Microsoft DiskANN 논문 해석
DiskANN
1. 개요
DiskANN은 그래프 기반의 대규모 근사 최근접 이웃 탐색 시 스템으로, 64 GB 메모리와 저렴한 SSD만으로 수십억 개의 벡터 를 색인 및 검색할 수 있도록 설계되었다. 이는 전통적인 메모리 기반 근사 최근접 이웃 탐색방식이 요구하는 대용량의 RAM 용량 한계를 피하면서도, 높은 재현율과 낮은 탐색 지연을 균형있게 제공한다.
2. Vamana 그래프 구성 알고리즘
DiskANN의 가장 핵심은 Index를 구성하는데 핵심 알고리즘인 Vamana 그래프 구성 알고리즘이다. Vamana 그래프 구성 알고리즘은 DiskANN의 색인을 구성하는 주요 알고리즘이다. 먼저 전체 데이터 세트 N개의 벡터에서 무작위 edge를 만든다. 여기서 기준점을 선택하고 선택된 기준 점을 기준으로 하이퍼파라미터 α값에 따라 두 번의 가지치기를 한다. 어떤 점 p의 이웃을 선택한다고 했을 때 이웃이 아닌 점들 의 집합 V라고 하자. V에서 가장 가까운 이웃 p*를 선택한 뒤 V 에서 다른 후보점 p’을 선택할지를 이 α값으로 정하게 된다. α값은 두 개의 벡터가 주어졌을 때 거리를 구하는 함수가 D라면 아래의 식으로 나타낼 수 있다.
\[\alpha \times D(p*,p') \le D(p,p')\]만약 α가 1이라면 p와 p’의 거리가 p*와 p’의 거리의 1배수보다 크거나 같아야 계속 이웃 후보로 고려한다는 뜻이다. 만약 1배 수 보다 작다면 p’은 후보에서 제외해버리고 edge를 끊어버린다. 첫 번째 가지치기는 α값을 1로 두고 edge를 끊으며 두 번째 가지 치기에는 α를 1보다 큰 값으로 두고 이를 만족하는 edge는 다시 이어준다.
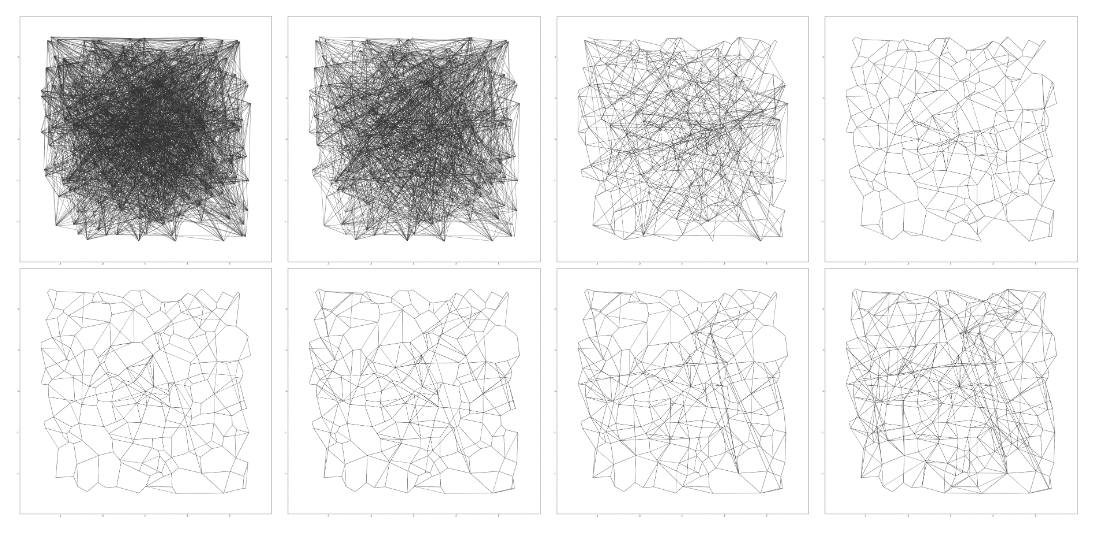
아래의 그림은 DiskANN 원 논문에 있는 그림으로 2차원 벡터에 200개의 점을 기준으로 그린것이다. Vamana Indexing algorithm으로 그린 것이며 순서대로 α를 1로 두고 가지치기 후에 1 이상의 값으로 먼 벡터에 대해서 지름길을 만드는 것을 볼 수 있다.
3. Index build 및 적재
Disk 인덱스를 빌드하기 시작할때 PQ_disk_bytes 값을 0으로 주지 않는다면 별도로 compressed된 그래프(_disk.index_pq_compressed.bin, _disk.index_pq_compressed.bin)를 만든다. 이는 양자화(이 양자화에 대해서는 추후 포스팅이 있을 예정이다)되어 작아진 그래프이고, 이후 Search 시 Memory에 올라와 Search시 참조되게 된다. (만약에 PQ_disk_bytes를 0으로 해서 빌드하면 index_pq_compressed 파일은 없고 Search시 전체 Index를 참조하지만 이는 속도가 매우 느려진다) 그리고, 앞서 설명한 Vamana Graph 생성을 통해 Index를 만들며 이는 전체 Vector에 대한 Index이므로 매우 용량이 크고, 따라서 SSD에 적재된다.
이 데이터를 k-means를 통해 군집화하여 그래프를 생성한다. 데이터가 크지 않다면 한 묶음의 그래프만 나오겠지만 많다면 다수의 그래프가 나오게되고, 이후 그래프가 통합되며 전체 Indexing이 완료된다. 여기서 각 그래프의 중심점을 centroid라고 하는데, 이 centroid에서 가장 가까운 벡터를 Medoid라고한다.
4. Beam Search
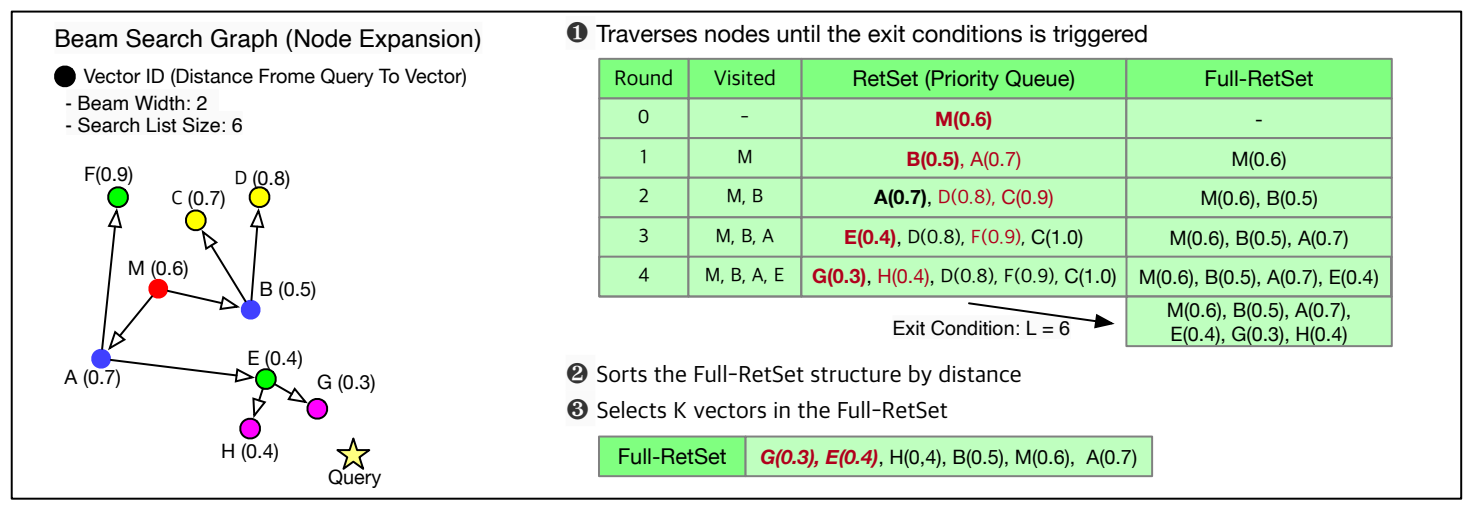
탐색은 그래프의 중심점인 centroid와 가장 가까운 벡터인 medoid에서 시작되며, 쿼리와의 거리가 가까운 이웃 벡터들을 Beam Width만큼 선택하여 탐색 영역을 점차 확장한다. (여기서 Beam Width는 DiskANN을 구동하는데 인자값 W이다)
이때 거리 계산을 위해 실제 벡터 값이 필요한데, DRAM 또는 SSD의 캐시 영역에서 해당 벡터를 읽어오게 된다. 여기서는 Search List가 중요하다. 이는 DiskANN을 구동할때 인자값인 L에 해당하는데, 실질적으로 몇 개까지의 노드를 탐색할지 정하는 파라미터이다. 내부적으로 확장노드를 기록하는 집합과, 후보군을 담는 큐가 있다. 확장노드 노드를 기록(탐색이 완료된)하는 집합의 크기가 Search 실행시 입력한 Search list 크기만큼 도달하게되면 탐색이 종료된다. (즉, 중간 종료 조건이 없다)
이 과정에서 탐색 완료된 집합의 크기를 쿼리와 거리 기준 오름차순으로 정렬한 후 K개 만큼 반환하게 된다.
5. 성능에 영향을 미치는 요인
Search시 응답 시간에 영향을 주는 인자는 Beam Width에 영향을 주는 W값과 메모리에 얼마나 캐시할지 정하는 Cache 값과 (여기서 Cache는 Medoid에서 BFS로 지정한 Cache 사이즈만큼의 Vector를 메모리에 올려서 Cache로 쓰는 것이다) Search list값이고 recall rate(재현율)에 영향을 주는 것은 W값과 Search list의 값이다.
Search list의 크기가 늘어난다면 Recall rate는 증가하지만, 응답시간도 늘어난다. 아래의 그래프를 보자
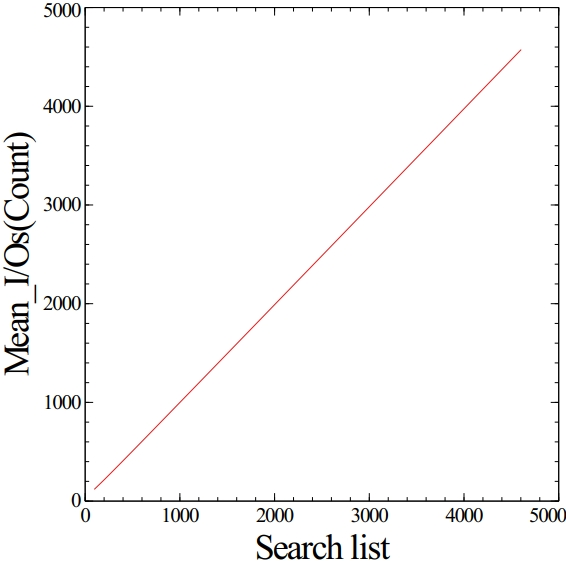
Search list의 크기가 늘어날 수록 평균 I/O 요청 횟수가 커진다. 여기서 말하는 I/O 요청 횟수는 SSD에 몇 개의 벡터에 대해서 요청한 것인지에 대한 것으로 DiskAnn에 포함되어있는 지표이다. Search list의 크기는 한번 탐색에 대해서 몇 개의 원소까지 탐색할 것인지 정하는 값이므로 당연히 Search list의 수가 늘수록 평균 I/O 요청 횟수는 당연히 비례한다. 또한 이 요청 횟수가 는다면 아래와 같이
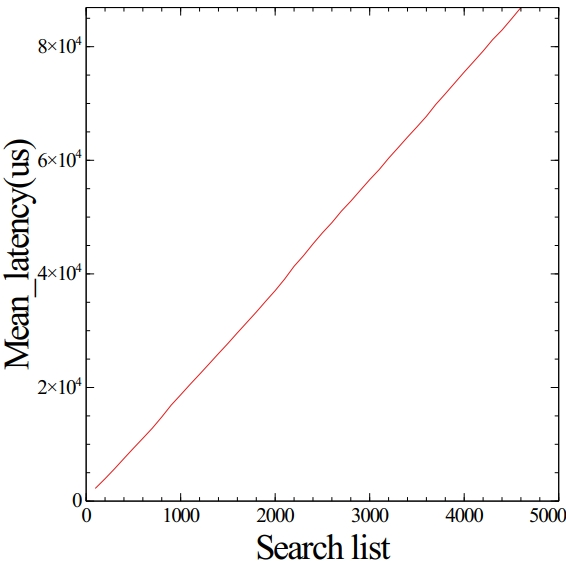
평균 지연시간도 늘어나게 된다. 이는 요청 횟수가 늘수록 대기시간도 길어지고 이 대기시간이 각 Query의 값에 영향을 미치기 때문이다. 사실 서비스를 만드는 입장에서는 가장 중요한건, 그래서 초당 몇 개의 요청을 처리할 수 있는가? 일 것이다.
아래의 그래프를 보자.
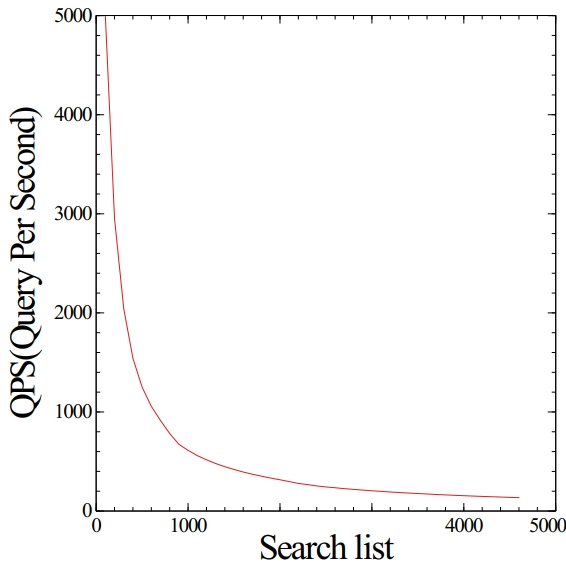
QPS(Query Per Second)는 말 그대로 초당 몇 개의 요청을 처리하는 지에 대한 내용으로 완만한 곡선 그래프를 그리는걸 알 수 있다.
이는 이상할 것도 아닌 것이 기본적으로 QPS는 Latency의 역수이다.
평균 지연시간이 위와 같은 선형 그래프이므로 이에 대한 역수인 QPS는 아래와 같은 수식으로 나타낼 수 있는데
\[QPS = \frac{1}{Mean Latency} = \frac{1}{ax+b}\]위와 같은 수식으로 나타나며 이를 그래프로 그리면 쌍곡선에서 x가 0 이상일때 나타나는 곡선 그래프로 나타나게 된다.
Search list의 경우 재현율에 대해서 그래프를 그려보면 아래와 같은 형태를 띈다.
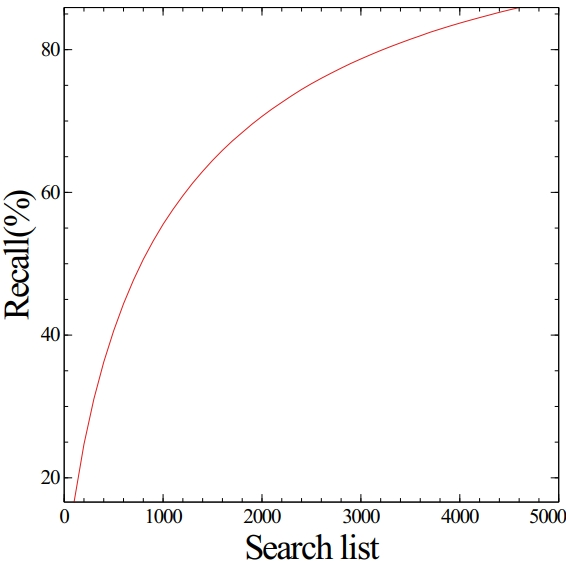
이 역시 선형적인 그래프가 아닌 곡선 그래프를 띈다.
이는 그래프 탐색의 특징으로 아래와 같이 Medoid에서 탐색을 시작할 경우
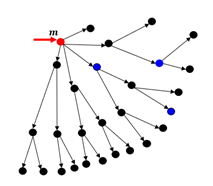
파란점이 정답이라 할 때 Medoid 근처에 있는 정답점을 찾을 때는 몇개 안되는 Vector만 찾아도 정답을 찾을 수 있지만 멀리 있는 점일 경우 가지가 크게 늘어나므로 해당 점을 찾기 위해서 더 많은 Vector를 탐색해야하므로 완만하게 증가하는 것이다.
※ Query와 Medoid간 Distance에 따른 Search 성능
그렇다면 Query에서 먼 Medoid보다 좀 더 가까운 Medoid를 사용했을 때 조금 더 거리가 가까우니 더 빨리 Search를 할 수 있지 않을까?
정말 물리적 거리라면 그게 맞는 말이지만, DiskANN에서는 그렇지 않다. 거리보다는 연결성이 더 중요하다.
이는 vamana 인덱싱에서 각 벡터를 연결할때 사용하는 파라미터인 $ \alpha $ 값의 영향을 받을 수 있는 것으로 보인다.(예상이며 검증되면 확실하게 바꿔두겠다.)
※ 추가 업데이트 및 검증 예정
참고문헌
- Jayaram Subramanya, Suhas, Fnu, Devvrit, Harsha Vardhan, Simhadri, Ravishankar, Krishnawamy, and Rohan, Kadekodi. “DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node.” . In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2019.
- 우지훈, 정보돈, 정연우, 디스크 기반 근사 최근접 이웃 탐색 기법에서 search list 크기 별 벡터 탐색 성능 및 재현율 상관 관계 분석, 2025년 전반기 한국정보과학회 데이터베이스 부문
- DiskANN - 공식 깃허브