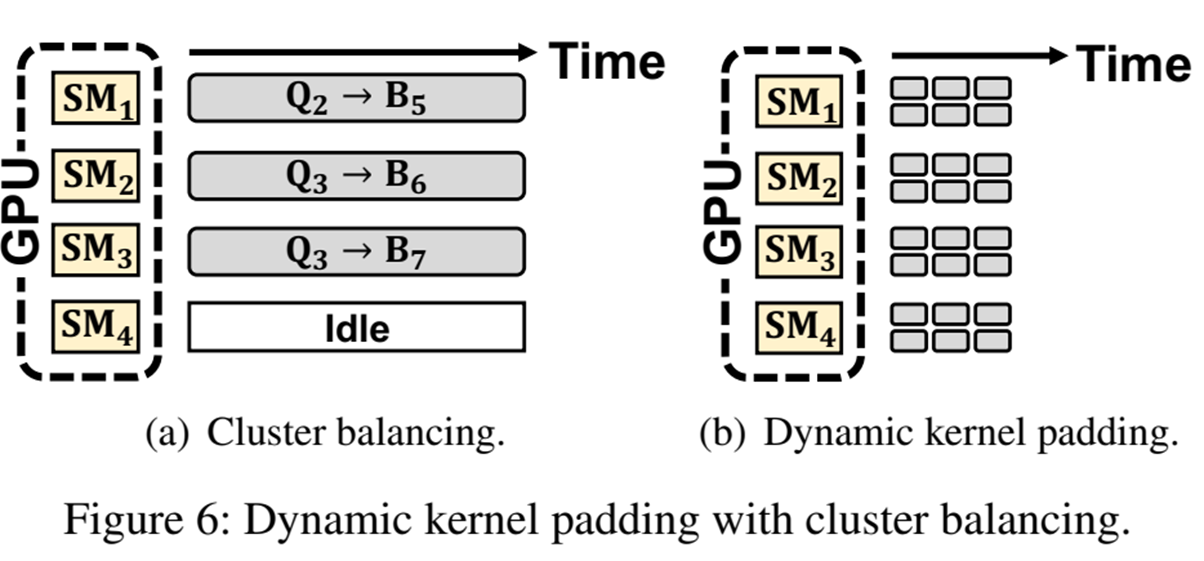
이를 진행하는 실행하고 결정하는 주체는 KC이다.
e. Final result return
위와 같이 모든 과정을 거쳐 처리된 Vector들은 다시 CPU로 반환되고 CPU는 그중에 가장 높은 K개를 반환하여 프로세스가 완료된다.
※ 추가 업데이트 및 퇴고 예정
참고문헌
- Zili Zhang, , Fangyue Liu, Gang Huang, Xuanzhe Liu, and Xin Jin. “Fast Vector Query Processing for Large Datasets Beyond GPU Memory with Reordered Pipelining.” . In 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) (pp. 23–40). USENIX Association, 2024.