컴퓨터 구조 - CPU 구조 - Thread level parallelism
TLP(Thread level parallelism)
1. 개요
이전의 Pipeline에 대한 부분은 ILP(Instruction Level Parallelism)에 대한 내용이었다.
ILP의 주요 내용은 Super Scalar 구조를 통해 CPI를 줄이고 Instruction에 대해 병렬 처리를 하는 것이었다.
하지만 이 Instruction 들은 결국에는 하나의 Program 안에 있는 명령어이다.
이 말인 즉슨 한 개의 Thread에 속한 다수의 Instruction을 병렬화 했다는 뜻이다.
이렇게 병렬화 할 경우 각 명령어 간의 의존성에 의해 Hazard가 생기고 이를 해결하기 위해 필연적인 Stall이 발생하여 성능이 떨어지게 된다.
때문에 연구자들은 계속해서 더 ILP성을 늘리는게 도움이 될까? 하는 의문을 갖게 되었고 이는 ILP에 대한 Limits를 확인하고자 명령어 의존성을 제외하고 모든 Hazard를 지운 아주 이상적인 아키텍처에서 Benchmark를 돌렸을 때 일정 이상으로는 성능이 올라가지 않는 것을 확인하고 난 뒤에 밝혀졌다.
여기서 연구자들이 생각해낸게 바로 Thread Level Parallelism이다.
각 다른 Thread에 속한 명령어들은 의존성이 없으니 이를 빠르게 전환해가면서 실행시키면 어떨까 하는 아이디어에서 시작된 것이다.
이게 가능한 이유가 이미 Diversified Pipeline과 Superscalar Pipeline 에서 다수의 Thread를 동시에 돌릴 수 있는
기반이 생겼기 때문이다. 물론 아래와 같이 공유할 수 없는 것들은 있다.
- PC(Program Counter)
- Register file
- Flag
- Stack
위와 같은 것들만 별도로 복제하여 각 Thread 마다 하나씩 가지고 있을 수 있게 해준다면 한 코어 내에서 Thread Level Parallelism이 가능하다.
그렇다면 여기서 중요한건 어떤 기준으로 Thread를 Scheduling 할지이다.
2. 종류
1) Fine-Grained Multithreading
각각 명령어를 실행할 때마다 Thread 전환을 하는 방식이다. OS에서 스케줄링 기법중 Round-Robin을 생각하면 편하다. 기본적으로 한번의 Instruction Cycle마다 Switching이 일어나기 때문에 긴 stall 이든 짧은 stall이든 성능에 영향을 받지 않으나(명령어간의 의존성에 영향을 받지 않는다) 각각의 Thread에 대해서 어쨌든 자신의 차례가 와야 Instrunction을 계속 수행 할 수 있기 때문에 Thread 별 성능 저하는 피할 수 없다.

2) Coarse-Grained Multithreading
Thread를 실행하다가 Stall이 발생할 경우(가령, cache miss)에 다른 Thread로 전환한다.
Stall이 발생할때만 다른 Thread로 전환하기 때문에 각각의 Thread가 느려지지는 않지만 Fine-Grained Multithreading와 달리 명령어간에 의존성을 고려해야하고 이로인한 회로를 설계해야한다. 또한 짧은 Stall에 대해서도 Thread Switch가 일어나므로 Throughput에 대해 손해가 생긴다.
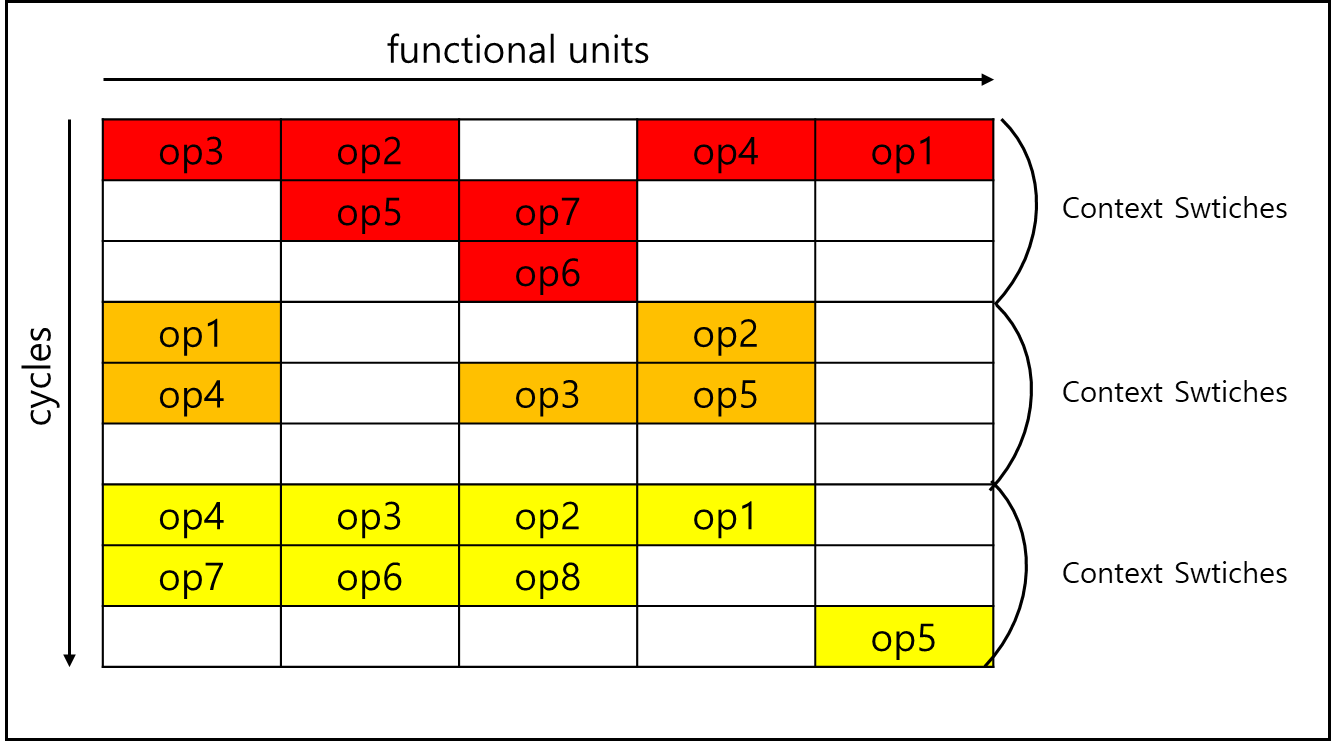
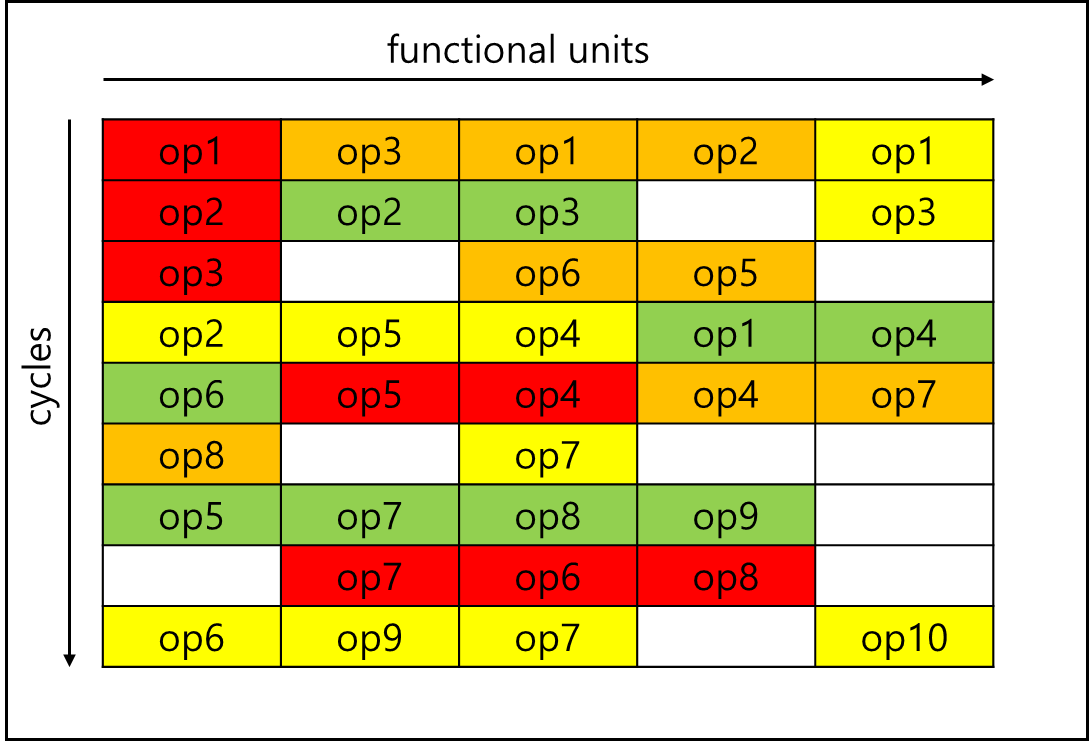
3) Simultaneous Multithreading(SMT)
모든 Thread의 Instruction을 큐에 넣고 같이 구동하는 방식이다. 별 개의 Thread cycle 없이 모두 섞여서 실행되기 때문에 가장 효율적이다. 이는 Reservation Staion이 크기 때문에 가능한 일로 각 Thread 별로 Renaming table과 각각의 Program Counter 만 있으면 가능한 아키텍처이다.
이를 두고 인텔에서는 Hyper Threading이라고 한다.
※ 참고사항
현대에선 CPU에서는 Superscalar에 Diversified Pipeline하여 out-of-order processing이 가능하며, 각 Thread별 레지스터와 PC, Flag, Stack등을 추가하여 코어 하나에 Simultaneous Multithreading으로 돌리되 이러한 코어를 다수 운용하는 Multi Processing 형태로 나온다.
참고자료
- Computer Organization and Design-The hardware/software interface, 5th edition, Patterson, Hennessy, Elsevier
- 서강대학교 이혁준 교수님 강의자료 - 고급 컴퓨터 구조