병렬분산컴퓨팅 - 분산 시스템 개요
분산 시스템
이번 포스팅에는 분산 시스템의 전반적인 특징과 목적에 대해서 설명할 예정이다.
각 부분에 대한 세부적인 부분은 앞으로 추가적인 포스팅을 통해 설명 예정이다.
1. 개요
분산 시스템(Distributed System)은 독립적인 컴퓨터들의 집합이 네트워크를 통해 메세지를 주고 받으며 하나의 통합된 서비스를 제공하는 시스템이다.
아래와 같은 특징을 갖는다.
- 공유 메모리 없음 (No Shared Memory): 각 노드는 자신만의 로컬 메모리를 가지며 데이터를 직접 공유하지 않는다.
- 메시지 패싱 (Message Passing): 노드 간의 모든 통신과 협력은 네트워크를 통한 메시지 교환으로 이루어진다.
- 독립적 실패 (Independent Failures): 특정 노드나 네트워크 링크가 실패하더라도 전체 시스템은 계속 작동할 수 있도록 설계된다.
- 확장성 (Scalability): 노드를 추가함으로써 시스템의 규모를 유연하게 키울 수 있다.
2. 왜 분산 시스템을 사용하는가?
분산 시스템의 필요성은 아래와 같다.
1) 대규모 확장성 (Massive Scalability)
기기를 추가함으로써 수백만의 사용자와 페타바이트의 데이터를 제어할 수 있음
2) 결함 내성 (Fault Tolerance)
몇몇 기기가 고장남에도 다른 기기가 해당 서비스를 유지함으로써 결함 내성이 있음
3) 지리 분산 (Geographic Distribution)
서비스 배포시 사용자에게 가까운 곳에서 서비스를 제공함으로써 사용자에게 감소된 지연시간과 나은 사용자 경험을 제공함.
4) 낮은 지연시간 (Low Latency)
요청 한 작업을 분산함으로써 사용자에게 최소의 응답시간만으로 서비스를 제공
5) 유연한 확장 (Elastic Expansion)
기기를 필요한 만큼만 늘리고 줄일 수 있음 (비용 효율적)
3. 분산 시스템의 어려운 점 (주요과제)
1) 글로벌 클락 부재 (No Global Clock)
모든 기기에 완벽하게 일치하는 시간 소스가 없어 이벤트의 순서를 정하기 어렵다.
때문에 이벤트 발생시 다른 기기에서는 다른 순서로 적용될 수 있다.
2) 부분적 실패 (Partial Failure)
시스템의 일부는 고장 나고 일부는 정상 작동하는 복잡한 상황이 발생한다.
3) 동시성 (Concurrency)
여러 사용자가 동시에 동일한 데이터를 업데이트할 때 발생하는 충돌을 관리해야 한다.
4) 네트워크 불확실성 (Network uncertainty)
메시지가 지연, 유실, 중복되거나 순서가 바뀌어 도착할 수 있다.
4. 분산 시스템의 목표
분산 시스템을 설계할 때 주요 4대 목표는 아래와 같다.
1) 확장성 (Scalability)
사용자, 데이터, 작업의 증가를 지원해야한다.
이를 위해서는 부하의 증가를 제어할 수 있어야하며, 자원 할당의 점진적 증가가 가능해야한다. 또한 데이터를 복제 및 분산해서 저장할 수 있어야한다.
a. 확장성이 어려운 이유
중앙 집중식 서비스 (Centralized Services)
단일 서버가 모든 요청을 처리할 경우 해당 서버가 병목 지점(Bottleneck)이 되며, 서버에 장애가 발생하면 전체 서비스가 중단되는 단일 장애점(Single point of failure)이 된다. 부하가 증가할수록 성능이 급격히 저하된다.중앙 집중식 데이터 (Centralized Data)
하나의 데이터베이스만 사용할 경우 전체 시스템의 처리량(Throughput)과 가용성이 제한된다.
대규모 데이터와 동시 접속을 처리하기 어렵고, 백업이나 유지보수도 까다로워진다.조정 작업의 병목 현상 (Coordination Bottleneck)
시스템 전체를 관리하는 코디네이터가 존재할 경우, 모든 동기화와 조정 작업이 이곳에 집중되어 병목이 발생한다.
이는 높은 지연 시간을 유발하며 전체 시스템의 확장 성능을 제한한다.통신 오버헤드 (Communication Overhead)
사용자나 노드가 늘어날수록 교환해야 하는 메시지가 너무 많아지고 데이터 전송량이 증가하여 네트워크 혼잡이 발생한다.
이로 인해 지연 시간이 늘어나고 대역폭 비용이 상승하여 성능을 떨어뜨린다.자원의 한계 (Resource Limits)
CPU, 메모리, 저장 장치, 네트워크 등 물리적 자원은 한정되어 있다.
자원 확보를 위한 경쟁(Contention)은 성능 저하를 일으키며, 이를 해결하기 위해 매우 세밀한 자원 관리가 필요하다.
b. 확장성을 위한 현대적인 테크닉들
Scale Out(Horizontal Scaling)
Load balancer 뒤에 동일한 기기를 더 추가해서 부하를 분산시킨다.Replication
데이터를 복제해서 복제된 데이터에서 데이터를 읽어오게 한다.Caching
DB까지 확인 할 것 없이 Redis나 Memcached를 이용해서 캐싱한 데이터를 전달해서 지연시간을 줄인다.Load Balancing
부하를 분산시키는 기술이다.Data Partitioning(Sharding)
데이터를 분할 해서 저장함으로써 Scale out으로 데이터를 확장해서 저장할 수 있게 한다.Leverage the Cloud
클라우드를 이용해서 서비스를 사용한 만큼만 비용을 지출하고 서비스를 제공한다.
2) 신뢰성 및 결함 내성 (Reliability & Fault Tolerance)
몇몇 결함에도 불구하고 서비스가 지속되게 하는 것을 말한다. 아래의 3가지로 나눌 수 있다.
a. 결함 감지(Failure Detection)
어떤 노드의 에러나 혹은 응답이 없는 것을 정확하게 빠르게 감지해야한다.
이를 위해서 HeartBeat나 Health Check와 같은 매커니즘을 사용한다.
b. 복제, 중복(Replication & Redundancy)
동일한 일을 하거나 동일한 데이터를 제공하는 다수의 노드를 구동하여 한 개의 노드가 제대로 작동하지 않더라도 서비스에는 영향이 없게끔 한다.
이를 위한 기술로는 Replicated Storage나 다중 가용영역, 다중 리전등이 있다.
c. 대체 실행 및 복구(Failover & Recovery)
어떤 노드가 제대로 작동하지 않으면 대체 노드가 그 노드를 대신하여 서비스를 제공함으로써 서비스를 유지하는 것
Replication과도 완전 관련이 없지 않으며이를 위해서 Leader 선출, 자동 대체, 컨테이너 재실행 등의 매커니즘이 사용된다.
3) 일관성 및 조화 (Consistency & Coordination)
다수의 노드에도 데이터의 일관성과 이벤트와 명령의 순서를 지킬 수 있는 것을 말한다.
a. 동시성 제어 (Concurrency Control)
공유데이터에 동시 접근을 제어하고 충돌을 방지한다.
b. 순서 및 일관성 (Ordering & Consistency)
실행하는 명령을 일관성 있는 순서로 실행되게 보장하고 데이터의 View를 일관성있도록 유지한다.
c. 동기화 (Synchronization)
노드들의 실행과 요청의 순서가 제대로 작동하도록 보장한다.
d. 리더 선출 (Leader Election)
노드들 사이의 의사결정을 할 수 있도록 리더를 선출한다.
4) 성능 및 자원 효율성 (Performance & Resource Efficiency)
자원을 효율적으로 사용하여 좋은 성능을 유지하는 것을 말한다.
5. 분산시스템을 위한 아키텍처 모델
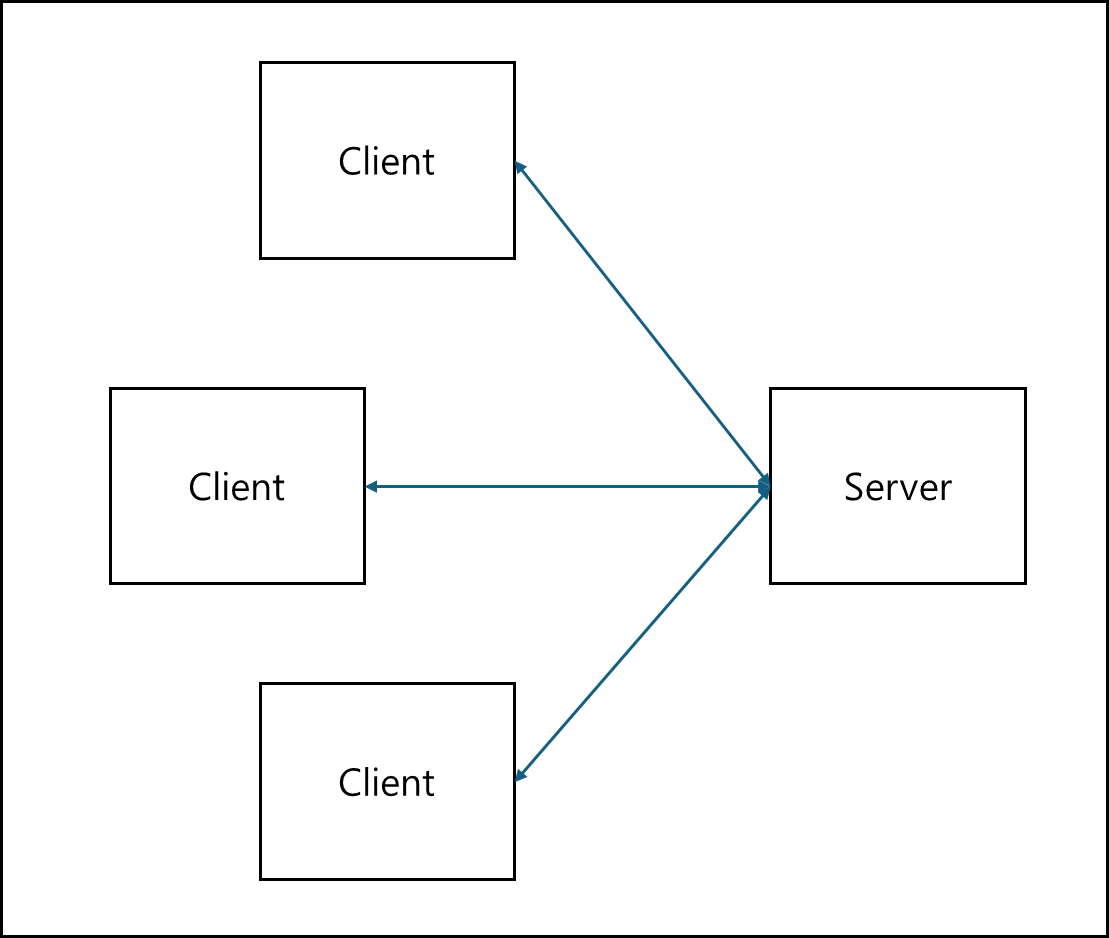
1) 클라이언트-서버
전통적인 방식으로 클라이언트가 중앙화된 서버로 요청을 보내고 받는 아키텍처이다.
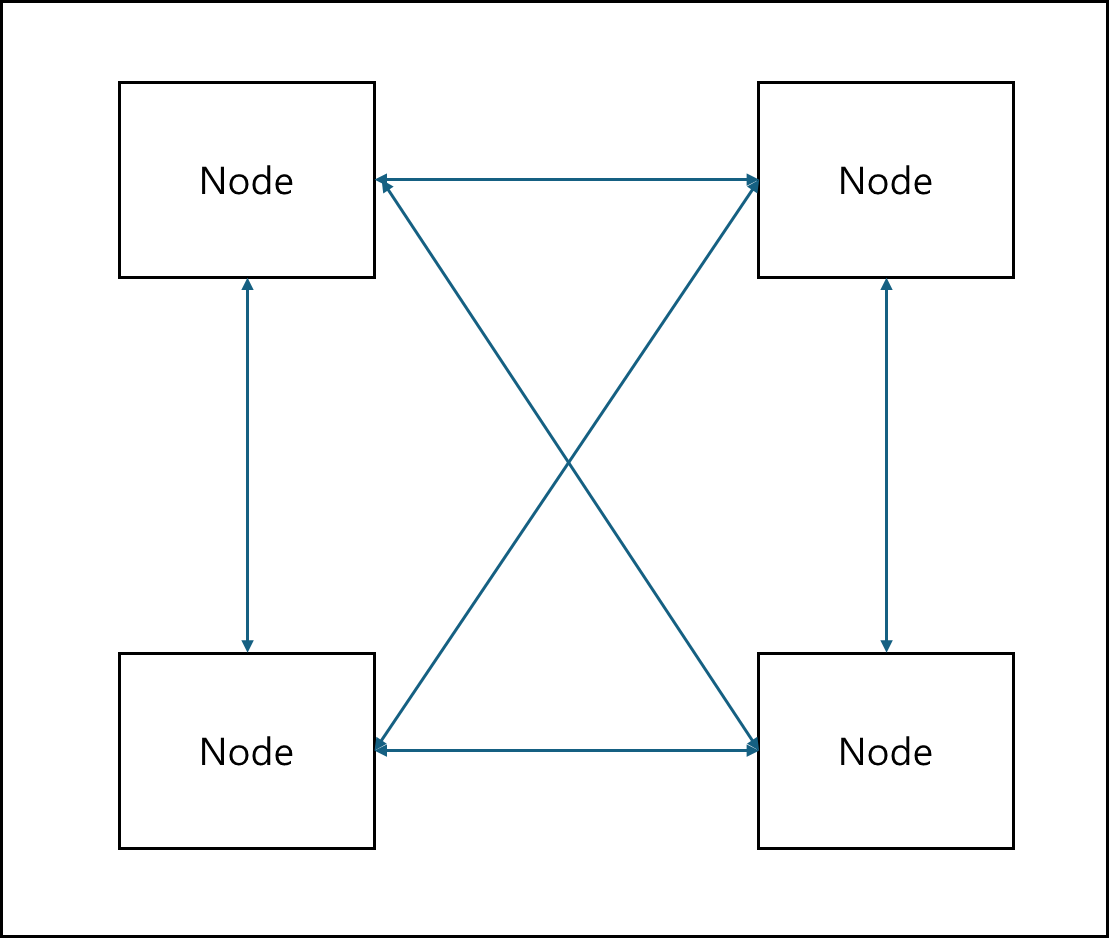
2) Peer-to-Peer
Bittorrent나 블록체인에서 사용하는 방식으로 각 Node들이 클라이언트이자 서버이며 Node끼리 요청을 주고 받는 구조이다.
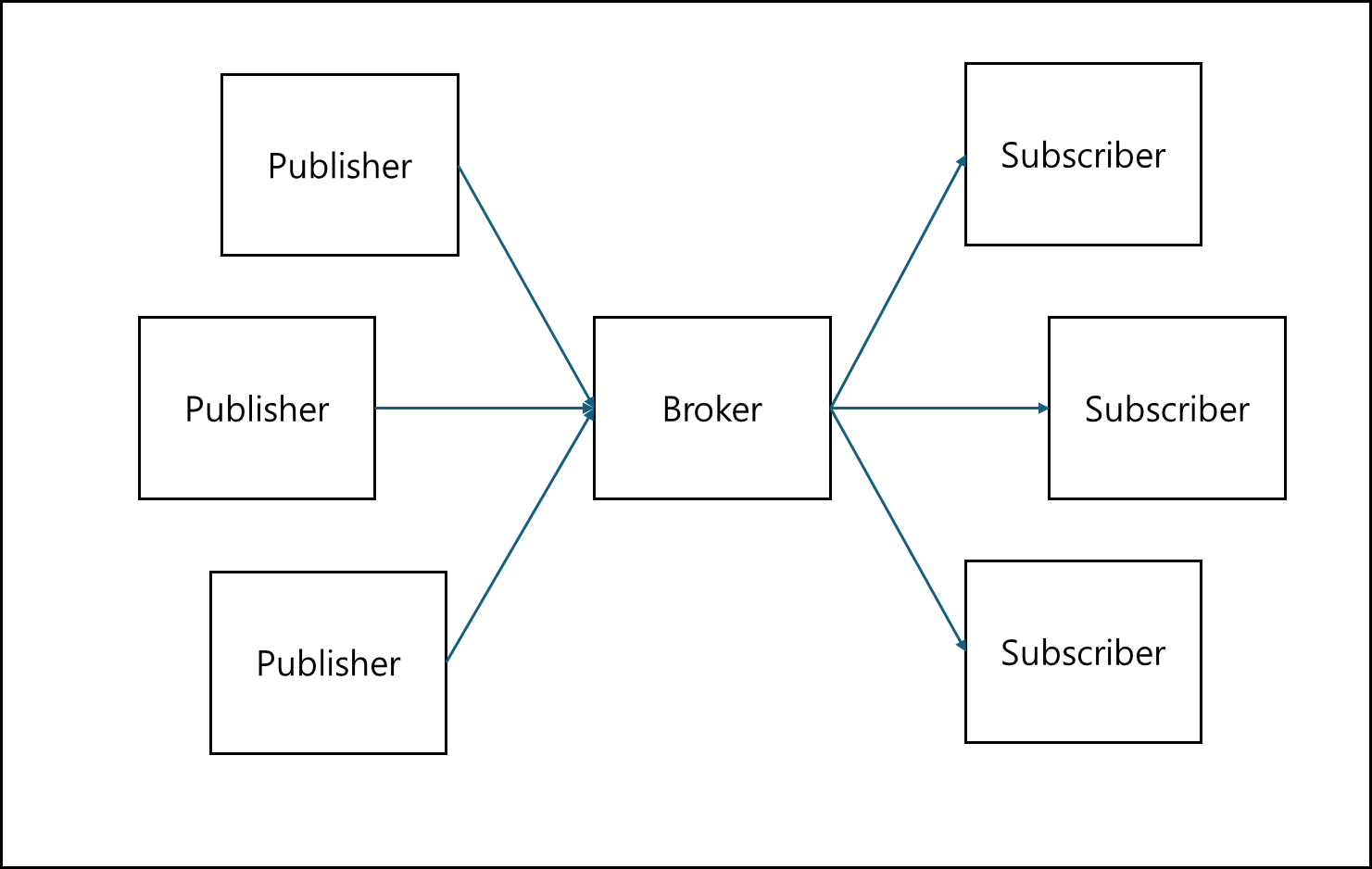
3) Publish-Subscribe
배포자(Publisher)와 구독자(Subscriber)로 나뉘며 배포자는 구독자들을 대상으로 어떤 토픽에 대해서 메세지를 뿌리는 방식이다.
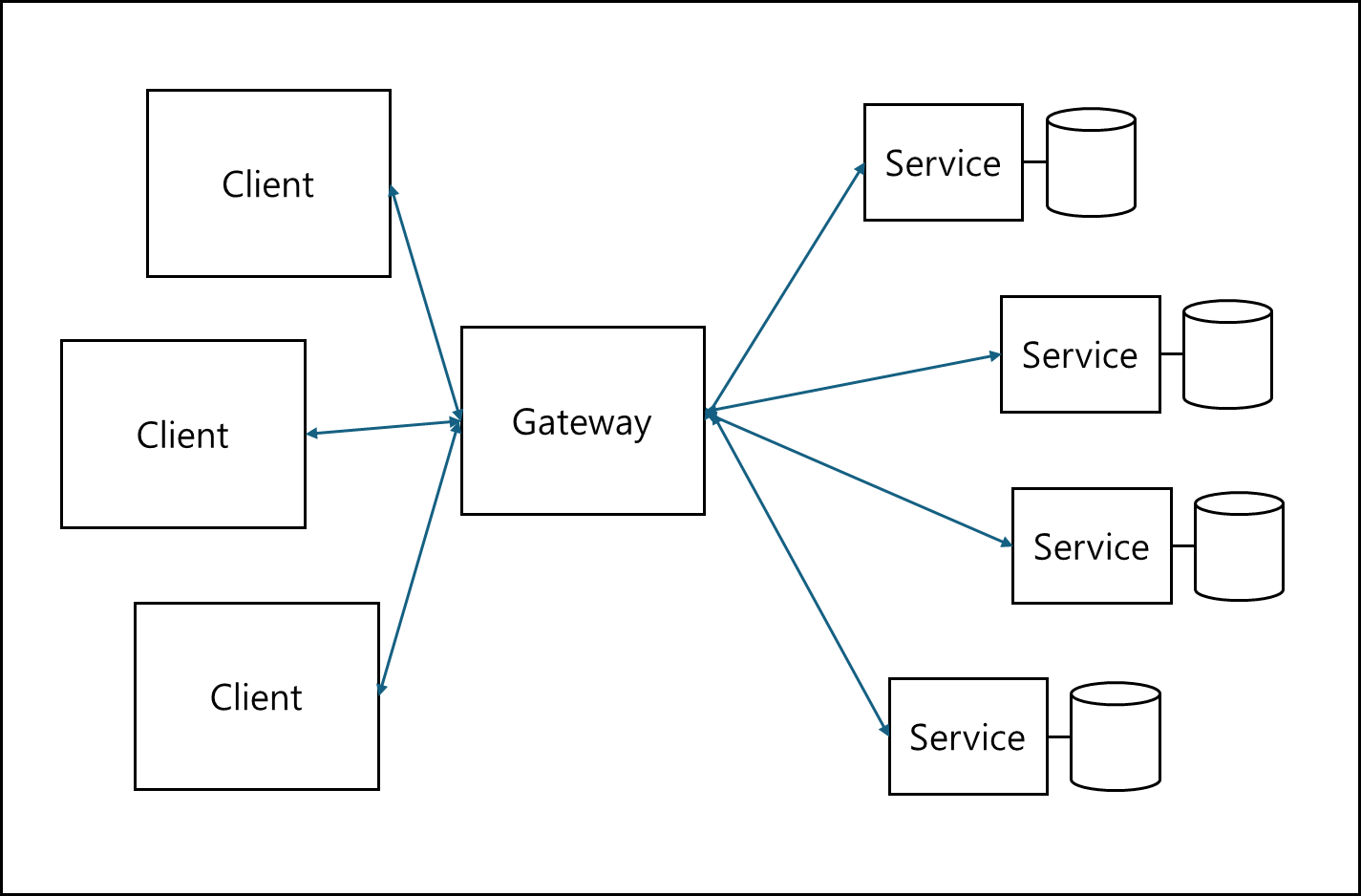
4) Microservices
어플리케이션이 각 독립적인 서비스로 분할되어 API로 연결되어있는 구조로, 요청이 들어올시 API Gateway가 해당 서비스로 요청을 보내어 받는 응답을 반환하는 방식의 구조이다.
이전에 이 구조에 대해서 포스팅 한적 있으니 참고하면 이해하기 쉽다.
6. 분산시스템의 핵심모델
1) 상호작용 모델 (Interaction Model)
느리고 불확실한 네트워크를 통해서 각 프로세스가 통신을 해야한다.
이 과정에서 고려해야할 것들을 세부적으로 나누면 아래와 같다.
a. 상호작용의 불명확성(Communication Uncertainty)
메세지는 여러가지 이우로 도착하지 않거나 늦게 도착하거나 혹은 순서가 뒤집혀서 도착 할 수 있다.
b. 타이밍의 불명확성(Timing Uncertainty)
각 프로세스는 독립적인 Clock을 갖고 있기 때문에 각기 시간이 맞지 않을 수 있다.
c. 동기적 시스템 (Synchronous System)
동기 시스템은 시간의 흐름과 처리 속도에 대해 명확한 상한선(Bounds)이 존재한다고 가정하는 모델이다.
- 주요 가정
- 메시지 지연의 상한선 : 메시지가 전달되는 데 걸리는 최대 시간을 알고 있다.
- 프로세스 실행 시간의 상한선 : 프로세스가 작업을 수행하는 데 걸리는 최대 시간을 알고 있다.
- 클락 드리프트(Clock Drift)의 상한선 : 각 노드의 시계가 서로 어긋나는 정도의 최대치를 알고 있다.
- 특징 및 결과
- 결함 감지 용이 : 정해진 시간(Timeout) 내에 응답이 오지 않으면 해당 노드에 결함이 발생했음을 확실하게 판단할 수 있다.
- 이론적 특성 : 시스템의 동작을 예측하고 논리적으로 추론하기 쉽지만, 실제 인터넷 환경에서는 적용하기 어려운 비현실적인 모델이다.
- 대표 사례
실시간 제어 시스템(Real-time control systems), 산업 자동화 분야 등.
d. 비동기 시스템 (Asynchronous System)
비동기 시스템은 시간이나 지연에 대해 어떠한 상한선도 가정하지 않는 모델입니다.
- 주요 가정
- 메시지 지연, 프로세스 실행 시간, 클락 드리프트에 대한 제한이 전혀 없다.
- 특징 및 결과
- 결함 감지의 어려움 : 타임아웃(Timeout)이 발생하더라도, 이것이 실제 프로세스의 결함 때문인지 아니면 단순히 네트워크가 매우 느린 것인지 구분할 수 없어 모호하다.
- 이론적 특성 : 가정을 최소화하기 때문에 모델링은 어렵지만, 실제 세계의 분산 시스템은 근본적으로 비동기적이다.
- 대표 사례
인터넷 서비스, 클라우드 시스템, 분산 데이터베이스 등.
동기 모델은 가정이 명확하여 결함 감지가 단순하지만 현실 세계에서는 드물며, 비동기 모델은 실제 인터넷 환경을 반영하지만 결함 감지나 상태 조정이 훨씬 더 어렵다.
2) 실패 모델 (Failure Model)
각 구성요소는 각기 다른 이유로 인해 작동하지 않을 수 있다. 아래의 세 개는 고려해야하는 실패 이유들이다.
a. Omission / Crash Failure
기대하던 작업이 수행되지 않았을 때를 말한다.
b. Byzantine / Arbitrary Failure
어떤 구성요소가 적합한 작업을 하지 않거나 악의적인 작업을 수행할때를 말한다.
c. Timing Failure
정확한 결과가 사용하기에는 늦은 시간에 도착한 경우를 말한다.
3) 보안 모델 (Security Model)
기본적으로 분산 시스템은 신뢰불가능한 네트워크와 잠재적으로 신뢰할수없는 인프라에서 구동되는데 여기서 어떻게 보안을 유지할지를 고민할때 고려해야하는 것들이다.
a. 위협
- 악의적인 공격
- 오염된 노드
- 네트워크 실패
b. 보안 목표
- 기밀성
- 진실성
- 가용성
c. 보안 매커니즘
- 인증
- 허가
- 암호화
- 감사와 모니터링
※ 추가 업데이트 예정
참고자료
- 서강대학교 박성용 교수님 강의자료 - 병렬 분산 컴퓨팅
원문 참고자료들
- Peter S. Pacheco, An Introduction to Parallel Programming, Elsevier Inc. (Morgan Kaufmann), 2011, ISBN 978-0-12-374260-5
- Gerassimos Barlas, Multicore and GPU Programming – An Integrated Approach, Elsevier Inc. (Morgan Kaufmann), 2015, ISBN 978-0-12-417137-4.
- G. Coulouria, J. Dollimore, T. Kindberg, and G. Blair, Distributed Systems: Concepts and Design, 5 th Edition, Pearson, 2012, ISBN 978-0-273-76059-7
- M. van Steen and A. S. Tanenbaum, Distributed Systems, 3 rd Edition, 2017
- Martin Kleppmann, Designing Data-Intensive Applications, 1 st Edition, O’Reilly Media, 2017, ISBN 978-1491903070 (또는 2nd Edition in February 2026)