컴퓨터 구조 - 메모리 컨트롤러와 스케줄링
메모리 컨트롤러와 스케줄링
1. DRAM Controller 개요
DRAM Controller의 구조는 아래와 같다.
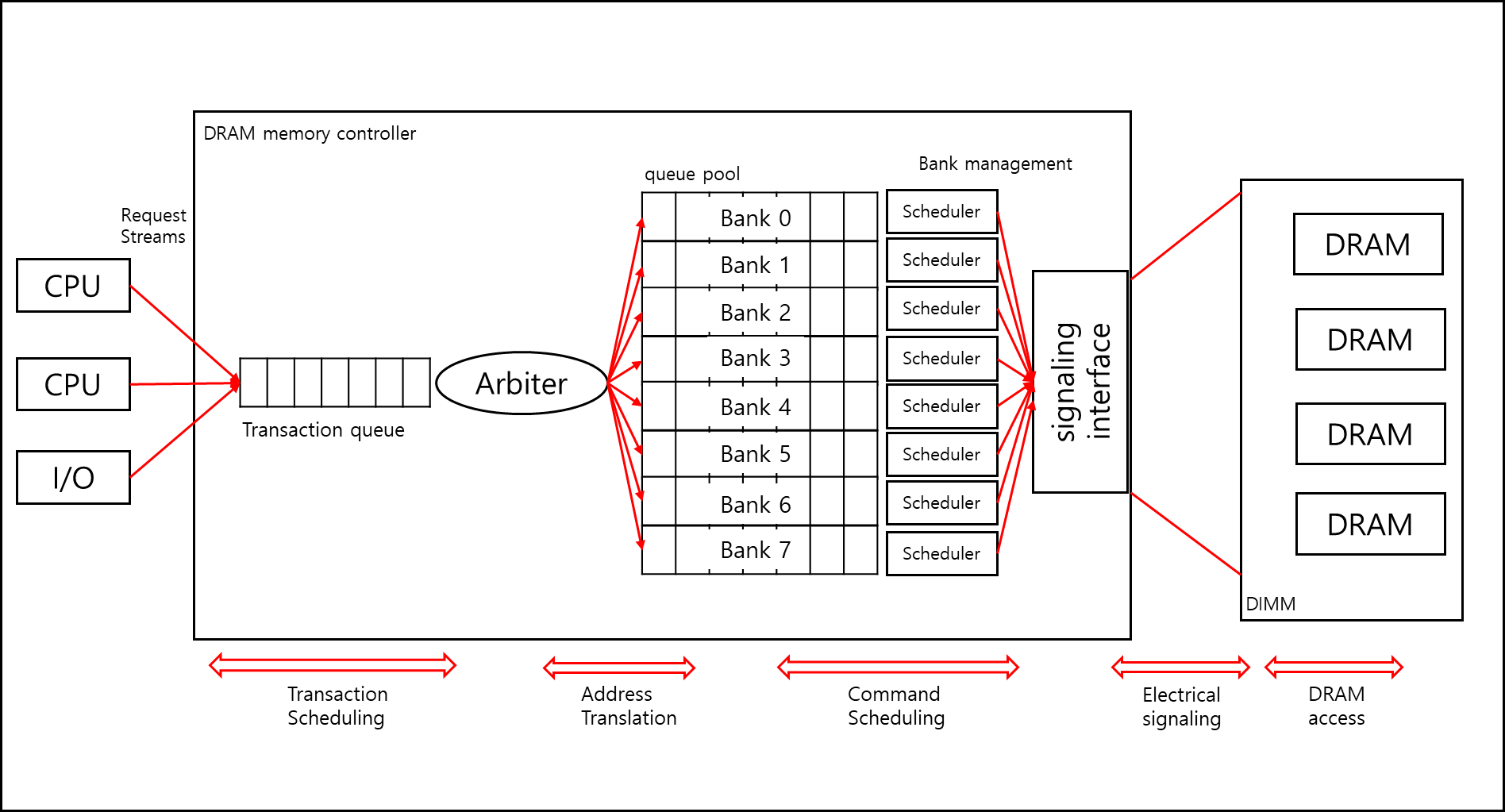
DRAM Controller의 각각의 컴포넌트에 대한 설명은 아래에서 추가적으로 설명하기로 하고 크게보면 DRAM Controller는 아래와 같은 역할을 한다.
1) DRAM의 올바른 동작 보장
캐피시터 특성상 일정 시간이 지나면 데이터가 사라질 수 있기 때문에 주기적으로 (일반적으로 64ms) 단위로 모든 row에 대해 DRAM Refresh를 해주어야한다. 이때 DRAM 컨트롤러가 이 Refresh를 담당한다.
2) 타이밍 제약을 지키며 DRAM 요청 처리
각 자원간(Bank, Bus, Channel)에 충돌이 발생하지 않도록 제어한다.
DRAM에 명령어을 순차적으로 요청하는 것도 이 컨트롤러가 담당한다.
3) 성능 향상을 위한 버퍼링 및 스케줄링
같은 ROW에 대해서 엑세스 하는 경우 매우 빨라진다. 이는 recharge, active 과정을 skip하고 바로 읽어들일수 있기 때문이다.
DRAM에 엑세스를 요청하는 경우 동일한 ROW에 대해서 엑세스를 요청하는 것을 모아서 처리한다면 성능은 더 올라간다.
컨트롤러는 이러한 요청을 모아서 처리하고 스케줄링하여 성능을 높여준다.
4) 전력 및 온도 관리
DRAM은 chip 단위로 전력을 절약할 수 있는 power모드가 있는데 DRAM 컨트롤러는 이러한 mode 제어와 각 chip을 끄고 킴으로써 발열과 power 소비를 제어한다.
2. DRAM Contoller의 위치는?
이 DRAM Controller는 어디에 위치하면 가장 좋을까?
각각 마다 장단점이 있다.
a. Mainboard chipset에 있을 경우
장점
- 시스템 설계시 다양한 DRAM을 유연하게 교체, 확장할 수 있다.
- CPU 전력 밀도가 감소한다. 이는 발열 관리가 수월하고 클럭이나 코어 확장에도 유리해진다.
단점
- CPU와 메모리 컨트롤러간 거리가 멀어지므로 메모리 접근 지연(Latency)가 커진다.
- CPU 컨트롤러 간 통신 대역폭에도 제한이 생긴다.
b. CPU 안에 있을 경우
장점
- 메모리 접근 지연이 낮아진다, 이는 CPU와 메모리 컨트롤간의 거리가 짧기 때문이다. 성능 증가는 당연히 따라온다.
- 대역폭이 높아진다. CPU 안에서 바로 통신하므로 다수의 레인을 이용할 수 있기 때문이다.
- 요청에 대한 우선순위나 메타정보 수집이 쉽기 때문에 높은 수준의 스케줄링 관리가 가능하다.
단점
- 회로 규모가 커진다. 메모리 컨트롤러때문에 CPU의 사이즈가 커지는 것이다.
- 전력 밀도가 올라가 발열 관리가 까다로워진다.
- CPU마다 지원하는 DRAM이 다를수 있어 유연성이 떨어진다.
c. 현재 사용하는 방식은?
옛날에는 Mainboard chipset에 있었으나 현재는 CPU안에 on-chip으로 들어가 있다.
아무래도 성능상 더 뛰어나기 때문이다. 그리고 Mainboard chipset은 메모리 제어기능 대신 USB와 STAT, PCIe등의 주변장치 인터페이스를 관리한다.
3. DRAM 스케줄링
1) DRAM Controller 구조
아까 봤던 그 그림을 다시 가져와서 보겠다.
IO를 통해 DMA(Direct Memory Access)를 하거나, SSD나 HD와 같은 디스크에서 file system으로 엑세스하거나 다수의 Core로부터 DRAM 엑세스 요청을 받을 경우 Transaction queue에 요청들이 쌓인다. 여기서 Arbiter를 통해 Transaction queue에서 1차적으로 스케줄링이 된다.
이후 각각 Bank를 담당하는 파이프를 지나 각 Bank queue의 요청을 스케줄링 후 순차적으로 정렬된 요청이 interface를 통해 DRAM으로 전달된다.
※ DRAM Burst - DDR(Double Data Rate)
간단히 말해서 한번에 많이 갖고 오는 기술을 말한다.
최근에는 DDR1~5 이런식으로 표기되는 기술을 말한다.
a. SDR
클럭 한 사이클에 up일때 n만큼(n은 한번에 갖고오는 정도 보통 64bit) 버퍼에 담았다가 보내는 방식이다. DDR 기술 이전에는 모두 이 방식을 사용했다.
b. DDR
클럭 한 사이클에 up과 down일때 2n 만큼 버퍼에 담았다가 보낸다. 이로써 한번에 128bit만큼 보낸다.
c. DDR2
클럭 2 사이클에 up과 down일때 4n 만큼 버퍼에 담았다가 보내며, 한번에 256bit만큼 보낸다.
이러면 단위 사이클당 데이터는 동일하지 않냐고 할 수 있지만, 한번에 보내는 양에 차이가 있기 때문에 총 대역폭은 늘어난다.
d. DDR3
클럭 4 사이클에 up과 down일때 8n만큼 버퍼에 담았다가 보내며, 한번에 512bit만큼 보낸다.
e. DDR4
DDR4에서는 pre-fetch 크기는 8n으로 늘어나지 않았으며 부분적으로는 4n 프리패치도 지원한다. 또한 DRAM에서 사용하는 Clock을 높이는 방향으로 발전했다.
f. DDR5
pre-fetch에서 16n을 지원하며 클럭수는 DDR4의 2배로 증가하고 전압 수는 오히려 감소했다. ECC 또한 on-chip에서 지원하게 되어 데이터 안정성도 높아졌다.
2) 스케줄링
a. 스케줄링의 필요성
DRAM 스케줄링이 왜 필요한가 싶겠지만, 기본적으로 DRAM의 읽기 및 쓰기는 Pre-charge, Activate, Read/Write를 거친다. 동일한 ROW의 경우라면 Read/Write만 하면 되겠지만 다른 Row 라면 최악의 경우 Pre-charge부터 해야할 수 있으며 이 절차는 성능 저하를 야기한다. 따라서 동일한 Row에 대한 요청이라면 모아서 처리하는게 응답시간 면에서는 이득이다.
b. 스케줄링 알고리즘
가장 대표적인 알고리즘 두 개만 소개하도록 하겠다.
FCFS(First Come First Served)
가장 일반적인 알고리즘으로 먼저온 것은 먼저 처리하는 것이다. 하지만 이 경우 최악의 경우에 요청마다 Pre-charge, Activate, Read/Write를 거쳐야할 수 있으므로 효율적이지 않다.FR-FCFS(First Ready,First Come First Served)
준비된 Row(Pre-charge, Activate)로 들어온 요청부터 처리하고 준비된 Row에 대한 요청이 없다면 먼저 들어온 순서대로 처리하는 방식이다.
성능적으로 가장 좋을 것 같지만 한 개의 Row에 대해서만 처리가 되면 다른 요청들은 기아(Starvation) 현상이 일어날 수 있으므로 일반적으로는 aging 처리를 해서 기아 현상이 일어나지 않게끔 같이 처리한다.
참고자료
- Computer Organization and Design-The hardware/software interface, 5th edition, Patterson, Hennessy, Elsevier
- 서강대학교 이혁준 교수님 강의자료 - 고급 컴퓨터 구조
- ADATA - Comprehensive Guide to DDR5 Memory