Vector DB - Quantization
Vector DB - Quantization
사실 이걸 여기 넣어도 될까 싶은데, 그냥 데이터 Store전에 Pre-Processing이라고 한다면 이것도 Vector DB에서 논할거리가 될 것도 같고, 무엇보다 Code book의 경우 Quantization을 거친 데이터를 쓰기 때문에 여기 포함했다.
1. 개요
찾아보니 양자화(Quantization)라는 단어는 여기뿐만 아니라 꽤 많이 쓰는 단어이다. 기본적으로 물리쪽에서는 연속적이지 않고 이산적인 물리량으로 만드는 것이고, 통신쪽에서는 아날로그 신호를 특정 이산치만으로 바꾸는 과정이라는 것이라고 한다.
단순히 말해서 아래의 그림과 같다.
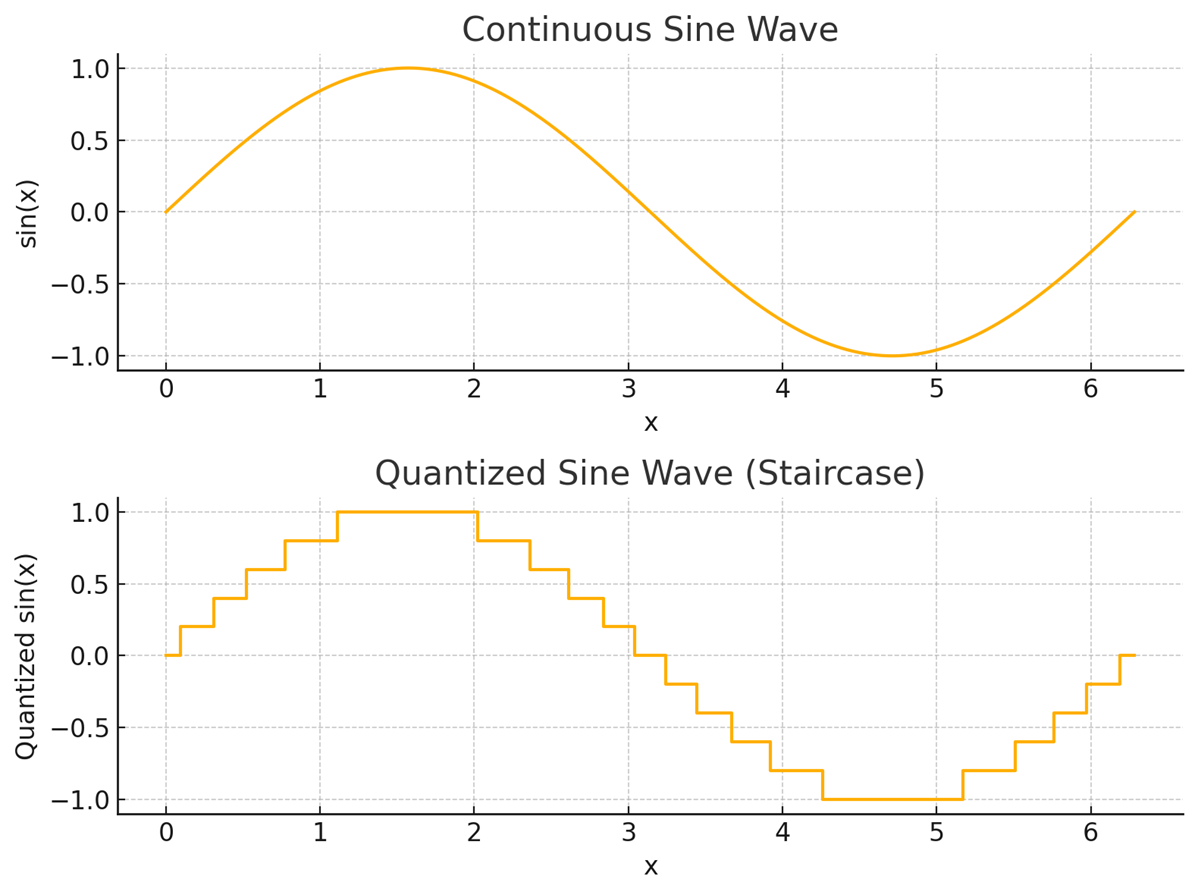
물리 관련이든, 통신이든 데이터가 큰 것(연속적인 것)에서 데이터가 작은 것(이산적인 것)으로 바꾸는 것이다.
AI 모델에 대한 양자화도 마찬가지인데, 기본 골자는 모델의 Vector가 32bit를 이용한 float으로 나타냈다면 이를 8bit int와 같은 용량을 덜 먹는 데이터로 줄이는 것이다.
이에 대한 방식은 여러가지이며, 양자화를 적용하는 시점도 여러가지가 있다.
2. 양자화의 목표
기본적으로 데이터가 크다면 메모리 대역폭이 많이 필요한데, 양자화를 통해서 데이터를 줄인다면 위에서도 메모리 대역폭이 줄어들고 그로 인해 메모리 필요 용량을 줄일 수 있다.
이는 최근 그래픽 카드의 Memory 용량이 문제가 되는데, 양자화로 어느정도 해소 할 수 있다고 할수 있다. 또한, 데이터가 줄어든다면 한번에 메모리에 올릴 수 있는 데이터가 많아지기에 속도도 빨라진다고 할 수 있으며 정수로 바꾸는 형태의 양자화라면 정수 연산을 사용하기 때문에 실제로 속도가 빨라진다.
3. 양자화의 단점
양자화라는게 무조건 좋은 것만 있는건 아니다. 손실 압축이 기반이기 때문에 데이터 손실은 당연히 따라오며 특히 이 손실 압축된 데이터를 가지고 연산을 하면 오류가 증폭된다.
이를 해결하기 위해서 여러가지 방법이 있다.
4. 양자화 종류
※ 양자화 종류 의사 결정트리
아래는 텐서플로우 개발자 가이드에서 제공하는 양자화 종류 의사 결정 트리이다.
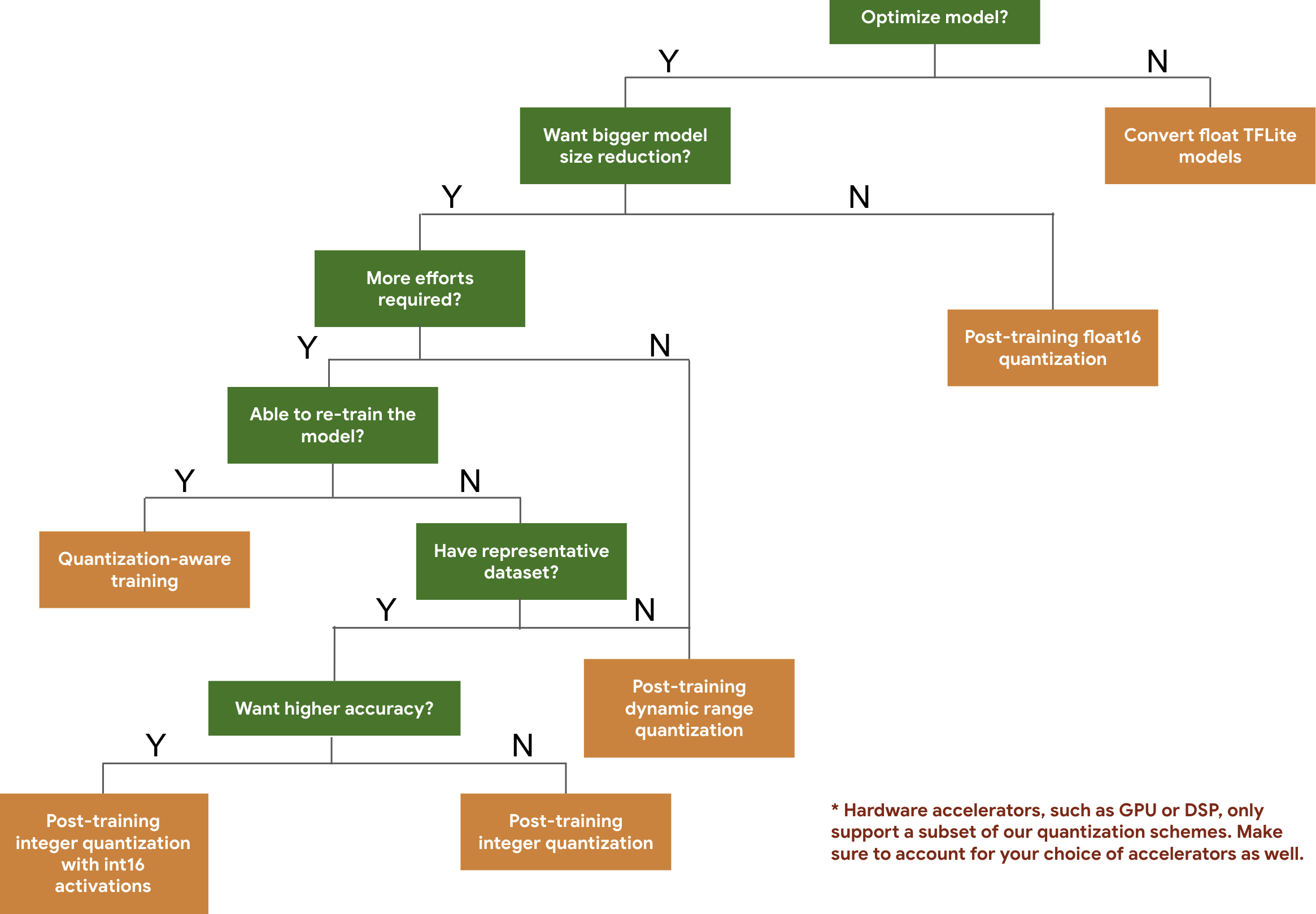
1) 사후 양자화(PTQ, Post-Training Quantization)
PTQ는 사전 훈련된 모델을 사용한 후 양자화를 적용하는 방식이다. 추가 학습은 필요하지 않기 때문에 적용이 빠르다. 주로 메모리 사용량을 줄이고, 연산 속도를 높이는데 사용되는데 모델 정확도 손실을 최소화하면서 리소스 줄이는데 좋다. 하지만 정밀도가 중요하다면 정확도 손실이 발생할 수 있다.
내부에서도 여러 종류가 있다.
이 과정에서 보정(calibration)을 적용하여 정확도 손실을 최소화하기도 한다.
a. Post-Training float16 quantization
32비트 부동소수점(FP32)에서 16비트 부동소수점(FP16)으로 변환하는 방식이다.
데이터를 저장할때는 16bit 부동소수점으로 저장하나, 실제 구동할때는 32bit로 업샘플링(Up sampling)을 수행해서 사용할 수 있으며, 아예 float16을 지원하는 GPU에서 구동된다면 그대로 구동할 수도 있다.
b. Post-Training dynamic range quantization
학습된 모델의 가중치와 상수만 8비트 정수(int8)로 고정 소수점화하고, 활성화(activation)는 런타임에 동적으로 float32-> int8 -> float32로 변환한다.
이 말인 즉슨 float32를 입력으로 받아 int8로 바꾸어 정수 커널에서 연산 후 다시 float32로 변환한다는 뜻이다.
메모리 대역폭과 연산량은 줄지만 본래와 유사한 정확도를 유지할 수 있다.
c. Post-Training integer quantization
가중치와 활성화 모두를 8비트 정수(int8)로 양자화하여 추론 과정에서 완전한 정수 연산만 사용하도록 하는 기법이다. 대신에 보정(calibration)이 필요한데, 이를 위해 소량의 대표 데이터셋을 이용해 범위(scale)과, 어느 부분이 int8의 0에 해당하게 할건지 제로 포인트를 계산해서 활성화의 동적 범위(range)를 보정해야한다.
d. Post-Training integer quantization with int16 activations
가중치는 8비트 정수(int8)로, 활성화는 16비트 정수(int16)로 양자화하는 방식으로, 중간 결과(intermediate)에 더 높은 비트폭을 할당해 정확도와 성능 간의 균형을 맞추는 방법이다.
2) 학습 중 양자화(QAT, Quantization-Aware Training)
훈련 과정에서부터 양자화를 적용하는 방식으로 낮은 정밀도(half-precision 같은)로 모델을 학습 시키면서도 높은 정확도를 유지할 수 있는 방법이다. 이 방법은 훈련 중에 양자화를 고려하여 모델이 적응하도록 하기 때문에 성능 손실이 적지만, PTQ에 비해 더 많은 계산 자원이 필요하다. 주로 매우 높은 성능이 요구되는 응용 프로그램에서 사용되는데 정확도와 리소스 절감을 균형있게 유지할수있다.
3) QLoRA(Quantized Low-Rank Adaptation)
최근에 주목받고 있는 QLoRA는 양자화된 가중치로 대형 모델을 적은 메모리로 미세 조정(fine-tuning, 최근 gpt를 이용한 서비스에서 많이 사용됨) 하는 기술이다. 이는 주로 매우 큰 언어 모델을 적은 자원으로 개인화하거나 특정 작업에 맞게 조정할 때 사용된다. QLoRA는 특히 대형 모델의 성능을 유지하면서도 메모리 요구 사항을 크게 줄일 수 있는 것이 강점이다. QLoRA는 INT4(4-bit) 양자화를 사용하며, 이를 통해 모델의 메모리 사용량을 최소화하면서도 높은 정확도를 유지할 수 있다.
※ 추가 업데이트 및 검증 예정이고, 아직 완벽하지 않으니 참고만 바란다.