병렬분산컴퓨팅 - 분산 시스템 통신 패러다임
분산 시스템 통신 패러다임
1. Remote Procedure Call (RPC)
1) RPC의 개요
원격 프로시저 호출(Remote Procedure Call)은 네트워크를 통한 통신 과정을 로컬 함수를 호출하는 것처럼 간단하게 처리할 수 있도록 설계된 통신 패러다임이다.
로컬 호출은 동일한 메모리 공간에서 나노초 단위로 실행되는 신뢰할수있는 작업이지만 RPC는 ms 이상의 네트워크 지연, 패킷 손실 및 딜레이나 서버 크래쉬로 인한 타임아웃과 같은 부분적인 실패 가능성이 존재하며 서로 다른 노드간에 전달하기 때문에 데이터의 직렬화와 역직렬화가 필수이다.
2) RPC 구동 방식
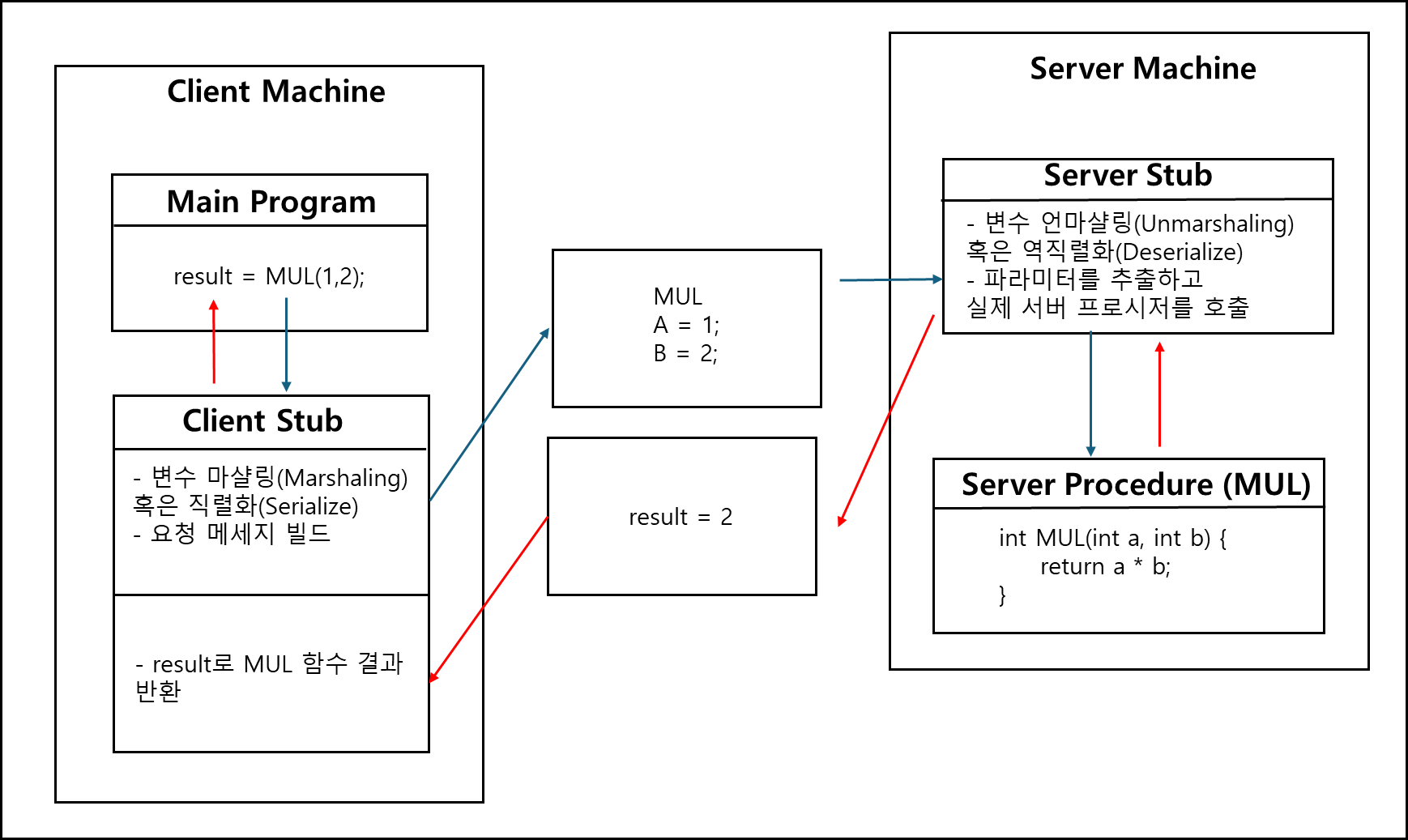
- Main Program에서 MUL 함수를 호출한다 (로컬 호출처럼 보임).
- MUL 함수로의 요청은 Client Stub로 이동한다. Client Stub는 파라미터를 마샬링(Marshal, 직렬화)하여 요청 메시지를 생성한다.
- 메시지가 네트워크를 통해 서버로 전달된다.
- 네트워크를 통해 서버로 전달된 메세지는 Server Stub가 받게되고, Server Stub은 메시지를 언마샬링(Unmarshal)하여 파라미터를 추출하고 실제 서버 프로시저를 호출한다.
- 서버에서 작업을 수행한 후 결과 값을 다시 Server Stub을 통해 클라이언트로 보낸다.
- Server Stub이 보낸 메세지를 Client Stub이 받아 Main Program으로 전달한다.
2) Contract와 Stub 생성
통신을 위한 Stub을 사용자가 직접 만들어야한다고 생각하면 굉장히 일이 많을 것이다. 하지만 다행스럽게도 IDL(Interface Definition Language)를 통해
이러한 Stub 코드를 쉽게 만들 수 있다.
전통적인 RPC(SUN RPC, ONC RPC)나 현대적인 RPC(gRPC, Protocol Buffers)를 통해 Stub이 하는 일을 정의하면 IDL 컴파일러(rpcgen, protoc)가 해당 IDL을 인식하여 아래의 산출물들을 반환한다.
Client Stub
메인 프로그램의 호출을 받아 파라미터를 마샬링(직렬화)하고, 네트워크를 통해 요청을 보낸 뒤 응답을 수신한다.Server Stub
네트워크로부터 받은 요청을 언마샬링(역직렬화)하여 실제 서버 내의 프로시저를 호출하고, 실행 결과를 다시 반환한다.Serialization Code
서로 다른 하드웨어 아키텍처 간에도 데이터를 올바르게 해석할 수 있도록 기계 독립적인 데이터 표현 방식(XDR 또는 Protobuf)을 구현한 코드이다.
3) Parameter Passing
RPC는 머신 간에 메모리 주소(포인터)를 직접 전달할 수 없다. 따라서 포인터 대신 데이터를 복사하여 전달하며, 서로 다른 아키텍처(엔디언 방식 등) 간의 호환성을 위해 XDR이나 Protocol Buffers(protobuf) 같은 기기 독립적인 직렬화 형식을 사용한다.
여기서 기기 독립적이라는 말은 Node들의 아키텍처에 따른 Endian과 Data type에 영향을 받지 않는 형태라는 뜻으로
XDR과 protobuf 둘 다 자체적인 방식을 통해 데이터를 직렬화한다.
4) Failure Semantics
원격 호출 중 타임아웃이 발생하면 서버가 실제로 명령을 실행했는지 알 수 없는 문제가 발생한다. 이를 해결하기 위해 다음과 같은 보장 수준을 정의한다.
a. Maybe
Client가 요청을 보낸 뒤 서버에서 요청이 없어도 신경쓰지 않는 방식이다.
응답이 없어도 재시도 하지 않으면 별다른 조치를 취하지 않는다.
Logging이나 Monitoring event와 같이 하나 하나의 요청이 엄청 중요한 정도까지는 아닌 시스템에서 사용한다.
가장 신뢰성이 낮고 간단한 방식이다.
b. At Least Once
최소 한번의 도착은 보장하는 방식이다. Client가 서버에 요청 후 일정시간 동안 응답이 없다면 한번 더 요청을 보낸다.
이후 응답을 받을때까지 요청하기 때문에 최소 한번 도착 보장이다.
이때 요청 자체가 멱등성(idempotency, 몇번을 실행해도 동일한 결과인 것) 있는 요청이 아니라면 중복해서 적용될 가능성이 있다.
※ 멱등성 있는 요청
아래와 같은 요청이 있다고 해보자.
1
x = x + 1;
위와 같은 요청이 원래는 한번만 적용되어야하는데 N번 요청했다고 해보자.
원래 x 초기값이 0이라 한번 실행시 1이어야하는데 N번 요청이 들어와버리면 x의 값은 N이 되어버린다.
하지만 아래와 같은 코드를 보자.
1
x = 1;
위의 코드는 몇 번을 실행해도 x에는 1만 들어있다.
이렇게 몇번을 실행해도 동일한 결과인 것을 멱등성이 있다고 한다.
At least Once 방식의 경우에는 이러한 멱등성이 있는 요청이 아니라면 첫번째와 요청과 같이 잘못된 결과가 있기 때문에 아래의 두가지 방법 중에 하나를 선택해야한다.
- 요청 내용을 멱등성이 있게 구성한다.
- 요청의 중복을 제거한다.
1번의 경우에는 x에 1을 대입하는 형태의 멱등성 있는 요청 내용이고, 2번의 경우에는 각 요청에 ID를 부여하는 것이다.
Application에서 해당 요청에 대한 ID를 Table로 유지하여 이미 받은 요청인지 대조하여 이미 처리한 요청이라면 무시하는식으로 서버측에서 해당 요청을 받았음을 체크하게 한다.
아무래도 2번 보다는 1번이 관리의 측면에서는 좀 더 쉬운 부분이 있으나 구현은 더 어려울 수 있다.
요청에 대해서 로그를 남길때는 1번 방식을 좀 더 선호하는 부분이 있는 듯하다. 실제로 MongoDB와 같은 Sharded Replication을 지원하는 DB는 동기화를 위해서 요청을 날리는데, 이 요청은 x += 1과 같은 형태의 요청이라도 내부적으로 oplog를 남길때는 x=1과 같이 멱등성 있는 형태로 유지하여 문제가 생길때 복구를 용이하게 구성한다.
c. At Most Once
무조건 한번의 도착을 보장하는 방식이다. Exactly Once 방식이라고도 하며, 이전에 “최소 한번 방식”은 Application에서 중복 제거 혹은 멱등성 있는 요청으로 처리를 해야했다면 이 경우 Stub에서 별도의 요청에 대한 ID table을 유지하여 해당 요청을 중복을 제거하는 방식이다. 최소 한번 방식보다 Stub의 Overhead가 훨씬 크다
※ 추가 업데이트 예정
참고자료
- 서강대학교 박성용 교수님 강의자료 - 병렬 분산 컴퓨팅
원문 참고자료들
- G. Coulouria, J. Dollimore, T. Kindberg, and G. Blair, Distributed Systems: Concepts and Design, 5 th Edition, Pearson, 2012, ISBN 978-0-273-76059-7
- M. van Steen and A. S. Tanenbaum, Distributed Systems, 3 rd Edition, 2017
- Martin Kleppmann, Designing Data-Intensive Applications, 1 st Edition, O’Reilly Media, 2017, ISBN 978-1491903070 (또는 2nd Edition in February 2026)