Vector DB - Product Quantization
Vector DB - Product Quantization
1. 개요
DiskANN과 여러 VectorDB 운용간 쓰이는 양자화 방식인 Product Quantization(이하 PQ)에 예시와 함께 잘 설명해둔 한국어 포스팅이 없어서 내가 정리해서 쓰게 되었다.
이해한대로 썼는데 혹시나 내용이 틀렸다면 메일(blakewoo0819@gmail.com)로 틀린 내용을 보내주시면 감사하겠다.
기본적으로 VectorDB는 항상 메모리가 부족하다. 이는 벡터 데이터 자체가 용량이 매우 크기 때문이다.
끽해봐야 1,000,000개의 벡터 데이터를 메모리에 올리는데 수 GB가 필요한 경우도 있으니까 벡터 데이터가 얼마나 큰지 더 말할 것도 없다.
메모리 사용량을 줄이기 위해서 PQ를 사용하는데 메모리 사용량을 97%나 줄이고 정확도에 크게 영향을 미치지 않는 굉장한 방법이다.
2. 예시를 포함한 세부 절차
아래와 같이 8차원의 벡터 데이터가 6개 있다고 해보자. (혹시 차원 개념이 어렵다면, 선형대수부터 하고 오는게 좋다)
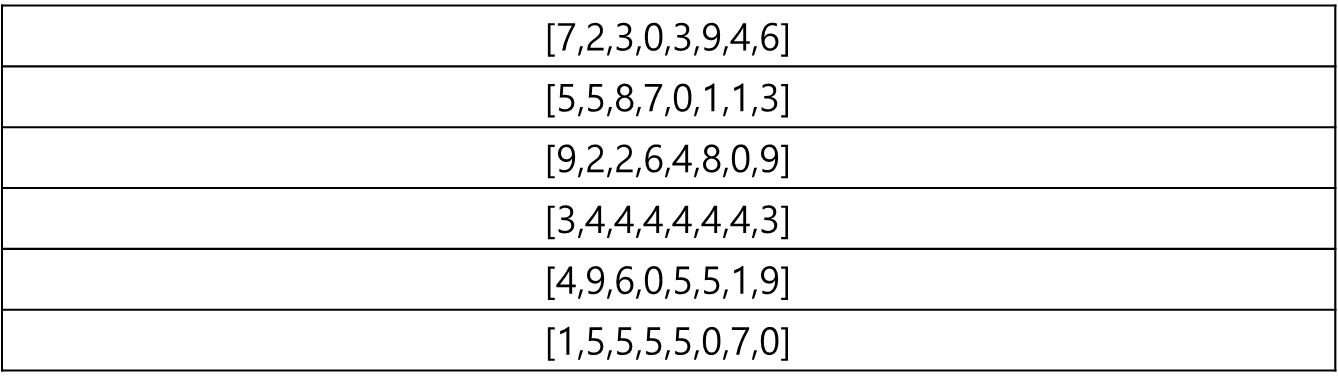
위 데이터를 PQ하고 싶다. 여기서 정할 것은 M값인데 이 M값은 8차원을 몇 개의 작은 차원으로 나눌 것이냐를 말한다(당연하지만 딱 나눠 떨어지는 수를 쓴다).
이번 예시에서는 M을 4로 잡아서 2차원씩으로 쪼개보겠다.
쪼갠다면 아래와 같이 된다.
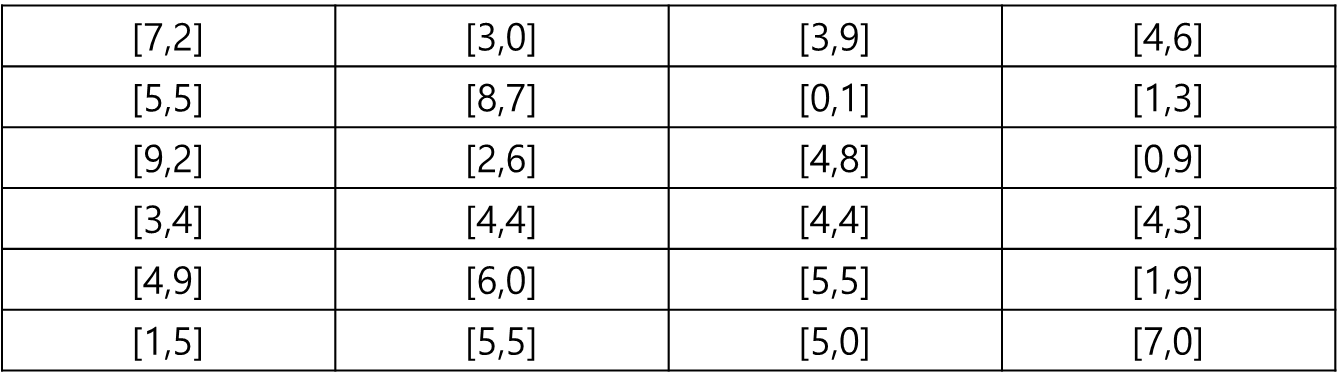
위와 같이 2차원으로 쪼개진 값을 열(Column)단위로 살펴보면 총 4개(M개)로 나뉜다.
여기서 K값을 정해야하는데, 위 Column 단위 값 집합을 몇 개의 군집으로 나눌 것인가에 대한 값이다.
여기서는 편의상 K를 2로 지정하겠다.
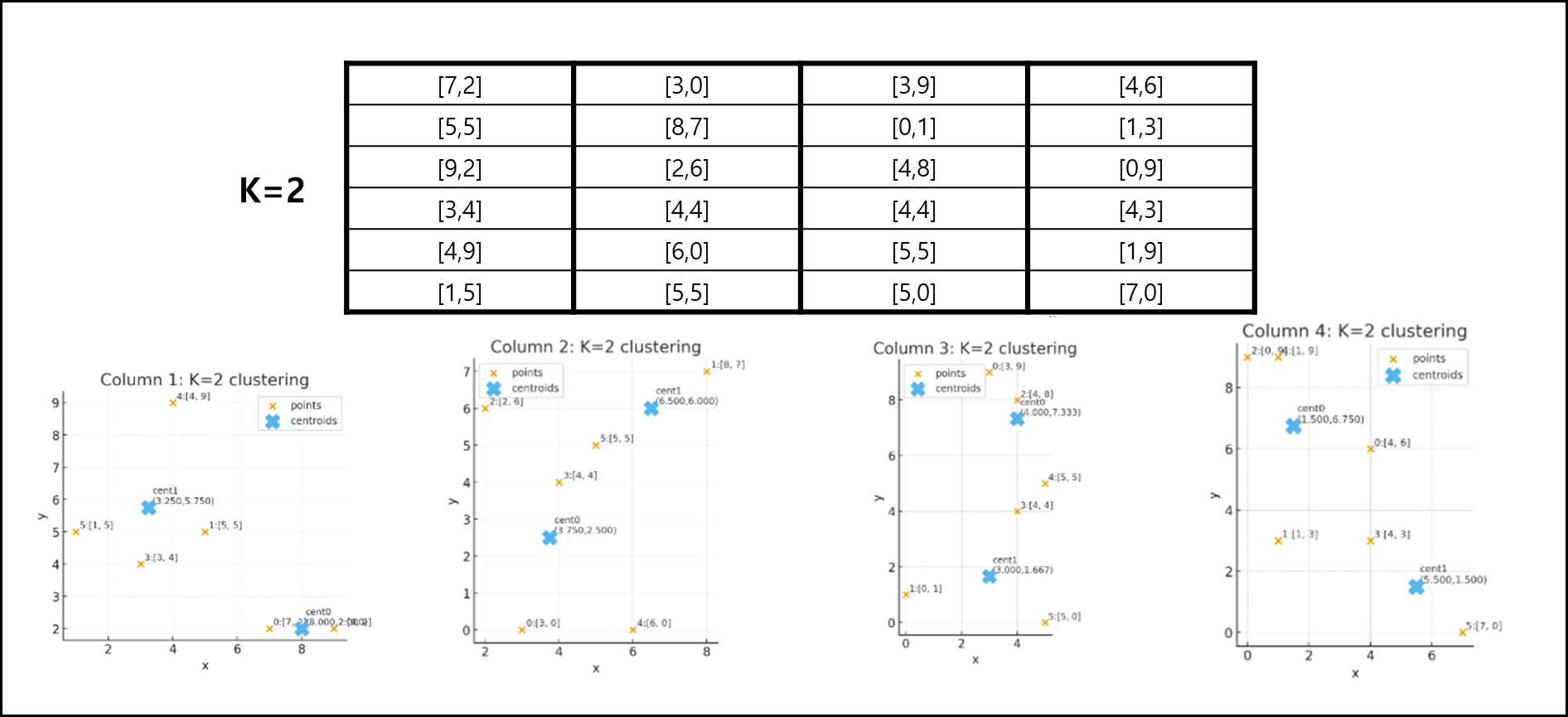
각각의 Column에 대해서 군집화 개수를 2로 잡으면 각 Column에 있는 6개의 데이터가 3개씩 군집처리된다.
이렇게 군집화된 3개의 데이터의 중심값을 Centroid라고 하는데 이 Centroid값이 중요하다.
전체의 데이터를 Column당 2개(K개)를 나눌 수 있다. 이를 표로 표현하면 아래와 같다.

위와 같이 표현된걸 Codebook이라고 하며 이렇게 Codebook을 구했다면 원래 Vector와 들어올 Query에 대해서 Codebook을 통해 값을 줄일 수 있다.
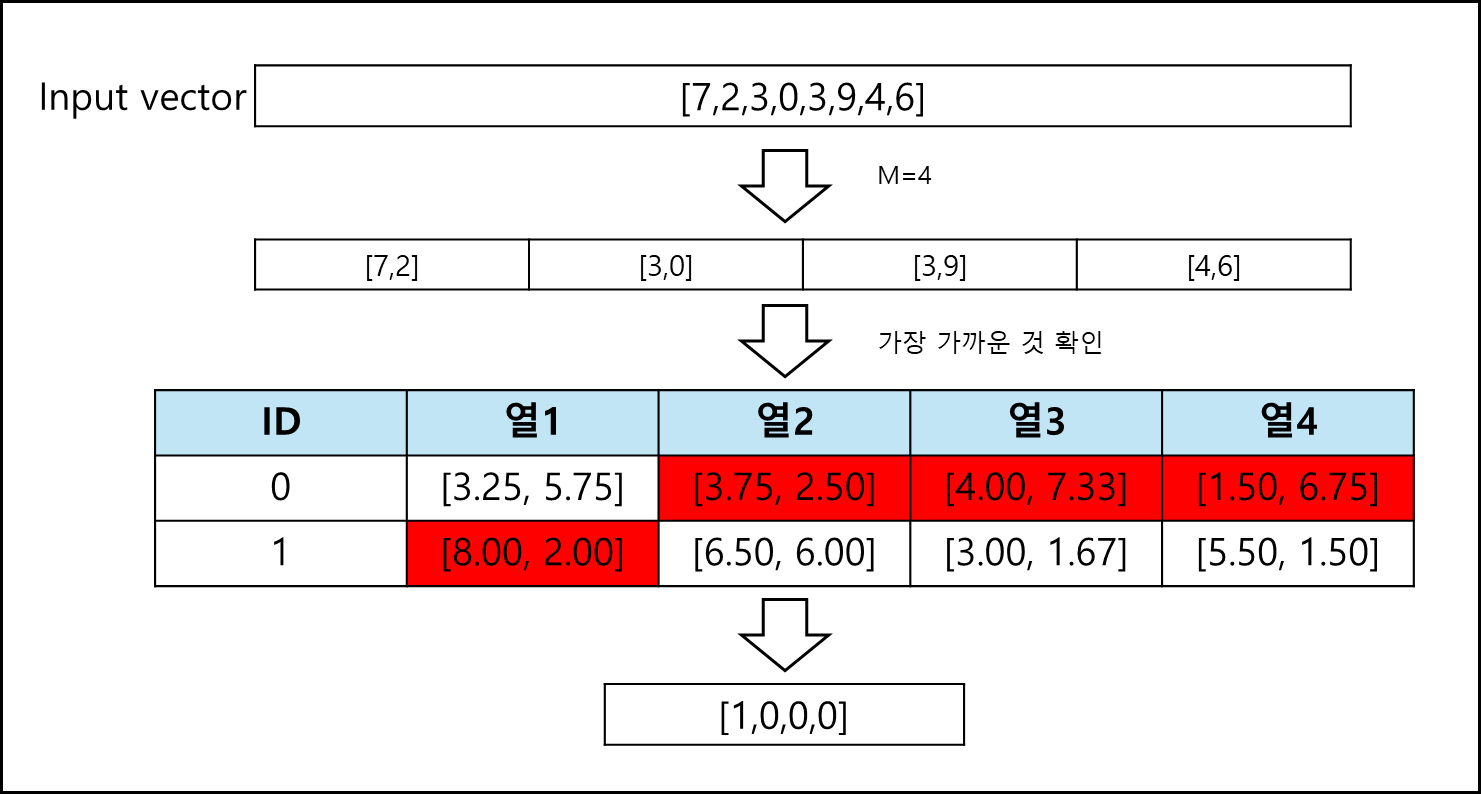
위의 절차를 살펴보자. [7,2,3,0,3,9,4,6] 이라는 벡터가 있다.
이를 M=4로 나누어서 코드북과 비교한다. 각 2차원씩을 비교하여 가까운 값의 ID를 취하면 [1,0,0,0] 과 같이 나온다.
원본 데이터와 비교하면 사이즈가 절반이나 줄어들었다.
3. 평가
사실 위의 설명은 매우매우 단순화 한것으로 기본적으로 몇백 차원은 우습게 넘어가는 벡터 데이터의 경우 이 M값과 K값은 성능과 PQ 이후의 데이터 사이즈에 큰 영향을 미친다.
예를 들어 데이터로 쓰고자하는 벡터의 차원수는 1024이고, 총 벡터의 개수가 1024개라고 할때 해당 벡터의 차원 하나당 double 자료형으로 표현한다면 벡터 한 개당 데이터 사이즈는 1024(차원) * 8(Bytes) = 8KB이다. 총 개수가 1024개이면 8MB가 되는 것이다.
이를 M=2,K=2로 PQ처리하면 512 차원씩 2개로 분할하고 각각에 대해서 군집화를 2개로 나눈 값이므로 벡터 하나당 2개의 bit로 표현이 가능하다. 이 2개의 bit가 1024개 필요한 것이므로 코드북을 제외했을 때 256byte면 전체 데이터를 표현하기에는 충분하다.
원래 데이터에 비하면 32768배나 차이나는 것이다. 물론 실제로 저렇게 극단적으로 PQ를 하진 않는다.
저렇게하면 1024 * 1024를 4분할해서 쓰는 거랑 다를바 없기 때문에 오차가 극단적으로 늘어난다.
이 때문에 M값과 K값이 늘어나고 줄어들 수록 성능과 용량에 어떤 영향을 미치는지 잘 알아야한다.
M값이 늘어난다면 한 개의 벡터 데이터가 M개로 쪼개진다. 이럴 경우 좀 더 세부적으로 쪼개게되어 정확도가 올라간다.
하지만 나눠진 수가 많을 수록 합산해야하는 개수가 늘어나므로 TABLE LOOKUP 수가 늘어나게되어 연산량이 늘어나고 쿼리 지연이 늘어 날 수 있다.
K값이 늘어난다면 M개로 나눠진 각각의 데이터들이 좀 더 세밀하게 군집화된다. 이 역시 세부적으로 쪼개지는 것이니 정확도가 올라간다.
하지만 이 역시 K가 많을 수록 코드북 크기가 늘어난다. 왜냐면 K=2일때 각 서브 데이터셋에 대해서 2개씩의 Centroid만 보관하면 되지만 K=4라면 4개씩 보관해야하기 때문이다. 또한 연산 지연 역시 늘수 있는데 이는 Codebook이 커지면 캐시에 한번에 올라가는 양이 줄어들 수 있으므로 캐싱에 영향을 받아 속도가 느려지기 때문이다.
위와 같은 영향이 있기 때문에 M값과 K값은 얼마나 잡을지 생각하면서 지정해야하며, 최적화에 대한 관련된 많은 연구들이 있다.
(참고자료에 포함된 Microsoft research 문서도 그 중 하나이다)
참고 자료
- pinecone - Product Quantization: Compressing high-dimensional vectors by 97%
- mildlyoverfitted - Product quantization in Faiss and from scratch
- Aditya Krishnan, , and Edo Liberty. “Projective Clustering Product Quantization.” (2021).
- Microsoft research - Optimized Product Quantization